Recognition: no theorem link
FrontierFinance: A Long-Horizon Computer-Use Benchmark of Real-World Financial Tasks
Pith reviewed 2026-05-10 19:43 UTC · model grok-4.3
The pith
Human financial experts achieve higher average scores and more client-ready outputs than current AI systems on a benchmark of complex modeling tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
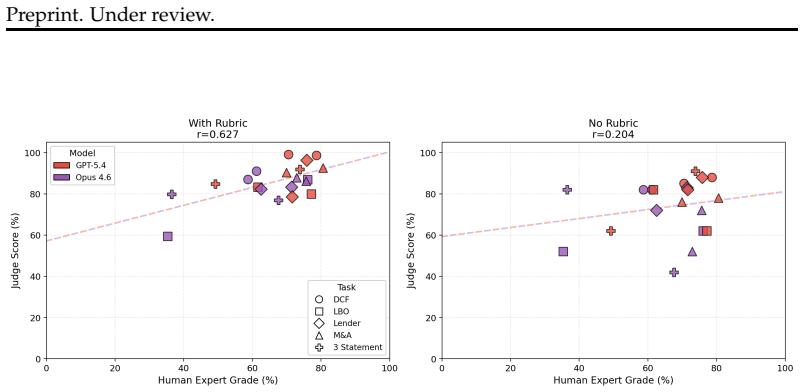
We introduce FrontierFinance as a long-horizon benchmark consisting of 25 complex financial modeling tasks. The tasks reflect industry-standard workflows and are paired with detailed rubrics for evaluation. Human experts both receive higher scores on average and are more likely to provide client-ready outputs than current state-of-the-art systems.
What carries the argument
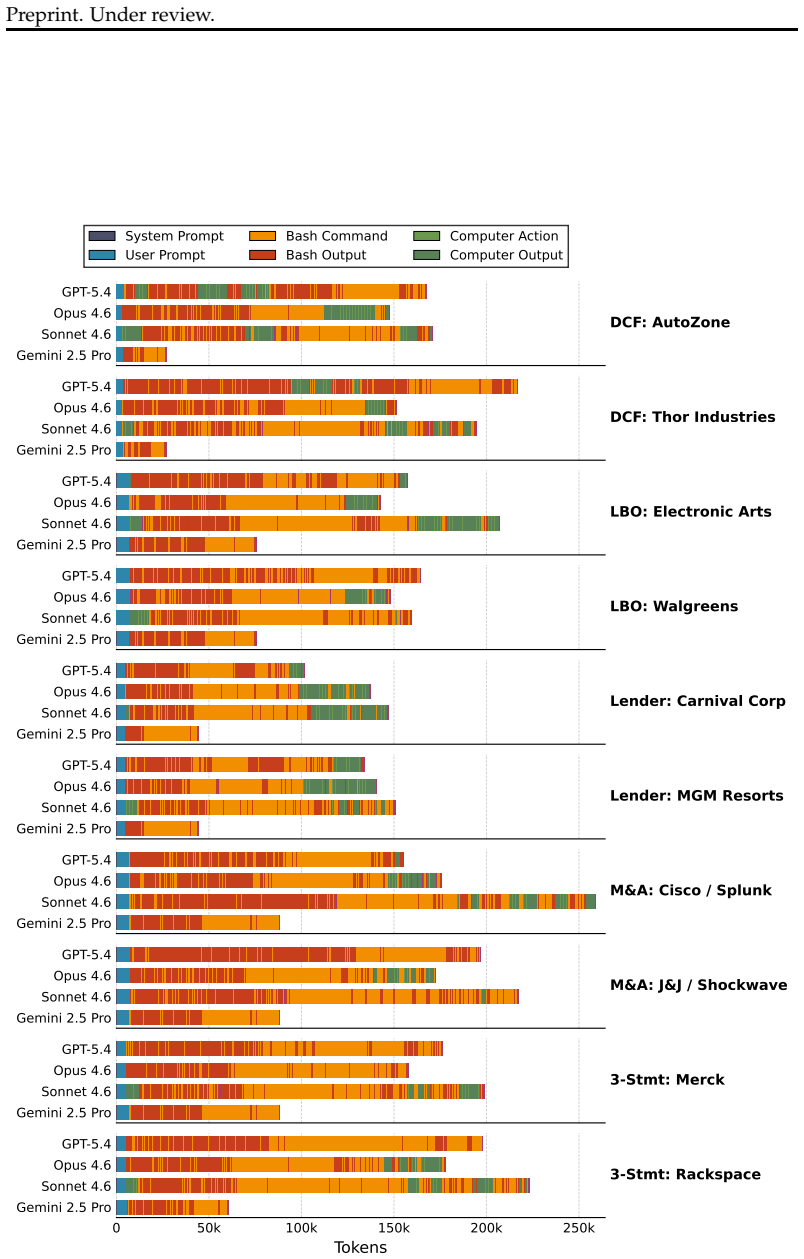
FrontierFinance benchmark of 25 long-horizon financial modeling tasks with rubrics for structured scoring of human and AI performance.
If this is right
- Current AI systems require advances in managing extended sequences of decisions and maintaining quality over many steps in financial work.
- Finance professionals can use the benchmark and rubrics to evaluate new tools before adoption in client-facing roles.
- The performance gap indicates areas where human judgment and verification remain necessary in standard modeling processes.
- Future AI development can be tracked against fixed human baselines on these realistic tasks.
Where Pith is reading between the lines
- Similar long-horizon benchmarks in other professional fields could help map where AI still falls short of expert performance.
- The focus on client-ready outputs suggests AI must improve not only accuracy but also consistency in format and reliability to be deployable.
- If AI systems reach human levels on these tasks, it could shift how financial analysis is staffed, though current results indicate that shift is not yet here.
Load-bearing premise
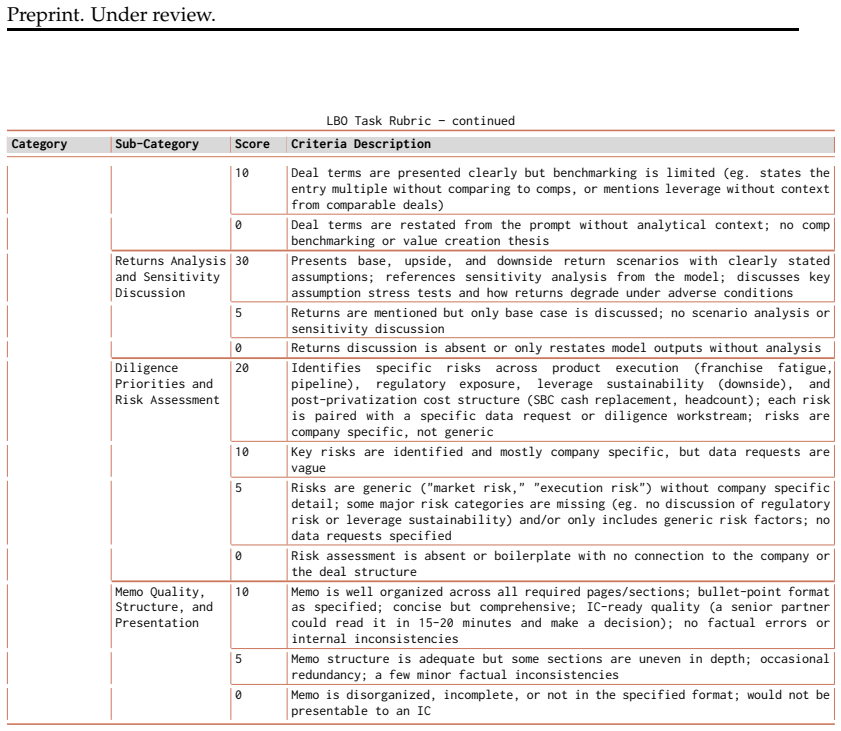
The 25 tasks and detailed rubrics accurately reflect industry-standard financial modeling workflows and enable fair comparison between humans and LLMs.
What would settle it
A new AI system that consistently produces higher average rubric scores or a higher rate of client-ready outputs than the human experts across the same 25 tasks would contradict the central claim.
Figures






read the original abstract
As concerns surrounding AI-driven labor displacement intensify in knowledge-intensive sectors, existing benchmarks fail to measure performance on tasks that define practical professional expertise. Finance, in particular, has been identified as a domain with high AI exposure risk, yet lacks robust benchmarks to track real-world developments. This gap is compounded by the absence of clear accountability mechanisms in current Large Language Model (LLM) deployments. To address this, we introduce FrontierFinance, a long-horizon benchmark of 25 complex financial modeling tasks across five core finance models, requiring an average of over 18 hours of skilled human labor per task to complete. Developed with financial professionals, the benchmark reflects industry-standard financial modeling workflows and is paired with detailed rubrics for structured evaluation. We engage human experts to define the tasks, create rubrics, grade LLMs, and perform the tasks themselves as human baselines. We demonstrate that our human experts both receive higher scores on average, and are more likely to provide client-ready outputs than current state-of-the-art systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FrontierFinance, a long-horizon computer-use benchmark consisting of 25 complex financial modeling tasks across five core finance models. These tasks are designed to require an average of over 18 hours of skilled human labor each and were developed with financial professionals to reflect industry-standard workflows. The benchmark is paired with detailed rubrics for evaluation. Human experts are engaged to define tasks, create rubrics, grade LLM outputs, and perform the tasks as baselines. The central claim is that human experts achieve higher average scores and are more likely to produce client-ready outputs than current state-of-the-art LLMs.
Significance. If the results are robust, this benchmark could be highly significant for the field by providing a realistic measure of LLM performance on practical financial tasks, which existing benchmarks do not adequately capture. The professional involvement and human baselines add credibility. It could inform discussions on AI's impact on knowledge work in finance and guide future model development toward better handling of long-horizon, multi-step tasks.
major comments (2)
- [Abstract] The abstract asserts that human experts receive higher scores on average and are more likely to provide client-ready outputs, but supplies no quantitative results, specific LLMs tested, or details on the scoring procedures, which are essential for verifying the claim.
- [Benchmark Design] The claim that the 25 tasks and rubrics accurately reflect industry-standard financial modeling workflows relies on development with financial professionals, but the manuscript provides limited information on the selection process, number of experts, and any validation steps taken to ensure representativeness.
minor comments (1)
- [Introduction] The discussion of existing benchmarks could include more specific comparisons to highlight the novelty of the long-horizon aspect.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We appreciate the feedback and have prepared point-by-point responses below, with revisions planned to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that human experts receive higher scores on average and are more likely to provide client-ready outputs, but supplies no quantitative results, specific LLMs tested, or details on the scoring procedures, which are essential for verifying the claim.
Authors: We agree that the abstract would be more informative with key quantitative details. Although the full results, including the specific state-of-the-art LLMs evaluated and the rubric-based scoring procedures, are described in the methods and results sections, we will revise the abstract to include the LLMs tested, the average human and LLM scores, and a concise reference to the evaluation rubric. revision: yes
-
Referee: [Benchmark Design] The claim that the 25 tasks and rubrics accurately reflect industry-standard financial modeling workflows relies on development with financial professionals, but the manuscript provides limited information on the selection process, number of experts, and any validation steps taken to ensure representativeness.
Authors: We acknowledge the value of greater transparency here. The tasks and rubrics were developed through collaboration with financial professionals to align with industry workflows. In the revised manuscript, we will expand the benchmark design section to specify the number of experts involved, their selection criteria and backgrounds, and the validation steps employed, such as iterative reviews and pilot testing for representativeness. revision: yes
Circularity Check
No significant circularity in benchmark evaluation
full rationale
The paper introduces FrontierFinance as a new benchmark of 25 tasks and rubrics developed collaboratively with financial professionals. Human experts both create the tasks/rubrics and serve as independent baselines by performing the tasks themselves, with grading applied uniformly via the same structured rubrics to both human and LLM outputs. The central claim (humans receive higher average scores and produce more client-ready outputs than SOTA systems) is a direct empirical comparison on this externally defined benchmark, with no equations, fitted parameters, predictions, or derivations that reduce to the inputs by construction. No self-citations or uniqueness theorems are invoked as load-bearing elements. The evaluation chain is self-contained against the stated human baselines and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks and rubrics developed with financial professionals accurately represent industry-standard financial modeling workflows
Reference graph
Works this paper leans on
-
[1]
Inspect AI: Framework for Large Language Model Evaluations
UK AI Security Institute. Inspect AI: Framework for Large Language Model Evaluations . URL https://github.com/UKGovernmentBEIS/inspect_ai
-
[2]
Labor market impacts of AI : A new measure and early evidence
Anthropic Economic Research Team . Labor market impacts of AI : A new measure and early evidence. Technical report, Anthropic, March 2026. URL https://www.anthropic.com/research/labor-market-impacts
2026
-
[3]
Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues
Ge Bai, Jie Liu, Xingyuan Bu, Yancheng He, Jiaheng Liu, Zhanhui Zhou, Zhuoran Lin, Wenbo Su, Tiezheng Ge, Bo Zheng, and Wanli Ouyang. Mt-bench-101: A fine-grained benchmark for evaluating large language models in multi-turn dialogues. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 7...
-
[4]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Mądry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025. URL https://arxiv.org/abs/2410.07095
work page Pith review arXiv 2025
-
[5]
F in QA : A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. F in QA : A dataset of numerical reasoning over financial data. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empiri...
-
[6]
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. C onv F in QA : Exploring the chain of numerical reasoning in conversational finance question answering. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 6279--6292...
-
[7]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating llms by human preference, 2024. URL https://arxiv.org/abs/2403.04132
work page internal anchor Pith review arXiv 2024
-
[8]
Davenport and Laks Srinivasan
Thomas H. Davenport and Laks Srinivasan. Companies are laying off workers because of AI 's potential—not its performance. Harvard Business Review, January 2026. URL https://hbr.org/2026/01/companies-are-laying-off-workers-because-of-ais-potential-not-its-performance
2026
-
[9]
Yukang Feng, Jianwen Sun, Zelai Yang, Jiaxin Ai, Chuanhao Li, Zizhen Li, Fanrui Zhang, Kang He, Rui Ma, Jifan Lin, Jie Sun, Yang Xiao, Sizhuo Zhou, Wenxiao Wu, Yiming Liu, Pengfei Liu, Yu Qiao, Shenglin Zhang, and Kaipeng Zhang. Longcli-bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026. URL http...
-
[10]
Xuanqi Gao, Siyi Xie, Juan Zhai, Shiqing Ma, and Chao Shen. Mcp-radar: A multi-dimensional benchmark for evaluating tool use capabilities in large language models, 2025. URL https://arxiv.org/abs/2505.16700
-
[11]
Evaluating the impact of AI on the labor market: Current state of affairs
Martha Gimbel, Molly Kinder, Joshua Kendall, and Maddie Lee. Evaluating the impact of AI on the labor market: Current state of affairs. Technical report, Yale Budget Lab, October 2025. URL https://budgetlab.yale.edu/research/evaluating-impact-ai-labor-market-current-state-affairs
2025
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Financebench: A new benchmark for financial question answering.arXiv preprint arXiv:2311.11944, 2023
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. Financebench: A new benchmark for financial question answering, 2023. URL https://arxiv.org/abs/2311.11944
-
[14]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. URL https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, and Minjoon Seo. Prometheus: Inducing fine-grained evaluation capability in language models, 2024. URL https://arxiv.org/abs/2310.08491
-
[16]
B iz B ench: A quantitative reasoning benchmark for business and finance
Michael Krumdick, Rik Koncel-Kedziorski, Viet Dac Lai, Varshini Reddy, Charles Lovering, and Chris Tanner. B iz B ench: A quantitative reasoning benchmark for business and finance. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 8...
-
[17]
Measuring ai ability to complete long tasks
Thomas Kwa, Ben West, Joel Becker, and 21 others. Measuring ai ability to complete long tasks. https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/, 03 2025
2025
-
[18]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-harness: End-to-end optimization of model harnesses, 2026. URL https://arxiv.org/abs/2603.28052
work page internal anchor Pith review arXiv 2026
-
[19]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents, 2025. URL https://arxiv.org/abs/2308.03688
work page internal anchor Pith review arXiv 2025
-
[20]
G -Eval: NLG Evaluation using Gpt-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G -eval: NLG evaluation using gpt-4 with better human alignment. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 2511--2522, Singapore, December 2023. Association for Computational ...
-
[21]
arXiv preprint arXiv:2502.12115 , year=
Samuel Miserendino, Michele Wang, Tejal Patwardhan, and Johannes Heidecke. Swe-lancer: Can frontier llms earn \ 1 million from real-world freelance software engineering?, 2025. URL https://arxiv.org/abs/2502.12115
-
[22]
Tejal Patwardhan, Rachel Dias, Elizabeth Proehl, Grace Kim, Michele Wang, Olivia Watkins, Simón Posada Fishman, Marwan Aljubeh, Phoebe Thacker, Laurance Fauconnet, Natalie S. Kim, Patrick Chao, Samuel Miserendino, Gildas Chabot, David Li, Michael Sharman, Alexandra Barr, Amelia Glaese, and Jerry Tworek. Gdpval: Evaluating ai model performance on real-worl...
-
[23]
D oc F in QA : A long-context financial reasoning dataset
Varshini Reddy, Rik Koncel-Kedziorski, Viet Dac Lai, Michael Krumdick, Charles Lovering, and Chris Tanner. D oc F in QA : A long-context financial reasoning dataset. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 445--458, Bangk...
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review arXiv 2023
-
[25]
Hcast: Human-calibrated autonomy software tasks, 2025
David Rein, Joel Becker, Amy Deng, Seraphina Nix, Chris Canal, Daniel O'Connel, Pip Arnott, Ryan Bloom, Thomas Broadley, Katharyn Garcia, Brian Goodrich, Max Hasin, Sami Jawhar, Megan Kinniment, Thomas Kwa, Aron Lajko, Nate Rush, Lucas Jun Koba Sato, Sydney Von Arx, Ben West, Lawrence Chan, and Elizabeth Barnes. Hcast: Human-calibrated autonomy software t...
-
[26]
How will AI affect the US labor market? Technical report, Goldman Sachs Research, March 2026
Goldman Sachs Research. How will AI affect the US labor market? Technical report, Goldman Sachs Research, March 2026. URL https://www.goldmansachs.com/insights/articles/how-will-ai-affect-the-us-labor-market
2026
-
[27]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, and Aditya Gupta. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models, 2023. URL https://arxiv.org/abs/2206.04615
work page internal anchor Pith review arXiv 2023
-
[28]
Simon Thorne. Large language models for spreadsheets: Benchmarking progress and evaluating performance with flare, 2025. URL https://arxiv.org/abs/2506.17330
-
[29]
Bertie Vidgen, Austin Mann, Abby Fennelly, John Wright Stanly, Lucas Rothman, Marco Burstein, Julien Benchek, David Ostrofsky, Anirudh Ravichandran, Debnil Sur, Neel Venugopal, Alannah Hsia, Isaac Robinson, Calix Huang, Olivia Varones, Daniyal Khan, Michael Haines, Austin Bridges, Jesse Boyle, Koby Twist, Zach Richards, Chirag Mahapatra, Brendan Foody, an...
-
[30]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https://arxiv.org/abs/2404.07972
work page internal anchor Pith review arXiv 2024
-
[31]
XF in B ench: Benchmarking LLM s in complex financial problem solving and reasoning
Zhihan Zhang, Yixin Cao, and Lizi Liao. XF in B ench: Benchmarking LLM s in complex financial problem solving and reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 8715--8758, Vienna, Austria, July 2025. Association for Computational L...
-
[32]
Financemath: Knowledge-intensive math reasoning in finance domains
Yilun Zhao, Hongjun Liu, Yitao Long, Rui Zhang, Chen Zhao, and Arman Cohan. Financemath: Knowledge-intensive math reasoning in finance domains. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 12841--12858, Bangkok, Thailand, Augus...
-
[33]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023. URL https://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URL https://arxiv.org/abs/2307.13854
work page Pith review arXiv 2024
-
[35]
Wei Zhou, Bolei Ma, Annemarie Friedrich, and Mohsen Mesgar
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. TAT - QA : A question answering benchmark on a hybrid of tabular and textual content in finance. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguis...
-
[36]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[37]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[38]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[39]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.