Recognition: 2 theorem links
· Lean TheoremThe UNDO Flip-Flop: A Controlled Probe for Reversible Semantic State Management in State Space Model
Pith reviewed 2026-05-10 18:40 UTC · model grok-4.3
The pith
State space models fail to discover stack-based rollback in the UNDO Flip-Flop task
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
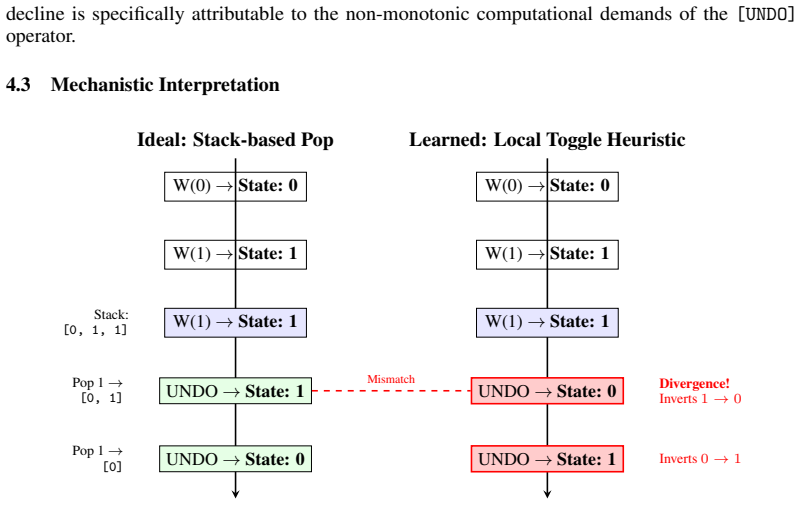
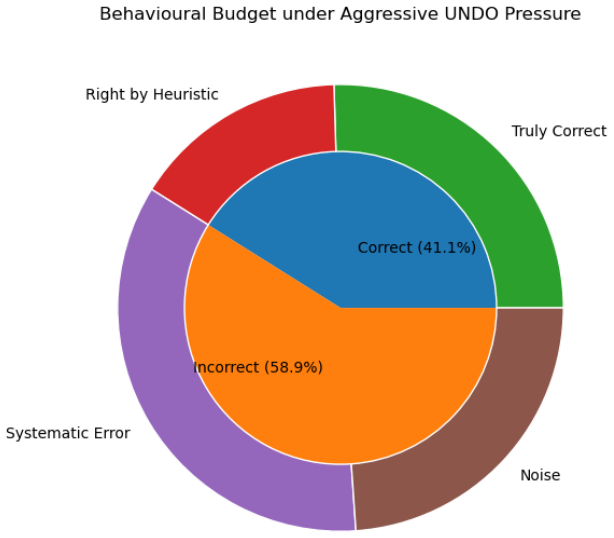
Both one-layer and two-layer variants of Mamba-2 fail to acquire the provably expressible stack-based rollback mechanism. They converge instead on a local toggle heuristic that inverts the current state rather than retrieving stored history. Under an adversarial retraction pressure test held within the training length distribution, the two-layer model collapses to 41.10% accuracy, below random chance. Causal ablation shows that the bottleneck lies in retrieval, not storage. These results confirm systematic rather than incidental failure and draw a clear line between representational capacity and what gradient-based training reliably learns.
What carries the argument
The UNDO Flip-Flop task, which requires maintaining an implicit bounded stack to recover historical states under non-monotonic update sequences.
If this is right
- SSMs possess theoretical capacity for star-free sequential tasks and bounded hierarchical structures but gradient optimization may not discover them.
- The UNDO task isolates reversible retrieval as a distinct requirement from monotonic tracking.
- Failure in retrieval points to a need for training methods that encourage history access.
- New tasks are required to reveal gaps between expressivity and learnability.
Where Pith is reading between the lines
- Other sequence models might exhibit the same preference for local heuristics on similar reversible tasks.
- Scaling model size or training data could potentially overcome the toggle convergence.
- The distinction between what is representable and what is learnable applies to many other architectures and tasks.
Load-bearing premise
The UNDO Flip-Flop task design and adversarial test isolate the requirement for bounded-stack retrieval, treating the local toggle as a failure to solve the intended problem.
What would settle it
A model achieving high accuracy on adversarial tests by explicitly using stack-like internal dynamics to rollback states.
Figures


read the original abstract
State space models (SSMs) have been shown to possess the theoretical capacity to model both star-free sequential tasks and bounded hierarchical structures Sarrof et al. (2024). However, formal expressivity results do not guarantee that gradient-based optimisation will reliably discover the corresponding solutions. Existing benchmarks probe either monotonic state tracking, as in the standard Flip-Flop task, or structural nesting, as in the Dyck languages, but neither isolates reversible semantic state retrieval. We introduce the UNDO Flip-Flop task to fill this gap. By extending the standard Flip-Flop with an UNDO, the task requires a model to maintain an implicit bounded stack and recover historical states under non-monotonic update sequences. We evaluate one-layer and two-layer Mamba-2 under this framework. Both variants fail to acquire the provably expressible stack-based rollback mechanism, converging instead on a local toggle heuristic that inverts the current state rather than retrieving stored history. Under an adversarial retraction pressure test held within the training length distribution, the two-layer model collapses to 41.10% accuracy, which is below random chance. The results confirm systematic rather than incidental failure. Causal ablation shows that the bottleneck lies in retrieval, not storage. These results draw a clear line between what an architecture can in principle represent and what gradient descent reliably learns, a distinction that theoretical expressivity analyses alone cannot capture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the UNDO Flip-Flop task, which augments the standard Flip-Flop with an UNDO operation to require models to maintain an implicit bounded stack and retrieve prior states under non-monotonic sequences. It evaluates one- and two-layer Mamba-2 models on this task and reports that both converge on a local toggle heuristic rather than the provably expressible stack-based rollback, with the two-layer model collapsing to 41.10% accuracy (below chance) under an adversarial retraction pressure test conducted within the training length distribution. Causal ablations are used to localize the failure to retrieval rather than storage, underscoring a gap between theoretical expressivity of SSMs for bounded hierarchical structures and what gradient descent discovers in practice.
Significance. If the empirical results hold after verification of methods and task construction, the work is significant for providing a controlled diagnostic that separates expressivity from learnability in state space models. The UNDO Flip-Flop task and the adversarial test offer a falsifiable probe for reversible semantic state management that existing monotonic or nesting benchmarks do not isolate, which could inform targeted improvements in SSM training or architectures for history-dependent sequential tasks.
major comments (1)
- [Abstract] Abstract: The claim that the two-layer model 'collapses to 41.10% accuracy, which is below random chance' under the adversarial retraction pressure test is load-bearing for the conclusion of systematic failure to acquire stack-based retrieval. The manuscript must specify the exact generation procedure for the retraction sequences, their length distribution relative to training, and the random baseline calculation to confirm that the below-chance result isolates retrieval failure rather than an artifact of task construction or optimization dynamics.
minor comments (3)
- The citation to Sarrof et al. (2024) for theoretical expressivity results should include the full bibliographic entry and a brief recap of the relevant theorem on bounded hierarchical structures to make the contrast with empirical findings self-contained.
- [Task Definition] Clarify in the task definition section whether the UNDO operation is strictly bounded (e.g., by a fixed stack depth) and how this bound is enforced during sequence generation, as this directly supports the claim that the task requires bounded-stack retrieval.
- The abstract reports concrete accuracy figures and ablation results; the main text should include the corresponding tables or figures with error bars, number of runs, and exact hyperparameter settings to allow reproduction of the toggle-heuristic observation.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for recognizing the potential significance of the UNDO Flip-Flop task as a diagnostic for separating expressivity from learnability in state space models. We address the single major comment below and have prepared revisions to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the two-layer model 'collapses to 41.10% accuracy, which is below random chance' under the adversarial retraction pressure test is load-bearing for the conclusion of systematic failure to acquire stack-based retrieval. The manuscript must specify the exact generation procedure for the retraction sequences, their length distribution relative to training, and the random baseline calculation to confirm that the below-chance result isolates retrieval failure rather than an artifact of task construction or optimization dynamics.
Authors: We agree that the abstract should be self-contained on this point to avoid any ambiguity about whether the below-chance performance reflects a genuine retrieval failure. The generation procedure, length distribution, and random baseline are already specified in the Methods and Experimental Setup sections. In the revised manuscript we have added a concise summary of these elements directly into the abstract so that the claim stands on its own. This addition confirms that the adversarial test operates strictly inside the training length distribution and that the baseline corresponds to the toggle heuristic the models actually learn, thereby isolating the retrieval bottleneck rather than an artifact of task construction. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a purely empirical evaluation introducing the UNDO Flip-Flop task and measuring Mamba-2 performance (including the 41.10% accuracy collapse and causal ablation separating retrieval from storage). No equations, derivations, or fitted parameters are presented that reduce the central claims to self-referential inputs by construction. The cited expressivity result (Sarrof et al. 2024) is external to the present authors and is used only to frame the empirical gap, not to force the reported outcomes. The task design and adversarial test are defined independently of the model results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The UNDO Flip-Flop task requires models to maintain an implicit bounded stack for reversible semantic state retrieval.
Reference graph
Works this paper leans on
-
[1]
ISSN 2168-2712. doi: 10.1109/TIT.1956.1056813. URL https://ieeexplore.ieee.org/abstract/document/1056813. Tri Dao and Albert Gu. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality, May
-
[2]
URLhttp://arxiv.org/abs/2405.21060. arXiv:2405.21060 [cs]. Grégoire Delétang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, and Pedro A. Ortega. Neural Networks and the Chomsky Hierarchy, February
work page internal anchor Pith review arXiv
-
[3]
URL http://arxiv.org/abs/2207. 02098. arXiv:2207.02098 [cs]. Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A. Wichmann. Shortcut Learning in Deep Neural Networks.Nature Machine Intelligence, 2(11):665–673, November
-
[4]
ISSN 2522-5839. doi: 10.1038/s42256-020-00257-z. URLhttp://arxiv.org/abs/2004.07780. arXiv:2004.07780 [cs]. Albert Gu and Tri Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces, May
-
[5]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
URLhttp://arxiv.org/abs/2312.00752. arXiv:2312.00752 [cs]. Michael Hahn. Theoretical Limitations of Self-Attention in Neural Sequence Models.Transactions of the Association for Computational Linguistics, 8:156–171, December
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
ISSN 2307-387X. doi: 10.1162/tacl_a_00306. URLhttps://direct.mit.edu/tacl/article/43545. 8 John Hewitt, Michael Hahn, Surya Ganguli, Percy Liang, and Christopher D. Manning. RNNs can generate bounded hierarchical languages with optimal memory, October
-
[7]
URL http: //arxiv.org/abs/2010.07515. arXiv:2010.07515 [cs]. Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. Repeat After Me: Transformers are Better than State Space Models at Copying, June
-
[8]
arXiv preprint arXiv:2402.01032 , year=
URL http://arxiv. org/abs/2402.01032. arXiv:2402.01032 [cs]. Fred Karlsson. Constraints on Multiple Center-Embedding of Clauses.Journal of Linguistics, 43(2): 365–392,
-
[9]
URLhttps://www.jstor.org/stable/40057996
ISSN 0022-2267. URLhttps://www.jstor.org/stable/40057996. Bingbin Liu, Jordan T. Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang. Exposing Attention Glitches with Flip-Flop Language Modeling, October
-
[10]
Ash, Surbhi Goel, Akshay Krishnamurthy, and Cyril Zhang
URL http://arxiv.org/ abs/2306.00946. arXiv:2306.00946 [cs]. R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the Wrong Reasons: Diagnosing Syntactic Heuristics in Natural Language Inference. In Anna Korhonen, David Traum, and Lluís Màrquez, editors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 342...
-
[11]
Thomas and Pavlick, Ellie and Linzen, Tal
Association for Computational Linguistics. doi: 10.18653/v1/P19-1334. URLhttps://aclanthology.org/P19-1334/. William Merrill and Ashish Sabharwal. The Parallelism Tradeoff: Limitations of Log-Precision Transformers, April
-
[12]
URL http://arxiv.org/abs/2207.00729. arXiv:2207.00729 [cs]. William Merrill, Jackson Petty, and Ashish Sabharwal. The Illusion of State in State-Space Models, March
-
[13]
The illusion of state in state-space models
URLhttp://arxiv.org/abs/2404.08819. arXiv:2404.08819 [cs]. Yash Sarrof, Yana Veitsman, and Michael Hahn. The Expressive Capacity of State Space Models: A Formal Language Perspective. InAdvances in Neural Information Processing Systems 37, pages 41202–41241,
-
[14]
URL http://arxiv.org/abs/2405.17394
doi: 10.52202/079017-1304. URL http://arxiv.org/abs/2405.17394. arXiv:2405.17394 [cs]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, June
-
[15]
URL http://arxiv.org/ abs/1706.03762. arXiv:1706.03762 [cs] version:
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2105.11115 , year=
URL http://arxiv.org/ abs/2105.11115. arXiv:2105.11115 [cs]. A Appendix Figure 4: Training Convergence 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.