Recognition: no theorem link
ReLU Networks for Exact Generation of Similar Graphs
Pith reviewed 2026-05-10 18:34 UTC · model grok-4.3
The pith
ReLU networks of constant depth and O(n²d) size can deterministically generate every graph within edit distance d from a given n-vertex input graph.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
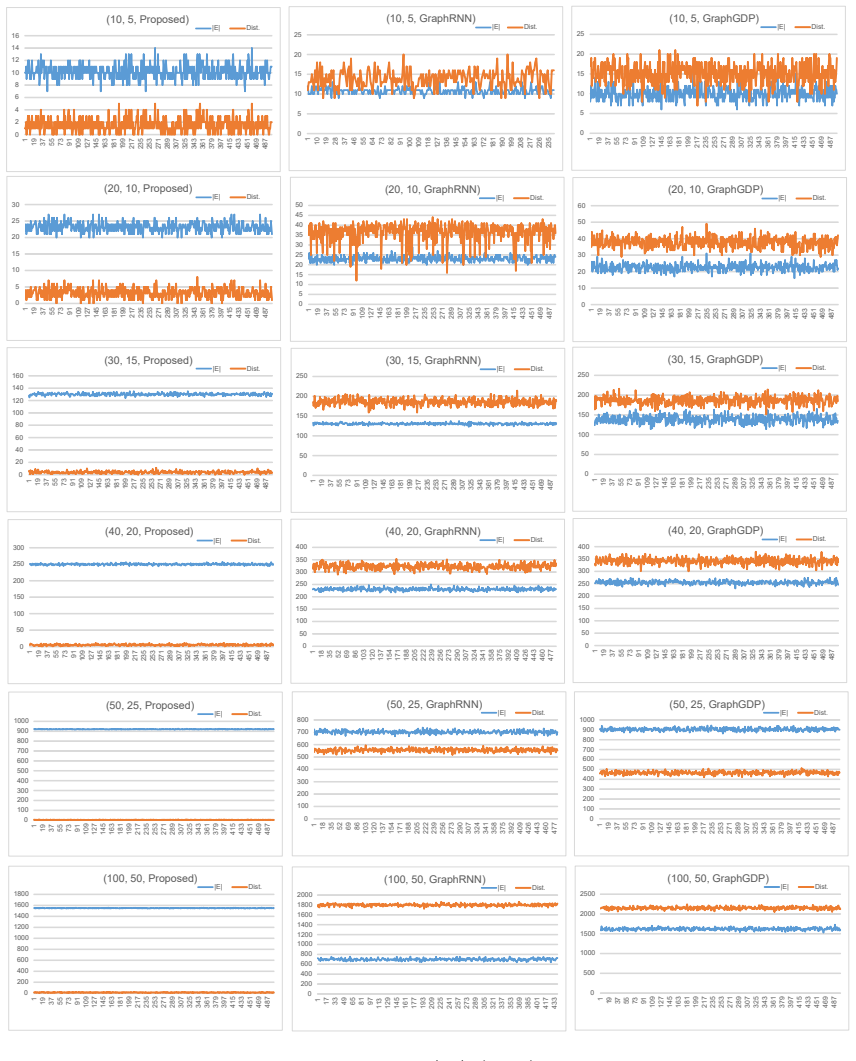
The authors show the existence of constant depth and O(n² d) size ReLU networks that deterministically generate graphs within edit distance d from a given input graph with n vertices, eliminating reliance on training data while guaranteeing validity of the generated graphs. The networks are constructed so that every output is a simple undirected graph differing from the input by at most d edits. Experimental checks confirm that the networks succeed on instances up to 1400 vertices where data-driven baselines cannot produce graphs obeying the distance limit.
What carries the argument
A ReLU network whose layers encode all combinations of up to d edge additions and deletions through threshold activations on the adjacency representation of the input graph.
If this is right
- The networks produce only valid graphs and require no training data or sampling.
- They remain compact enough to build for n up to at least 1400 and d up to 140.
- Data-driven generators are shown to violate the distance bound on the same test cases.
- The construction supplies a provable foundation for exact constrained graph augmentation.
Where Pith is reading between the lines
- The same encoding technique might extend to other edit operations such as vertex relabeling if the distance definition is adjusted accordingly.
- For applications that need only a subset of the d-neighborhood, smaller or shallower sub-networks could be extracted from the full construction.
- The O(n²d) size bound gives a concrete target for hardware implementations that must generate similar graphs on the fly.
Load-bearing premise
The input must be a simple undirected graph on exactly n vertices and graph edit distance must be the standard count of edge insertions plus deletions.
What would settle it
An explicit small n and d where the constructed network misses at least one graph that differs from the input by exactly d edge operations.
Figures





read the original abstract
Generation of graphs constrained by a specified graph edit distance from a source graph is important in applications such as cheminformatics, network anomaly synthesis, and structured data augmentation. Despite the growing demand for such constrained generative models in areas including molecule design and network perturbation analysis, the neural architectures required to provably generate graphs within a bounded graph edit distance remain largely unexplored. In addition, existing graph generative models are predominantly data-driven and depend heavily on the availability and quality of training data, which may result in generated graphs that do not satisfy the desired edit distance constraints. In this paper, we address these challenges by theoretically characterizing ReLU neural networks capable of generating graphs within a prescribed graph edit distance from a given graph. In particular, we show the existence of constant depth and O(n^2 d) size ReLU networks that deterministically generate graphs within edit distance d from a given input graph with n vertices, eliminating reliance on training data while guaranteeing validity of the generated graphs. Experimental evaluations demonstrate that the proposed network successfully generates valid graphs for instances with up to 1400 vertices and edit distance bounds up to 140, whereas baseline generative models fail to generate graphs with the desired edit distance. These results provide a theoretical foundation for constructing compact generative models with guaranteed validity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to prove the existence of constant-depth ReLU networks of size O(n²d) that, given any n-vertex input graph, deterministically output a valid simple undirected graph at edit distance at most d. The networks require no training data and guarantee validity (symmetry, zero diagonal). Experiments show the construction succeeds for n up to 1400 and d up to 140 while baselines fail to meet the distance constraint.
Significance. If the existence result and construction hold, the work supplies a training-free, provably valid mechanism for exact edit-distance-constrained graph generation. This is potentially valuable for applications such as molecular perturbation and network anomaly synthesis where invalid outputs must be avoided. The reported scaling to n=1400 provides concrete evidence that the O(n²d) bound is practically relevant when the network can be realized.
major comments (2)
- [§3] §3 (Network Construction): The central existence claim rests on an explicit ReLU construction that achieves constant depth and O(n²d) size while bounding edits by d and enforcing validity. The provided description does not include the layer-by-layer definitions, the encoding of the input adjacency matrix into the first layer, or the ReLU-based selection mechanism that applies at most d flips; without these, the depth and size bounds cannot be verified.
- [§4] §4 (Experiments): The empirical results for n=1400, d=140 are presented as validation of the theoretical construction, yet no implementation details (e.g., how the O(n²d) network is instantiated or whether the constant-depth property is preserved in code) are given. This leaves open whether the reported success actually realizes the claimed architecture or relies on a different, possibly deeper, realization.
minor comments (2)
- [§2] The notation for graph edit distance and the precise definition of 'size' (neurons vs. parameters) should be stated explicitly in §2 to avoid ambiguity with standard graph-generation literature.
- [Figure 1] Figure 1 (or equivalent architecture diagram) would benefit from labeling the constant number of layers and the O(n²d) scaling to make the depth claim visually immediate.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review of our manuscript. The comments highlight important areas where additional clarity will strengthen the presentation of both the theoretical construction and the experimental validation. We address each major comment below and indicate the specific revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Network Construction): The central existence claim rests on an explicit ReLU construction that achieves constant depth and O(n²d) size while bounding edits by d and enforcing validity. The provided description does not include the layer-by-layer definitions, the encoding of the input adjacency matrix into the first layer, or the ReLU-based selection mechanism that applies at most d flips; without these, the depth and size bounds cannot be verified.
Authors: We agree that the current description of the construction in Section 3 is at a high level and does not supply the explicit layer-by-layer definitions needed for independent verification. In the revised manuscript we will expand Section 3 with the complete specification: (i) the precise encoding of the n×n adjacency matrix as the network input vector, (ii) the fixed sequence of linear transformations and ReLU activations that realize the constant-depth architecture, and (iii) the ReLU-based selection logic that identifies and applies at most d valid edge flips while enforcing symmetry and zero diagonal. These additions will make the O(n²d) size bound and constant depth (independent of both n and d) directly verifiable from the layer definitions. revision: yes
-
Referee: [§4] §4 (Experiments): The empirical results for n=1400, d=140 are presented as validation of the theoretical construction, yet no implementation details (e.g., how the O(n²d) network is instantiated or whether the constant-depth property is preserved in code) are given. This leaves open whether the reported success actually realizes the claimed architecture or relies on a different, possibly deeper, realization.
Authors: We concur that the experimental section currently lacks sufficient implementation detail to confirm that the reported runs instantiate the exact constant-depth construction. In the revised version we will add a dedicated implementation subsection that (i) describes how the theoretical layers are realized via efficient matrix operations, (ii) states the exact depth used in code, and (iii) explains why this depth remains constant even for the largest tested instances (n=1400). This will demonstrate that the empirical success directly corresponds to the claimed architecture rather than an alternative, deeper network. revision: yes
Circularity Check
Existence proof via explicit ReLU network construction is self-contained with no circular reduction
full rationale
The paper's central claim is an existence result obtained by direct construction of constant-depth ReLU networks of size O(n²d) that map an input n-vertex graph to an output graph differing in at most d edge positions while preserving validity. This construction is derived from the standard definition of graph edit distance on simple undirected graphs and does not rely on parameter fitting to data, self-referential definitions, or load-bearing self-citations. No equations or steps in the abstract reduce the claimed network properties back to the input by construction; the result is presented as independent of training data and externally verifiable via the explicit architecture. Experimental sections are separate from the theoretical existence argument and do not affect the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Graph edit distance is defined in the conventional way allowing vertex and edge insertions, deletions, and substitutions.
Reference graph
Works this paper leans on
-
[1]
C. H. Wan, S. P. Chuang, and H. Y. Lee. Towards audio-to-scene image synthesis using generative adversarial network. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2019
2019
-
[2]
WaveNet: A Generative Model for Raw Audio
A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu. Wavenet: A generative model for raw audio.arXiv Preprint arXiv:1609.03499, 2016
work page internal anchor Pith review arXiv 2016
-
[3]
Aldausari, A
N. Aldausari, A. Sowmya, N. Marcus, and G. Mohammadi. Video generative adversarial networks: A review.ACM Computing Surveys, 55:1–25, 2022
2022
-
[4]
N. Killoran, L. J. Lee, A. Delong, D. Duvenaud, and B. J. Frey. Generating and designing dna with deep generative models.arXiv Preprint arXiv:1712.06148, 2017
-
[5]
Buschmann and L
T. Buschmann and L. V. Bystrykh. Levenshtein error-correcting barcodes for multiplexed dna sequencing.BMC Bioinformatics, 14:1–10, 2013
2013
-
[6]
Al Kindhi, M
B. Al Kindhi, M. A. Hendrawan, D. Purwitasari, T. A. Sardjono, and M. H. Purnomo. Distance-based pattern matching of dna sequences for evaluating primary mutation. InProceedings of the 2017 Second International Conference on Information Technology, Information Systems and Electrical Engineering, pages 310–314, 2017
2017
-
[7]
Hinton, L
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. R. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, and B. Kingsbury. Deep neural net- works for acoustic modeling in speech recognition: The shared views of four research groups.IEEE Signal Processing Magazine, 29:82–97, 2012. 41
2012
-
[8]
Zhou and O
J. Zhou and O. Troyanskaya. Deep supervised and convolutional generative stochastic network for protein secondary structure prediction. InProceedings of the International Conference on Machine Learning, 2014
2014
-
[9]
J. Lim, S. Ryu, J. W. Kim, and W. Y. Kim. Molecular generative model based on conditional variational autoencoder for de novo molecular design.Journal of Cheminformatics, 10:1–9, 2018
2018
-
[10]
Schwalbe-Koda and R
D. Schwalbe-Koda and R. G´ omez-Bombarelli. Generative models for automatic chemical design. InMachine Learning Meets Quantum Physics, pages 445–467. 2020
2020
-
[11]
C. H. Gronbech, M. F. Vording, P. N. Timshel, C. K. Sonderby, T. H. Pers, and O. Winther. scvae: Variational auto-encoders for single-cell gene expression data.Bioinformatics, 36:4415–4422, 2020
2020
-
[12]
D. P. Kingma and M. Welling. An introduction to variational autoencoders. Foundations and Trends in Machine Learning, 12:307–392, 2019
2019
-
[13]
Bengio, L
Y. Bengio, L. Yao, G. Alain, and P. Vincent. Generalized denoising auto- encoders as generative models. InAdvances in Neural Information Processing Systems, volume 26, 2013
2013
-
[14]
Goodfellow, J
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial networks.Communications of the ACM, 63:139–144, 2020
2020
-
[15]
F. Gao, Y. Yang, J. Wang, J. Sun, E. Yang, and H. Zhou. A deep convolu- tional generative adversarial networks-based semi-supervised method for object recognition in synthetic aperture radar images.Remote Sensing, 10:846, 2018
2018
-
[16]
Hinton and R
G. Hinton and R. Salakhutdinov. Deep boltzmann machines. InJournal of Machine Learning Research Workshop and Conference Proceedings, 2009
2009
-
[17]
Van Den Oord
A. Van Den Oord. Conditional image generation with pixelcnn decoders. In Advances in Neural Information Processing Systems, volume 29, 2016. 42
2016
-
[18]
Van Den Oord, N
A. Van Den Oord, N. Kalchbrenner, and K. Kavukcuoglu. Pixel recurrent neural networks. InProceedings of the International Conference on Machine Learning, 2016
2016
-
[19]
Gregor, I
K. Gregor, I. Danihelka, A. Graves, D. Rezende, and D. Wierstra. Draw: A re- current neural network for image generation. InProceedings of the International Conference on Machine Learning, 2015
2015
-
[20]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InPro- ceedings of the Advances in Neural Information Processing Systems (NeurIPS), volume 33, pages 6840–6851, 2020
2020
-
[21]
L. Yang, Z. Zhang, Y. Song, S. Hong, R. Xu, Y. Zhao, W. Zhang, B. Cui, and M.-H. Yang. Diffusion models: A comprehensive survey of methods and applications.ACM Computing Surveys, 56:1–39, 2023
2023
-
[22]
Kumano and T
S. Kumano and T. Akutsu. Comparison of the representational power of random forests, binary decision diagrams, and neural networks.Neural Computation, 34:1019–1044, 2022
2022
-
[23]
Hornik, M
K. Hornik, M. Stinchcombe, and H. White. Multilayer feedforward networks are universal approximators.Neural Networks, 2:359–366, 1989
1989
-
[24]
G. F. Mont´ ufar, R. Pascanu, K. Cho, and Y. Bengio. On the number of linear regions of deep neural networks. InProceedings of Advances in Neural Informa- tion Processing Systems, volume 27, pages 1–9, 2014
2014
-
[25]
Raghu, B
M. Raghu, B. Poole, J. Kleinberg, S. Ganguli, and J. S. Dickstein. On the expressive power of deep neural networks. InProceedings of the International Conference on Machine Learning, volume 70, pages 2847–2854, 2017
2017
-
[26]
Representation Benefits of Deep Feedforward Networks
M. Telgarsky. Representation benefits of deep feedforward networks.arXiv Preprint arXiv:1509.08101, 2015
work page Pith review arXiv 2015
-
[27]
Szymanski and B
L. Szymanski and B. McCane. Deep networks are effective encoders of period- icity.IEEE Transactions on Neural Networks and Learning Systems, 25:1816– 1827, 2014. 43
2014
-
[28]
V. Chatziafratis, S. G. Nagarajan, I. Panageas, and X. Wang. Depth- width trade-offs for relu networks via sharkovsky’s theorem.arXiv Preprint arXiv:1912.04378, 2019
-
[29]
Hanin and D
B. Hanin and D. Rolnick. Complexity of linear regions in deep networks. In Proceedings of the International Conference on Machine Learning, pages 2596– 2604, 2019
2019
-
[30]
Bengio, O
Y. Bengio, O. Delalleau, and C. Simard. Decision trees do not generalize to new variations.Computational Intelligence, 26:449–467, 2010
2010
-
[31]
G. Biau, E. Scornet, and J. Welbl. Neural random forests.Sankhy¯ a: The Indian Journal of Statistics, Series A, 81:347–386, 2019
2019
-
[32]
Ghafoor and T
M. Ghafoor and T. Akutsu. On the generative power of relu network for gener- ating similar strings.IEEE Access, 12:52603–52622, 2024
2024
-
[33]
Sanfeliu and K
A. Sanfeliu and K. S. Fu. A distance measure between attributed relational graphs for pattern recognition.IEEE Transactions on Systems, Man, and Cy- bernetics, SMC-13:353–362, 1983
1983
-
[34]
X. Gao, B. Xiao, D. Tao, and X. Li. A survey of graph edit distance.Pattern Analysis and Applications, 13:113–129, 2010
2010
-
[35]
Ibragimov, M
R. Ibragimov, M. Malek, J. Guo, and J. Baumbach. Gedevo: An evolutionary graph edit distance algorithm for biological network alignment. InGerman Conference on Bioinformatics, pages 68–79, 2013
2013
-
[36]
Riesen, M
K. Riesen, M. Ferrer, R. Dornberger, and H. Bunke. Greedy graph edit distance. InInternational Workshop on Machine Learning and Data Mining in Pattern Recognition, pages 3–16. Springer, 2015
2015
-
[37]
Z. Zeng, A. K. Tung, J. Wang, J. Feng, and L. Zhou. Comparing stars: On approximating graph edit distance.Proceedings of the VLDB Endowment, 2:25– 36, 2009. 44
2009
-
[38]
Learning shape correspondence with anisotropic convolutional neural networks
S. Bougleux, L. Brun, V. Carletti, P. Foggia, B. Ga¨ uzere, and M. Vento. A quadratic assignment formulation of the graph edit distance.arXiv Preprint arXiv:1512.07494, 2015
-
[39]
Y. Bai, H. Ding, K. Gu, Y. Sun, and W. Wang. Learning-based efficient graph similarity computation via multi-scale convolutional set matching. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 34, pages 3219– 3226, 2020
2020
- [40]
-
[41]
J. You, R. Ying, X. Ren, W. Hamilton, and J. Leskovec. Graphrnn: Generating realistic graphs with deep auto-regressive models. InProceedings of the 35th International Conference on Machine Learning, pages 5708–5717, 2018
2018
- [42]
- [43]
-
[44]
Huang, L
H. Huang, L. Sun, B. Du, Y. Fu, and W. Lv. Graphgdp: Generative diffusion processes for permutation invariant graph generation. InProceedings of the 2022 IEEE International Conference on Data Mining (ICDM), pages 201–210, 2022
2022
- [45]
-
[46]
Madeira, C
M. Madeira, C. Vignac, D. Thanou, and P. Frossard. Generative modelling of structurally constrained graphs. InProceedings of the 38th Conference on Neural Information Processing Systems, pages 137218–137262, 2024
2024
- [47]
-
[48]
A. Bommakanti, H. R. Vonteri, S. Ranu, and P. Karras. Eugene: Explainable unsupervised approximation of graph edit distance with generalized edit costs. arXiv Preprint arXiv:2402.05885, 2024
-
[49]
M. Ghafoor and T. Akutsu. Designing relu generative networks to enumerate trees with a given tree edit distance.arXiv Preprint arXiv:2510.10706, 2025. DOI: 10.48550/arXiv.2510.10706
-
[50]
Approximate graph edit distance computation by means of bipartite graph matching.Image and Vision Computing, 27(7):950– 959, June 2009
Kaspar Riesen and Horst Bunke. Approximate graph edit distance computation by means of bipartite graph matching.Image and Vision Computing, 27(7):950– 959, June 2009
2009
-
[51]
Graph edit distance as a quadratic assignment problem.Pattern Recognition Letters, 87:38–46, 2017
S´ ebastien Bougleux, Luc Brun, Vincenzo Carletti, Pasquale Foggia, Benoit Ga¨ uz` ere, and Mario Vento. Graph edit distance as a quadratic assignment problem.Pattern Recognition Letters, 87:38–46, 2017
2017
-
[52]
The edit distance function and symmetrization.The Electronic Journal of Combinatorics, 20(3):P26, 2013
Ryan Martin. The edit distance function and symmetrization.The Electronic Journal of Combinatorics, 20(3):P26, 2013. 46
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.