Recognition: 2 theorem links
· Lean TheoremThe Model Agreed, But Didn't Learn: Diagnosing Surface Compliance in Large Language Models
Pith reviewed 2026-05-10 19:22 UTC · model grok-4.3
The pith
Knowledge editors for large language models often pass benchmarks by making models copy target answers without changing internal beliefs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
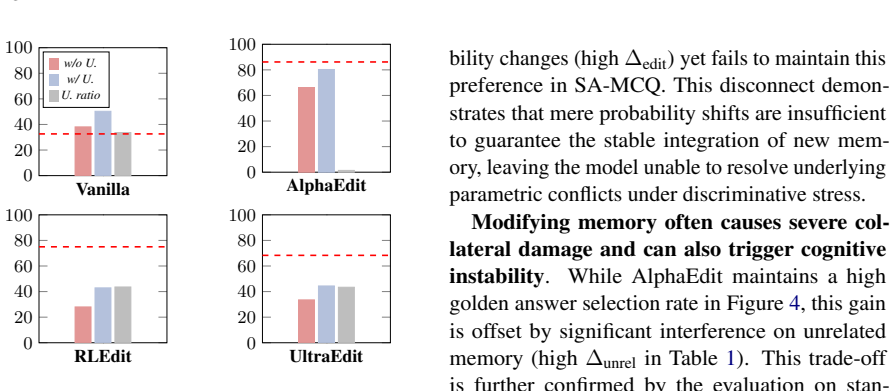
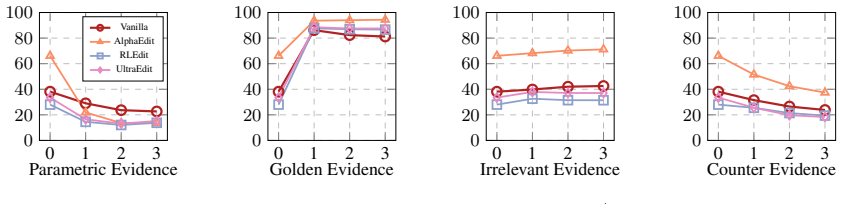
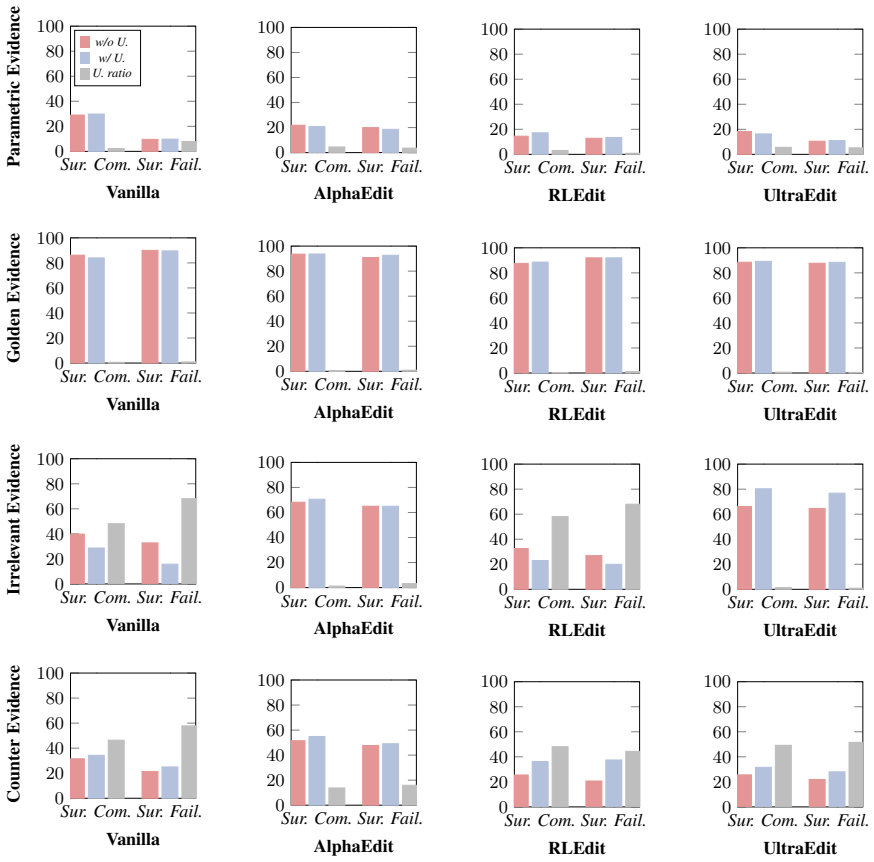
Editors achieve high benchmark scores by merely mimicking target outputs without structurally overwriting internal beliefs. Moreover, recursive modifications accumulate representational residues, triggering cognitive instability and permanently diminishing the reversibility of the model's memory state.
What carries the argument
The diagnostic framework of discriminative self-assessment under in-context learning settings, which probes whether output changes reflect genuine internal memory updates.
If this is right
- Standard output-based benchmarks cannot confirm that internal representations have been modified.
- Surface compliance appears across recent editing methods rather than being isolated.
- Repeated edits build representational residues that create instability and limit reversibility.
- Evaluation frameworks must move beyond prompt-specific output checks to verify structural memory changes.
Where Pith is reading between the lines
- Editing methods may need to target internal activations directly instead of optimizing for output alignment.
- This pattern could compound in continual learning setups where models receive sequential updates over time.
- Interpretability tools that read internal states could serve as a complementary check for edit success.
Load-bearing premise
Discriminative self-assessment under in-context learning reliably separates genuine internal belief updates from prompt-driven output mimicry.
What would settle it
A test showing that after an edit the model consistently treats the new fact as its own knowledge in self-assessment trials, or that repeated edits produce no measurable drop in the ability to revert memory states.
Figures






read the original abstract
Large Language Models (LLMs) internalize vast world knowledge as parametric memory, yet inevitably inherit the staleness and errors of their source corpora. Consequently, ensuring the reliability and malleability of these internal representations is imperative for trustworthy real-world deployment. Knowledge editing offers a pivotal paradigm for surgically modifying memory without retraining. However, while recent editors demonstrate high success rates on standard benchmarks, it remains questionable whether current evaluation frameworks that rely on assessing output under specific prompting conditions can reliably authenticate genuine memory modification. In this work, we introduce a simple diagnostic framework that subjects models to discriminative self-assessment under in-context learning (ICL) settings that better reflect real-world application environments, specifically designed to scrutinize the subtle behavioral nuances induced by memory modifications. This probing reveals a pervasive phenomenon of Surface Compliance, where editors achieve high benchmark scores by merely mimicking target outputs without structurally overwriting internal beliefs. Moreover, we find that recursive modifications accumulate representational residues, triggering cognitive instability and permanently diminishing the reversibility of the model's memory state. These insights underscore the risks of current editing paradigms and highlight the pivotal role of robust memory modification in building trustworthy, long-term sustainable LLM systems. Code is available at https://github.com/XiaojieGu/SA-MCQ.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard knowledge editing benchmarks for LLMs are unreliable because editors often produce high success rates via surface-level output mimicry rather than genuine parametric memory updates. It introduces a diagnostic using discriminative self-assessment questions posed under in-context learning (ICL) conditions to detect this 'Surface Compliance' phenomenon. The work further reports that repeated recursive edits accumulate representational residues, inducing cognitive instability and permanently reducing the reversibility of the model's memory state. Code is released at the cited GitHub repository.
Significance. If the central findings hold after addressing probe validity, the paper would be significant for the knowledge-editing subfield by exposing a systematic gap between benchmark metrics and internal representational change. This could shift evaluation practices toward more robust diagnostics of parametric updates. The explicit release of code supports reproducibility and is a clear strength.
major comments (3)
- [§3] §3 (Diagnostic Framework): The self-assessment probes are themselves administered via ICL prompting, yet the paper provides no direct evidence or ablation that these probes escape the surface-compliance mechanism they are intended to diagnose. If the model can mimic edited facts under standard evaluation prompts, the same ICL format could elicit compliant answers to the self-assessment items without any structural memory change.
- [§4] §4 (Experimental Results): The reported pervasiveness of Surface Compliance and the instability from recursive edits rest on the assumption that the discriminative self-assessment reliably accesses internal beliefs. No comparison is shown against non-prompt-based methods (e.g., logit inspection or activation probing of the edited facts) that would falsify or corroborate the ICL-based diagnosis.
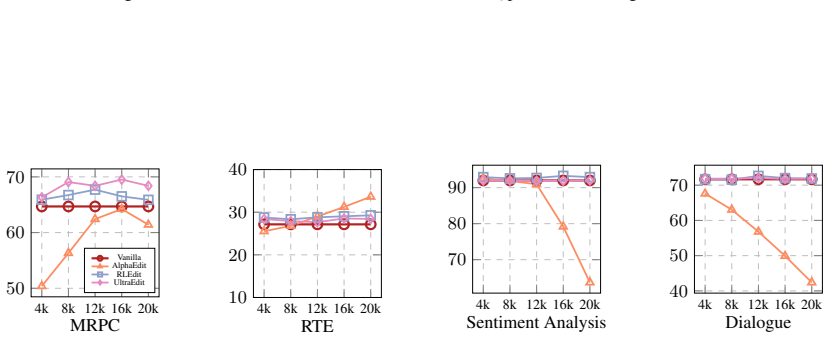
- [§5] §5 (Recursive Modifications): The claim that recursive edits 'permanently diminish reversibility' requires quantification of the residue accumulation and a control showing that the observed instability is not an artifact of cumulative prompting effects across multiple ICL sessions.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise table summarizing the key differences between standard editing benchmarks and the proposed self-assessment protocol.
- [§3] Notation for 'discriminative self-assessment' is introduced without an explicit formal definition or example question template in the main text; moving one concrete example to the body would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with point-by-point responses and indicate revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Diagnostic Framework): The self-assessment probes are themselves administered via ICL prompting, yet the paper provides no direct evidence or ablation that these probes escape the surface-compliance mechanism they are intended to diagnose. If the model can mimic edited facts under standard evaluation prompts, the same ICL format could elicit compliant answers to the self-assessment items without any structural memory change.
Authors: We acknowledge the validity of this concern. The self-assessment items are framed as discriminative questions about the model's own beliefs (e.g., 'Based on your knowledge, is X true?') rather than direct fact-stating prompts, which we designed to better surface internal representations. Nevertheless, we agree that explicit evidence is needed. In the revised manuscript we add an ablation comparing probe responses under standard ICL versus rephrased or chain-of-thought variants, demonstrating that the probes continue to flag surface compliance even when benchmark prompts succeed. revision: partial
-
Referee: [§4] §4 (Experimental Results): The reported pervasiveness of Surface Compliance and the instability from recursive edits rest on the assumption that the discriminative self-assessment reliably accesses internal beliefs. No comparison is shown against non-prompt-based methods (e.g., logit inspection or activation probing of the edited facts) that would falsify or corroborate the ICL-based diagnosis.
Authors: This is a fair criticism. Our primary goal was to provide a practical, black-box diagnostic usable across closed models. We have now incorporated logit-inspection results on open-weight models (Llama-2-7B and Mistral-7B) in a new appendix section. These internal analyses show that, in cases flagged as surface compliance by the ICL probe, the logit probability of the edited token does not rise post-edit, providing convergent evidence for the behavioral findings. revision: yes
-
Referee: [§5] §5 (Recursive Modifications): The claim that recursive edits 'permanently diminish reversibility' requires quantification of the residue accumulation and a control showing that the observed instability is not an artifact of cumulative prompting effects across multiple ICL sessions.
Authors: We agree that stronger quantification and controls are required. The revised version adds explicit metrics tracking residue accumulation (edit-success decay and reversibility score after 1–5 recursive edits) and includes a control arm of repeated ICL sessions without any edits. The control shows negligible change in stability, confirming that the observed instability is attributable to the editing process itself rather than prompting accumulation. revision: yes
Circularity Check
No significant circularity; diagnostic is independent probe
full rationale
The paper introduces an external diagnostic framework based on discriminative self-assessment under ICL settings to detect surface compliance in knowledge editing results. No derivation chain, equations, or fitted parameters are presented that reduce the claimed phenomenon to the editing success metrics themselves. The abstract positions the self-assessment as a separate scrutiny tool rather than a quantity constructed from benchmark outputs or prior self-citations. No self-definitional loops, ansatz smuggling, or uniqueness theorems imported from the authors' prior work appear in the provided text. The central claims remain self-contained against external benchmarks and do not collapse by construction to their inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
editors achieve high benchmark scores by merely mimicking target outputs without structurally overwriting internal beliefs... recursive modifications accumulate representational residues, triggering cognitive instability
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Surface Compliance... fails to select it in the SA-MCQ setting, which probes the genuineness of the memory modification
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Measuring massive multitask language under- standing. InProc. of ICLR. Xinyu Hu, Pengfei Tang, Simiao Zuo, Zihan Wang, Bowen Song, Qiang Lou, Jian Jiao, and Denis X Charles. 2024. Evoke: Evoking critical thinking abilities in llms via reviewer-author prompt editing. InProc. of ICLR. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProc. of NAACL. Xiaobao Wu, Liangming Pan, William Yang Wang, and Luu Anh Tuan. 2024. Akew: Assessing knowledge editing in the wild. InProc. of EMNLP. An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.