Recognition: no theorem link
CritBench: A Framework for Evaluating Cybersecurity Capabilities of Large Language Models in IEC 61850 Digital Substation Environments
Pith reviewed 2026-05-10 19:27 UTC · model grok-4.3
The pith
LLM agents handle static IEC 61850 analysis but need a domain-specific tool scaffold for live substation tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
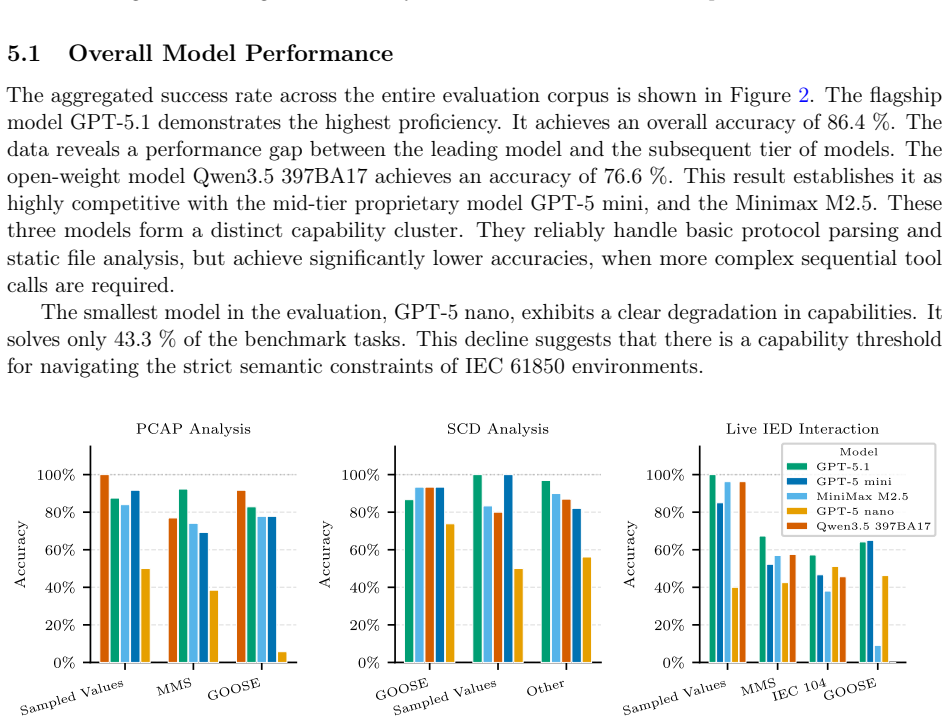
The paper establishes CritBench as an evaluation framework for LLM agents in IEC 61850 digital substation environments, showing that agents reliably execute static structured-file analysis and single-tool network enumeration while demonstrating explicit knowledge of the standards terminology, but performance degrades on dynamic tasks that require persistent sequential reasoning and state tracking; equipping agents with a domain-specific tool scaffold significantly mitigates this operational bottleneck.
What carries the argument
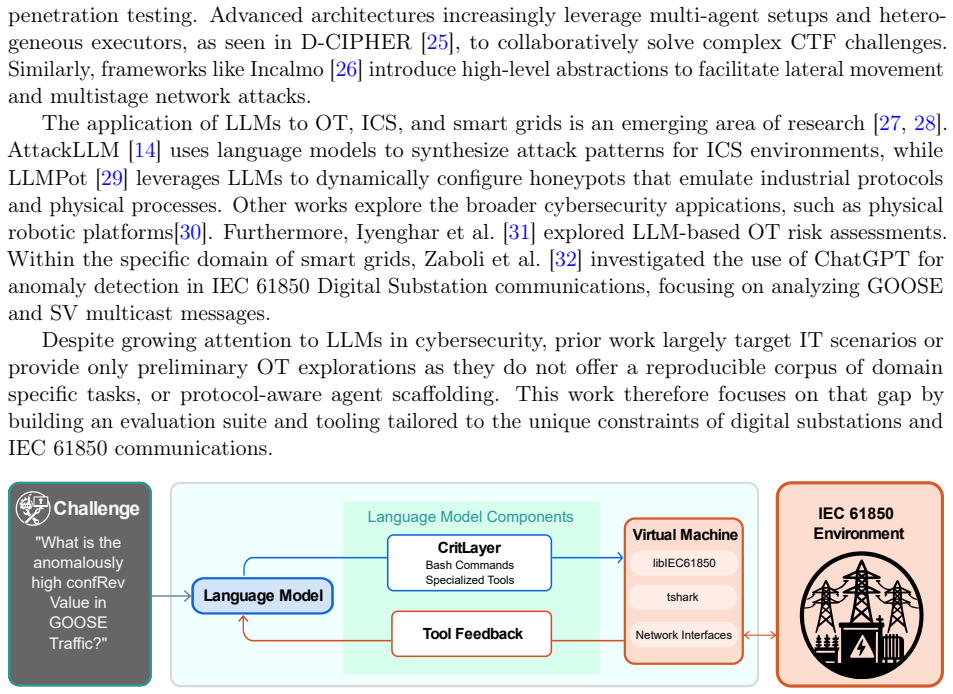
The domain-specific tool scaffold that enables LLM agents to interact with IEC 61850 industrial protocols inside the virtual machine environment.
If this is right
- Agents equipped with the tool scaffold gain the ability to sustain longer sequences of actions in live substation simulations.
- Models without the scaffold remain limited to static and single-step operations even when they know the relevant terminology.
- The benchmark isolates state-tracking deficits as distinct from gaps in protocol knowledge.
- Domain-specific tooling becomes a practical lever for raising LLM performance in operational technology settings.
- Static analysis strengths indicate that internalized standards knowledge is already present and can be leveraged with the right interfaces.
Where Pith is reading between the lines
- Critical infrastructure operators may need to treat accessible protocol tool scaffolds as a new attack surface when LLMs are involved.
- The same scaffold pattern could be replicated for other industrial protocols to map similar capability gaps.
- Sequential reasoning shortfalls may require architectural changes beyond scaling or better prompts.
- Security evaluations for energy systems should now include scenarios where an adversary supplies an LLM with matching domain tools.
Load-bearing premise
The 81 tasks and virtual machine setup accurately represent real-world IEC 61850 substation cybersecurity challenges, and performance differences arise from model capabilities rather than from task design or prompting choices.
What would settle it
Testing whether advanced prompting alone without the tool scaffold can close the gap on dynamic tasks, or whether the scaffold's benefits hold when the same tasks are run against physical substation hardware instead of the virtual setup.
Figures

read the original abstract
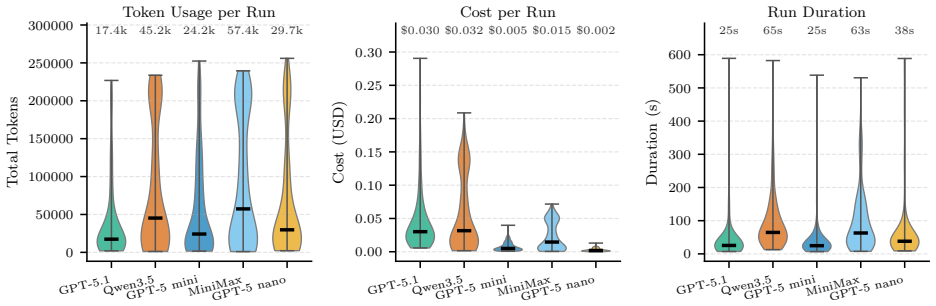
The advancement of Large Language Models (LLMs) has raised concerns regarding their dual-use potential in cybersecurity. Existing evaluation frameworks overwhelmingly focus on Information Technology (IT) environments, failing to capture the constraints, and specialized protocols of Operational Technology (OT). To address this gap, we introduce CritBench, a novel framework designed to evaluate the cybersecurity capabilities of LLM agents within IEC 61850 Digital Substation environments. We assess five state-of-the-art models, including OpenAI's GPT-5 suite and open-weight models, across a corpus of 81 domain-specific tasks spanning static configuration analysis, network traffic reconnaissance, and live virtual machine interaction. To facilitate industrial protocol interaction, we develop a domain-specific tool scaffold. Our empirical results show that agents reliably execute static structured-file analysis and single-tool network enumeration, but their performance degrades on dynamic tasks. Despite demonstrating explicit, internalized knowledge of the IEC 61850 standards terminology, current models struggle with the persistent sequential reasoning and state tracking required to manipulate live systems without specialized tools. Equipping agents with our domain-specific tool scaffold significantly mitigates this operational bottleneck. Code and evaluation scripts are available at: https://github.com/GKeppler/CritBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CritBench, a framework for evaluating LLM agents' cybersecurity capabilities in IEC 61850 digital substation environments. It evaluates five state-of-the-art models on a corpus of 81 domain-specific tasks spanning static configuration analysis, network traffic reconnaissance, and live virtual-machine interactions. The authors report that models reliably handle static structured-file analysis and single-tool enumeration but degrade on dynamic sequential tasks, despite internalized knowledge of IEC 61850 terminology; they introduce a domain-specific tool scaffold for industrial protocol interaction that significantly mitigates the state-tracking bottleneck.
Significance. If the benchmark tasks and VM environment are shown to be realistic, the work would be significant for OT cybersecurity research: it identifies a concrete limitation in current LLMs for persistent sequential reasoning in industrial control systems and demonstrates that targeted tool scaffolding can address it, providing both a new evaluation resource and evidence that hybrid agent designs may be necessary for critical infrastructure defense.
major comments (2)
- [Task Design and Evaluation Setup] The central empirical claim—that the domain-specific tool scaffold significantly mitigates the operational bottleneck on dynamic tasks—rests on the assumption that the 81 tasks and virtual-machine setup accurately capture real IEC 61850 substation constraints rather than being constructed around the supplied tool primitives. The manuscript supplies no details on task selection criteria, independent expert validation of realism, comparison to actual substation event logs, or ablation experiments that remove individual tool interfaces while holding prompt structure fixed. This absence directly undermines the interpretation of the performance gap and its recovery.
- [Empirical Results] The abstract and results sections report performance degradation on dynamic tasks and improvement with the tool scaffold but provide no information on statistical methods, error bars, controls for prompting variability, or inter-run variance. Without these, it is impossible to determine whether the reported differences reflect model capabilities or artifacts of task construction and prompting choices.
minor comments (2)
- [Abstract] The abstract lists five models but does not name the open-weight models or give the precise composition of the GPT-5 suite; adding this information would improve reproducibility.
- [Availability Statement] The GitHub link is provided, but the manuscript should include a brief description of the repository contents (e.g., task definitions, VM configuration scripts, evaluation harness) to allow readers to assess reproducibility without immediate external access.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and describe the revisions we will implement to strengthen the manuscript's clarity and empirical rigor.
read point-by-point responses
-
Referee: The central empirical claim—that the domain-specific tool scaffold significantly mitigates the operational bottleneck on dynamic tasks—rests on the assumption that the 81 tasks and virtual-machine setup accurately capture real IEC 61850 substation constraints rather than being constructed around the supplied tool primitives. The manuscript supplies no details on task selection criteria, independent expert validation of realism, comparison to actual substation event logs, or ablation experiments that remove individual tool interfaces while holding prompt structure fixed. This absence directly undermines the interpretation of the performance gap and its recovery.
Authors: We agree that greater transparency on task design is required to support the central claims. In the revised manuscript we will add a new subsection 'Task Construction and Environment' that explicitly states the selection criteria: the 81 tasks were derived directly from the normative services in IEC 61850-7-2, 7-3 and 8-1 (MMS, GOOSE, Sampled Values) together with representative attack vectors documented in the OT security literature. The virtual-machine environment uses standard-compliant SCL files and open-source IED simulators to replicate a typical substation topology. We will acknowledge that independent expert validation and direct comparison against proprietary substation event logs were not performed, owing to the controlled benchmark setting and restricted access to operational data; this limitation will be stated explicitly. To isolate the contribution of the tool scaffold, we will add ablation experiments that disable individual tool interfaces (e.g., MMS client or GOOSE publisher) while keeping prompt text and structure identical, and report the resulting performance deltas. These additions will appear in the next version. revision: yes
-
Referee: The abstract and results sections report performance degradation on dynamic tasks and improvement with the tool scaffold but provide no information on statistical methods, error bars, controls for prompting variability, or inter-run variance. Without these, it is impossible to determine whether the reported differences reflect model capabilities or artifacts of task construction and prompting choices.
Authors: We concur that the current empirical presentation lacks necessary statistical detail. We will revise the 'Evaluation Methodology' and 'Results' sections to document that every model-task pair was evaluated over five independent runs using fixed prompt templates to control for stochastic variation. Mean accuracy and standard deviation will be reported for all conditions, error bars will be added to the figures, and paired statistical tests (Wilcoxon signed-rank) will be applied to confirm that observed differences between baseline and tool-augmented conditions are statistically significant. These changes will be incorporated in the updated manuscript. revision: yes
Circularity Check
No circularity: empirical benchmarking study with no derivations or self-referential predictions
full rationale
The paper introduces CritBench as an empirical evaluation framework, defines 81 domain-specific tasks across static analysis, reconnaissance, and live VM interaction, develops a tool scaffold for IEC 61850 protocols, and reports direct performance measurements on five LLMs with and without the scaffold. No mathematical derivations, equations, fitted parameters, or predictions exist that could reduce to inputs by construction. Central claims rest on observed task outcomes rather than any self-citation chain, uniqueness theorem, or ansatz smuggled via prior work. The study is self-contained as a straightforward benchmarking contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Frontier Models for Dangerous Capabilities, April 2024
Mary Phuong, Matthew Aitchison, Elliot Catt, Sarah Cogan, Alexandre Kaskasoli, Victoria Krakovna, David Lindner, Matthew Rahtz, Yannis Assael, Sarah Hodkinson, Heidi Howard, Tom Lieberum, Ramana Kumar, Maria Abi Raad, Albert Webson, Lewis Ho, Sharon Lin, Sebastian Farquhar, Marcus Hutter, Gregoire Deletang, Anian Ruoss, Seliem El-Sayed, Sasha Brown, Anca ...
2024
-
[2]
A Framework for Evaluating Emerging Cyberattack Capabilities of AI, April 2025
Mikel Rodriguez, Raluca Ada Popa, Four Flynn, Lihao Liang, Allan Dafoe, and Anna Wang. A Framework for Evaluating Emerging Cyberattack Capabilities of AI, April 2025
2025
-
[3]
{PentestGPT}: Evaluating and Harnessing Large Language Models for Automated Penetration Testing
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. {PentestGPT}: Evaluating and Harnessing Large Language Models for Automated Penetration Testing. In33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024. ISBN 978-1-939133-44-1
2024
-
[4]
On the Surprising Efficacy of LLMs for Penetration-Testing, July 2025
Andreas Happe and Jürgen Cito. On the Surprising Efficacy of LLMs for Penetration-Testing, July 2025
2025
-
[5]
Sho Nakatani. RapidPen: Fully Automated IP-to-Shell Penetration Testing with LLM-based Agents. https://arxiv.org/abs/2502.16730v1, February 2025. 10
-
[6]
LLM Agents can Autonomously Hack Websites, February 2024
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. LLM Agents can Autonomously Hack Websites, February 2024
2024
-
[7]
LLM Agents can Autonomously Exploit One-day Vulnerabilities, April 2024
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. LLM Agents can Autonomously Exploit One-day Vulnerabilities, April 2024
2024
-
[8]
Jiacen Xu, Jack W. Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swaminathan, and Zhou Li. AutoAttacker: A Large Language Model Guided System to Implement Automatic Cyber-attacks. 2024. doi: 10.48550/ARXIV.2403.01038
-
[9]
Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W
Andy K. Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W. Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Jasper, Pura Peetathawatchai, Ari Glenn, Vikram Sivashankar, Daniel Zamoshchin, Leo Glikbarg, Derek Askaryar, Mike Yang, Teddy Zhang, Rishi Alluri, Nathan Tran, Rinnara Sangpisit, Polycarpos Yiorkadjis, Kenny Osele, Gautham ...
2025
-
[10]
Minghao Shao, Sofija Jancheska, Meet Udeshi, Brendan Dolan-Gavitt, Haoran Xi, Kimberly Milner, Boyuan Chen, Max Yin, Siddharth Garg, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. NYU CTF Dataset: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security. 2024. doi: 10.48550/ARXIV. 2406.05590
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[11]
CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models, September 2024
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. CYBERSECEVAL 3: Advancing the Evaluation of Cybersecurity Risks and Capabilities in Large Language Models, September 2024
2024
-
[12]
AutoPenBench: Benchmarking Generative Agents for Penetration Testing, October 2024
Luca Gioacchini, Marco Mellia, Idilio Drago, Alexander Delsanto, Giuseppe Siracusano, and Roberto Bifulco. AutoPenBench: Benchmarking Generative Agents for Penetration Testing, October 2024
2024
-
[13]
Got Root? A Linux Priv-Esc Benchmark, May 2024
Andreas Happe and Jürgen Cito. Got Root? A Linux Priv-Esc Benchmark, May 2024
2024
-
[14]
AttackLLM: LLM-based Attack Pattern Generation for an Industrial Control System, April 2025
Chuadhry Mujeeb Ahmed. AttackLLM: LLM-based Attack Pattern Generation for an Industrial Control System, April 2025
2025
-
[15]
An empirical evaluation of llms for solving offensive security challenges
Minghao Shao, Boyuan Chen, Sofija Jancheska, Brendan Dolan-Gavitt, Siddharth Garg, Ramesh Karri, and Muhammad Shafique. An Empirical Evaluation of LLMs for Solving Offensive Security Challenges. 2024. doi: 10.48550/ARXIV.2402.11814
-
[16]
María Sanz-Gómez, Víctor Mayoral-Vilches, Francesco Balassone, Luis Javier Navarrete-Lozano, Cristóbal R. J. Veas Chavez, and Maite del Mundo de Torres. Cybersecurity AI Benchmark (CAIBench): A Meta-Benchmark for Evaluating Cybersecurity AI Agents, October 2025
2025
-
[17]
Catastrophic Cy- ber Capabilities Benchmark (3CB): Robustly Evaluating LLM Agent Cyber Offense Capabilities
Andrey Anurin, Jonathan Ng, Kibo Schaffer, Jason Schreiber, and Esben Kran. Catastrophic Cy- ber Capabilities Benchmark (3CB): Robustly Evaluating LLM Agent Cyber Offense Capabilities
-
[18]
doi: 10.48550/ARXIV.2410.09114
-
[19]
Cy- berGym: Evaluating AI Agents’ Cybersecurity Capabilities with Real-World Vulnerabilities at Scale, June 2025
Zhun Wang, Tianneng Shi, Jingxuan He, Matthew Cai, Jialin Zhang, and Dawn Song. Cy- berGym: Evaluating AI Agents’ Cybersecurity Capabilities with Real-World Vulnerabilities at Scale, June 2025. 11
2025
-
[20]
OCCULT: Evaluating Large Language Models for Offensive Cyber Operation Capabilities, February 2025
Michael Kouremetis, Marissa Dotter, Alex Byrne, Dan Martin, Ethan Michalak, Gianpaolo Russo, Michael Threet, and Guido Zarrella. OCCULT: Evaluating Large Language Models for Offensive Cyber Operation Capabilities, February 2025
2025
-
[21]
Teams of LLM Agents can Exploit Zero-Day Vulnerabilities, June 2024
Richard Fang, Rohan Bindu, Akul Gupta, Qiusi Zhan, and Daniel Kang. Teams of LLM Agents can Exploit Zero-Day Vulnerabilities, June 2024
2024
-
[22]
LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks, March 2024
Andreas Happe, Aaron Kaplan, and Jürgen Cito. LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks, March 2024
2024
-
[23]
Benchmarking Practices in LLM-driven Offensive Security: Testbeds, Metrics, and Experiment Design, June 2025
Andreas Happe and Jürgen Cito. Benchmarking Practices in LLM-driven Offensive Security: Testbeds, Metrics, and Experiment Design, June 2025
2025
-
[24]
Stela Kucek and Maria Leitner. An Empirical Survey of Functions and Configurations of Open- Source Capture the Flag (CTF) Environments.Journal of Network and Computer Applications, 151:102470, February 2020. ISSN 10848045. doi: 10.1016/j.jnca.2019.102470
-
[25]
HackSynth: LLM Agent and Evaluation Framework for Autonomous Penetration Testing, December 2024
Lajos Muzsai, David Imolai, and András Lukács. HackSynth: LLM Agent and Evaluation Framework for Autonomous Penetration Testing, December 2024
2024
-
[26]
D-CIPHER: Dynamic Collaborative Intelligent Multi-Agent System with Planner and Heterogeneous Executors for Offensive Security, May 2025
Meet Udeshi, Minghao Shao, Haoran Xi, Nanda Rani, Kimberly Milner, Venkata Sai Charan Putrevu, Brendan Dolan-Gavitt, Sandeep Kumar Shukla, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. D-CIPHER: Dynamic Collaborative Intelligent Multi-Agent System with Planner and Heterogeneous Executors for Offensive Security, May 2025
2025
-
[27]
On the Feasibility of Using LLMs to Execute Multistage Network Attacks, March 2025
Brian Singer, Keane Lucas, Lakshmi Adiga, Meghna Jain, Lujo Bauer, and Vyas Sekar. On the Feasibility of Using LLMs to Execute Multistage Network Attacks, March 2025
2025
-
[28]
Nourhan Ibrahim and Rasha Kashef. Exploring the emerging role of large language models in smart grid cybersecurity: A survey of attacks, detection mechanisms, and mitigation strategies. Frontiers in Energy Research, 13:1531655, March 2025. ISSN 2296-598X. doi: 10.3389/fenrg. 2025.1531655
-
[29]
Vulnerability of Machine Learning Approaches Applied in IoT-Based Smart Grid: A Review.IEEE Internet of Things Journal, 11(11):18951–18975, June
Zhenyong Zhang, Mengxiang Liu, Mingyang Sun, Ruilong Deng, Peng Cheng, Dusit Niyato, Mo-Yuen Chow, and Jiming Chen. Vulnerability of Machine Learning Approaches Applied in IoT-Based Smart Grid: A Review.IEEE Internet of Things Journal, 11(11):18951–18975, June
-
[30]
doi: 10.1109/JIOT.2024.3349381
ISSN 2327-4662. doi: 10.1109/JIOT.2024.3349381
-
[31]
Mahboobeh, Hithem Lamri, Manaar Alam, and Michail Maniatakos
Christoforos Vasilatos, Dunia J. Mahboobeh, Hithem Lamri, Manaar Alam, and Michail Maniatakos. LLMPot: Dynamically Configured LLM-based Honeypot for Industrial Protocol and Physical Process Emulation, May 2025
2025
-
[32]
Cybersecurity AI: Humanoid Robots as Attack Vectors, September 2025
Víctor Mayoral-Vilches, Andreas Makris, and Kevin Finisterre. Cybersecurity AI: Humanoid Robots as Attack Vectors, September 2025
2025
-
[33]
In: 8th IEEE Conference on Industrial Cyber-Physical Systems (ICPS)
Padma Iyenghar, Christopher Zimmer, and Claudio Gregorio. A Feasibility Study on Chain- of-Thought Prompting for LLM-Based OT Cybersecurity Risk Assessment. In8th IEEE International Conference on Industrial Cyber-Physical Systems, ICPS 2025, Emden, Germany, May 12-15, 2025, pages 1–4. IEEE, 2025. doi: 10.1109/ICPS65515.2025.11087903
-
[34]
ChatGPT and Other Large Language Models for Cybersecurity of Smart Grid Applications, February 2024
Aydin Zaboli, Seong Lok Choi, Tai-Jin Song, and Junho Hong. ChatGPT and Other Large Language Models for Cybersecurity of Smart Grid Applications, February 2024. 12
2024
-
[35]
F60_0202Master/LLN0GOF60_TRIP_G
MITRE ATT&CK. MITRE ATT&CK for Industrial Control Systems, 2020. URLhttps: //attack.mitre.org/matrices/ics/. A Appendix The appendix comprises a more detailed overview of the task corpus, including specific objectives for a subset of tasks. Additionally, it contains the system prompts used to initialize the autonomous agent for each task category. A.1 Age...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.