Recognition: no theorem link
Target Policy Optimization
Pith reviewed 2026-05-10 19:16 UTC · model grok-4.3
The pith
Target Policy Optimization separates deciding which completions to favor from how parameters should update by building an explicit target distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given scored completions sampled from an old policy, TPO constructs a target distribution q_i proportional to p_i^old times exp(u_i) and fits the current policy to q via cross-entropy minimization. This produces a loss gradient of p^theta minus q on the sampled logits that vanishes automatically upon matching the target, thereby separating the choice of favored completions from the mechanics of the parameter update.
What carries the argument
The target distribution q_i ∝ p_i^old exp(u_i) together with cross-entropy fitting of the policy to q, yielding gradient p^theta - q.
If this is right
- The update direction becomes independent of specific learning-rate or clipping choices that normally control overshoot.
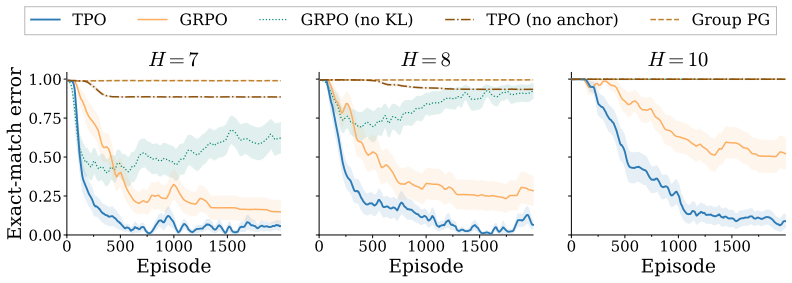
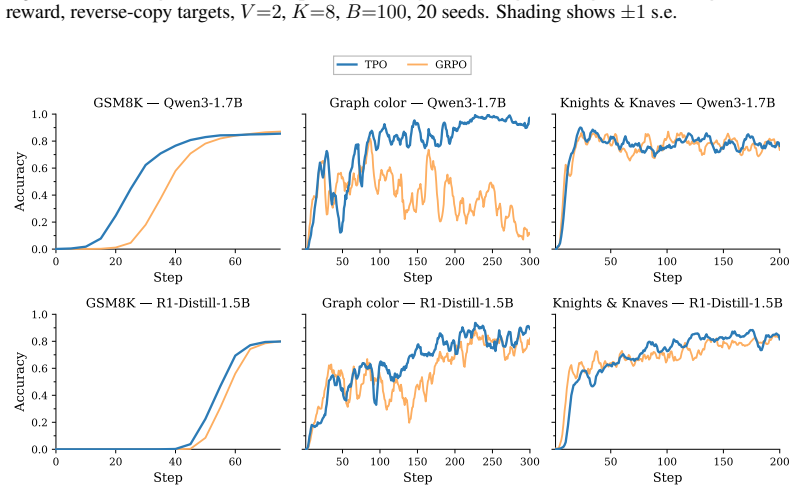
- Performance gains appear specifically under sparse reward conditions across tabular, sequence, and billion-parameter settings.
- The loss reaches zero naturally once the policy probabilities align with the constructed target.
- The same construction and fitting procedure works without modification from small bandits to large language model RLVR.
Where Pith is reading between the lines
- The explicit target may reduce the need for variance-reduction baselines or advantage normalization in other RL algorithms.
- Because the target mixes old policy mass with utility, TPO could be adapted to incorporate offline data or human preferences more directly.
- In generative modeling, repeated application might produce policies whose output distributions more closely track desired utility landscapes without iterative clipping.
Load-bearing premise
That constructing the target from the old policy and utilities and then fitting via cross-entropy produces more stable or higher-performing updates than standard policy-gradient methods, particularly when rewards are sparse.
What would settle it
A controlled experiment in which TPO fails to match or exceed the performance of PG, PPO, GRPO, or DG on a sparse-reward task while the constructed target remains well-defined.
Figures
















read the original abstract
In RL, given a prompt, we sample a group of completions from a model and score them. Two questions follow: which completions should gain probability mass, and how should the parameters move to realize that change? Standard policy-gradient methods answer both at once, so the update can overshoot or undershoot depending on the learning rate, clipping, and other optimizer choices. We introduce \emph{Target Policy Optimization} (TPO), which separates the two questions. Given scored completions, TPO constructs a target distribution $q_i \propto p_i^{\,\mathrm{old}} \exp(u_i)$ and fits the policy to it by cross-entropy. The loss gradient on sampled-completion logits is $p^\theta - q$, which vanishes once the policy matches the target. On tabular bandits, transformer sequence tasks, and billion-parameter LLM RLVR, TPO matches PG, PPO, GRPO, and DG on easy tasks and substantially outperforms them under sparse reward. Code is available at https://github.com/JeanKaddour/tpo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Target Policy Optimization (TPO) for reinforcement learning. Given a prompt and a group of scored completions, TPO constructs a target distribution q_i ∝ p_i^old exp(u_i) from the previous policy and utilities, then fits the current policy to q via cross-entropy loss. The resulting gradient on the sampled-completion logits is p^θ - q and vanishes when the policy matches the target. Empirical evaluations on tabular bandits, transformer sequence tasks, and billion-parameter LLM RLVR show TPO matching PG, PPO, GRPO, and DG on easy tasks while substantially outperforming them under sparse rewards. Code is provided for reproducibility.
Significance. If the results hold, TPO offers a clean separation between target construction and parameter updates that yields a well-defined, vanishing gradient at match. This could improve stability and performance in sparse-reward settings common to LLM alignment and RLVR. The open-source code is a clear strength that supports verification and extension.
major comments (2)
- [Abstract] Abstract: the claim of substantial outperformance under sparse reward is presented without any quantitative results, number of runs, error bars, or statistical tests, which is load-bearing for assessing whether the observed gains are reliable or merely anecdotal.
- [Method] Method description: the gradient statement 'p^θ - q' on sampled-completion logits assumes a softmax over the group and no additional normalization; the manuscript should derive this explicitly (including how group normalization interacts with the proportionality in q) to confirm it does not introduce new instabilities.
minor comments (2)
- [Abstract] Notation: p_i^old is written with a superscript in one place and subscript in another; consistent subscript notation would improve readability.
- [Introduction] The manuscript should add a short paragraph contrasting TPO with KL-regularized methods to clarify whether the target q implicitly encodes a similar regularizer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below and will incorporate the suggested changes to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of substantial outperformance under sparse reward is presented without any quantitative results, number of runs, error bars, or statistical tests, which is load-bearing for assessing whether the observed gains are reliable or merely anecdotal.
Authors: We agree that the abstract would benefit from quantitative support for the sparse-reward claim. In the revised version we will add specific metrics drawn from the LLM RLVR experiments (e.g., mean reward improvement and standard deviation over the reported number of runs) while keeping the abstract concise. revision: yes
-
Referee: [Method] Method description: the gradient statement 'p^θ - q' on sampled-completion logits assumes a softmax over the group and no additional normalization; the manuscript should derive this explicitly (including how group normalization interacts with the proportionality in q) to confirm it does not introduce new instabilities.
Authors: We will insert a short derivation in the Method section. The cross-entropy loss is L = −∑_i q_i log p^θ_i with p^θ the softmax over the group; its gradient w.r.t. the logits is exactly p^θ − q. Because q is already normalized to sum to one within the same group (q_i ∝ p_old_i exp(u_i) followed by group-level normalization), the proportionality does not introduce extra scaling factors or instabilities beyond ordinary cross-entropy training. The added paragraph will contain the full derivation and a brief stability remark. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's core construction defines the target q_i explicitly and independently as proportional to the previous policy p_old multiplied by exp(u_i) from external scores, then applies a standard cross-entropy objective whose gradient p^θ - q vanishes at equality by the algebraic property of the loss itself. This separation does not redefine any quantity in terms of the current parameters, invoke self-citations for uniqueness or ansatz justification, or rename a fitted input as a prediction; the update rule follows directly from the chosen objective without reducing the claimed stability advantage to a tautology. Empirical results on bandits, sequence tasks, and LLMs are reported as observed performance rather than derived necessities, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Utility scores u_i for sampled completions are provided by an external oracle or verifier and remain fixed during the update.
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs.arXiv preprint arXiv:2402.14740,
work page internal anchor Pith review arXiv
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. KTO: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review arXiv
-
[4]
Chang, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kianté Brantley, Thorsten Joachims, J
Zhaolin Gao, Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Gokul Swamy, Kianté Brantley, Thorsten Joachims, J. Andrew Bagnell, Jason D. Lee, and Wen Sun. REBEL: Reinforcement learning via regressing relative rewards.arXiv preprint arXiv:2404.16767,
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, He Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. REINFORCE++: A simple and efficient approach for aligning large language models.arXiv preprint arXiv:2501.03262,
work page internal anchor Pith review arXiv
-
[7]
Dhillon, David Brandfonbrener, and Rishabh Agarwal
URLhttps://arxiv.org/abs/2510.13786. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizhong Wang, P...
-
[8]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
URL https://arxiv.org/abs/ 2411.15124. Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. ReMax: A simple, effective, and efficient reinforcement learning method for aligning large language models. InInternational Conference on Machine Learning,
work page internal anchor Pith review arXiv
-
[9]
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
URLhttps://arxiv.org/abs/2601.05242. Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like training: A critical perspective.arXiv preprint arXiv:2503.20783,
work page internal anchor Pith review arXiv
-
[10]
URL https://arxiv.org/abs/ 2412.05265. Ian Osband. Delightful policy gradients.arXiv preprint arXiv:2603.14608,
-
[11]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. InarXiv preprint arXiv:1910.00177,
work page internal anchor Pith review arXiv 1910
-
[12]
Multi-task grpo: Reliable llm reasoning across tasks.arXiv preprint arXiv:2602.05547, 2026
URLhttps://arxiv.org/abs/2602.05547. John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational Conference on Machine Learning, pages 1889–1897. PMLR,
-
[13]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256,
work page internal anchor Pith review arXiv
-
[16]
Maximum likelihood reinforcement learning, 2026
URL https://openreview.net/forum?id= GqYSunGmp7. Fahim Tajwar, Guanning Zeng, Yueer Zhou, Yuda Song, Daman Arora, Yiding Jiang, Jeff Schneider, Ruslan Salakhutdinov, Haiwen Feng, and Andrea Zanette. Maximum likelihood reinforcement learning.arXiv preprint arXiv:2602.02710,
-
[17]
arXiv preprint arXiv:2510.18855 , year=
URLhttps://arxiv.org/abs/2510.18855. Manan Tomar, Lior Shani, Yonathan Efroni, and Mohammad Ghavamzadeh. Mirror descent policy optimization. InInternational Conference on Learning Representations,
-
[18]
18 An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Wang, Bowen Zheng, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu et al. DAPO: An open-source LLM reinforcement learning system.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. GSPO: Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The derivation is inlogit space, matching the experiment and Osband (2026): the policy in each context is a softmax over explicit logits
B Multi-context tabular weighting derivation This appendix derives the effective per-context coefficients for the multi-context tabular bandit in Section 3.2. The derivation is inlogit space, matching the experiment and Osband (2026): the policy in each context is a softmax over explicit logits. To avoid overloadingK from the main text, let A denote the n...
2026
-
[22]
correct versus incorrect
Single-sample GRPO.In the implemented MNIST variant, rewards are standardized across the minibatch: AB(a) = 1{a=y} −µ B σB , where µB and σB are the minibatch reward mean and standard deviation. Conditioning on the realized minibatch statistics(µ B, σB)for one example, the expected update is gGRPO|µB ,σB =E[A B(a) (ea −π)] = p σB (ey −π) = p σB v. Thus th...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.