Recognition: no theorem link
ARIA: Adaptive Retrieval Intelligence Assistant -- A Multimodal RAG Framework for Domain-Specific Engineering Education
Pith reviewed 2026-05-16 07:48 UTC · model grok-4.3
The pith
A multimodal RAG framework answers every relevant engineering course question while rejecting nearly all irrelevant ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a retrieval-augmented generation architecture, equipped with multimodal extraction for text, formulas, and diagrams plus controlled prompting, produces domain-specific educational assistants that achieve 100 percent recall on relevant questions, 90.9 percent precision in query filtering, and superior pedagogical quality compared with a general large language model on the same materials.
What carries the argument
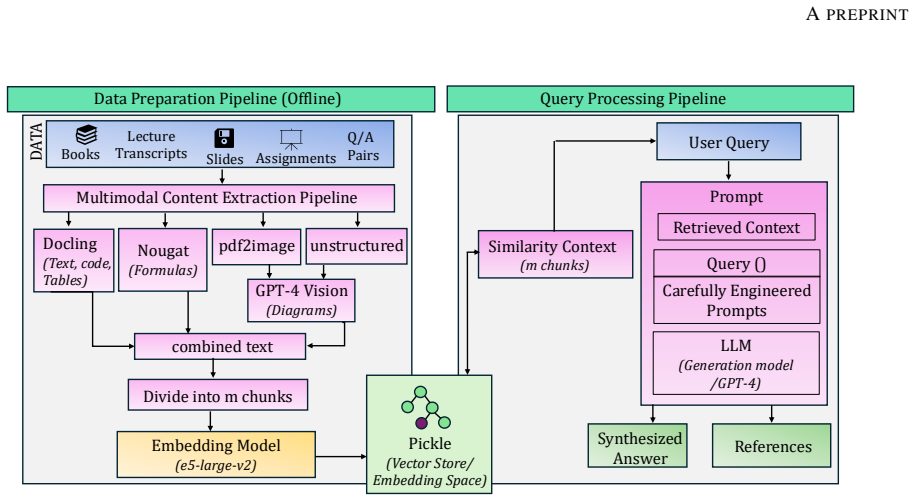
The multimodal retrieval pipeline that converts course documents containing text, formulas, and diagrams into semantic embeddings for grounded response generation and query filtering.
If this is right
- Course materials can be loaded directly to create a custom assistant without retraining the base model.
- The built-in filtering step stops the assistant from generating answers for questions outside the course scope.
- Response quality for on-topic questions can reach near-expert levels under expert review.
- The same architecture can be reused across multiple courses with only the source documents changed.
Where Pith is reading between the lines
- Instructors could update the assistant each semester simply by adding new lecture files rather than rebuilding the system.
- This approach may reduce the frequency of incorrect technical answers that general models give on specialized topics.
- Linking the assistant to a course platform could give students immediate, material-grounded help during study.
- Testing on courses outside engineering would show whether the same extraction and filtering steps work in other fields.
Load-bearing premise
Results from one engineering course tested with a small fixed set of queries will hold for other subjects, varied student phrasing, and real classroom use.
What would settle it
Measure whether the same system maintains 100 percent recall and high precision when loaded with materials from a different course and tested on a fresh set of relevant and irrelevant questions.
Figures





read the original abstract
Developing effective, domain-specific educational support systems is central to advancing AI in education. Although large language models (LLMs) demonstrate remarkable capabilities, they face significant limitations in specialized educational applications, including hallucinations, limited knowledge updates, and lack of domain expertise. Fine-tuning requires complete model retraining, creating substantial computational overhead, while general-purpose LLMs often provide inaccurate responses in specialized contexts due to reliance on generalized training data. To address this, we propose ARIA (Adaptive Retrieval Intelligence Assistant), a Retrieval-Augmented Generation (RAG) framework for creating intelligent teaching assistants across university-level courses. ARIA leverages a multimodal content extraction pipeline combining Docling for structured document analysis, Nougat for mathematical formula recognition, and GPT-4 Vision API for diagram interpretation, with the e5-large-v2 embedding model for high semantic performance and low latency. This enables accurate processing of complex educational materials while maintaining pedagogical consistency through engineered prompts and response controls. We evaluate ARIA using lecture material from Statics and Mechanics of Materials, a sophomore-level civil engineering course at Johns Hopkins University, benchmarking against ChatGPT-5. Results demonstrate 97.5% accuracy in domain-specific question filtering and superior pedagogical performance. ARIA correctly answered all 20 relevant course questions while rejecting 58 of 60 non-relevant queries, achieving 90.9% precision, 100% recall, and 4.89/5.0 average response quality. These findings demonstrate that ARIA's course-agnostic architecture represents a scalable framework for domain-specific educational AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
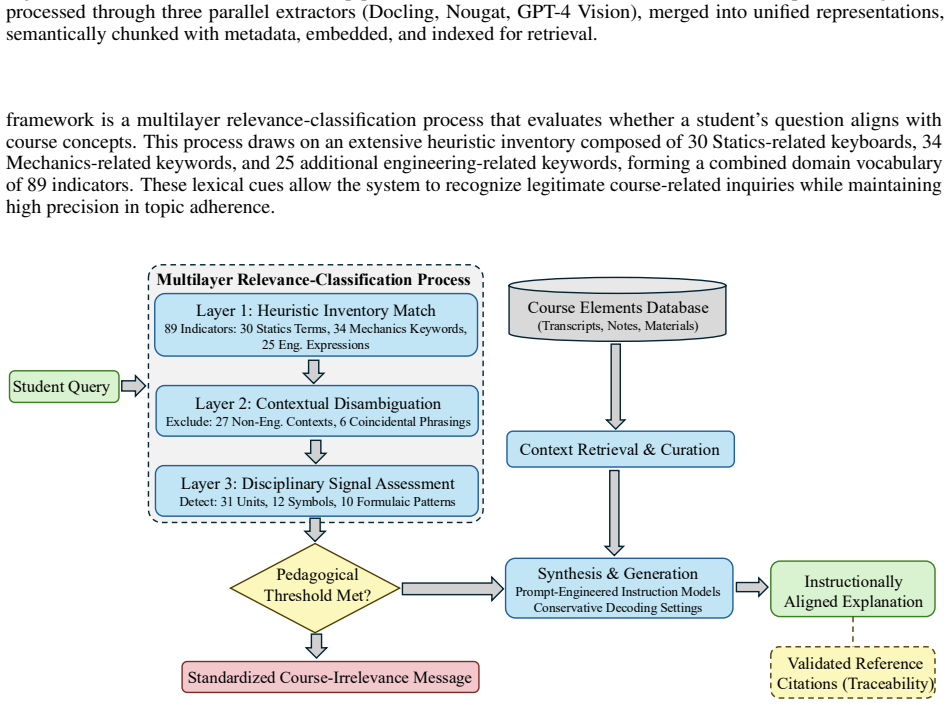
Summary. The paper introduces ARIA, a multimodal RAG framework for domain-specific engineering education that integrates Docling for structured document parsing, Nougat for formula recognition, GPT-4 Vision for diagram interpretation, and the e5-large-v2 embedding model, together with engineered prompts and response controls. Evaluated on lecture materials from a single Statics and Mechanics of Materials course at Johns Hopkins University, ARIA is benchmarked against ChatGPT-5 and claims 97.5% filtering accuracy, 100% recall on 20 relevant queries, 90.9% precision from rejecting 58 of 60 non-relevant queries, and 4.89/5.0 average response quality, positioning the system as a scalable, course-agnostic alternative to fine-tuning LLMs.
Significance. If the performance claims hold under broader testing, ARIA demonstrates a practical, low-overhead path to domain-specific educational assistants that mitigates hallucinations and knowledge staleness without full model retraining. The explicit multimodal pipeline for equations and diagrams is a concrete strength for STEM contexts, and the emphasis on engineered prompts for pedagogical consistency offers a replicable template for other courses.
major comments (1)
- Evaluation section: the reported 100% recall and 90.9% precision rest on a hand-curated set of only 80 queries (20 relevant + 60 non-relevant) drawn exclusively from one course's materials at a single institution. No description is given of query authorship, sampling from real student logs, inter-rater reliability, or hold-out testing on other domains or material types, so the generalization of the superiority claim over ChatGPT-5 cannot be assessed from the presented evidence.
minor comments (2)
- Methods: the exact system prompts, few-shot examples, and response-control instructions used for both ARIA and the ChatGPT-5 baseline are not provided, preventing reproduction of the comparison.
- Results: no error analysis, confusion-matrix breakdown, or statistical significance tests accompany the accuracy and quality metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment on the evaluation section below and will revise the paper to improve transparency and contextualize our claims appropriately.
read point-by-point responses
-
Referee: Evaluation section: the reported 100% recall and 90.9% precision rest on a hand-curated set of only 80 queries (20 relevant + 60 non-relevant) drawn exclusively from one course's materials at a single institution. No description is given of query authorship, sampling from real student logs, inter-rater reliability, or hold-out testing on other domains or material types, so the generalization of the superiority claim over ChatGPT-5 cannot be assessed from the presented evidence.
Authors: We acknowledge the controlled nature of the evaluation and will revise the Evaluation section to provide a detailed description of the query curation process. The 80 queries were authored by the research team (with domain expertise in civil engineering) to cover core topics from the Statics and Mechanics of Materials lecture materials for the relevant set, while the non-relevant queries were drawn from unrelated engineering and general topics to test filtering. We did not sample from real student interaction logs to preserve privacy and maintain experimental control. Inter-rater reliability metrics were not computed as query design was performed internally by the authors. We agree that the single-course scope limits strong generalization claims; we will add explicit caveats and a limitations paragraph stating that these results represent a proof-of-concept demonstration on one domain-specific course. The architecture itself is designed to be course-agnostic via the same multimodal pipeline and prompts, but we will temper language around superiority over ChatGPT-5 to reflect the current evidence base. revision: partial
- The study does not include hold-out testing or evaluation on other courses, institutions, or material types, so we cannot provide such results or inter-rater reliability data from external annotators.
Circularity Check
No circularity: empirical evaluation on external course materials
full rationale
The paper describes a multimodal RAG architecture and reports direct empirical measurements (97.5% filtering accuracy, 100% recall on 20 queries, 4.89/5 quality) against an external benchmark (ChatGPT-5) and fixed course lecture materials. No equations, fitted parameters, or self-citations are used to derive the performance numbers; the results are presented as measured outcomes on a held-out query set rather than being forced by construction from the framework definition itself. The evaluation is therefore self-contained against external references and does not reduce to any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- Selection of e5-large-v2 embedding model
axioms (1)
- domain assumption Multimodal tools (Docling, Nougat, GPT-4 Vision) accurately extract structured content including formulas and diagrams from course materials.
Reference graph
Works this paper leans on
- [1]
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al., Gpt-4 technical report, arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, et al., Llama 2: Open foundation and fine-tuned chat models, arXiv preprint arXiv:2307.09288 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, P. Fung, Survey of hallucination in natural language generation, ACM computing surveys 55 (12) (2023) 1–38
work page 2023
- [5]
-
[6]
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, H. Wang, H. Wang, Retrieval-augmented generation for large language models: A survey, arXiv preprint arXiv:2312.10997 2 (1) (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Y . Goldberg, A primer on neural network models for natural language processing, Journal of Artificial Intelligence Research 57 (2016) 345–420
work page 2016
-
[8]
Language Models as Knowledge Bases?
F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y . Wu, A. H. Miller, S. Riedel, Language models as knowledge bases?, arXiv preprint arXiv:1909.01066 (2019)
work page internal anchor Pith review arXiv 1909
-
[9]
How Much Knowledge Can You Pack Into the Parameters of a Language Model?
A. Roberts, C. Raffel, N. Shazeer, How much knowledge can you pack into the parameters of a language model?, arXiv preprint arXiv:2002.08910 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2002
- [10]
-
[11]
Y . Qin, S. Hu, Y . Lin, W. Chen, N. Ding, G. Cui, Z. Zeng, X. Zhou, Y . Huang, C. Xiao, et al., Tool learning with foundation models, ACM Computing Surveys 57 (4) (2024) 1–40
work page 2024
-
[12]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
work page 2019
-
[13]
J. D. M.-W. C. Kenton, L. K. Toutanova, et al., Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of naacL-HLT, V ol. 1, Minneapolis, Minnesota, 2019
work page 2019
- [14]
- [15]
-
[16]
Retrieval augmentation reduces hallucination in conversation, 2021
K. Shuster, S. Poff, M. Chen, D. Kiela, J. Weston, Retrieval augmentation reduces hallucination in conversation, arXiv preprint arXiv:2104.07567 (2021)
-
[17]
K. Guu, K. Lee, Z. Tung, P. Pasupat, M. Chang, Retrieval augmented language model pre-training, in: International conference on machine learning, PMLR, 2020, pp. 3929–3938
work page 2020
-
[18]
S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, E. Rutherford, K. Millican, G. B. Van Den Driessche, J.-B. Lespiau, B. Damoc, A. Clark, et al., Improving language models by retrieving from trillions of tokens, in: International conference on machine learning, PMLR, 2022, pp. 2206–2240
work page 2022
- [19]
- [20]
-
[21]
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, et al., A survey on large language model based autonomous agents, Frontiers of Computer Science 18 (6) (2024) 186345
work page 2024
-
[22]
Nougat: Neural Optical Understanding for Academic Documents
L. Blecher, G. Cucurull, T. Scialom, R. Stojnic, Nougat: Neural optical understanding for academic documents, arXiv preprint arXiv:2308.13418 (2023)
work page internal anchor Pith review arXiv 2023
-
[23]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers, I. Gurevych, Sentence-bert: Sentence embeddings using siamese bert-networks, arXiv preprint arXiv:1908.10084 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[24]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
work page 2017
-
[25]
J. Schulman, B. Zoph, C. Kim, J. Hilton, J. Menick, J. Weng, J. F. C. Uribe, L. Fedus, L. Metz, M. Pokorny, et al., Chatgpt: Optimizing language models for dialogue, OpenAI blog 2 (4) (2022)
work page 2022
-
[26]
X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, et al., Deepseek llm: Scaling open-source language models with longtermism, arXiv preprint arXiv:2401.02954 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen, et al., Lora: Low-rank adaptation of large language models., ICLR 1 (2) (2022) 3
work page 2022
-
[28]
C. Li, H. Farkhoor, R. Liu, J. Yosinski, Measuring the intrinsic dimension of objective landscapes, arXiv preprint arXiv:1804.08838 (2018). 13 APREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
A. Aghajanyan, L. Zettlemoyer, S. Gupta, Intrinsic dimensionality explains the effectiveness of language model fine-tuning, arXiv preprint arXiv:2012.13255 (2020)
-
[30]
Q. Xu, J. Gu, J. Lu, Leveraging artificial intelligence and large language models for enhanced teaching and learning: A systematic literature review, in: 2024 13th International Conference on Computer Technologies and Development (TechDev), IEEE, 2024, pp. 73–77
work page 2024
- [31]
-
[32]
S. Yang, H. Zhao, Y . Xu, K. Brennan, B. Schneider, Debugging with an ai tutor: Investigating novice help-seeking behaviors and perceived learning, in: Proceedings of the 2024 ACM Conference on International Computing Education Research-V olume 1, 2024, pp. 84–94
work page 2024
-
[33]
Simulating classroom education with llm-empowered agents.arXiv preprint arXiv:2406.19226,
Z. Zhang, D. Zhang-Li, J. Yu, L. Gong, J. Zhou, Z. Hao, J. Jiang, J. Cao, H. Liu, Z. Liu, et al., Simulating classroom education with llm-empowered agents, arXiv preprint arXiv:2406.19226 (2024)
- [34]
- [35]
-
[36]
C. K. Y . Chan, A comprehensive ai policy education framework for university teaching and learning, International journal of educational technology in higher education 20 (1) (2023) 38
work page 2023
- [37]
-
[38]
W. Xing, C. Li, H. Li, W. Zhu, B. Lyu, Z. Yan, Is retrieval-augmented generation all you need? investigating structured external memory to enhance large language models’ generation for math learning (2024)
work page 2024
-
[39]
F. P. Beer, E. R. Johnston Jr, J. T. DeWolf, D. F. Mazurek, Mechanics of materials (2006)
work page 2006
-
[40]
N. Livathinos, C. Auer, M. Lysak, A. Nassar, M. Dolfi, P. Vagenas, C. B. Ramis, M. Omenetti, K. Dinkla, Y . Kim, et al., Docling: An efficient open-source toolkit for ai-driven document conversion, arXiv preprint arXiv:2501.17887 (2025). Appendix A: ARIA Domain Experiment Results Table 3: Complete ARIA Domain Experiment Question Set and Results ID Questio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.