A Comparative Study of Demonstration Selection for Practical Large Language Models-based Next POI Prediction
Pith reviewed 2026-05-15 11:06 UTC · model grok-4.3
The pith
Simpler heuristic methods for selecting LLM demonstrations outperform complex embedding approaches in next POI prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
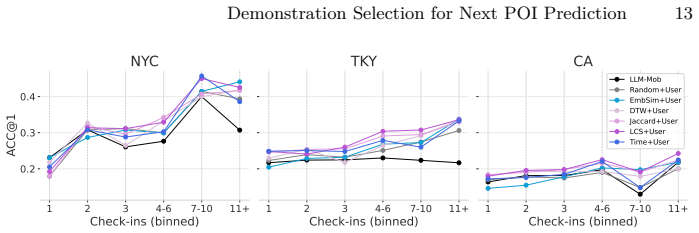
The authors establish that heuristic demonstration selection methods based on geographical proximity, temporal ordering, and sequential patterns consistently outperform embedding-based selection methods in both prediction accuracy and computational efficiency for LLM-based next POI prediction. These heuristic methods enable LLMs to achieve or exceed the performance of fine-tuned models in certain scenarios without any further training.
What carries the argument
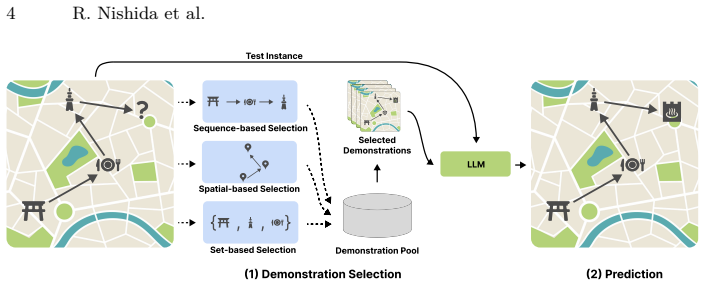
Heuristic demonstration selection using geographical proximity, temporal ordering, and sequential patterns from user check-in sequences.
If this is right
- LLM performance on next POI tasks improves with heuristic selection while reducing compute requirements.
- Practical deployment of LLMs for location prediction becomes feasible without fine-tuning.
- Embedding-based selection is not necessary and may be inferior for this application.
- Simple domain-informed rules capture relevant context better than general-purpose embeddings in this setting.
Where Pith is reading between the lines
- Similar heuristic advantages might appear in other sequential prediction tasks like next-item recommendation.
- Developers could prioritize lightweight heuristic selectors when building LLM applications for mobility data.
- Testing on larger or more diverse datasets would clarify if the outperformance holds broadly.
Load-bearing premise
The advantages of heuristic methods observed on the three tested datasets will hold for other user behavior datasets and real deployment conditions.
What would settle it
Running the same experiments on a fourth independent real-world check-in dataset where embedding-based methods achieve higher accuracy than the heuristics.
Figures



read the original abstract
This paper investigates demonstration selection strategies for predicting a user's next point-of-interest (POI) using large language models (LLMs), aiming to accurately forecast a user's subsequent location based on historical check-in data. While in-context learning (ICL) with LLMs has recently gained attention as a promising alternative to traditional supervised approaches, the effectiveness of ICL significantly depends on the selected demonstration. Although previous studies have examined methods such as random selection, embedding-based selection, and task-specific selection, there remains a lack of comprehensive comparative analysis among these strategies. To bridge this gap and clarify the best practices for real-world applications, we comprehensively evaluate existing demonstration selection methods alongside simpler heuristic approaches such as geographical proximity, temporal ordering, and sequential patterns. Extensive experiments conducted on three real-world datasets indicate that these heuristic methods consistently outperform more complex and computationally demanding embedding-based methods, both in terms of computational cost and prediction accuracy. Notably, in certain scenarios, LLMs using demonstrations selected by these simpler heuristic methods even outperform existing fine-tuned models, without requiring further training. Our source code is available at: https://github.com/ryonsd/DS-LLM4POI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a comparative empirical study of demonstration selection methods for in-context learning with LLMs on the task of next POI prediction from historical check-in sequences. It evaluates simple heuristic approaches (geographical proximity, temporal ordering, sequential patterns) against random selection and embedding-based methods across three real-world datasets, reporting that the heuristics achieve higher accuracy at lower computational cost and, in some cases, outperform fine-tuned supervised models without any training.
Significance. If the empirical results prove robust, the work has clear practical value for resource-constrained deployment of LLMs in mobility and location-based services. It provides evidence that domain-specific heuristics can be preferable to generic embedding similarity for ICL demonstration selection, potentially lowering inference costs and removing the need for task-specific fine-tuning in POI prediction pipelines.
major comments (2)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): the central claim of consistent outperformance by heuristics rests on accuracy numbers from only three check-in datasets; no statistical significance tests (paired t-tests, Wilcoxon, or bootstrap confidence intervals) are reported for the differences versus embedding baselines, making it impossible to judge whether the reported gains exceed experimental variance.
- [§6 or Limitations] §6 (Discussion) or Limitations: the manuscript does not test whether the observed heuristic advantage persists on datasets that exhibit weaker spatial-temporal locality, higher sparsity, or cross-city mobility patterns. Without such controls, the superiority could be an artifact of the locality bias present in the three chosen traces rather than a general property of heuristic selection for LLM-based POI prediction.
minor comments (2)
- [Abstract] Abstract: the statement that heuristics 'consistently outperform' should be accompanied by at least the headline accuracy deltas and the names of the three datasets to give readers an immediate quantitative sense of the effect sizes.
- [§3] §3 (Methodology): the precise definitions and hyper-parameters of the embedding-based baselines (e.g., which sentence-transformer model, pooling strategy, and similarity metric) are not fully specified, hindering exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper accordingly to strengthen the empirical analysis and clarify limitations.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): the central claim of consistent outperformance by heuristics rests on accuracy numbers from only three check-in datasets; no statistical significance tests (paired t-tests, Wilcoxon, or bootstrap confidence intervals) are reported for the differences versus embedding baselines, making it impossible to judge whether the reported gains exceed experimental variance.
Authors: We agree that statistical significance testing is necessary to rigorously support the observed differences. In the revised manuscript, we will re-run the experiments with multiple random seeds where applicable and add paired t-tests (or Wilcoxon signed-rank tests) along with bootstrap confidence intervals to the accuracy tables in §5, directly comparing heuristic methods to embedding baselines on each dataset. revision: yes
-
Referee: [§6 or Limitations] §6 (Discussion) or Limitations: the manuscript does not test whether the observed heuristic advantage persists on datasets that exhibit weaker spatial-temporal locality, higher sparsity, or cross-city mobility patterns. Without such controls, the superiority could be an artifact of the locality bias present in the three chosen traces rather than a general property of heuristic selection for LLM-based POI prediction.
Authors: We acknowledge this limitation on generalizability. The three datasets used are standard benchmarks in POI prediction research and exhibit typical spatial-temporal patterns. In the revision, we will expand the Limitations section to explicitly discuss how the heuristic advantage may depend on dataset characteristics such as locality and sparsity, and we will frame the results as applying to common real-world check-in traces while recommending future work on more diverse datasets. revision: partial
Circularity Check
No significant circularity in empirical comparison study
full rationale
This paper conducts a purely empirical evaluation of demonstration selection strategies for LLM-based next POI prediction across three real-world datasets. It contains no mathematical derivations, parameter fitting, uniqueness theorems, or self-citation chains that reduce any claim to its own inputs by construction. All performance claims rest on direct experimental results against external benchmarks, with no load-bearing steps that qualify as self-definitional, fitted-input predictions, or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The effectiveness of in-context learning significantly depends on the selected demonstration.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Twenty-Third Interna- tional Joint Conference on Artificial Intelligence
Cheng, C., Yang, H., Lyu, M.R., King, I.: Where you like to go next: successive point-of-interest recommendation. In: Proceedings of the Twenty-Third Interna- tional Joint Conference on Artificial Intelligence. p. 2605 ⚶2611. IJCAI ’13, AAAI Press (2013)
work page 2013
-
[2]
Cho, E., Myers, S.A., Leskovec, J.: Friendship and mobility: user movement in location-based social networks. In: Proceedings of the 17th ACM SIGKDD in- ternational conference on Knowledge discovery and data mining. pp. 1082–1090 (2011)
work page 2011
-
[3]
Dai, S., Shao, N., Zhao, H., Yu, W., Si, Z., Xu, C., Sun, Z., Zhang, X., Xu, J.: Uncovering chatgptns capabilities in recommender systems. p. 1126 ⚶1132. RecSys ’23, Association for Computing Machinery, New York, NY, USA (2023). https: //doi.org/10.1145/3604915.3610646
-
[4]
In: 2024 IEEE Conference on Artificial Intelligence (CAI)
Feng, S., Lyu, H., Li, F., Sun, Z., Chen, C.: Where to Move Next: Zero-shot Gen- eralization of LLMs for Next POI Recommendation . In: 2024 IEEE Conference on Artificial Intelligence (CAI). pp. 1530–1535. IEEE Computer Society, Los Alami- tos, CA, USA (Jun 2024). https://doi.org/10.1109/CAI59869.2024.00277
-
[5]
In: Proceedings of the 16th ACM Conference on Recommender Systems
Geng, S., Liu, S., Fu, Z., Ge, Y., Zhang, Y.: Recommendation as language pro- cessing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In: Proceedings of the 16th ACM Conference on Recommender Systems. p. 299 ⚶315. RecSys ’22, Association for Computing Machinery, New York, NY, USA (2022). https://doi.org/10.1145/3523227.3546767
-
[6]
Kawarada, M., Ishigaki, T., Takamura, H.: Prompting for numerical sequences: A case study on market comment generation. In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). pp. 13190–13200. ELRA and ICCL, Torino, Italia (May 2024), https://aclanthology.org/2024.lrec-...
work page 2024
-
[7]
Kawarada, M., Ishigaki, T., Topić, G., Takamura, H.: Demonstration selection strategies for numerical time series data-to-text. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 7378–7392. Association for Computational Linguistics, Miami, Florida, USA (Nov 2024). https://doi.org/10...
- [8]
-
[9]
On Generative Agents in Recommenda- tion
Li, P., de Rijke, M., Xue, H., Ao, S., Song, Y., Salim, F.D.: Large language mod- els for next point-of-interest recommendation. In: Proceedings of the 47th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval. p. 1463 ⚶1472. SIGIR ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1...
-
[10]
Ling Cai, Jun Xu, J.L., Pei, T.: Integrating spatial and temporal contexts into a factorization model for poi recommendation. International Journal of Geographical Information Science 32(3), 524–546 (2018). https://doi.org/10.1080/13658816 .2017.1400550
-
[11]
Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases
Luo, Y., Liu, Q., Liu, Z.: Stan: Spatio-temporal attention network for next loca- tion recommendation. In: Proceedings of the Web Conference 2021. p. 2177 ⚶2185. WWW ’21, Association for Computing Machinery, New York, NY, USA (2021). https://doi.org/10.1145/3442381.3449998 16 R. Nishida et al
-
[12]
doi: 10.18653/v1/2024.acl-long.492
Peng, K., Ding, L., Yuan, Y., Liu, X., Zhang, M., Ouyang, Y., Tao, D.: Revisiting demonstration selection strategies in in-context learning. In: Ku, L.W., Martins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9090–9101. Association for Computational Linguistics...
-
[13]
Sun, K., Qian, T., Chen, T., Liang, Y., Nguyen, Q.V.H., Yin, H.: Where to go next: Modeling long- and short-term user preferences for point-of-interest recom- mendation. Proceedings of the ... AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence 34(01), 214–221 (Apr 2020)
work page 2020
-
[14]
Team, Q.: Qwen2.5: A party of foundation models (September 2024), https://qw enlm.github.io/blog/qwen2.5/
work page 2024
-
[15]
Touvron, H., Martin, L., Stone, K., et al.: Llama 2: Open foundation and fine-tuned chat models (2023), https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [16]
-
[17]
In: Duh, K., Gomez, H., Bethard, S
Wang, L., Lim, E.P.: The whole is better than the sum: Using aggregated demon- strations in in-context learning for sequential recommendation. In: Duh, K., Gomez, H., Bethard, S. (eds.) Findings of the Association for Computational Lin- guistics: NAACL 2024. pp. 876–895. Association for Computational Linguistics, Mexico City, Mexico (Jun 2024). https://do...
- [18]
-
[19]
Wang, Z., Zhu, Y., Wang, C., Ma, W., Li, B., Yu, J.: Adaptive graph representation learning for next poi recommendation. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. p. 393⚶402. SIGIR ’23, Association for Computing Machinery, New York, NY, USA (2023). https://doi.org/10.1145/3539618.3591634
- [20]
-
[21]
Yan, X., Song, T., Jiao, Y., He, J., Wang, J., Li, R., Chu, W.: Spatio-temporal hypergraph learning for next poi recommendation. In: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Informa- tion Retrieval. p. 403 ⚶412. SIGIR ’23, Association for Computing Machinery, New York, NY, USA (2023). https://doi.org/10.114...
-
[22]
IEEE Transactions on Systems, Man, and Cybernetics: Systems 45(1), 129–142 (2015)
Yang, D., Zhang, D., Zheng, V.W., Yu, Z.: Modeling user activity preference by leveraging user spatial temporal characteristics in lbsns. IEEE Transactions on Systems, Man, and Cybernetics: Systems 45(1), 129–142 (2015). https://doi.or g/10.1109/TSMC.2014.2327053
-
[23]
Yang, S., Liu, J., Zhao, K.: Getnext: Trajectory flow map enhanced transformer for next poi recommendation. In: Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. p. 1144 ⚶1153. SIGIR ’22, Association for Computing Machinery, New York, NY, USA (2022). https://doi.org/10.1145/3477495.3531983
-
[24]
Zhu, S., Cui, M., Xiong, D.: Towards robust in-context learning for machine trans- lation with large language models. In: Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). pp. 16619–16629. ELRA and ICCL, Torino, Italia (May 2024), https://aclanthology.org/2024.lrec-main.1444/
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.