Recognition: 2 theorem links
· Lean TheoremFLeX: Fourier-based Low-rank EXpansion for multilingual transfer
Pith reviewed 2026-05-10 19:45 UTC · model grok-4.3
The pith
Fourier-based regularization during low-rank fine-tuning raises Java code generation accuracy from 34.2 percent to 42.1 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that applying regularization in the Fourier domain to the updates of low-rank adapter matrices during fine-tuning enables a model trained primarily on Python to generate correct Java code at a higher rate than either the baseline low-rank method or a more extensively fine-tuned Python model, with the Fourier term producing the clearest lift on the target language.
What carries the argument
Fourier-based regularization, which adds a penalty on selected frequency components of the low-rank weight updates to encourage adaptations that transfer better across languages.
If this is right
- LoRA fine-tuning on the compact MBPP dataset alone exceeds the cross-lingual performance of the released Code Llama-Python-7B model.
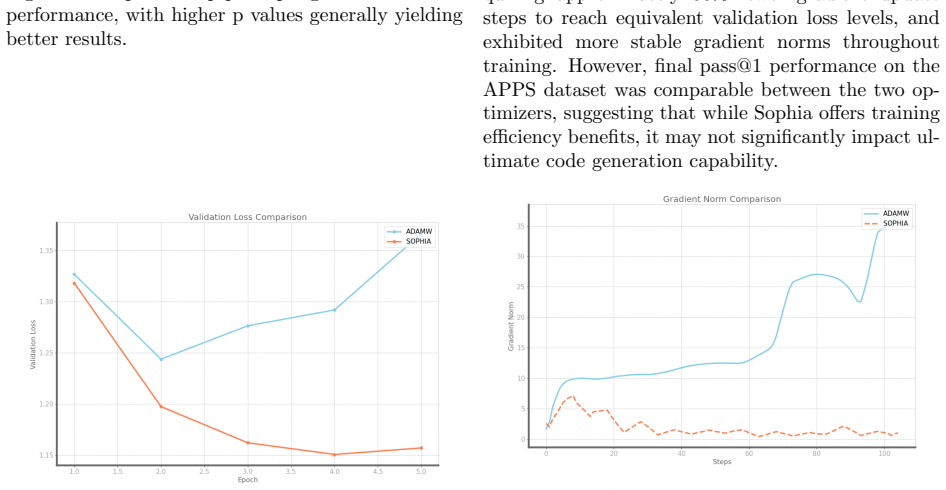
- The Sophia optimizer reaches competitive final accuracy faster than Adam, although the end scores remain close.
- The largest measured gain in Java transfer comes from adding the Fourier regularization during the low-rank updates.
- Parameter-efficient adaptation with frequency-domain constraints can substitute for full multilingual fine-tuning in at least the Python-to-Java direction.
Where Pith is reading between the lines
- The same frequency penalty might reduce language-specific overfitting and therefore help transfer to additional programming languages beyond the tested pair.
- Combining the Fourier term with other efficient adaptation methods could lower the total compute needed to support many languages at once.
- Repeating the protocol on larger base models or different source-target language pairs would test whether the regularization effect scales.
Load-bearing premise
The reported improvement on Java tasks is produced by the Fourier regularization itself rather than by choices of dataset, optimizer settings, or other training details that were not varied in the experiments.
What would settle it
Re-run the identical LoRA fine-tuning schedule on the same MBPP data but remove the Fourier regularization term, then measure whether the Java pass@1 score falls back to the 34.2 percent baseline.
Figures










read the original abstract
Cross-lingual code generation is critical in enterprise environments where multiple programming languages coexist. However, fine-tuning large language models (LLMs) individually for each language is computationally prohibitive. This paper investigates whether parameter-efficient fine-tuning methods and optimizer enhancements can improve cross-lingual transfer from Python to languages like Java. We fine-tune the Code Llama 7B model using low-rank adaptation (LoRA) to optimize a small subset of parameters and compare Adam and Sophia optimizers, while exploring a novel Fourier-based regularization technique. Our contributions include: (1)demonstrating that LoRA fine-tuning on a small, high-quality dataset (MBPP) can exceed the pass@1 performance of the more broadly fine-tuned Code Llama-Python-7B model (40.1% vs. 38.4%); (2) showing that while Sophia achieves faster convergence than Adam, final pass@1 scores show marginal differences; and (3) presenting evidence that Fourier-based regularization during fine-tuning significantly improves cross-lingual transfer, achieving 42.1% pass@1 on Java tasks compared to the 34.2% baseline. These findings suggest that combining LoRA, optimized training methods, and frequency-domain regularization can efficiently adapt single-language LLMs to perform well across multiple programming languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FLeX, which augments LoRA-based fine-tuning of Code Llama 7B on the MBPP dataset with a Fourier-based regularization term and optimizer comparisons (Adam vs. Sophia). It claims three contributions: (1) LoRA on MBPP alone yields 40.1% pass@1 on Java, exceeding the 38.4% of the broader Code Llama-Python-7B model; (2) Sophia converges faster than Adam with comparable final performance; and (3) the Fourier regularization further improves cross-lingual transfer to 42.1% pass@1 on Java tasks versus a 34.2% baseline.
Significance. If the reported gains from the Fourier regularization can be isolated through controlled ablations, the approach would offer a computationally efficient route to multilingual code generation without per-language full fine-tuning. The combination of parameter-efficient adaptation and frequency-domain regularization is a plausible direction for low-resource language transfer in LLMs.
major comments (1)
- [Abstract / Experimental Results] Abstract, contribution (3): the 42.1% vs. 34.2% Java pass@1 lift is presented as evidence for the Fourier regularization, yet the manuscript does not state whether the 34.2% baseline uses the identical LoRA rank, optimizer, training steps, and MBPP data as the proposed run. Because contribution (1) already demonstrates that LoRA on MBPP alone improves over broader baselines, any additional gain cannot be attributed to the frequency-domain term without an ablation that holds all other factors fixed.
minor comments (2)
- [Abstract] No error bars, number of random seeds, or statistical tests accompany the pass@1 figures, limiting assessment of whether the reported differences are reliable.
- [Methods] The precise definition of the Fourier regularization term (e.g., which frequencies are penalized and how the strength hyper-parameter is chosen) should be stated explicitly in the methods section rather than left to the abstract.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying an ambiguity in how the contributions are presented. We address the major comment below and will revise the manuscript to improve clarity and experimental rigor.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract, contribution (3): the 42.1% vs. 34.2% Java pass@1 lift is presented as evidence for the Fourier regularization, yet the manuscript does not state whether the 34.2% baseline uses the identical LoRA rank, optimizer, training steps, and MBPP data as the proposed run. Because contribution (1) already demonstrates that LoRA on MBPP alone improves over broader baselines, any additional gain cannot be attributed to the frequency-domain term without an ablation that holds all other factors fixed.
Authors: We appreciate the referee highlighting this important point regarding the attribution of improvements to the Fourier regularization. The 34.2% figure represents the pass@1 performance of the base Code Llama 7B model on Java tasks from the MBPP benchmark, prior to any fine-tuning. Contribution (1) shows that applying LoRA fine-tuning on the MBPP dataset alone raises this to 40.1%, surpassing even the Code Llama-Python-7B model. The 42.1% is achieved by incorporating the Fourier-based regularization into this LoRA fine-tuning process. Nevertheless, to ensure the gain from the regularization is isolated, we agree that a controlled ablation is necessary. In the revised version, we will add such an ablation experiment, maintaining identical settings for LoRA rank, optimizer, number of training steps, and the MBPP training data. We will update the abstract and the experimental section to clearly present these comparisons. This revision will allow readers to directly assess the impact of the Fourier term. revision: yes
Circularity Check
No circularity: empirical results from controlled fine-tuning runs
full rationale
The paper reports direct experimental measurements of pass@1 scores on Java code generation tasks after fine-tuning Code Llama 7B with LoRA adapters, Adam/Sophia optimizers, and a Fourier-based regularization term. Contributions (1)–(3) consist of observed performance deltas (e.g., 42.1 % vs. 34.2 % baseline, 40.1 % vs. 38.4 % for LoRA on MBPP) obtained from training runs. No equations, parameter-fitting procedures, or self-citations are presented that would reduce any claimed improvement to a quantity defined by the result itself. The derivation chain is therefore self-contained and consists solely of empirical observation rather than any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- Fourier regularization strength
axioms (2)
- domain assumption LoRA updates are sufficient to achieve meaningful cross-lingual transfer in code models
- domain assumption MBPP is a high-quality and representative dataset for both fine-tuning and cross-lingual evaluation
invented entities (1)
-
Fourier-based regularization term
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Fourier-based regularization ... LFourier(w) = sum ρ(k,n,T) |ŵk|^2 with ρ(k) = 1 - ϕ_low + (ϕ_high - ϕ_low) min(1, k/(n T))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LoRA fine-tuning on MBPP achieving 40.1% pass@1 vs Code Llama-Python-7B 38.4%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Code Llama: Open Foundation Models for Code
Baptiste Rozi` ere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code Llama: Open Foundation Models for Code. 2023. https://arxiv.org/abs/2308.12950
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. 2021. https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [3]
-
[4]
arXiv preprint arXiv:2207.10397 , year=
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. CodeT: Code Generation with Generated Tests. 2023. https://arxiv.org/abs/2207.10397
-
[5]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. 2022. https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. QLoRA: Efficient Finetuning of Quantized LLMs. 2023. https://arxiv.org/abs/2305.14314
work page internal anchor Pith review arXiv 2023
-
[7]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models. In NeurIPS Datasets and Benchmarks, 2021. https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Federico Cassano, John Gouwar, Daniel Nguyen, Sydney Nguyen, Luna Phipps-Costin, Donald Pinckney, Ming-Ho Yee, Yangtian Zi, Carolyn Jane Anderson, Molly Q. Feldman, Arjun Guha, Michael Greenberg, and Abhinav Jangda. MultiPL-E: A Scalable and Polyglot Approach to Benchmarking Neural Code Generation. 2023. https://arxiv.org/abs/2208.08227
-
[9]
Measuring Coding Challenge Competence With APPS
Dan Hendrycks, Steven Basart, Saurav Kada- vath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InNeurIPS Datasets and Benchmarks, 2021. https://arxiv.org/abs/2105.09938
work page internal anchor Pith review arXiv 2021
-
[10]
Language Models are Few-Shot Learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAd- vances in Neural Information Processing Sys- tems, volume 33, pp. 1877–1901, 2020. https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[11]
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. CodeGen: An open large language model for code with multi-turn program synthesis. 2022. https://arxiv.org/abs/2203.13474
work page internal anchor Pith review arXiv 2022
-
[12]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Pe- ter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. 2023. https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InIn- ternational Conference on Learning Representa- tions, 2019. https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[14]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, 9 Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet Challenge: Evaluating the state of semantic code search. 2019. https://arxiv.org/abs/1909.09436
work page internal anchor Pith review arXiv 2019
-
[15]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating Large Language Models Trained on Code. InNeurIPS, 2021. https://arxiv.org/abs/2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
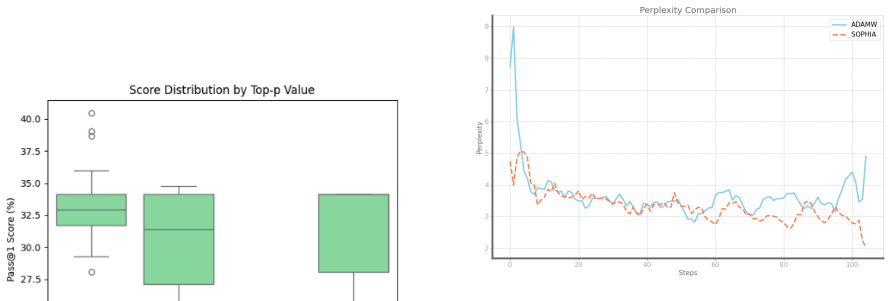
Qiwei Peng, Yekun Chai, and Xuhong Li. HumanEval-XL: A Multilingual Code Genera- tion Benchmark for Cross-lingual Natural Lan- guage Generalization. InLREC-COLING, 2024. https://arxiv.org/abs/2402.16694 10 8 Appendix 8.1 Round 1: LoRA Fine-tuning with MBPP 8.1.1 Experimental Setup & Results In Round 1, I explored whether a smaller, high- quality dataset c...
-
[17]
Figure 9: Temperature evaluation results showing that higher temperatures (0.8-1.0) and very low tem- peratures (0.0-0.2) produced better results than mid- range values
consisting of 974 Python programming problems. Figure 9: Temperature evaluation results showing that higher temperatures (0.8-1.0) and very low tem- peratures (0.0-0.2) produced better results than mid- range values. The LoRA adaptation significantly reduced trainable parameters to approximately 11.9 million parame- ters, representing less than 0.2% of th...
-
[18]
Frequency domain regularization applied di- rectly to LoRA parameters without merging them with base model weights preserved the low- rank structure
-
[19]
The optimal configuration targeted only MLP feed-forward layers rather than attention layers, contrary to typical LoRA implementations
-
[20]
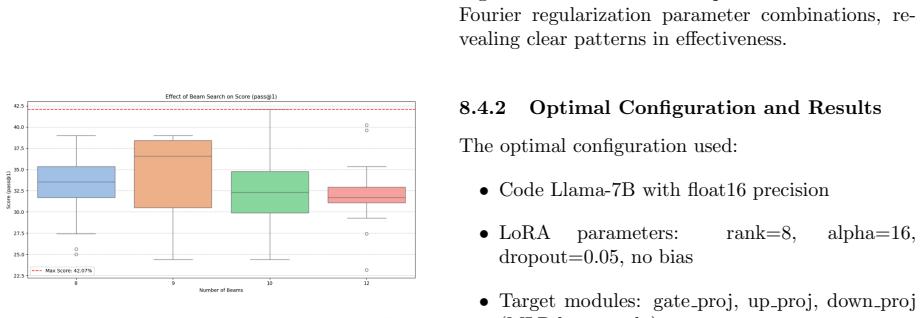
Isolation of updates more effectively constrained regularization to preserve cross-lingual knowl- edge without disrupting base model capabilities Figure 19: Performance comparison across different Fourier regularization parameter combinations, re- vealing clear patterns in effectiveness. 8.4.2 Optimal Configuration and Results The optimal configuration us...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.