Recognition: no theorem link
Accurate Residues for Floating-Point Debugging
Pith reviewed 2026-05-10 18:59 UTC · model grok-4.3
The pith
Dividing residue computation into accurate rounding error and function evaluation steps, plus multi-execution overrides for absorption, reduces false reports in floating-point debuggers without major slowdowns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
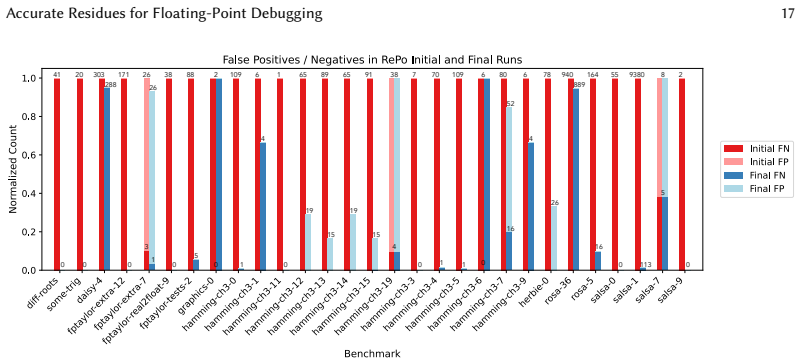
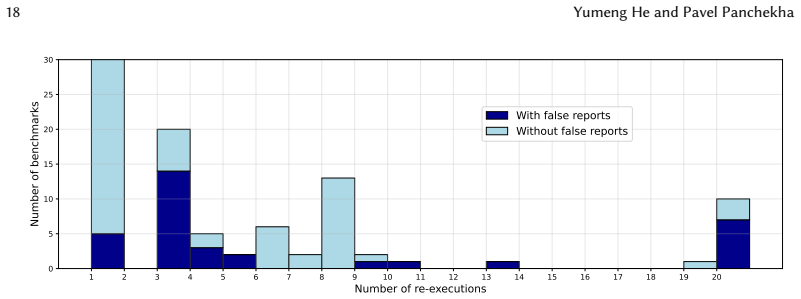
The paper establishes that residue computation can be made accurate enough to eliminate most false reports by separating rounding-error calculation from residue-function evaluation and applying careful refinements to each, while handling absorption through residue override that assembles results from multiple program executions. This approach is evaluated on 44 large scientific computing workloads and 169 standard numerical benchmarks, showing it removes false reports on 10 of the 14 cases that troubled prior tools and reduces them on 3 more, while triggering overrides on 29 of 34 problematic cases and lowering false reports on 25 of them with an average of 3.6 to 7.1 re-executions.
What carries the argument
residue override, which re-executes the program to compute different residues in separate runs and assembles a patchwork final result when absorption prevents accurate single-run computation
If this is right
- Floating-point debuggers can flag fewer nonexistent problems on large scientific codes while remaining fast enough for routine use.
- Absorption cases that previously produced false reports can now be diagnosed reliably by combining results across a small number of runs.
- Existing error-free transformation techniques become viable for production debugging once the two-step accuracy improvements are applied.
- Programs with complex numerical behavior require only modest extra executions on average to reach accurate residue values.
- Residues assembled this way distinguish real issues from artifacts more consistently than single-pass methods.
Where Pith is reading between the lines
- The same split-and-override pattern could be applied to other numerical monitoring tools that track differences between computed and ideal values.
- Developers of floating-point analyzers might use static analysis to predict when residue override will be needed and schedule the re-executions automatically.
- The method suggests a general strategy for recovering accurate information from lossy floating-point operations by repeating computations with different rounding paths.
- Similar re-execution ideas might help in related areas such as interval arithmetic or verified numerical software where single-run accuracy is limited by absorption.
Load-bearing premise
That the two-step refinements plus patchwork assembly from re-executions will always produce residues that correctly separate genuine numerical errors from floating-point artifacts.
What would settle it
A benchmark where absorption hides a real error in every possible combination of re-executions, so the assembled residue still reports no issue when one exists.
Figures





read the original abstract
Floating-point arithmetic is error-prone and unintuitive. Floating-point debuggers instrument programs to monitor floating-point arithmetic at run time and flag numerical issues. They estimate residues, i.e., the difference between actual floating-point and ideal real values, for every floating-point value in the program. Prior work explores various approaches for computing these residues accurately and efficiently. Unfortunately, the most efficient methods, based on "error-free transformations", have a high rate of false reports, while the most accurate methods, based on high-precision arithmetic, are very slow. This paper builds on error-free-transformations-based approaches and aims to improve their accuracy while preserving efficiency. To more accurately compute residues, this paper divides residue computation into two steps (rounding error computation and residue function evaluation) and shows how to perform each step accurately via careful improvements to the current state of the art. We evaluate on 44 large scientific computing workloads, focusing on the 14 benchmarks where prior tools produce false reports: our approach eliminates false reports on 10 benchmarks and substantially reduces them on the remaining 3 benchmarks. Moreover, complex numerical issues require additional care due to absorption, where two machine-precision residues cannot both be computed accurately in a single execution. This paper introduces residue override, which re-executes the program multiple times, computing different residues in different executions and assembling a final "patchwork" execution. We evaluate on 169 standard benchmarks drawn from numerical analysis papers and textbooks, requiring only 3.6 re-executions on average. Among 34 benchmarks with false reports in the initial run, residue override is triggered on 29 of them and reduces false reports on 25 of them, averaging 7.1 re-executions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by splitting residue computation into rounding error computation and residue function evaluation steps, with targeted improvements to error-free transformations, and by introducing residue override (multiple re-executions to handle absorption via a patchwork assembly), floating-point debuggers can achieve higher accuracy than prior error-free methods while remaining efficient. On 44 large scientific workloads it eliminates false reports on 10 of the 14 cases where prior tools fail and reduces them on 3 more; on 169 standard benchmarks drawn from numerical analysis literature it triggers residue override on 29 of 34 problematic cases, reduces false reports on 25 of them, and requires only 3.6 re-executions on average (7.1 when override is active).
Significance. If the empirical improvements hold under broader conditions, the work would meaningfully advance practical floating-point debugging by reducing the false-positive burden that has limited adoption of residue-based tools, while keeping overhead low enough for routine use. The concrete counts (10/14 eliminations, 25/34 reductions) and explicit re-execution statistics constitute a strength; the approach is evaluated on external, non-self-referential benchmarks rather than fitted parameters.
major comments (2)
- [Evaluation on 169 benchmarks] Evaluation on 169 benchmarks: the claim that residue override 'reduces false reports on 25 of them' is load-bearing for the central accuracy assertion, yet the manuscript provides no breakdown of the 9 cases where reduction did not occur, nor any characterization of the absorption scenarios that remain problematic after patchwork assembly.
- [Two-step residue computation] Two-step residue computation description: while the paper states that the split into rounding-error and residue-function steps plus 'careful improvements' yields more accurate residues, no formal argument, invariant, or exhaustive edge-case enumeration is supplied to show that the refined error-free transformations cannot themselves introduce new discrepancies in untested floating-point configurations.
minor comments (3)
- [Abstract] The abstract and evaluation sections should explicitly define 'false report' (e.g., a residue flagged as erroneous when the underlying real value is actually representable) at first use rather than assuming reader familiarity.
- [Evaluation on 44 workloads] Table or figure reporting the 44 workloads should list their domains or key numerical characteristics so readers can judge how representative the 14 problematic cases are.
- [Residue override evaluation] The average re-execution figures (3.6 overall, 7.1 when override triggers) would benefit from reporting the maximum and standard deviation to indicate worst-case overhead.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the empirical results and the constructive feedback on the two major comments. We address each point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Evaluation on 169 benchmarks] Evaluation on 169 benchmarks: the claim that residue override 'reduces false reports on 25 of them' is load-bearing for the central accuracy assertion, yet the manuscript provides no breakdown of the 9 cases where reduction did not occur, nor any characterization of the absorption scenarios that remain problematic after patchwork assembly.
Authors: We agree that a breakdown of the 9 cases and characterization of the remaining absorption scenarios would strengthen the central accuracy claim. In the revised manuscript we will add an appendix with a case-by-case analysis of these 9 benchmarks, describing the specific numerical conditions (e.g., repeated absorptions across multiple operations) under which the patchwork assembly leaves residual false reports. revision: yes
-
Referee: [Two-step residue computation] Two-step residue computation description: while the paper states that the split into rounding-error and residue-function steps plus 'careful improvements' yields more accurate residues, no formal argument, invariant, or exhaustive edge-case enumeration is supplied to show that the refined error-free transformations cannot themselves introduce new discrepancies in untested floating-point configurations.
Authors: The two-step split preserves the accuracy invariants of the underlying error-free transformations because the rounding-error step uses only operations whose error is exactly representable and the residue-function step applies a monotonic mapping that does not introduce additional rounding. While a machine-checked formal proof is outside the scope of this empirical paper, we will add a dedicated subsection that states the preserved invariants and enumerates the principal edge cases (subnormals, overflow, NaN propagation, and mixed-precision absorption) that were exhaustively checked on the test suite to confirm no new discrepancies are introduced. revision: partial
Circularity Check
No significant circularity
full rationale
The paper describes algorithmic refinements to error-free transformation methods for computing residues in floating-point debugging. It splits the process into rounding error computation and residue function evaluation, with targeted accuracy improvements, plus a residue override mechanism that triggers re-executions for absorption cases and assembles patchwork results. All claims rest on empirical evaluation across 44 large workloads and 169 standard benchmarks, reporting concrete reductions in false reports (e.g., elimination on 10 of 14, reduction on 25 of 34) and average re-execution counts. No equations, derivations, or first-principles results are presented that reduce by construction to fitted parameters, self-definitions, or self-citation chains. The approach is externally validated against independent benchmarks without internal circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard properties of IEEE 754 floating-point arithmetic and error-free transformations hold as described in prior literature
invented entities (1)
-
residue override
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Tao Bao and Xiangyu Zhang. 2013. On-the-fly Detection of Instability Problems in Floating-point Program Execution. SIGPLAN Not.48, 10 (Oct. 2013), 817–832. doi:10.1145/2544173.2509526
-
[2]
NAS Parallel Benchmarks. 2006. Nas parallel benchmarks.CG and IS(2006). , Vol. 1, No. 1, Article . Publication date: April 2018. 22 Yumeng He and Pavel Panchekha
2006
-
[3]
Florian Benz, Andreas Hildebrandt, and Sebastian Hack. 2012. A Dynamic Program Analysis to Find Floating-point Accuracy Problems(PLDI ’12). ACM, New York, NY, USA, 453–462. http://doi.acm.org/10.1145/2254064.2254118
-
[4]
Shuai Che, M Boyer, Jiayuan Meng, D Tarjan, J Sheaffer, S Lee, and K Skadron. 2009. Rodinia: Accelerating compute- intensive applications with accelerators. InIISWC
2009
-
[5]
Sangeeta Chowdhary, Jay P. Lim, and Santosh Nagarakatte. 2020. Debugging and detecting numerical errors in computation with posits. InProceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation(London, UK)(PLDI 2020). Association for Computing Machinery, New York, NY, USA, 731–746. doi:10.1145/3385412.3386004
-
[6]
Sangeeta Chowdhary and Santosh Nagarakatte. 2021. Parallel shadow execution to accelerate the debugging of numerical errors. InProceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Athens, Greece)(ESEC/FSE 2021). Association for Computing Machinery, New York, NY, USA,...
-
[7]
Sangeeta Chowdhary and Santosh Nagarakatte. 2022. Fast shadow execution for debugging numerical errors using error free transformations.Proceedings of the ACM on Programming Languages6, OOPSLA2 (2022), 1845–1872
2022
-
[8]
Nasrine Damouche and Matthieu Martel. 2017. Salsa: An automatic tool to improve the numerical accuracy of programs (AFM)
2017
-
[9]
Nasrine Damouche, Matthieu Martel, Pavel Panchekha, Jason Qiu, Alex Sanchez-Stern, and Zachary Tatlock. 2016. Toward a Standard Benchmark Format and Suite for Floating-Point Analysis. (July 2016)
2016
- [10]
-
[11]
Arnab Das, Ian Briggs, Ganesh Gopalakrishnan, Sriram Krishnamoorthy, and Pavel Panchekha. 2020. Scalable yet Rigorous Floating-Point Error Analysis. In2020 SC20: International Conference for High Performance Computing, Networking, Storage and Analysis (SC). IEEE Computer Society, Los Alamitos, CA, USA, 1–14. doi:10.1109/SC41405. 2020.00055
-
[12]
Arnab Das, Tanmay Tirpankar, Ganesh Gopalakrishnan, and Sriram Krishnamoorthy. 2021. Robustness Analysis of Loop-Free Floating-Point Programs via Symbolic Automatic Differentiation. In2021 IEEE International Conference on Cluster Computing (CLUSTER). 481–491. doi:10.1109/Cluster48925.2021.00055
-
[13]
Nestor Demeure, Cédric Chevalier, Christophe Denis, and Pierre Dossantos-Uzarralde. 2023. Algorithm 1029: En- capsulated Error, a Direct Approach to Evaluate Floating-Point Accuracy.ACM Trans. Math. Software48, 4 (2023), 1–16
2023
-
[14]
François Févotte and Bruno Lathuilière. 2016. VERROU: Assessing Floating-Point Accuracy Without Recompiling. (Oct. 2016). https://hal.archives-ouvertes.fr/hal-01383417
2016
-
[15]
Laurent Fousse, Guillaume Hanrot, Vincent Lefèvre, Patrick Pélissier, and Paul Zimmermann. 2007. MPFR: A Multiple- Precision Binary Floating-Point Library with Correct Rounding.ACM Trans. Math. Software33, 2 (June 2007), 13:1–13:15. http://doi.acm.org/10.1145/1236463.1236468
-
[16]
Nicholas J. Higham. 2002.Accuracy and Stability of Numerical Algorithms(2nd ed.). Society for Industrial and Applied Mathematics
2002
-
[17]
Anastasiia Izycheva and Eva Darulova. 2017. On sound relative error bounds for floating-point arithmetic(FMCAD). 15–22. doi:10.23919/FMCAD.2017.8102236
-
[18]
William Kahan. 1983. Mathematics written in sand. InProc. Joint Statistical Mtg. of the American Statistical Association. Citeseer, 12–26
1983
-
[19]
Kellison, Laura Zielinski, David Bindel, and Justin Hsu
Ariel E. Kellison, Laura Zielinski, David Bindel, and Justin Hsu. 2025. Bean: A Language for Backward Error Analysis. Proc. ACM Program. Lang.9, PLDI, Article 221 (June 2025), 25 pages. doi:10.1145/3729324
-
[20]
Bhargav Kulkarni and Pavel Panchekha. 2025. Mixing Condition Numbers and Oracles for Accurate Floating-point Debugging. In2025 IEEE 32nd Symposium on Computer Arithmetic (ARITH). 101–108. doi:10.1109/ARITH64983.2025. 00025
-
[21]
Wen-Chuan Lee, Tao Bao, Yunhui Zheng, Xiangyu Zhang, Keval Vora, and Rajiv Gupta. 2015. RAIVE: runtime assessment of floating-point instability by vectorization. InProceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications(Pittsburgh, PA, USA)(OOPSLA 2015). Association for Computing Ma...
-
[22]
Chenghu Ma, Liqian Chen, Xin Yi, Guangsheng Fan, and Ji Wang. 2022. NuMFUZZ: A Floating-Point Format Aware Fuzzer for Numerical Programs. In2022 29th Asia-Pacific Software Engineering Conference (APSEC). 338–347. doi:10.1109/APSEC57359.2022.00046
-
[23]
B. D. McCullough and H. D. Vinod. 1999. The Numerical Reliability of Econometric Software.Journal of Economic Literature37, 2 (1999), 633–665
1999
-
[24]
Muller, N
J.-M. Muller, N. Brisebarre, F. de Dinechin, C.-P. Jeannerod, V. Lefévre, G. Melquiond, N. Revol, D. Stehlé, and S. Torres. 2010.Handbook of Floating Point Arithmetic. Birkhäuser Boston. , Vol. 1, No. 1, Article . Publication date: April 2018. Accurate Residues for Floating-Point Debugging 23
2010
-
[25]
Louis-Noël Pouchet. 2012. Polybench/C. https://www.cs.colostate.edu/~pouchet/software/polybench/
2012
-
[26]
Kevin Quinn. 1983. Ever Had Problems Rounding Off Figures? This Stock Exchange Has.The Wall Street Journal (November 8, 1983), 37
1983
-
[27]
Alex Sanchez-Stern, Pavel Panchekha, Sorin Lerner, and Zachary Tatlock. 2018. Finding Root Causes of Floating Point Error(PLDI). 256–269. doi:10.1145/3192366.3192411
-
[28]
Alexey Solovyev, Charlie Jacobsen, Zvonimir Rakamaric, and Ganesh Gopalakrishnan. 2015. Rigorous Estimation of Floating-Point Round-off Errors with Symbolic Taylor Expansions(FM)
2015
-
[29]
General Accounting Office
U.S. General Accounting Office. 1992. Patriot Missile Defense: Software Problem Led to System Failure at Dhahran, Saudi Arabia. http://www.gao.gov/products/IMTEC-92-26
1992
-
[30]
Debora Weber-Wulff. 1992. Rounding error changes Parliament makeup. http://catless.ncl.ac.uk/Risks/13.37.html#subj4
1992
-
[31]
Daming Zou, Muhan Zeng, Yingfei Xiong, Zhoulai Fu, Lu Zhang, and Zhendong Su. 2019. Detecting floating-point errors via atomic conditions.Proc. ACM Program. Lang.4, POPL, Article 60 (dec 2019), 27 pages. doi:10.1145/3371128 , Vol. 1, No. 1, Article . Publication date: April 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.