Recognition: 2 theorem links
· Lean TheoremBeyond Functional Correctness: Design Issues in AI IDE-Generated Large-Scale Projects
Pith reviewed 2026-05-10 18:21 UTC · model grok-4.3
The pith
Cursor with a feature-driven human-in-the-loop process generates functional projects averaging 17,000 lines of code, yet these projects contain thousands of design issues that threaten long-term maintainability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers. The most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; these design issues violate design principles such as SRP, SoC, and DRY.
What carries the argument
The Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated descriptions, paired with CodeScene and SonarQube static analysis to surface design issues.
Load-bearing premise
The design issues reported by CodeScene and SonarQube accurately predict real maintainability and evolvability problems that would appear when the generated projects are maintained or extended in practice.
What would settle it
A controlled maintenance experiment that measures the time and defect rates required to add new features to one of the AI-generated projects versus an equivalent human-written codebase over several iterations.
Figures
















read the original abstract
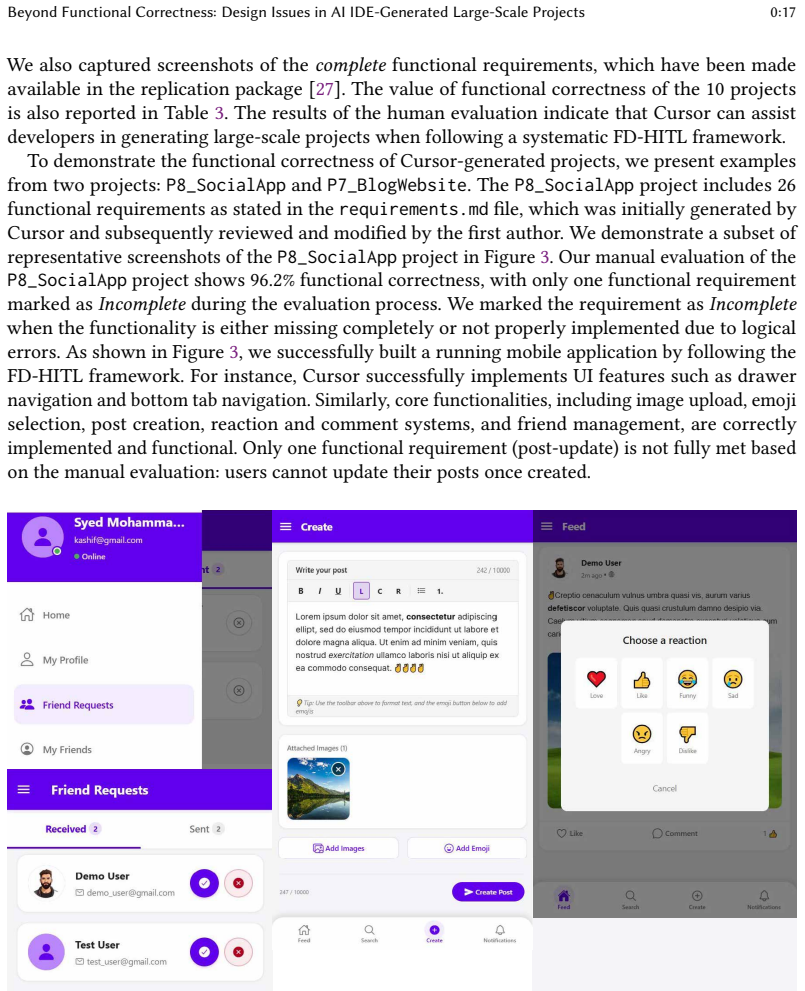
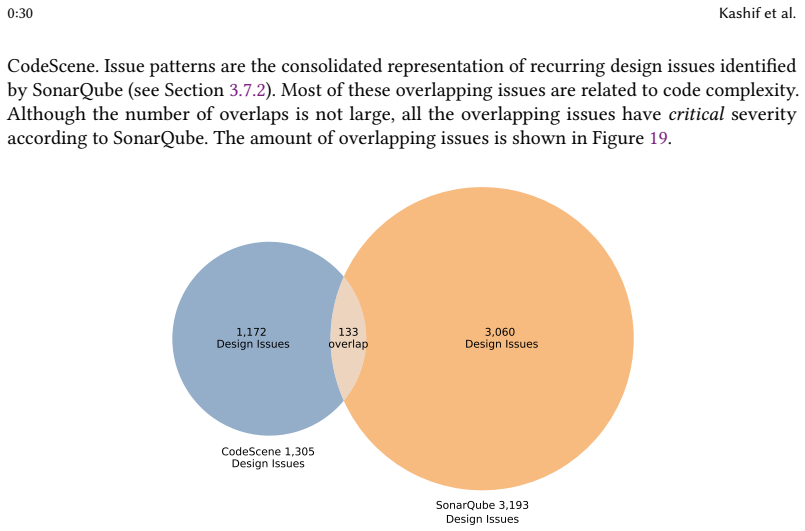
New generation of AI coding tools, including AI-powered IDEs equipped with agentic capabilities, can generate code within the context of the project. These AI IDEs are increasingly perceived as capable of producing project-level code at scale. However, there is limited empirical evidence on the extent to which they can generate large-scale software systems and what design issues such systems may exhibit. To address this gap, we conducted a study to explore the capability of Cursor in generating large-scale projects and to evaluate the design quality of projects generated by Cursor. First, we propose a Feature-Driven Human-In-The-Loop (FD-HITL) framework that systematically guides project generation from curated project descriptions. We generated 10 projects using Cursor with the FD-HITL framework across three application domains and multiple technologies. We assessed the functional correctness of these projects through manual evaluation, obtaining an average functional correctness score of 91%. Next, we analyzed the generated projects using two static analysis tools, CodeScene and SonarQube, to detect design issues. We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube. Our findings show that (1) when used with the FD-HITL framework, Cursor can generate functional large-scale projects averaging 16,965 LoC and 114 files; (2) the generated projects nevertheless contain design issues that may pose long-term maintainability and evolvability risks, requiring careful review by experienced developers; (3) the most prevalent issues include Code Duplication, high Code Complexity, Large Methods, Framework Best-Practice Violations, Exception-Handling Issues and Accessibility Issues; (4) these design issues violate design principles such as SRP, SoC, and DRY. The replication package is at https://github.com/Kashifraz/DIinAGP
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Feature-Driven Human-In-The-Loop (FD-HITL) framework to guide Cursor AI IDE in generating large-scale projects from curated descriptions. It reports results from 10 projects (averaging 16,965 LoC and 114 files across three domains) that achieve 91% functional correctness by manual evaluation. Static analysis via CodeScene (1,305 issues in 9 categories) and SonarQube (3,193 issues in 11 categories) identifies prevalent problems including code duplication, high complexity, large methods, framework violations, exception handling, and accessibility issues. These are mapped to violations of SRP, SoC, and DRY, leading to the conclusion that the projects contain design issues posing long-term maintainability and evolvability risks and thus require careful review by experienced developers. A replication package is provided.
Significance. If the link between static-analysis flags and real maintainability risks holds, the work provides valuable empirical evidence on the current limits of agentic AI IDEs for producing production-scale code. The FD-HITL framework, concrete project-scale metrics, and open replication package are strengths that could inform both practitioners using these tools and researchers studying AI-assisted software engineering. The shift from functional correctness alone to design-quality assessment addresses a timely gap.
major comments (3)
- [Abstract] Abstract, finding (2): the claim that the identified design issues 'may pose long-term maintainability and evolvability risks' rests entirely on heuristic outputs from CodeScene and SonarQube without any direct validation. No expert review, maintenance-task experiments, defect-rate measurements, or comparison against human-written equivalents is reported to show that the 1,305 + 3,193 detections would actually increase costs or defects in practice, especially for LLM-generated structures that may trigger false positives in rule-based tools.
- [Methods] Methods section (project selection and manual evaluation): the description of how the 10 projects and three domains were chosen is insufficiently detailed, and the 91% functional-correctness score lacks reporting of inter-rater reliability, number of evaluators, or the concrete test cases and acceptance criteria used. These omissions weaken confidence in both the scale and correctness claims.
- [Results] Results (design-issue categorization): the mapping of tool detections to SRP, SoC, and DRY violations is stated without per-category examples, code snippets, or quantitative justification showing how specific CodeScene/SonarQube rules correspond to these principles in the generated artifacts. This makes the principle-violation claim difficult to assess.
minor comments (2)
- [Abstract] Abstract: the three application domains and the specific technologies used are mentioned but not named; adding this information would improve readability.
- [Replication package] The replication package URL is given but should be accompanied by a brief description of its contents (e.g., project prompts, generated code, tool reports) to aid reviewers and readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps us improve the clarity and rigor of our work. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract, finding (2): the claim that the identified design issues 'may pose long-term maintainability and evolvability risks' rests entirely on heuristic outputs from CodeScene and SonarQube without any direct validation. No expert review, maintenance-task experiments, defect-rate measurements, or comparison against human-written equivalents is reported to show that the 1,305 + 3,193 detections would actually increase costs or defects in practice, especially for LLM-generated structures that may trigger false positives in rule-based tools.
Authors: We agree that the maintainability-risk claim is grounded in outputs from established static-analysis tools rather than direct validation experiments. CodeScene and SonarQube are widely adopted in both industry and research, with prior studies demonstrating correlations between their metrics and real maintenance effort; however, we acknowledge that LLM-generated code may introduce unique false-positive risks not fully explored here. To address this, we will revise the abstract to qualify the statement (e.g., 'may indicate potential long-term risks according to static-analysis heuristics') and add an explicit limitations subsection discussing tool applicability to AI-generated artifacts and the absence of direct maintenance-task validation, while noting this as future work. This keeps the contribution focused on applying these tools to AI IDE output while avoiding overstatement. revision: partial
-
Referee: [Methods] Methods section (project selection and manual evaluation): the description of how the 10 projects and three domains were chosen is insufficiently detailed, and the 91% functional-correctness score lacks reporting of inter-rater reliability, number of evaluators, or the concrete test cases and acceptance criteria used. These omissions weaken confidence in both the scale and correctness claims.
Authors: We thank the referee for identifying these reporting gaps. In the revised manuscript we will expand the Methods section with: (1) explicit selection criteria for the 10 projects and three domains, including rationale for domain diversity and technology choices to support representativeness; (2) details that functional evaluation was performed by two independent evaluators with a third resolving conflicts; (3) the computed inter-rater reliability (Cohen's kappa); and (4) representative test cases and acceptance criteria per project. These additions will strengthen reproducibility and reader confidence in the scale and correctness results. revision: yes
-
Referee: [Results] Results (design-issue categorization): the mapping of tool detections to SRP, SoC, and DRY violations is stated without per-category examples, code snippets, or quantitative justification showing how specific CodeScene/SonarQube rules correspond to these principles in the generated artifacts. This makes the principle-violation claim difficult to assess.
Authors: We accept that the current mapping lacks sufficient illustrative support. In the revision we will augment the Results section by adding: concrete per-category examples (e.g., a duplicated code fragment violating DRY), anonymized code snippets drawn from the generated projects, and a justification table that links specific tool rules (such as SonarQube cognitive complexity or CodeScene duplication metrics) to the relevant principles (SRP, SoC, DRY) with quantitative counts of how many issues fall under each mapping. This will make the principle-violation analysis transparent and easier to evaluate. revision: yes
Circularity Check
No significant circularity in empirical analysis of generated projects
full rationale
This is a direct empirical study: the authors define an FD-HITL framework, use it to generate 10 projects via Cursor, manually score functional correctness at 91%, and then apply independent external static-analysis tools (CodeScene, SonarQube) to count design-issue detections. No equations, fitted parameters, or predictions are defined in terms of the target claims; the mapping of tool flags to SRP/SoC/DRY is interpretive but not self-referential. The central results (LoC counts, issue tallies, prevalence rankings) are measurements of generated artifacts rather than derivations that collapse to the paper's own inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked to force the conclusions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Static analysis tools CodeScene and SonarQube accurately detect design issues that matter for long-term maintainability and evolvability.
- domain assumption The ten projects generated via FD-HITL are representative of large-scale software systems.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identified 1,305 design issues categorized into 9 categories by CodeScene and 3,193 issues in 11 categories by SonarQube... violations of SRP, SoC, and DRY
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
average functional correctness score of 91%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shraddha Barke, Michael B James, and Nadia Polikarpova. 2023. Grounded copilot: How programmers interact with code-generating models.Proceedings of the ACM on Programming Languages7, OOPSLA1 (2023), 85–111
2023
- [2]
-
[3]
Markus Borg, Marwa Ezzouhri, and Adam Tornhill. 2024. Ghost Echoes Revealed: Benchmarking Maintainability Metrics and Machine Learning Predictions Against Human Assessments. InProceedings of the 40th International Conference on Software Maintenance and Evolution (ICSME). IEEE, 678–688
2024
-
[4]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101
2006
-
[5]
John L Campbell, Charles Quincy, Jordan Osserman, and Ove K Pedersen. 2013. Coding in-depth semistructured interviews: Problems of unitization and intercoder reliability and agreement.Sociological Methods & Research42, 3 (2013), 294–320
2013
-
[6]
Alexander Chatzigeorgiou and Anastasios Manakos. 2014. Investigating the evolution of code smells in object-oriented systems.Innovations in Systems and Software Engineering10, 1 (2014), 3–18
2014
-
[7]
2026.Claude Code
Claude. 2026.Claude Code. https://code.claude.com/docs/en/overview#jetbrains [Accessed 2026-01-11]
2026
-
[8]
2026.CodeScene
CodeScene. 2026.CodeScene. https://codescene.com/ [Accessed 2026-01-11]
2026
-
[9]
2024.Amazon CodeWhisperer
CodeWhisperer. 2024.Amazon CodeWhisperer. https://docs.aws.amazon.com/codewhisperer/latest/userguide/what-is- cwspr.html [Accessed 2025-08-10]
2024
-
[10]
2024.GitHub Copilot
Copilot. 2024.GitHub Copilot. https://github.com/copilot/ [Accessed 2025-08-10]. ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. 0:38 Kashif et al
2024
-
[11]
Domenico Cotroneo, Cristina Improta, and Pietro Liguori. 2025. Human-written vs. ai-generated code: A large-scale study of defects, vulnerabilities, and complexity. InProceeding of the 36th IEEE International Symposium on Software Reliability Engineering (ISSRE). IEEE, 252–263
2025
-
[12]
2026.Cursor
Cursor. 2026.Cursor. https://cursor.com/ [Accessed 2026-01-11]
2026
-
[13]
Arghavan Moradi Dakhel, Vahid Majdinasab, Amin Nikanjam, Foutse Khomh, Michel C Desmarais, and Zhen Ming Jack Jiang. 2023. Github copilot ai pair programmer: Asset or liability?Journal of Systems and Software203 (2023), 111734
2023
-
[14]
Simone Daniotti, Johannes Wachs, Xiangnan Feng, and Frank Neffke. 2026. Who is using AI to code? Global diffusion and impact of generative AI.Science391, 6787 (2026), 831–835
2026
-
[15]
2024.Gemini
Google DeepMind. 2024.Gemini. https://gemini.google.com/ [Accessed 2025-08-10]
2024
-
[16]
Georgios Digkas, Mircea Lungu, Alexander Chatzigeorgiou, and Paris Avgeriou. 2017. The evolution of technical debt in the apache ecosystem. InProceedings of the 11th European Conference on Software Architecture (ECSA). Springer, 51–66
2017
-
[17]
Philipp Eibl, Sadra Sabouri, and Souti Chattopadhyay. 2025. Exploring the Challenges and Opportunities of AI-assisted Codebase Generation. InProceeding of the 41st IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 241–252
2025
-
[18]
Etemadi, N
K. Etemadi, N. Harrand, S. Larsen, H. Adzemovic, H. L. Phu, A. Verma, others, and M. Monperrus. 2022. Sorald: Automatic patch suggestions for sonarqube static analysis violations.IEEE Transactions on Dependable and Secure Computing20, 4 (2022), 2794–2810
2022
-
[19]
Ahmed Fawzy, Amjed Tahir, and Kelly Blincoe. 2026. Vibe Coding in Practice: Motivations, Challenges, and a Future Outlook–a Grey Literature Review. InProceedings of the 48th International Conference on Software Engineering (ICSE): SEIP Track. ACM
2026
-
[20]
2008.A voiding Repetition
Martin Fowler. 2008.A voiding Repetition. https://martinfowler.com/ieeeSoftware/repetition.pdf [Accessed 2026-02-27]
2008
-
[21]
Yujia Fu, Peng Liang, Amjed Tahir, Zengyang Li, Mojtaba Shahin, Jiaxin Yu, and Jinfu Chen. 2025. Security weaknesses of copilot-generated code in github projects: An empirical study.ACM Transactions on Software Engineering and Methodology34, 8 (2025), 1–34
2025
- [22]
-
[23]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. 2023. MetaGPT: Meta programming for a multi-agent collaborative framework. InProceedings of the 12th International Conference on Learning Representations (ICLR). OpenReview.net, 1–29
2023
-
[24]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
2024
- [25]
-
[26]
Kailun Jin, Chung-Yu Wang, Hung Viet Pham, and Hadi Hemmati. 2024. Can ChatGPT Support Developers? An Empirical Evaluation of Large Language Models for Code Generation. InProceedings of the 21st IEEE/ACM International Conference on Mining Software Repositories (MSR). 167–171
2024
-
[27]
Syed Mohammad Kashif, Ruiyin Li, Peng Liang, Amjed Tahir, Qiong Feng, Zengyang Li, and Mojtaba Shahin. 2026. Dataset for the Paper: Beyond Functional Correctness: Design Issues in AI IDE Generated Large-Scale Projects. https://github.com/Kashifraz/DIinAGP
2026
-
[28]
Syed Mohammad Kashif, Peng Liang, and Amjed Tahir. 2025. On Developers’ Self-Declaration of AI-Generated Code: An Analysis of Practices.ACM Transactions on Software Engineering and Methodology(2025)
2025
- [29]
-
[30]
Yulia Kumar, Israel Akinwunmi, and Dov Kruger. 2025. Evaluating the Advantage of an AI-Native IDE Cursor on Programmer Performance. InProceedings of the 15th IEEE Integrated STEM Education Conference (ISEC). IEEE, 1–8
2025
-
[31]
Jasmine Latendresse, Suhaib Mujahid, Diego Elias Costa, and Emad Shihab. 2022. Not all dependencies are equal: An empirical study on production dependencies in npm. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE). ACM, 1–12
2022
- [32]
-
[33]
Ruiyin Li, Peng Liang, Yifei Wang, Yangxiao Cai, Weisong Sun, and Zengyang Li. 2025. Unveiling the role of chatgpt in software development: Insights from developer-chatgpt interactions on github.ACM Transactions on Software Engineering and Methodology(2025). ACM Trans. Softw. Eng. Methodol., Vol. 0, No. 0, Article 0. Publication date: 2026. Beyond Functio...
2025
-
[34]
Yichen Li, Yun Peng, Yintong Huo, and Michael R Lyu. 2024. Enhancing LLM-based coding tools through native integration of ide-derived static context. InProceedings of the 1st International Workshop on Large Language Models for Code (LLM4Code). ACM, 70–74
2024
-
[35]
Jenny T Liang, Chenyang Yang, and Brad A Myers. 2024. A large-scale survey on the usability of AI programming assis- tants: Successes and challenges. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering (ICSE). ACM, 1–13
2024
-
[36]
Yue Liu, Thanh Le-Cong, Ratnadira Widyasari, Chakkrit Tantithamthavorn, Li Li, Xuan-Bach D Le, and David Lo. 2024. Refining chatgpt-generated code: Characterizing and mitigating code quality issues.ACM Transactions on Software Engineering and Methodology33, 5 (2024), 1–26
2024
-
[37]
2025.Harness Engineering: Leveraging Codex in an Agent-First World
Ryan Lopopolo. 2025.Harness Engineering: Leveraging Codex in an Agent-First World. https://openai.com/index/harness- engineering/ [Accessed 2026-03-25]
2025
- [38]
-
[39]
Md Abdullah Al Mamun, Christian Berger, and Jörgen Hansson. 2017. Correlations of software code metrics: an empirical study. InProceedings of the 27th International Workshop on Software Measurement and 12th International Conference on Software Process and Product Measurement (IWSM Mensura). ACM, 255–266
2017
-
[40]
2009.Clean Code: A Handbook of Agile Software Craftsmanship
Robert C Martin. 2009.Clean Code: A Handbook of Agile Software Craftsmanship. Pearson Education
2009
-
[41]
Robert C. Martin. 2014.The Single Responsibility Principle. https://blog.cleancoder.com/uncle-bob/2014/05/08/ SingleReponsibilityPrinciple.html [Accessed 2026-02-27]
2014
-
[42]
Nora McDonald, Sarita Schoenebeck, and Andrea Forte. 2019. Reliability and Inter-rater Reliability in Qualitative Research: Norms and Guidelines for CSCW and HCI Practice.Proceedings of the ACM on Human-Computer Interaction 3, CSCW (2019), 1–23
2019
-
[43]
Naouel Moha, Yann-Gaël Guéhéneuc, Laurence Duchien, and Anne-Francoise Le Meur. 2010. DECOR: A Method for the Specification and Detection of Code and Design Smells.IEEE Transactions on Software Engineering36, 1 (2010), 20–36
2010
-
[44]
Minh Huynh Nguyen, Thang Phan Chau, Phong X Nguyen, and Nghi DQ Bui. 2025. Agilecoder: Dynamic collaborative agents for software development based on agile methodology. InProceedings of the 2nd IEEE/ACM International Conference on AI Foundation Models and Software Engineering (FORGE). IEEE, 156–167
2025
-
[45]
2024.ChatGPT
OpenAI. 2024.ChatGPT. https://openai.com/index/chatgpt/ [Accessed 2025-08-10]
2024
-
[46]
2026.Codex
OpenAI. 2026.Codex. https://openai.com/codex/ [Accessed 2026-01-11]
2026
-
[47]
Shuyin Ouyang, Jie M Zhang, Mark Harman, and Meng Wang. 2024. An empirical study of the non-determinism of chatgpt in code generation.ACM Transactions on Software Engineering and Methodology34, 2 (2024), 1–28
2024
-
[48]
2001.A Practical Guide to Feature-Driven Development
Steve R Palmer and Mac Felsing. 2001.A Practical Guide to Feature-Driven Development. Pearson Education
2001
-
[49]
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. 2022. Asleep at the keyboard? assessing the security of github copilot’s code contributions. InProceeings of the 43rd IEEE Symposium on Security and Privacy (SP). IEEE, 754–768
2022
-
[50]
2023.The 10 Most Common Projects
Dan Politz. 2023.The 10 Most Common Projects. https://getcredo.com/common-project-custom-web-development- company/
2023
- [51]
- [52]
-
[53]
Alfred Santa Molison, Marcia Moraes, Glaucia Melo, Fabio Santos, and Wesley KG Assuncao. 2025. Is LLM-Generated Code More Maintainable & Reliable Than Human-Written Code?. InProceeding of the 19th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). IEEE, 151–162
2025
-
[54]
Jim Shore. 2004. Fail fast [software debugging].IEEE Software21, 5 (2004), 21–25
2004
-
[55]
2025.100+ Mobile App Ideas
Nikhil Solanki. 2025.100+ Mobile App Ideas. https://www.manektech.com/blog/mobile-app-ideas
2025
-
[56]
2026.SonarQube
SonarSource. 2026.SonarQube. https://www.sonarsource.com/products/sonarqube/ [Accessed 2026-01-11]
2026
-
[57]
César Soto-Valero, Nicolas Harrand, Martin Monperrus, and Benoit Baudry. 2021. A comprehensive study of bloated dependencies in the maven ecosystem.Empirical Software Engineering26, 3 (2021), 1–44
2021
-
[58]
2025.Stack Overflow Developer Survey
StackOverflow. 2025.Stack Overflow Developer Survey. https://survey.stackoverflow.co/2025/ [Accessed on 2025-08-27]
2025
-
[59]
Florian Tambon, Arghavan Moradi-Dakhel, Amin Nikanjam, Foutse Khomh, Michel C Desmarais, and Giuliano Antoniol. 2025. Bugs in large language models generated code: An empirical study.Empirical Software Engineering30, 3 (2025), 1–48
2025
- [60]
-
[61]
Peri Tarr, Harold Ossher, William Harrison, and Stanley M Sutton Jr. 1999. N Degrees of Separation: Multi-Dimensional Separation of Concerns. InProceedings of the 21st International Conference on Software Engineering (ICSE). ACM, 107–119
1999
- [62]
-
[63]
Adam Tornhill and Markus Borg. 2022. Code red: the business impact of code quality-a quantitative study of 39 proprietary production codebases. InProceedings of the 5th International Conference on Technical Debt (TechDebt). IEEE, 11–20
2022
-
[64]
Jonathan Ullrich, Matthias Koch, and Andreas Vogelsang. 2025. From requirements to code: Understanding developer practices in llm-assisted software engineering. InProceeding of the 33rd IEEE International Requirements Engineering Conference (RE). IEEE, 257–266
2025
- [65]
-
[66]
Thomas Weber, Maximilian Brandmaier, Albrecht Schmidt, and Sven Mayer. 2024. Significant productivity gains through programming with large language models.Proceedings of the ACM on Human-Computer Interaction8, EICS (2024), 1–29
2024
-
[67]
Aiko Yamashita and Leon Moonen. 2012. Do code smells reflect important maintainability aspects?. InProceedings of the 28th IEEE International Conference on Software Maintenance (ICSM). IEEE, 306–315
2012
-
[68]
Daniel M Yellin. 2023. The premature obituary of programming.Commun. ACM66 (2023), 41–44
2023
-
[69]
P. Yu, Y. Wu, J. Peng, J. Zhang, and P. Xie. 2023. Towards Understanding Fixes of SonarQube Static Analysis Violations: A Large-Scale Empirical Study. InProceedings of the 30th International Conference on Software Analysis, Evolution and Reengineering (SANER). IEEE, 569–580
2023
- [70]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.