Recognition: 2 theorem links
· Lean TheoremLanguage-Guided Multimodal Texture Authoring via Generative Models
Pith reviewed 2026-05-10 18:31 UTC · model grok-4.3
The pith
A shared language-aligned latent space lets single text prompts generate coordinated haptic vibrations, tapping transients, and visual previews for texture authoring.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training a shared latent space that aligns language with multiple generative models, one prompt produces semantically matched outputs: force- and speed-conditioned autoregressive sequences for sliding haptic vibrations, transient signals for tapping, and diffusion-based visual renderings. Anchor-referenced ratings reveal that the outputs track expected perceptual trends, such as asperity effects in roughness and compliance in hardness, while participants report coherent multimodal sensations and reduced authoring effort.
What carries the argument
The shared, language-aligned latent space that links text prompts to coordinated outputs from autoregressive haptic models and diffusion visual models.
If this is right
- Designers can author multimodal textures by writing goals in plain language rather than adjusting low-level parameters through trial and error.
- A single prompt simultaneously steers sliding vibrations, tapping transients, and visual appearance while preserving semantic consistency.
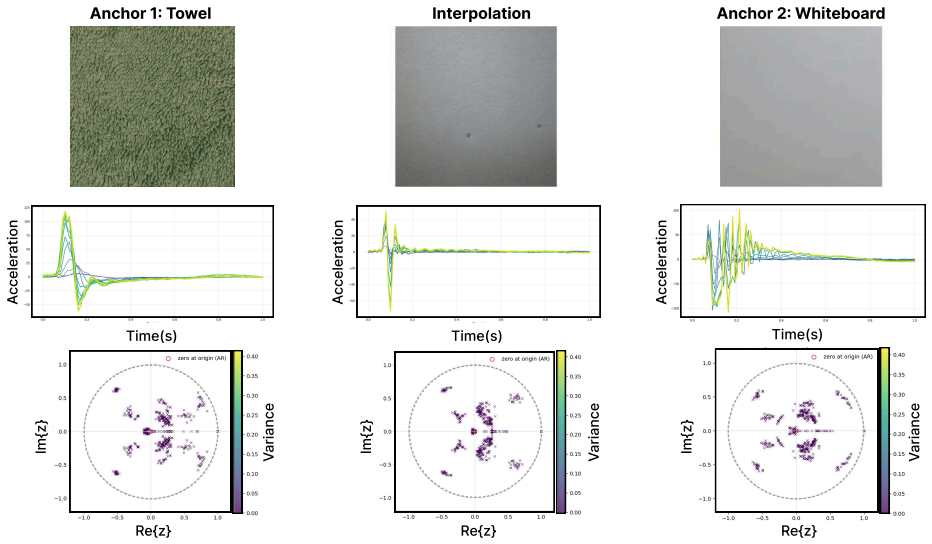
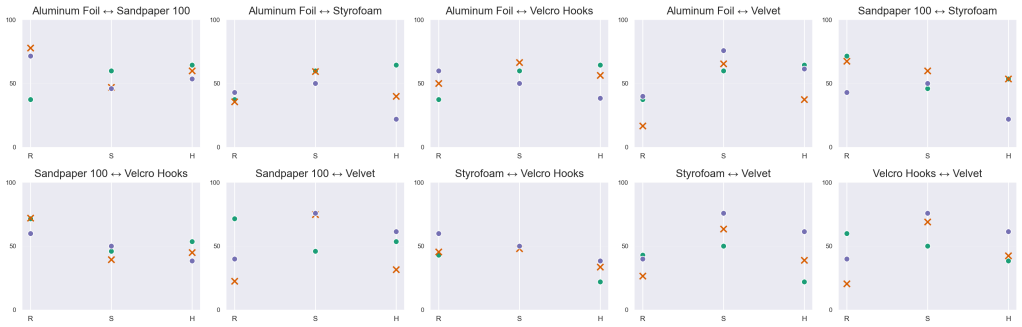
- Ratings projected between real references demonstrate that roughness tracks surface asperity, hardness tracks compliance, and slipperiness tracks surface film effects.
- Users experience coherent cross-modal feedback and report low effort when iterating via text prompts on a 3D haptic device.
Where Pith is reading between the lines
- The same alignment technique could be tested on additional attributes such as temperature or stickiness to expand the range of controllable material properties.
- Integration with real-time rendering engines might allow prompt-driven texture updates during interactive design sessions.
- The approach suggests a path for extending language control to other paired modalities, such as sound and force profiles, if similar latent alignment can be achieved.
Load-bearing premise
The learned latent space captures perceptually meaningful structure that generalizes beyond the training examples and the three evaluated material attributes.
What would settle it
Participant ratings of the generated textures fail to form consistent, interpretable trends when projected onto lines between real-material anchors for roughness, slipperiness, or hardness, or different prompts produce outputs that participants judge as semantically mismatched across the haptic and visual channels.
Figures








read the original abstract
Authoring realistic haptic textures typically requires low-level parameter tuning and repeated trial-and-error, limiting speed, transparency, and creative reach. We present a language-driven authoring system that turns natural-language prompts into multimodal textures: two coordinated haptic channels - sliding vibrations via force/speed-conditioned autoregressive (AR) models and tapping transients - and a text-prompted visual preview from a diffusion model. A shared, language-aligned latent links modalities so a single prompt yields semantically consistent haptic and visual signals; designers can write goals (e.g., "gritty but cushioned surface," "smooth and hard metal surface") and immediately see and feel the result through a 3D haptic device. To verify that the learned latent encodes perceptually meaningful structure, we conduct an anchor-referenced, attribute-wise evaluation for roughness, slipperiness, and hardness. Participant ratings are projected to the interpretable line between two real-material references, revealing consistent trends - asperity effects in roughness, compliance in hardness, and surface-film influence in slipperiness. A human-subject study further indicates coherent cross-modal experience and low effort for prompt-based iteration. The results show that language can serve as a practical control modality for texture authoring: prompts reliably steer material semantics across haptic and visual channels, enabling a prompt-first, designer-oriented workflow that replaces manual parameter tuning with interpretable, text-guided refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a language-guided multimodal texture authoring system that maps natural-language prompts to coordinated haptic outputs (force/speed-conditioned AR models for sliding vibrations and tapping transients) and visual previews (diffusion model) via a shared language-aligned latent space. A single prompt is claimed to produce semantically consistent cross-modal results. Verification relies on an anchor-referenced user study in which participant ratings for roughness, slipperiness, and hardness are projected onto lines between real-material references, yielding 'consistent trends,' plus a separate human-subject study reporting coherent cross-modal experience and low iteration effort.
Significance. If the central claim holds, the work could meaningfully advance prompt-based, designer-oriented workflows in haptics and HCI by replacing manual parameter tuning with interpretable language control. The anchor-referenced projection method and cross-modal consistency demonstration are potentially useful contributions. However, the absence of quantitative metrics, model details, ablations, and controls for visual bias limits the strength of the evidence that the latent encodes generalizable perceptual structure.
major comments (3)
- [User evaluation / anchor-referenced study] User evaluation section: the anchor-referenced projection of ratings onto lines between real-material references for roughness, slipperiness, and hardness implicitly assumes linear perceptual interpolation and that the chosen anchors span the relevant semantics without bias. No validation of linearity, no ablation of anchor choice, and no controls separating haptic signals from the accompanying visual diffusion preview are provided; if ratings are driven primarily by visuals, the evidence that the shared latent itself encodes perceptually meaningful cross-modal structure collapses.
- [Methods / system architecture] Methods / system description: no quantitative metrics, training details, model architectures, loss functions, or error analysis are reported for the AR haptic models, diffusion visual model, or the shared language-aligned latent. Without these, the reliability of the semantic-steering claim cannot be assessed and the work is not reproducible.
- [Evaluation / experiments] No ablation studies (e.g., shared latent vs. independent modality models or language vs. non-language conditioning) are described. Such comparisons are load-bearing for the claim that the language-aligned latent is what produces the observed cross-modal consistency.
minor comments (2)
- [Abstract / Introduction] The abstract and introduction could more clearly distinguish the novel contribution (shared latent) from the component generative models.
- [Figures / evaluation plots] Figure captions and axis labels in the evaluation plots should explicitly state the projection method and any statistical tests used to support 'consistent trends.'
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where additional clarification, details, and caveats can strengthen the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: User evaluation section: the anchor-referenced projection of ratings onto lines between real-material references for roughness, slipperiness, and hardness implicitly assumes linear perceptual interpolation and that the chosen anchors span the relevant semantics without bias. No validation of linearity, no ablation of anchor choice, and no controls separating haptic signals from the accompanying visual diffusion preview are provided; if ratings are driven primarily by visuals, the evidence that the shared latent itself encodes perceptually meaningful cross-modal structure collapses.
Authors: We agree that the anchor-referenced projection method rests on an unvalidated linearity assumption and that the study did not ablate anchor selection or isolate haptic ratings from visual previews. These are legitimate concerns that could affect interpretation of the latent's cross-modal contribution. In the revised manuscript we will add an explicit limitations subsection in the evaluation that states these assumptions, notes the lack of linearity validation and modality-isolation controls, and discusses potential visual bias. We will also emphasize that the observed attribute trends align with established haptic literature. We cannot perform new controlled experiments for this revision but will flag the need for such studies as future work. revision: partial
-
Referee: Methods / system description: no quantitative metrics, training details, model architectures, loss functions, or error analysis are reported for the AR haptic models, diffusion visual model, or the shared language-aligned latent. Without these, the reliability of the semantic-steering claim cannot be assessed and the work is not reproducible.
Authors: We acknowledge that the current manuscript provides insufficient technical detail on the generative components, limiting reproducibility and assessment of the semantic alignment claim. The focus was on the integrated authoring workflow and user evaluation. In the revision we will add an appendix containing the AR haptic model architecture and conditioning, diffusion model configuration, the shared latent alignment procedure, loss functions employed, training hyperparameters, and any available quantitative metrics or error statistics from our experiments. revision: yes
-
Referee: No ablation studies (e.g., shared latent vs. independent modality models or language vs. non-language conditioning) are described. Such comparisons are load-bearing for the claim that the language-aligned latent is what produces the observed cross-modal consistency.
Authors: We concur that ablation studies comparing the shared latent against independent modality models or language versus non-language conditioning would provide stronger evidence that the language-aligned latent drives the observed consistency. These experiments were not conducted in the original work. In the revised manuscript we will add a dedicated limitations paragraph that explicitly notes the absence of such ablations, explains their importance for validating the latent's role, and identifies them as a priority for future research. We cannot design, run, and report new ablation experiments within the scope of this revision. revision: no
- New controlled user studies with modality separation and linearity validation
- Ablation experiments on the shared latent versus independent models
Circularity Check
No significant circularity; evaluation relies on independent participant data
full rationale
The paper describes a generative system with a shared language-aligned latent for consistent multimodal textures and verifies perceptual meaningfulness via an anchor-referenced user study. Participant ratings on generated outputs are projected onto lines between real-material references to show trends in roughness, slipperiness, and hardness. This constitutes external empirical validation using human judgments independent of model training or fitting. No equations, self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text that would reduce the central claims to inputs by construction. The derivation chain for the authoring pipeline and consistency claim remains self-contained against the external benchmarks of the human-subject evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Generative models (AR and diffusion) can be conditioned on language embeddings to produce outputs aligned with semantic descriptions.
- domain assumption Participant ratings on real-material anchors provide a valid projection for measuring perceptual consistency in generated textures.
invented entities (1)
-
Shared language-aligned latent space
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearA shared, language-aligned latent links modalities so a single prompt yields semantically consistent haptic and visual signals
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearParticipant ratings are projected to the interpretable line between two real-material references
Reference graph
Works this paper leans on
-
[1]
Rechap: an interactive recommender system for navigating a large number of mid- air haptic designs,
K. Theivendran, A. Wu, W. Frier, and O. Schneider, “Rechap: an interactive recommender system for navigating a large number of mid- air haptic designs,”IEEE Transactions on Haptics, vol. 17, no. 2, pp. 165–176, 2023
2023
-
[2]
Genartist: Multimodal llm as an agent for unified image generation and editing,
Z. Wang, A. Li, Z. Li, and X. Liu, “Genartist: Multimodal llm as an agent for unified image generation and editing,”Advances in Neural Information Processing Systems, vol. 37, pp. 128 374–128 395, 2024
2024
-
[3]
Creating realistic virtual textures from contact acceleration data,
J. M. Romano and K. J. Kuchenbecker, “Creating realistic virtual textures from contact acceleration data,”IEEE Transactions on Haptics, vol. 5, no. 2, pp. 109–119, 2011
2011
-
[4]
Haptics in minimally invasive surgical simulation and training,
C. Basdogan, S. De, J. Kim, M. Muniyandi, H. Kim, and M. A. Srinivasan, “Haptics in minimally invasive surgical simulation and training,”IEEE Computer Graphics and Applications, vol. 24, no. 2, pp. 56–64, 2004
2004
-
[5]
A review of virtual reality and haptics for product assembly (part 1): rigid parts,
P. Xia, A. M. Lopes, and M. T. Restivo, “A review of virtual reality and haptics for product assembly (part 1): rigid parts,”Assembly Automation, vol. 33, no. 1, pp. 68–77, 2013
2013
-
[6]
Vibrotactile display: Perception, technology, and applications,
S. Choi and K. J. Kuchenbecker, “Vibrotactile display: Perception, technology, and applications,”Proceedings of the IEEE, vol. 101, no. 9, pp. 2093–2104, 2012
2093
-
[7]
Modeling and rendering realistic textures from unconstrained tool-surface interactions,
H. Culbertson, J. Unwin, and K. J. Kuchenbecker, “Modeling and rendering realistic textures from unconstrained tool-surface interactions,” IEEE Transactions on Haptics, vol. 7, no. 3, pp. 381–393, 2014
2014
-
[8]
Vibviz: Organizing, visualizing and navigating vibration libraries,
H. Seifi, K. Zhang, and K. E. MacLean, “Vibviz: Organizing, visualizing and navigating vibration libraries,” inIEEE World Haptics Conference (WHC), 2015, pp. 254–259
2015
-
[9]
One hundred data-driven haptic texture models and open-source methods for rendering on 3d objects,
H. Culbertson, J. J. L. Delgado, and K. J. Kuchenbecker, “One hundred data-driven haptic texture models and open-source methods for rendering on 3d objects,” inIEEE Haptics Symposium (HAPTICS), 2014, pp. 319– 325
2014
-
[10]
Psychophysical dimensions of tactile perception of textures,
S. Okamoto, H. Nagano, and Y . Yamada, “Psychophysical dimensions of tactile perception of textures,”IEEE Transactions on Haptics, vol. 6, no. 1, pp. 81–93, 2012
2012
-
[11]
Vibrotactile signal generation from texture images or attributes using generative adversarial network,
Y . Ujitoko and Y . Ban, “Vibrotactile signal generation from texture images or attributes using generative adversarial network,” inInterna- tional conference on human haptic sensing and touch enabled computer applications. Springer, 2018, pp. 25–36
2018
-
[12]
Hapticgen: Generative text-to-vibration model for streamlining haptic design,
Y . Sung, K. John, S. H. Yoon, and H. Seifi, “Hapticgen: Generative text-to-vibration model for streamlining haptic design,” inProceedings of the CHI Conference on Human Factors in Computing Systems, 2025, pp. 1–24
2025
-
[13]
Tactual perception of material properties,
W. M. B. Tiest, “Tactual perception of material properties,”Vision research, vol. 50, no. 24, pp. 2775–2782, 2010
2010
-
[14]
Authoring new haptic textures based on interpolation of real textures in affective space,
W. Hassan, A. Abdulali, and S. Jeon, “Authoring new haptic textures based on interpolation of real textures in affective space,”IEEE Trans- actions on Industrial Electronics, vol. 67, no. 1, pp. 667–676, 2020
2020
-
[15]
Integrating texture models through regression of vibration and texture characteristics,
K. Tozuka, B. Poitrimol, G. Sasaki, K. Kobayashi, and H. Igarashi, “Integrating texture models through regression of vibration and texture characteristics,”ROBOMECH Journal, vol. 12, no. 1, p. 25, 2025
2025
-
[16]
Preference-driven texture modeling through interactive generation and search,
S. Lu, M. Zheng, M. C. Fontaine, S. Nikolaidis, and H. Culbertson, “Preference-driven texture modeling through interactive generation and search,”IEEE Transactions on Haptics, vol. 15, no. 3, pp. 508–520, 2022
2022
-
[17]
Learning an action- conditional model for haptic texture generation,
N. Heravi, W. Yuan, A. M. Okamura, and J. Bohg, “Learning an action- conditional model for haptic texture generation,” inIEEE International Conference on Robotics and Automation (ICRA), 2020, pp. 11 088– 11 095
2020
-
[18]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the International Conference on Machine Learning (ICML), 2021
2021
-
[19]
Haptics: The present and future of artificial touch sensation,
H. Culbertson, S. B. Schorr, and A. M. Okamura, “Haptics: The present and future of artificial touch sensation,”Annual review of control, robotics, and autonomous systems, vol. 1, no. 1, pp. 385–409, 2018
2018
-
[20]
Twenty years of world haptics: Retrospective and future directions,
J. E. Colgate, L. A. Jones, and H. Z. Tan, “Twenty years of world haptics: Retrospective and future directions,”IEEE Transactions on Haptics, vol. 18, no. 3, pp. 452–455, 2025
2025
-
[21]
Observations on active touch
J. J. Gibson, “Observations on active touch.”Psychological review, vol. 69, no. 6, p. 477, 1962
1962
-
[22]
Visual and tactual texture perception: Intersensory cooperation,
M. A. Heller, “Visual and tactual texture perception: Intersensory cooperation,”Perception & psychophysics, vol. 31, no. 4, pp. 339–344, 1982
1982
-
[23]
Merging the senses into a robust percept,
M. O. Ernst and H. H. B ¨ulthoff, “Merging the senses into a robust percept,”Trends in Cognitive Sciences, vol. 8, no. 4, pp. 162–169, 2004
2004
-
[24]
Multisensory texture perception,
R. L. Klatzky and S. J. Lederman, “Multisensory texture perception,” in Multisensory object perception in the primate brain. Springer, 2010, pp. 211–230
2010
-
[25]
Can you see what you feel? color and folding properties affect visual–tactile material discrimination of fabrics,
B. Xiao, W. Bi, X. Jia, H. Wei, and E. H. Adelson, “Can you see what you feel? color and folding properties affect visual–tactile material discrimination of fabrics,”Journal of Vision, vol. 16, no. 3, pp. 34–34, 2016
2016
-
[26]
Survey of tex- ture mapping techniques for representing and rendering volumetric mesostructure,
C. Koniaris, D. Cosker, X. Yang, and K. Mitchell, “Survey of tex- ture mapping techniques for representing and rendering volumetric mesostructure,”Journal of Computer Graphics Techniques, 2014
2014
-
[27]
Reflectance and texture of real-world surfaces,
K. J. Dana, B. van Ginneken, S. K. Nayar, and J. J. Koenderink, “Reflectance and texture of real-world surfaces,”ACM Trans. Graph., vol. 18, no. 1, p. 1–34, Jan. 1999
1999
-
[28]
Photoshape: photorealistic materials for large-scale shape collections,
K. Park, K. Rematas, A. Farhadi, and S. M. Seitz, “Photoshape: photorealistic materials for large-scale shape collections,”ACM Trans. Graph., vol. 37, no. 6, Dec. 2018
2018
-
[29]
Bidirectional visual- tactile cross-modal generation using latent feature space flow model,
Y . Fang, X. Zhang, W. Xu, G. Liu, and J. Zhao, “Bidirectional visual- tactile cross-modal generation using latent feature space flow model,” Neural Networks, vol. 172, p. 106088, 2024
2024
-
[30]
Natural scenes in tactile texture,
L. R. Manfredi, H. P. Saal, K. J. Brown, M. C. Zielinski, J. F. Dammann III, V . S. Polashock, and S. J. Bensmaia, “Natural scenes in tactile texture,”Journal of neurophysiology, vol. 111, no. 9, pp. 1792– 1802, 2014
2014
-
[31]
Signal processing for haptic surface modeling: A review,
A. L. Stefani, N. Bisagno, A. Rosani, N. Conci, and F. De Natale, “Signal processing for haptic surface modeling: A review,”Signal Processing: Image Communication, p. 117338, 2025
2025
-
[32]
A systematic review of haptic texture reproduction technology,
S. Chen, T. Yuan, L. Xu, W. Ru, and D. Wang, “A systematic review of haptic texture reproduction technology,”Intelligence & Robotics, vol. 5, no. 3, pp. 607–30, 2025
2025
-
[33]
Reality-based models for vibration feedback in virtual environments,
A. Okamura, M. Cutkosky, and J. Dennerlein, “Reality-based models for vibration feedback in virtual environments,”IEEE/ASME Transactions on Mechatronics, vol. 6, no. 3, pp. 245–252, 2001
2001
-
[34]
Dynamic simulation of tool- mediated texture interaction,
C. G. McDonald and K. J. Kuchenbecker, “Dynamic simulation of tool- mediated texture interaction,” in2013 World Haptics Conference (WHC), 2013, pp. 307–312
2013
-
[35]
Generating haptic texture models from unconstrained tool-surface in- teractions,
H. Culbertson, J. Unwin, B. E. Goodman, and K. J. Kuchenbecker, “Generating haptic texture models from unconstrained tool-surface in- teractions,” inWorld Haptics Conference (WHC), 2013, pp. 295–300
2013
-
[36]
Data-driven mod- eling of isotropic haptic textures using frequency-decomposed neural networks,
S. Shin, R. H. Osgouei, K.-D. Kim, and S. Choi, “Data-driven mod- eling of isotropic haptic textures using frequency-decomposed neural networks,” inIEEE World Haptics Conference (WHC), 2015, pp. 131– 138
2015
-
[37]
Data-driven haptic texture modeling and rendering based on deep spatio-temporal networks,
J. B. Joolee and S. Jeon, “Data-driven haptic texture modeling and rendering based on deep spatio-temporal networks,”IEEE Transactions on Haptics, vol. 15, no. 1, pp. 62–67, 2022
2022
-
[38]
Development and evaluation of a learning-based model for real-time haptic texture rendering,
N. Heravi, H. Culbertson, A. M. Okamura, and J. Bohg, “Development and evaluation of a learning-based model for real-time haptic texture rendering,”IEEE Transactions on Haptics, vol. 17, no. 4, pp. 705–716, 2024
2024
-
[39]
X. Yi, J. Wang, and P. Sun, “Time series diffusion method: A denoising diffusion probabilistic model for vibration signal generation,”arXiv preprint arXiv:2303.01234, 2023
-
[40]
Improving contact realism through event-based haptic feedback,
K. J. Kuchenbecker, J. Fiene, and G. Niemeyer, “Improving contact realism through event-based haptic feedback,”IEEE transactions on visualization and computer graphics, vol. 12, no. 2, pp. 219–230, 2006
2006
-
[41]
T-pad: Tactile pattern display through variable friction reduction,
L. Winfield, J. Glassmire, J. E. Colgate, and M. Peshkin, “T-pad: Tactile pattern display through variable friction reduction,” inSecond Joint EuroHaptics Conference and Symposium on Haptic Interfaces for Virtual Environment and Teleoperator Systems (WHC’07), 2007, pp. 421–426
2007
-
[42]
Fingertip friction modulation due to electrostatic attraction,
D. J. Meyer, M. A. Peshkin, and J. E. Colgate, “Fingertip friction modulation due to electrostatic attraction,” in2013 World Haptics Conference (WHC), 2013, pp. 43–48
2013
-
[43]
The slip hypothesis: tactile perception and its neuronal bases,
C. Schwarz, “The slip hypothesis: tactile perception and its neuronal bases,”Trends in neurosciences, vol. 39, no. 7, pp. 449–462, 2016
2016
-
[44]
Towards multisensory perception: Modeling and rendering sounds of tool-surface interactions,
S. Lu, Y . Chen, and H. Culbertson, “Towards multisensory perception: Modeling and rendering sounds of tool-surface interactions,”IEEE Transactions on Haptics, vol. 13, no. 1, pp. 94–101, 2020
2020
-
[45]
Auditory materiality: Exploring auditory effects on material perception in virtual reality,
B. Zhong, S. Je, and M. Z. Sagesser, “Auditory materiality: Exploring auditory effects on material perception in virtual reality,” in2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 2025, pp. 659–662
2025
-
[46]
Thermalbitdisplay: Haptic display providing thermal feedback perceived differently depend- ing on body parts,
A. Niijima, T. Takeda, T. Mukouchi, and T. Satou, “Thermalbitdisplay: Haptic display providing thermal feedback perceived differently depend- ing on body parts,” inExtended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–8
2020
-
[47]
Three-axis pneumatic haptic display for the mechanical and thermal stimulation of a human finger pad,
E.-H. Lee, S.-H. Kim, and K.-S. Yun, “Three-axis pneumatic haptic display for the mechanical and thermal stimulation of a human finger pad,” inActuators, vol. 10, no. 3. MDPI, 2021, p. 60
2021
-
[48]
Fluid reality: High-resolution, untethered haptic gloves using electroosmotic pump arrays,
V . Shen, T. Rae-Grant, J. Mullenbach, C. Harrison, and C. Shultz, “Fluid reality: High-resolution, untethered haptic gloves using electroosmotic pump arrays,” inProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–20
2023
-
[49]
Shape-it: Exploring text-to-shape-display for generative shape-changing behaviors with llms,
W. Qian, C. Gao, A. Sathya, R. Suzuki, and K. Nakagaki, “Shape-it: Exploring text-to-shape-display for generative shape-changing behaviors with llms,” inProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology, 2024, pp. 1–29
2024
-
[50]
Texturegan: Controlling deep image synthesis with texture patches,
W. Xian, P. Sangkloy, V . Agrawal, A. Raj, J. Lu, C. Fang, F. Yu, and J. Hays, “Texturegan: Controlling deep image synthesis with texture patches,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8456–8465
2018
-
[51]
Diffusion models: A comprehensive survey of methods and applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,”ACM computing surveys, vol. 56, no. 4, pp. 1–39, 2023
2023
-
[52]
Sequential gallery for interactive visual design optimization,
Y . Koyama, I. Sato, and M. Goto, “Sequential gallery for interactive visual design optimization,”ACM Transactions on Graphics (TOG), vol. 39, no. 4, pp. 88–1, 2020
2020
-
[53]
Text2tex: Text-driven texture synthesis via diffusion models,
D. Z. Chen, Y . Siddiqui, H.-Y . Lee, S. Tulyakov, and M. Nießner, “Text2tex: Text-driven texture synthesis via diffusion models,” inPro- ceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 18 558–18 568
2023
-
[54]
Vibrotactile signal generation from texture images or attributes using generative adversarial network,
Y . Ujitoko and Y . Ban, “Vibrotactile signal generation from texture images or attributes using generative adversarial network,” inHaptics: Science, Technology, and Applications, D. Prattichizzo, H. Shinoda, H. Z. Tan, E. Ruffaldi, and A. Frisoli, Eds. Cham: Springer International Publishing, 2018, pp. 25–36
2018
-
[55]
TEXasGAN: Tactile texture exploration and synthesis system using generative adversarial network,
M. Zhang, S. Terui, Y . Makino, and H. Shinoda, “TEXasGAN: Tactile texture exploration and synthesis system using generative adversarial network,”arXiv preprint arXiv:2407.11467, 2024
-
[56]
Tactstyle: Generating tactile textures with generative ai for digital fabrication,
F. Faruqi, M. Perroni-Scharf, J. S. Walia, Y . Zhu, S. Feng, D. Degraen, and S. Mueller, “Tactstyle: Generating tactile textures with generative ai for digital fabrication,” inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, 2025, pp. 1–16
2025
-
[57]
Gan-based image-to-friction generation for tactile simulation of fabric material,
S. Cai, L. Zhao, Y . Ban, T. Narumi, Y . Liu, and K. Zhu, “Gan-based image-to-friction generation for tactile simulation of fabric material,” Computers & Graphics, vol. 104, pp. 219–228, 2022
2022
-
[58]
Vis2hap: Vision-based haptic rendering by cross-modal generation,
G. Cao, J. Jiang, N. Mao, D. Bollegala, M. Li, and S. Luo, “Vis2hap: Vision-based haptic rendering by cross-modal generation,” inIEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 12 443–12 449
2023
-
[59]
Cm-avae: Cross-modal adversarial variational autoencoder for visual-to-tactile data generation,
Q. Xi, F. Wang, L. Tao, H. Zhang, X. Jiang, and J. Wu, “Cm-avae: Cross-modal adversarial variational autoencoder for visual-to-tactile data generation,”IEEE Robotics and Automation Letters, vol. 9, no. 6, pp. 5214–5221, 2024
2024
-
[60]
Method for audio-to-tactile cross- modality generation based on residual u-net,
H. Zhan, J. Chen, and L. Huang, “Method for audio-to-tactile cross- modality generation based on residual u-net,”IEEE Transactions on Instrumentation and Measurement, vol. 73, pp. 1–10, 2024
2024
-
[61]
Cross-modal generation of tactile friction coefficient from audio and visual measurements by transformer,
R. Song, X. Sun, and G. Liu, “Cross-modal generation of tactile friction coefficient from audio and visual measurements by transformer,”IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–11, 2023
2023
-
[62]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022, pp. 10 684–10 695
2022
-
[63]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,”Advances in neural information processing systems, vol. 35, pp. 36 479–36 494, 2022
2022
-
[65]
Magic3d: High-resolution text-to- 3d content creation,
C.-H. Lin, J. Gao, L. Tang, T. Takikawa, X. Zeng, X. Huang, K. Kreis, S. Fidler, M.-Y . Liu, and T.-Y . Lin, “Magic3d: High-resolution text-to- 3d content creation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 300–309
2023
-
[66]
Dream3d: Zero-shot text-to-3d synthesis using 3d shape prior and text- to-image diffusion models,
J. Xu, X. Wang, W. Cheng, Y .-P. Cao, Y . Shan, X. Qie, and S. Gao, “Dream3d: Zero-shot text-to-3d synthesis using 3d shape prior and text- to-image diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 20 908–20 918
2023
-
[67]
Audiogen: Textually guided audio generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “Audiogen: Textually guided audio generation,”arXiv preprint arXiv:2209.15352, 2022
-
[68]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasacchiet al., “Musiclm: Generating music from text,”arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review arXiv 2023
-
[69]
Audioldm 2: Learning holistic audio generation with self-supervised pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wang, W. Wang, Y . Wang, and M. D. Plumbley, “Audioldm 2: Learning holistic audio generation with self-supervised pretraining,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 32, pp. 2871–2883, 2024
2024
-
[70]
Texttoucher: Fine-grained text-to-touch generation,
J. Tu, H. Fu, F. Yang, H. Zhao, C. Zhang, and H. Qian, “Texttoucher: Fine-grained text-to-touch generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, 2025, pp. 7455–7463
2025
-
[71]
Text-driven generative framework for multimodal visual and haptic texture synthesis,
M. Naeem, M. I. Awan, and S. Jeon, “Text-driven generative framework for multimodal visual and haptic texture synthesis,” in2025 IEEE World Haptics Conference (WHC), 2025, pp. 140–146
2025
-
[72]
Penn haptic texture toolkit: A collection of textures for haptic rendering,
H. Culbertson and K. J. Kuchenbecker, “Penn haptic texture toolkit: A collection of textures for haptic rendering,” inIEEE Haptics Symposium (HAPTICS), 2014, pp. 99–106
2014
-
[73]
Importance of matching physical friction, hardness, and texture in creating realistic haptic virtual surfaces,
——, “Importance of matching physical friction, hardness, and texture in creating realistic haptic virtual surfaces,”IEEE Transactions on Haptics, vol. 10, no. 1, pp. 63–74, 2016
2016
-
[74]
Chatgpt (gpt-5),
OpenAI, “Chatgpt (gpt-5),” https://chat.openai.com, 2025, large lan- guage model developed by OpenAI. URL: https://chat.openai.com
2025
-
[75]
beta-vae: Learning basic visual concepts with a constrained variational framework,
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, “beta-vae: Learning basic visual concepts with a constrained variational framework,” inInternational conference on learning representations, 2017
2017
-
[76]
Stable diffusion v2-base — stabilityai / hugging face,
“Stable diffusion v2-base — stabilityai / hugging face,” https://huggingface.co/stabilityai/stable-diffusion-2-base, 2025, accessed: 2025-09-30
2025
-
[77]
Textures — poly haven,
“Textures — poly haven,” https://polyhaven.com/textures, 2025, ac- cessed: 2025-09-30
2025
-
[78]
Clustergan: Latent space clustering in generative adversarial networks,
S. Mukherjee, H. Asnani, E. Lin, and S. Kannan, “Clustergan: Latent space clustering in generative adversarial networks,” inProceedings of the AAAI conference on artificial intelligence, vol. 33, no. 01, 2019, pp. 4610–4617
2019
-
[79]
Unsupervised deep embedding for clustering analysis,
J. Xie, R. Girshick, and A. Farhadi, “Unsupervised deep embedding for clustering analysis,” inInternational conference on machine learning. PMLR, 2016, pp. 478–487
2016
-
[80]
M. Ben-Yosef and D. Weinshall, “Gaussian mixture generative adver- sarial networks for diverse datasets, and the unsupervised clustering of images,”arXiv preprint arXiv:1808.10356, 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.