Recognition: no theorem link
Guiding Symbolic Execution with Static Analysis and LLMs for Vulnerability Discovery
Pith reviewed 2026-05-10 18:22 UTC · model grok-4.3
The pith
SAILOR automates symbolic execution harness construction with static analysis and iterative LLM synthesis to detect hundreds of new memory-safety vulnerabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SAILOR discovers 379 distinct previously unknown memory-safety vulnerabilities (421 confirmed crashes) across 10 open-source C/C++ projects totaling 6.8 million lines of code by using static analysis to target candidates, LLM-orchestrated iterative harness synthesis, and symbolic execution with concrete validation, while the strongest of five baselines finds only 12 vulnerabilities and each phase proves essential.
What carries the argument
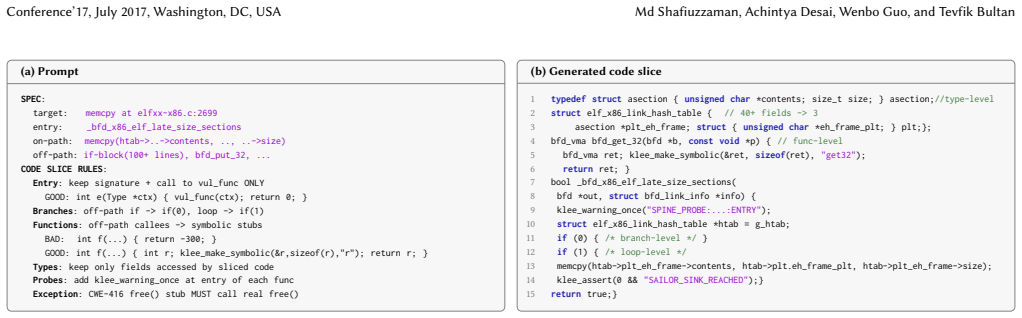
The three-phase pipeline: static analysis to generate vulnerability specifications from candidate locations, iterative LLM synthesis of harnesses using compilation and execution feedback, followed by symbolic execution and concrete replay validation.
If this is right
- Symbolic execution becomes applicable to large codebases without requiring expert manual harness development.
- Static analysis, LLM synthesis, and symbolic execution must all be combined, as removing any one drops confirmed detections by factors of 12x or to zero.
- LLM-orchestrated refinement against execution feedback can produce harnesses that enable detection of 30 times more vulnerabilities than LLM-only agentic approaches.
- Concrete replay validation ensures that reported issues correspond to real crashes in unmodified source.
Where Pith is reading between the lines
- The same orchestration pattern could be tested on other vulnerability classes such as use-after-free or integer overflows by adjusting the static analysis and assertion templates.
- Integrating the generated harnesses into fuzzing campaigns might increase coverage beyond what symbolic execution alone reaches.
- The method suggests that LLMs can serve as reliable code-reasoning intermediaries when anchored by static specifications and concrete feedback loops.
- Scaling the approach to even larger projects or additional languages would require testing whether the LLM iteration loop remains efficient without excessive retries.
Load-bearing premise
The assumption that the LLM can reliably generate correct, compilable harnesses from vulnerability specifications and feedback loops without introducing new errors or missing real bugs, and that static analysis can identify a sufficient set of true-positive candidate locations without excessive false negatives.
What would settle it
Running SAILOR on a project containing a known collection of documented or injected memory-safety vulnerabilities and finding that it detects far fewer than the known set, or that the LLM synthesis phase produces many harnesses that fail to compile or yield unconfirmable results.
Figures







read the original abstract
Symbolic execution detects vulnerabilities with precision, but applying it to large codebases requires harnesses that set up symbolic state, model dependencies, and specify assertions. Writing these harnesses has traditionally been a manual process requiring expert knowledge, which significantly limits the scalability of the technique. We present Static Analysis Informed and LLM-Orchestrated Symbolic Execution (SAILOR), which automates symbolic execution harness construction by combining static analysis with LLM-based synthesis. SAILOR operates in three phases: (1) static analysis identifies candidate vulnerable locations and generates vulnerability specifications; (2) an LLM uses vulnerability specifications and orchestrates harness synthesis by iteratively refining drivers, stubs, and assertions against compiler and symbolic execution feedback; symbolic execution then detects vulnerabilities using the generated harness, and (3) concrete replay validates the symbolic execution results against the unmodified project source. This design combines the scalability of static analysis, the code reasoning of LLMs, the path precision of symbolic execution, and the ground truth produced by concrete execution. We evaluate SAILOR on 10 open-source C/C++ projects totaling 6.8 M lines of code. SAILOR discovers 379 distinct, previously unknown memory-safety vulnerabilities (421 confirmed crashes). The strongest of five baselines we compare SAILOR to (agentic vulnerability detection using Claude Code with full codebase access and unlimited interaction), finds only 12 vulnerabilities. Each phase of SAILOR is critical: Without static analysis targeting confirmed vulnerabilities drop 12.2X; without iterative LLM synthesis zero vulnerabilities are confirmed; and without symbolic execution no approach can detect more than 12 vulnerabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAILOR, a framework that integrates static analysis to identify candidate vulnerability locations, LLM-based iterative synthesis of symbolic execution harnesses (drivers, stubs, assertions), and symbolic execution followed by concrete replay validation. Evaluated on 10 C/C++ projects (6.8M LOC), it reports discovering 379 previously unknown memory-safety vulnerabilities (421 confirmed crashes), significantly outperforming five baselines including an agentic approach with Claude that found only 12. Ablation studies claim each component is essential, with drops of 12.2X without static analysis and zero confirmations without LLM iteration or symbolic execution.
Significance. If the empirical results and validation hold, this represents a substantial advance in automated vulnerability discovery for large codebases. By automating harness construction, it addresses a key scalability barrier for symbolic execution, combining it with LLMs and static analysis in a way that yields orders-of-magnitude more findings than baselines. The ablation results provide evidence for the contribution of each phase, and the use of concrete replay offers a path to ground truth.
major comments (3)
- [Evaluation] The abstract and evaluation report 379 distinct vulnerabilities and 421 confirmed crashes, but provide no details on the process for filtering false positives from symbolic execution results, the number of harnesses that failed to compile or run, or the exact criteria used to classify vulnerabilities as 'previously unknown' (e.g., not reported in CVE databases or project issue trackers). This information is load-bearing for the central claim of novel discoveries.
- [Phase 3 (Concrete Replay)] The skeptic's concern is valid here: even with concrete replay on the unmodified project source, if the replay inputs are derived from harness-orchestrated call sequences or stubs that model external dependencies incorrectly (e.g., return values or side effects), the confirmed crashes may not correspond to vulnerabilities in the original code semantics. The manuscript should clarify whether replay executes the original entry points in isolation or through the synthesized harness.
- [Ablation Study] The claim that without iterative LLM synthesis zero vulnerabilities are confirmed is strong, but the evaluation does not report the total number of LLM iterations attempted, failure modes in harness synthesis, or whether the static analysis candidates were the same across ablations. This makes it hard to assess if the zero is due to the absence of iteration or other factors.
minor comments (2)
- [Abstract] The abstract mentions 'five baselines' but does not name them; a brief enumeration would improve clarity.
- [Introduction] Some terms like 'vulnerability specifications' could be defined more precisely in the introduction for readers unfamiliar with the pipeline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight areas where additional clarity will strengthen the presentation of our evaluation, validation process, and ablation results. We have revised the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [Evaluation] The abstract and evaluation report 379 distinct vulnerabilities and 421 confirmed crashes, but provide no details on the process for filtering false positives from symbolic execution results, the number of harnesses that failed to compile or run, or the exact criteria used to classify vulnerabilities as 'previously unknown' (e.g., not reported in CVE databases or project issue trackers). This information is load-bearing for the central claim of novel discoveries.
Authors: We agree that these details are essential to support the central claims. In the revised manuscript we have expanded the Evaluation section with a dedicated subsection on result validation. It now describes the false-positive filtering process (automated deduplication via crash location and stack-trace similarity followed by manual review of a representative sample), reports the number of harnesses that failed to compile or execute, and states the exact criteria used to classify vulnerabilities as previously unknown (cross-checks against CVE databases, project issue trackers, and commit histories as of the evaluation date). These additions provide the requested transparency without altering any reported counts. revision: yes
-
Referee: [Phase 3 (Concrete Replay)] The skeptic's concern is valid here: even with concrete replay on the unmodified project source, if the replay inputs are derived from harness-orchestrated call sequences or stubs that model external dependencies incorrectly (e.g., return values or side effects), the confirmed crashes may not correspond to vulnerabilities in the original code semantics. The manuscript should clarify whether replay executes the original entry points in isolation or through the synthesized harness.
Authors: We thank the referee for raising this important methodological point. We have revised the Phase 3 description to explicitly state that concrete replay invokes the original entry points directly on the unmodified project source using the concrete input values produced by symbolic execution. The synthesized harness, drivers, and stubs are not used during replay; they serve only to guide symbolic exploration. This isolation ensures that any confirmed crash reflects the semantics of the original code rather than any modeling assumptions in the harness. revision: yes
-
Referee: [Ablation Study] The claim that without iterative LLM synthesis zero vulnerabilities are confirmed is strong, but the evaluation does not report the total number of LLM iterations attempted, failure modes in harness synthesis, or whether the static analysis candidates were the same across ablations. This makes it hard to assess if the zero is due to the absence of iteration or other factors.
Authors: We agree that these additional metrics improve interpretability of the ablation results. The revised manuscript now reports the total number of LLM iterations attempted, a breakdown of harness-synthesis failure modes (compilation errors, symbolic-execution timeouts, and assertion violations), and confirms that the identical set of static-analysis candidates was used for every ablation variant. These clarifications allow readers to attribute the zero confirmations specifically to the absence of iteration. revision: yes
Circularity Check
No circularity: empirical counts and ablations are direct measurements
full rationale
The paper's central claims consist of empirical counts (379 vulnerabilities found, 421 crashes confirmed) from running SAILOR on 6.8 MLoC across 10 projects, plus ablation results showing drops when removing static analysis (12.2X), LLM synthesis (zero confirmations), or symbolic execution (max 12). These are direct experimental outcomes, not derivations, fitted parameters renamed as predictions, or self-citations that reduce the result to its inputs. No equations, uniqueness theorems, or ansatzes are invoked; the evaluation uses concrete replay on unmodified source as ground truth. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Static analysis can identify candidate vulnerable locations and generate usable vulnerability specifications for downstream synthesis.
- domain assumption LLMs can iteratively refine harness code (drivers, stubs, assertions) to a compilable and executable state when given compiler and symbolic-execution feedback.
Reference graph
Works this paper leans on
-
[1]
GitHub, Inc. 2026. CodeQL. https://codeql.github.com/ Accessed: 2026-03-14
2026
-
[2]
Domagoj Babic, Stefan Bucur, Yaohui Chen, Franjo Ivancic, Tim King, Markus Kusano, Caroline Lemieux, Laszlo Szekeres, and Wei Wang. 2019. FUDGE: Fuzz Driver Generation at Scale. InProceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). doi:10.1145/3338906.3340456
-
[3]
George Balatsouras and Yannis Smaragdakis. 2016. Structure-sensitive points-to analysis for C and C++. InInternational Static Analysis Symposium. Springer, 84–104. doi:10.1007/978-3-662-53413-7_5
-
[4]
Al Bessey, Ken Block, Ben Chelf, Andy Chou, Bryan Fulton, Seth Hallem, Charles Henri-Gros, Asya Kamsky, Scott McPeak, and Dawson Engler. 2010. A few billion lines of code later: using static analysis to find bugs in the real world.Commun. ACM53, 2 (2010), 66–75. doi:10.1145/1646353.1646374
-
[5]
Fraser Brown, Deian Stefan, and Dawson Engler. 2020. Sys: A Static/Symbolic Tool for Finding Good Bugs in Good (Browser) Code. In29th USENIX Security Symposium. 199–216
2020
-
[6]
Frank Busse, Pritam Gharat, Cristian Cadar, and Alastair F. Donaldson. 2022. Combining Static Analysis Error Traces with Dynamic Symbolic Execution (Ex- perience Paper). InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). doi:10.1145/3533767.3534384
-
[7]
Cristian Cadar, Daniel Dunbar, and Dawson Engler. 2008. Klee: unassisted and automatic generation of high-coverage tests for complex systems programs.. In OSDI, Vol. 8. 209–224
2008
-
[8]
Cristiano Calcagno, Dino Distefano, Jeremy Dubreil, Dominik Gabi, Pieter Hooimeijer, Martino Luca, Peter O’Hearn, Irene Papakonstantinou, Jim Purbrick, and Dulma Rodriguez. 2015. Moving fast with software verification. InNASA Formal Methods Symposium. Springer, 3–11. doi:10.1007/978-3-319-17524-9_1
-
[9]
Peng Chen, Yuxuan Xie, Yunlong Lyu, Yuxiao Wang, and Hao Chen. 2023. Hop- per: Interpretative Fuzzing for Libraries. InACM Conference on Computer and Communications Security (CCS). doi:10.1145/3576915.3616610
-
[10]
Xueying Du, Geng Zheng, Kaixin Wang, Yi Zou, Yujia Wang, Wentai Deng, Jiayi Feng, Mingwei Liu, Bihuan Chen, Xin Peng, et al . 2024. Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag.ACM Transactions on Software Engineering and Methodology(2024). doi:10.1145/3797277
-
[11]
Andrea Fioraldi, Dominik Maier, Heiko Eißfeldt, and Marc Heuse. 2020. {AFL++}: Combining incremental steps of fuzzing research. In14th USENIX workshop on offensive technologies (WOOT 20)
2020
-
[12]
Google. 2024. OSS-Fuzz-Gen: LLM-powered fuzz target generation. https: //github.com/google/oss-fuzz-gen Accessed: 2026-03-14
2024
-
[13]
Ispoglou, Daniel Austin, Vishwath Mohan, and Mathias Payer
Kyriakos K. Ispoglou, Daniel Austin, Vishwath Mohan, and Mathias Payer. 2020. FuzzGen: Automatic Fuzzer Generation. In29th USENIX Security Symposium
2020
-
[14]
Bokdeuk Jeong, Joonun Jang, Hayoon Yi, Jiin Moon, Junyoung Park, Jaeseung Choi, and Taesoo Kim. 2023. UTopia: Automatic Generation of Fuzz Driver using Unit Tests. InIEEE Symposium on Security and Privacy (S&P). doi:10.1109/SP46215. 2023.10179394
-
[15]
Duck, Jing Xian Goh, and Abhik Roychoudhury
Mengruo Jiang, Gregory J. Duck, Jing Xian Goh, and Abhik Roychoudhury
-
[16]
Large Language Model Powered Symbolic Execution. InACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA). doi:10.1145/3763163
-
[17]
Jinho Jung, Stephen Tong, Hong Hu, Jungwon Lim, Yonghwi Jin, and Taesoo Kim. 2021. WINNIE: Fuzzing Windows Applications with Harness Synthesis and Fast Cloning. InNetwork and Distributed System Security Symposium (NDSS)
2021
-
[18]
Avishree Khare, Saikat Dutta, Ziyang Li, Alaia Solko-Breslin, Rajeev Alur, and Mayur Naik. 2025. Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities. InProceedings of the 18th IEEE International Conference on Software Testing, Verification and Validation (ICST). doi:10.1109/ ICST62969.2025.10988968
-
[19]
James C King. 1976. Symbolic execution and program testing.Commun. ACM 19, 7 (1976), 385–394. doi:10.1145/360248.360252
-
[20]
Haonan Li, Yu Hao, Yizhuo Zhai, and Zhiyun Qian. 2024. Enhancing Static Analysis for Practical Bug Detection: An LLM-Integrated Approach. InACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA). doi:10.1145/3649828
-
[21]
Penghui Li, Wei Meng, and Kangjie Lu. 2022. SEDiff: Scope-Aware Differential Fuzzing to Test Internal Function Models in Symbolic Execution. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). doi:10.1145/3540250.3549080
-
[22]
Ziyang Li, Saikat Dutta, and Mayur Naik. 2025. IRIS: LLM-Assisted Static Analysis for Detecting Security Vulnerabilities. InInternational Conference on Learning Representations (ICLR)
2025
-
[23]
Baozheng Liu, Chao Zhang, Guang Gong, Yishun Zeng, Haifeng Ruan, and Jian- wei Zhuge. 2020. FANS: Fuzzing Android Native System Services via Automated Interface Analysis. In29th USENIX Security Symposium
2020
-
[24]
Yuwei Liu, Junquan Deng, Xiangkun Jia, Yanhao Wang, Minghua Wang, Lin Huang, Wei Tao, and Purui Su. 2025. PromeFuzz: A Knowledge-Driven Approach to Fuzzing Harness Generation with Large Language Models. InACM Conference on Computer and Communications Security (CCS). doi:10.1145/3719027.3765222
-
[25]
Yunlong Lyu, Yuxuan Xie, Peng Chen, and Hao Chen. 2024. Prompt Fuzzing for Fuzz Driver Generation. InACM Conference on Computer and Communications Security (CCS). doi:10.1145/3658644.3670396
-
[26]
2023.Static Analysis Results Interchange Format (SARIF) Version 2.1.0 Plus Errata 01
OASIS. 2023.Static Analysis Results Interchange Format (SARIF) Version 2.1.0 Plus Errata 01. OASIS Standard. OASIS. https://docs.oasis-open.org/sarif/sarif/v2.1.0/ sarif-v2.1.0.html
2023
-
[27]
LLVM Project. 2026. libFuzzer – a library for coverage-guided fuzz testing. https://llvm.org/docs/LibFuzzer.html Accessed: 2026-03-22
2026
-
[28]
Seemanta Saha, Laboni Sarker, Md Shafiuzzaman, Chaofan Shou, Albert Li, Ganesh Sankaran, and Tevfik Bultan. 2023. Rare Path Guided Fuzzing. InPro- ceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). 1295–1306. doi:10.1145/3597926.3598136
-
[29]
Konstantin Serebryany, Derek Bruening, Alexander Potapenko, and Dmitriy Vyukov. 2012. AddressSanitizer: A Fast Address Sanity Checker. InProceedings of the 2012 USENIX Annual Technical Conference (USENIX ATC). 309–318
2012
-
[30]
Md Shafiuzzaman, Achintya Desai, Laboni Sarker, and Tevfik Bultan. 2024. STASE: Static Analysis Guided Symbolic Execution for UEFI Vulnerability Signature Generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE). doi:10.1145/3691620.3695543
-
[31]
Zhiyuan Wei, Jing Sun, Yuqiang Sun, Ye Liu, Daoyuan Wu, Zijian Zhang, Xianhao Zhang, Meng Li, Yang Liu, Chunmiao Li, et al. 2025. Advanced smart contract vulnerability detection via llm-powered multi-agent systems.IEEE Transactions on Software Engineering(2025). doi:10.1109/TSE.2025.3538282
-
[32]
Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, and Lingming Zhang. 2023. Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep- Learning Libraries via Large Language Models. InACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). doi:10.5281/zenodo.7980923
-
[33]
Hao Xiong, Qinming Dai, Rui Chang, Mingran Qiu, Renxiang Wang, Wenbo Shen, and Yajin Zhou. 2024. Atlas: Automating Cross-Language Fuzzing on Android Closed-Source Libraries. InACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA). doi:10.1145/3650212.3652133
-
[34]
Hanxiang Xu, Wei Ma, Ting Zhou, Yanjie Zhao, Kai Chen, Qiang Hu, Yang Liu, and Haoyu Wang. 2025. CKGFuzzer: LLM-Based Fuzz Driver Generation Enhanced by Code Knowledge Graph. InIEEE/ACM International Conference on Software Engineering (ICSE), Industry Challenge Track
2025
- [35]
-
[36]
Muhammad Nabel Zaharudin, Muhammad Haziq Zuhaimi, and Faysal Hossain Shezan. 2024. Enhancing Symbolic Execution with LLMs for Vulnerability De- tection. InIEEE Symposium on Security and Privacy (S&P), Poster. Conference’17, July 2017, Washington, DC, USA Md Shafiuzzaman, Achintya Desai, Wenbo Guo, and Tevfik Bultan
2024
-
[37]
Cen Zhang, Xingwei Lin, Yuekang Li, Yinxing Xue, Jundong Xie, Hongxu Chen, Xinlei Ying, Jiashui Wang, and Yang Liu. 2021. APICraft: Fuzz Driver Generation for Closed-source SDK Libraries. In30th USENIX Security Symposium
2021
-
[38]
Cen Zhang, Yaowen Zheng, Mingqiang Bai, Yeting Li, Wei Ma, Xiaofei Xie, Yuekang Li, Limin Sun, and Yang Liu. 2024. How Effective Are They? Explor- ing Large Language Model Based Fuzz Driver Generation. InACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.