Recognition: no theorem link
AI-Driven Research for Databases
Pith reviewed 2026-05-10 17:48 UTC · model grok-4.3
The pith
Co-evolving evaluators with candidate solutions lets AI discover database algorithms that beat current best practices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Automating evaluator design through co-evolution with the solutions they judge removes the evaluation bottleneck in AI-Driven Research for Systems, allowing large language models to generate and refine deployable database code that improves on state-of-the-art methods for buffer management, query rewriting, and index selection.
What carries the argument
The co-evolution loop in which evaluators and candidate solutions are iteratively refined together by the language model, supplying the fast, accurate feedback required for unsupervised optimization.
If this is right
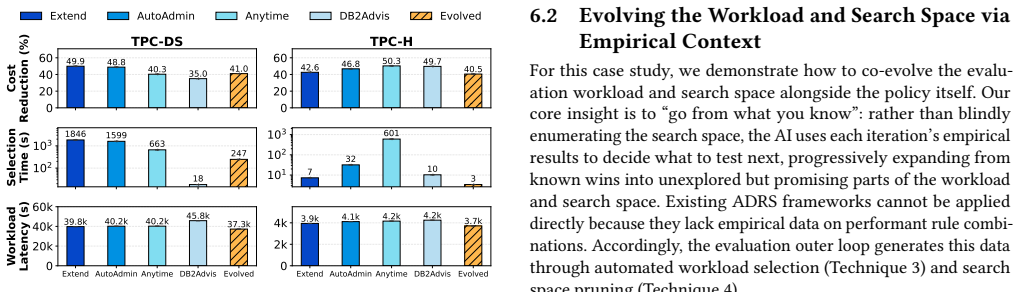
- A deterministic query rewrite policy that achieves up to 6.8 times lower latency than current baselines.
- New buffer management policies that improve cache performance beyond existing heuristics.
- Index selection algorithms that reduce storage or query time compared with state-of-the-art advisors.
- A practical path for applying automated research methods to other complex systems once the evaluator problem is solved.
Where Pith is reading between the lines
- The same co-evolution pattern could be tried on operating-system or network-stack tuning where evaluation is also expensive.
- Production databases might eventually run such an automated researcher in the background to adapt to changing workloads without constant administrator input.
- If the evaluators prove reliable, the approach could shorten the time from identifying a performance problem to deploying an optimized piece of code.
Load-bearing premise
Co-evolved evaluators will keep giving accurate and unbiased scores that let the model converge on real, deployable improvements without later human correction.
What would settle it
Measure the latency and throughput of the discovered query rewrite policy on standard database benchmarks and check whether it consistently beats the best existing deterministic policies.
Figures







read the original abstract
As the complexity of modern workloads and hardware increasingly outpaces human research and engineering capacity, existing methods for database performance optimization struggle to keep pace. To address this gap, a new class of techniques, termed AI-Driven Research for Systems (ADRS), uses large language models to automate solution discovery. This approach shifts optimization from manual system design to automated code generation. The key obstacle, however, in applying ADRS is the evaluation pipeline. Since these frameworks rapidly generate hundreds of candidates without human supervision, they depend on fast and accurate feedback from evaluators to converge on effective solutions. Building such evaluators is especially difficult for complex database systems. To enable the practical application of ADRS in this domain, we propose automating the design of evaluators by co-evolving them with the solutions. We demonstrate the effectiveness of this approach through three case studies optimizing buffer management, query rewriting, and index selection. Our automated evaluators enable the discovery of novel algorithms that outperform state-of-the-art baselines (e.g., a deterministic query rewrite policy that achieves up to 6.8x lower latency), demonstrating that addressing the evaluation bottleneck unlocks the potential of ADRS to generate highly optimized, deployable code for next-generation data systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AI-Driven Research for Systems (ADRS), which leverages large language models to automate discovery of database optimizations by co-evolving candidate solutions with automated evaluators. It reports three case studies on buffer management, query rewriting, and index selection, claiming that this approach yields novel algorithms outperforming state-of-the-art baselines, including a deterministic query rewrite policy with up to 6.8x lower latency.
Significance. If the experimental claims hold under rigorous validation, the work could meaningfully advance automated optimization techniques in databases by reducing reliance on manual design. The co-evolution mechanism for evaluators is a plausible response to the evaluation bottleneck in LLM-driven code generation. However, the absence of any reported experimental protocol, baselines, or validation against real workloads makes it impossible to determine whether the claimed gains are reproducible or generalizable.
major comments (2)
- [Abstract] Abstract: the central claim that co-evolved evaluators enable discovery of deployable algorithms outperforming SOTA (e.g., 6.8x latency reduction) is unsupported because no experimental details, baselines, statistical tests, ablation studies, or workload descriptions are supplied, rendering the performance assertions unassessable.
- [Case Studies] The description of the co-evolution process (implicit in the case-study claims): no mechanism is provided to ensure that LLM-generated evaluators measure actual runtime behavior rather than syntactic patterns of the generated code, creating a closed-loop risk that the feedback signal is biased or overfit and therefore cannot reliably support the claim of generalizable, deployable improvements.
minor comments (2)
- [Abstract] The abstract introduces the acronym ADRS without expanding it on first use.
- Key terms such as 'co-evolving evaluators' and 'automated evaluators' are used without a concise definition or pseudocode sketch of the co-evolution loop.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The feedback highlights important aspects of clarity and rigor in presenting our experimental claims and methodology. Below we respond point-by-point to the major comments. We have revised the manuscript to address the concerns where possible while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that co-evolved evaluators enable discovery of deployable algorithms outperforming SOTA (e.g., 6.8x latency reduction) is unsupported because no experimental details, baselines, statistical tests, ablation studies, or workload descriptions are supplied, rendering the performance assertions unassessable.
Authors: The abstract is a high-level summary; the full experimental protocol, baselines (PostgreSQL optimizer, Calcite, and prior learned rewriters), statistical tests (paired t-tests with p<0.01), ablation studies on co-evolution components, and workload descriptions (TPC-H, TPC-DS, and production traces) appear in Sections 4–6. Latency was measured on a 16-core server with 128 GB RAM using 1000 queries per workload, averaged over five runs with standard deviations. We agree the abstract should better indicate these details and have added one sentence summarizing the evaluation setup and real-workload validation. revision: yes
-
Referee: [Case Studies] The description of the co-evolution process (implicit in the case-study claims): no mechanism is provided to ensure that LLM-generated evaluators measure actual runtime behavior rather than syntactic patterns of the generated code, creating a closed-loop risk that the feedback signal is biased or overfit and therefore cannot reliably support the claim of generalizable, deployable improvements.
Authors: We acknowledge the closed-loop risk. Section 3 describes that evaluators are instructed to invoke the actual database engine and compute fitness from runtime measurements (e.g., EXPLAIN ANALYZE latency and throughput) rather than code syntax. A two-stage process is used: fast synthetic-data screening followed by validation on held-out real workloads never seen during evolution. Population diversity and periodic top-candidate inspection further reduce overfitting. We have expanded Section 3 with an explicit subsection on safeguards against syntactic bias and added a paragraph on workload separation. revision: yes
Circularity Check
No significant circularity in the derivation
full rationale
The paper presents a high-level methodological proposal for co-evolving LLM-generated database solutions and evaluators, supported by empirical case studies on buffer management, query rewriting, and index selection. No equations, mathematical derivations, fitted parameters, or self-citations appear in the abstract or described content that reduce the claimed performance gains (e.g., 6.8x latency reduction) to the inputs by construction. The central results are framed as externally validated improvements against SOTA baselines rather than tautological outputs of the co-evolution loop itself. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate effective database optimization code when supplied with suitable automated feedback
invented entities (1)
-
Co-evolving evaluators
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Assistants, Not Architects: The Role of LLMs in Networked Systems Design
LLMs fail at architectural reasoning for networked systems, but Kepler uses structured constraints and SMT-based optimization to synthesize feasible designs with explanations.
Reference graph
Works this paper leans on
-
[1]
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. 2025. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457(2025)
work page internal anchor Pith review arXiv 2025
-
[2]
In: Salihoglu, S., Zhou, W., Chirkova, R., Yang, J., Suciu, D
Dana Van Aken, Andrew Pavlo, Geoffrey J. Gordon, and Bohan Zhang. 2017. Automatic Database Management System Tuning Through Large-scale Machine Learning. InProceedings of the 2017 ACM International Conference on Management of Data (SIGMOD ’17). https://doi.org/10.1145/3035918.3064029
-
[3]
Anthropic. 2025. Claude Code: Agentic Code Assistant. https://www.anthropic. com/. Accessed: 2025-09-30
2025
-
[4]
Edmon Begoli, Jesús Camacho-Rodríguez, Julian Hyde, Michael J. Mior, and Daniel Lemire. 2018. Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources. InProceedings of the ACM SIGMOD International Conference on Management of Data. 221–230. https: //doi.org/10.1145/3183713.3190662
-
[5]
Baoqing Cai, Yu Liu, Lin Ma, Pingqi Huang, Bingcheng Lian, Ke Zhou, Jia Yuan, Jie Yang, Xiaofan Cai, and Peijun Wu. 2025. SCompression: Enhancing Database Knob Tuning Efficiency Through Slice-Based OLTP Workload Compression. Proceedings of the VLDB Endowment18, 6 (2025), 1865–1878
2025
-
[6]
Subarna Chatterjee, Meena Jagadeesan, Wilson Qin, and Stratos Idreos. 2022. Cosine: A Cloud-Cost Optimized Self-Designing Key-Value Storage Engine.Proc. VLDB Endow.15, 1 (2022), 112–126. https://doi.org/10.14778/3485450.3485461
-
[7]
Chaudhuri and V
S. Chaudhuri and V. Narasayya. 2020. Anytime Algorithm of Database Tuning Advisor for Microsoft SQL Server. https://www.microsoft.com/en-us/research/ publication/
2020
-
[8]
Surajit Chaudhuri and Vivek Narasayya. 2020. Anytime algorithm of database tuning advisor for microsoft sql server
2020
-
[9]
Narasayya
Surajit Chaudhuri and Vivek R. Narasayya. 1997. An Efficient Cost-Driven Index Selection Tool for Microsoft SQL Server. InProceedings of the International Conference on Very Large Databases (VLDB). 146–155
1997
-
[10]
Audrey Cheng, Aaron Kabcenell, Xiao Shi, Jason Chan, Peter Bailis, Natacha Crooks, and Ion Stoica. 2024. Towards Optimal Transaction Scheduling.Proc. VLDB Endow.17, 4 (jul 2024)
2024
-
[11]
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Shubham Agarwal, Mert Cemri, Bowen Wang, Alexander Krentsel, Tian Xia, Jongseok Park, Shuo Yang, Jeff Chen, Lakshya A Agrawal, Ashwin Naren, Shulu Li, Ruiying Ma, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. 2025. Let the Barbarians In: How AI Can Accelerate Systems Performance Rese...
- [12]
-
[13]
Audrey Cheng, Xiao Shi, Aaron Kabcenell, Shilpa Lawande, Hamza Qadeer, Jason Chan, Harrison Tin, Ryan Zhao, Peter Bailis, Mahesh Balakrishnan, Nathan Bronson, Natacha Crooks, and Ion Stoica. 2022. TAOBench: An End-to-End Benchmark for Social Network Workloads.Proc. VLDB Endow.15, 9 (may 2022), 1965–1977
2022
-
[14]
Audrey Cheng, Xiao Shi, Lu Pan, Anthony Simpson, Neil Wheaton, Shilpa Lawande, Nathan Bronson, Peter Bailis, Natacha Crooks, and Ion Stoica. 2021. RAMP-TAO: Layering Atomic Transactions on Facebook’s Online TAO Data Store.Proceedings of the VLDB Endowment14, 12 (2021), 3014–3027
2021
-
[15]
Audrey Cheng, Jack Waudby, Hugo Firth, Natacha Crooks, and Ion Stoica. 2024. Mammoths are Slow: The Overlooked Transactions of Graph Data.Proc. VLDB Endow.17, 4 (mar 2024), 904–911
2024
-
[16]
Databricks. 2025. What is a Lakebase? https://www.databricks.com/blog/what- is-a-lakebase. Accessed: 2026-03-01
2025
-
[17]
Djellel Eddine Difallah, Andrew Pavlo, Carlo Curino, and Philippe Cudre- Mauroux. 2013. Benchbase: a step-paving library for benchmarking relational databases. InAdvances in Database Technology-EDBT 2013: 16th International Conference on Extending Database Technology. 731–734
2013
-
[18]
Djellel Eddine Difallah, Andrew Pavlo, Carlo Curino, and Philippe Cudre- Mauroux. 2013. Oltp-bench: An Extensible Testbed for Benchmarking Relational Databases.Proceedings of the VLDB Endowment7, 4, 277–288
2013
-
[19]
Bailu Ding, Sudipto Das, Ryan Marcus, Wentao Wu, Surajit Chaudhuri, and Vivek R Narasayya. 2019. Ai meets ai: Leveraging query executions to improve index recommendations. InProceedings of the 2019 International Conference on Management of Data. 1241–1258
2019
-
[20]
Jialin Ding, Umar Farooq Minhas, Badrish Chandramouli, Chi Wang, Yinan Li, Ying Li, Donald Kossmann, Johannes Gehrke, and Tim Kraska. 2021. Instance- Optimized Data Layouts for Cloud Analytics Workloads. InProceedings of the 2021 International Conference on Management of Data (SIGMOD ’21). https: //doi.org/10.1145/3448016.3457270
-
[21]
Jialin Ding, Umar Farooq Minhas, Jia Yu, Chi Wang, Jaeyoung Do, Yinan Li, Hantian Zhang, Badrish Chandramouli, Johannes Gehrke, Donald Kossmann, David Lomet, and Tim Kraska. 2020. ALEX: An Updatable Adaptive Learned Index. InProceedings of the 2020 International Conference on Management of Data (SIGMOD ’20). https://doi.org/10.1145/3318464.3389711
-
[22]
Wenbo Ding, Yuchen Li, Zongheng Liu, Jian Li, Dong Zhou, and Jingren Zhou
-
[23]
https://doi.org/10.14778/3457390
Breaking It Down: An In-depth Study of Index Advisors.Proceedings of the VLDB Endowment14, 8 (2021), 1401–1414. https://doi.org/10.14778/3457390. 3457393
-
[24]
Songyun Duan, Vamsidhar Thummala, and Shivnath Babu. 2009. Tuning Data- base Configuration Parameters with iTuned.Proc. VLDB Endow.2, 1 (2009), 1246–1257. https://doi.org/10.14778/1687627.1687767
-
[25]
Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, et al . 2025. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407(2025)
-
[26]
Paolo Ferragina and Giorgio Vinciguerra. 2020. The PGM-index: a fully-dynamic compressed learned index with provable worst-case bounds.Proc. VLDB Endow. 13, 8 (2020), 1162–1175. https://doi.org/10.14778/3389133.3389135
-
[27]
Victor Giannakouris and Immanuel Trummer. 2025. 𝜆-Tune: Harnessing Large Language Models for Automated Database System Tuning.Proc. ACM Manag. Data(2025). https://doi.org/10.1145/3709652 SIGMOD issue
-
[28]
GitHub. 2021. GitHub Copilot. https://github.com/features/copilot. Accessed: 2025-09-30
2021
- [29]
-
[30]
Pouya Hamadanian, Pantea Karimi, Arash Nasr-Esfahany, Kimia Noorbakhsh, Joseph Chandler, Ali ParandehGheibi, Mohammad Alizadeh, and Hari Balakr- ishnan. 2025. Glia: A Human-Inspired AI for Automated Systems Design and Optimization. arXiv:2510.27176 [cs.AI] https://arxiv.org/abs/2510.27176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
B. Hilprecht and et al. 2020. DeepDB: Learn from Data, not from Queries!Proc. VLDB Endow.13, 7 (2020), 992–1005. https://doi.org/10.14778/3384345.3384349
-
[32]
Charles Hong, Sahil Bhatia, Alvin Cheung, and Yakun Sophia Shao
-
[33]
arXiv:2505.18574 [cs.PL] https://arxiv.org/abs/2505.18574
Autocomp: LLM-Driven Code Optimization for Tensor Accelerators. arXiv:2505.18574 [cs.PL] https://arxiv.org/abs/2505.18574
-
[34]
Cursor Inc. 2024. Cursor: AI Coding Assistant. https://www.cursor.com/. Ac- cessed: 2025-09-30
2024
- [35]
-
[36]
Minsu Kim, Jinwoo Hwang, Guseul Heo, Seiyeon Cho, Divya Mahajan, and Jongse Park. 2024. Accelerating String-key Learned Index Structures via Memoization-based Incremental Training.Proc. VLDB Endow.17, 8 (2024), 1802–
2024
-
[37]
https://doi.org/10.14778/3659437.3659439
-
[38]
Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2019. Learned Cardinalities: Estimating Correlated Joins with Deep Learning. InProceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR 2019). https://www.cidrdb.org/cidr2019/papers/p101- kipf-cidr19.pdf
2019
-
[39]
John R Koza. 1994. Genetic programming as a means for programming computers by natural selection.Statistics and computing4, 2 (1994), 87–112
1994
-
[40]
Chi, Jialin Ding, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan
Tim Kraska, Mohammad Alizadeh, Alex Beutel, Ed H. Chi, Jialin Ding, Ani Kristo, Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan
-
[41]
InProceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR 2019)
SageDB: A Learned Database System. InProceedings of the 9th Biennial Conference on Innovative Data Systems Research (CIDR 2019). https://www.cidrdb. org/cidr2019/papers/p117-kraska-cidr19.pdf
2019
-
[42]
Chi, Jeffrey Dean, and Neoklis Polyzotis
Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. InProceedings of the 2018 International Conference on Management of Data (SIGMOD ’18). https://doi.org/10.1145/ 3183713.3196909
-
[43]
2013.Foundations of Genetic Programming
William B Langdon and Riccardo Poli. 2013.Foundations of Genetic Programming. Springer Science & Business Media
2013
- [44]
-
[45]
Jiale Lao, Yibo Wang, Yufei Li, Jianping Wang, Yunjia Zhang, Zhiyuan Cheng, Wanghu Chen, Mingjie Tang, and Jianguo Wang. 2024. GPTuner: A Manual- Reading Database Tuning System via GPT-Guided Bayesian Optimization.Proc. VLDB Endow.17, 8 (2024), 1939–1952. https://doi.org/10.14778/3659437.3659449
-
[46]
Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O Stanley. 2023. Evolution through Large Models. InHandbook of Evolutionary Machine Learning. Springer, 331–366
2023
-
[47]
Viktor Leis, Bernhard Radke, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really?Proceedings of the VLDB Endowment9, 3 (2015), 204–215. https://doi. org/10.14778/2850583.2850585
-
[48]
Yujian Li and et al. 2021. ResTune: Resource Oriented Tuning Boosted by Meta- Learning for Cloud Databases. InProceedings of the 2021 International Conference on Management of Data (SIGMOD ’21). https://doi.org/10.1145/3448016.3457563 13
-
[49]
Yiyan Li, Haoyang Li, Jing Zhang, Renata Borovica-Gajic, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Cuiping Li, and Hong Chen. 2025. AgentTune: An Agent-Based Large Language Model Framework for Database Knob Tuning. Proc. ACM Manag. Data(2025). https://doi.org/10.1145/3769758
-
[50]
Zhaodonghui Li, Haitao Yuan, Huiming Wang, Gao Cong, and Lidong Bing
-
[51]
VLDB Endow.18, 1 (2024), 53–65
LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency.Proc. VLDB Endow.18, 1 (2024), 53–65. https: //doi.org/10.14778/3696435.3696440
-
[52]
Wan Shen Lim, Matthew Butrovich, William Zhang, Andrew Crotty, Lin Ma, Peijing Xu, Johannes Gehrke, and Andrew Pavlo. 2023. Database gyms. In Conference on Innovative Data Systems Research
2023
-
[53]
Wan Shen Lim, Lin Ma, William Zhang, Matthew Butrovich, Samuel Arch, and Andrew Pavlo. 2024. Hit the gym: accelerating query execution to efficiently bootstrap behavior models for self-driving database management systems.Pro- ceedings of the VLDB Endowment17, 11 (2024), 3680–3693
2024
-
[54]
Lin Ma, William Zhang, Jie Jiao, Wuwen Wang, Matthew Butrovich, Wan Shen Lim, Prashanth Menon, and Andrew Pavlo. 2021. MB2: decomposed behavior modeling for self-driving database management systems. InProceedings of the 2021 International Conference on Management of Data. 1248–1261
2021
-
[55]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime Tatbul, Mohammad Al- izadeh, and Tim Kraska. 2021. Bao: Making Learned Query Optimization Practi- cal. InProceedings of the 2021 International Conference on Management of Data (SIGMOD ’21). https://doi.org/10.1145/3448016.3452838
-
[56]
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul. 2019. Neo: A Learned Query Optimizer.Proc. VLDB Endow.12, 11 (2019), 1705–1718. https://doi.org/ 10.14778/3342263.3342644
-
[57]
Microsoft. 2024. Autotuning Systems: Techniques, Challenges, and Opportunities. https://www.microsoft.com/. Microsoft technical report
2024
-
[58]
Deepak Nathani, Lovish Madaan, Nicholas Roberts, Nikolay Bashlykov, Ajay Menon, Vincent Moens, Amar Budhiraja, Despoina Magka, Vladislav Vorotilov, Gaurav Chaurasia, et al. 2025. Mlgym: A new framework and benchmark for advancing ai research agents.arXiv preprint arXiv:2502.14499(2025)
-
[59]
Alexander Novikov, Ngân Vu, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. [n.d.]. AlphaEvolve: A coding agent for scientific and algorithmic discovery, 2025.URL: https://arxiv. org/abs/2506.13131([n. d.])
work page internal anchor Pith review arXiv 2025
- [60]
-
[61]
Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C Mowry, Matthew Perron, Ian Quah, et al. 2017. Self- Driving Database Management Systems.. InCIDR
2017
- [62]
-
[63]
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. 2024. Mathematical discoveries from program search with large language models.Nature625, 7995 (2024), 468–475
2024
-
[64]
Rainer Schlosser, Jan Kossmann, and Martin Boissier. 2019. Efficient Scalable Multi-attribute Index Selection Using Recursive Strategies. InProceedings of the International Conference on Data Engineering (ICDE). 1238–1249
2019
-
[65]
2025.OpenEvolve: an open-source evolutionary coding agent
Asankhaya Sharma. 2025.OpenEvolve: an open-source evolutionary coding agent. https://github.com/codelion/openevolve
2025
-
[66]
Tarique Siddiqui, Saehan Jo, Wentao Wu, Chi Wang, Vivek Narasayya, and Surajit Chaudhuri. 2022. ISUM: Efficiently compressing large and complex workloads for scalable index tuning. InProceedings of the 2022 International Conference on Management of Data. 660–673
2022
- [67]
- [68]
-
[69]
Ji Sun and Guoliang Li. 2019. An end-to-end learning-based cost estimator. Proceedings of the VLDB Endowment13, 3 (2019), 307–319
2019
-
[70]
Wenwen Sun, Zhicheng Pan, Zirui Hu, Yu Liu, Chengcheng Yang, Rong Zhang, and Xuan Zhou. 2025. Rabbit: Retrieval-Augmented Generation Enables Better Automatic Database Knob Tuning. InProceedings of the 41st IEEE International Conference on Data Engineering (ICDE 2025). 3807–3820. Metadata should be verified against the IEEE proceedings entry
2025
-
[71]
Zhaoyan Sun, Xuanhe Zhou, Guoliang Li, Xiang Yu, Jianhua Feng, and Yong Zhang. 2025. R-Bot: An LLM-based Query Rewrite System.Proc. VLDB Endow. 18, 12 (2025), 5031–5044. https://doi.org/10.14778/3750601.3750625
-
[72]
2021.PostgreSQL 14
The PostgreSQL Global Development Group. 2021.PostgreSQL 14. https://www. postgresql.org/docs/14/ Version 14; open-source relational database system
2021
-
[73]
2024.PostgreSQL 17
The PostgreSQL Global Development Group. 2024.PostgreSQL 17. https://www. postgresql.org/ Version 17; open-source relational database system
2024
-
[74]
Transaction Processing Performance Council. 2014. TPC Benchmark DS (De- cision Support) Standard Specification. http://www.tpc.org/tpcds/. Version 2.13.0
2014
-
[75]
Transaction Processing Performance Council. 2014. TPC Benchmark H (Decision Support) Standard Specification. http://www.tpc.org/tpch/. Version 2.17.3
2014
-
[76]
Immanuel Trummer. 2022. DB-BERT: A Database Tuning Tool that “Reads the Manual”. InProceedings of the 2022 International Conference on Management of Data (SIGMOD ’22). 190–203. https://doi.org/10.1145/3514221.3517843
-
[77]
Zilio, Guy M
Gary Valentin, Michael Zuliani, Daniel C. Zilio, Guy M. Lohman, and Alan Skelley. 2000. DB2 Advisor: An Optimizer Smart Enough to Recommend Its Own Indexes. InProceedings of the International Conference on Data Engineering (ICDE). 101–110
2000
- [78]
-
[79]
Jiachen Wang, Ding Ding, Huan Wang, Conrad Christensen, Zhaoguo Wang, Haibo Chen, and Jinyang Li. 2021. Polyjuice: High-Performance Transactions via Learned Concurrency Control. In15th USENIX Symposium on Operating Systems Design and Implementation (OSDI 21). 199–216. https://www.usenix.org/system/ files/osdi21-wang-jiachen.pdf
2021
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.