Recognition: 2 theorem links
· Lean TheoremA Noise Constrained Diffusion (NC-Diffusion) Framework for High Fidelity Image Compression
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Treating quantization noise from compression as the exact diffusion noise creates a stable process that boosts fidelity and inference speed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
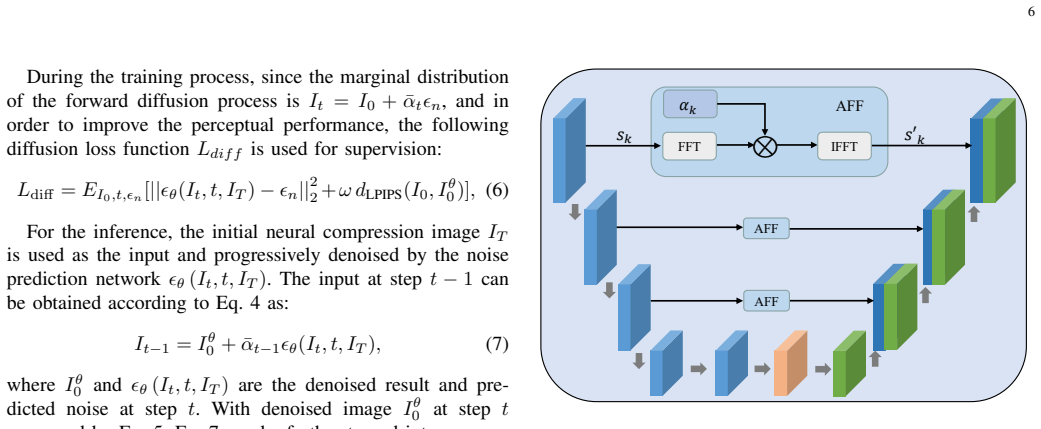
Core claim
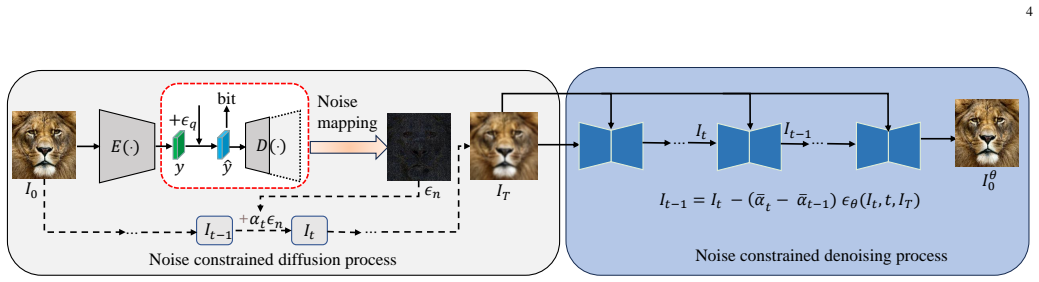
By formulating the compressor’s quantization noise as the diffusion noise in the forward process, NC-Diffusion constructs a constrained diffusion trajectory from the ground-truth image to the initial quantized compression result, removing the random-noise mismatch that produces deviations in existing diffusion compression methods and thereby improving both reconstruction fidelity and inference efficiency.
What carries the argument
The noise-constrained diffusion process that sets the compressor quantization noise as the precise noise schedule for the diffusion forward pass.
If this is right
- Reconstructed images stay closer to the originals because the diffusion process starts from the actual compression noise rather than unrelated random noise.
- Inference becomes faster because the diffusion steps no longer need to compensate for a noise mismatch.
- High-frequency details are better preserved through the added frequency-domain filtering in the U-Net skip connections.
- A zero-shot enhancement step can be applied after the diffusion process to raise fidelity without retraining.
Where Pith is reading between the lines
- The same noise-alignment idea could be tested on other generative models that currently rely on mismatched noise sources during compression pipelines.
- If the process remains stable across a wide range of bit rates, it may reduce the need to retrain separate diffusion models for each compression setting.
- The frequency-domain filter module might transfer to non-diffusion compression architectures that also use U-Net-style encoders.
Load-bearing premise
That the quantization noise added during compression behaves exactly like the noise required by the diffusion model and produces a stable, invertible mapping without new artifacts.
What would settle it
Apply the method to images whose quantization noise statistics deviate sharply from the diffusion noise schedule and check whether reconstruction error or visible artifacts increase compared with standard diffusion baselines.
Figures









read the original abstract
With the great success of diffusion models in image generation, diffusion-based image compression is attracting increasing interests. However, due to the random noise introduced in the diffusion learning, they usually produce reconstructions with deviation from the original images, leading to suboptimal compression results. To address this problem, in this paper, we propose a Noise Constrained Diffusion (NC-Diffusion) framework for high fidelity image compression. Unlike existing diffusion-based compression methods that add random Gaussian noise and direct the noise into the image space, the proposed NC-Diffusion formulates the quantization noise originally added in the learned image compression as the noise in the forward process of diffusion. Then a noise constrained diffusion process is constructed from the ground-truth image to the initial compression result generated with quantization noise. The NC-Diffusion overcomes the problem of noise mismatch between compression and diffusion, significantly improving the inference efficiency. In addition, an adaptive frequency-domain filtering module is developed to enhance the skip connections in the U-Net based diffusion architecture, in order to enhance high-frequency details. Moreover, a zero-shot sample-guided enhancement method is designed to further improve the fidelity of the image. Experiments on multiple benchmark datasets demonstrate that our method can achieve the best performance compared with existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Noise Constrained Diffusion (NC-Diffusion) framework for high-fidelity image compression. It formulates the quantization noise from learned image compression as the diffusion noise in the forward process, constructing a noise-constrained diffusion from the ground-truth image to the initial compression result. An adaptive frequency-domain filtering module is added to the U-Net to enhance high-frequency details, and a zero-shot sample-guided enhancement is introduced. The authors claim that this overcomes noise mismatch, improves inference efficiency, and achieves the best performance on multiple benchmark datasets compared to existing methods.
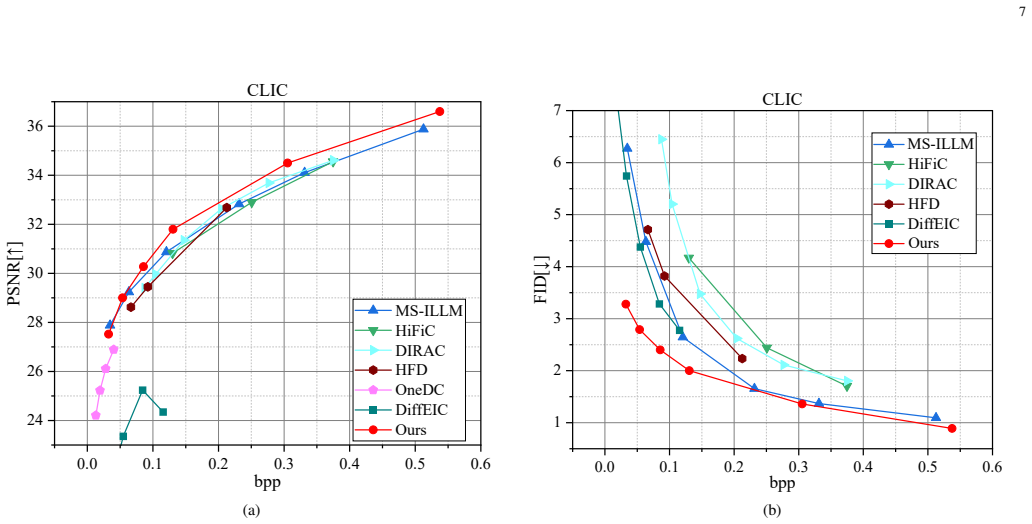
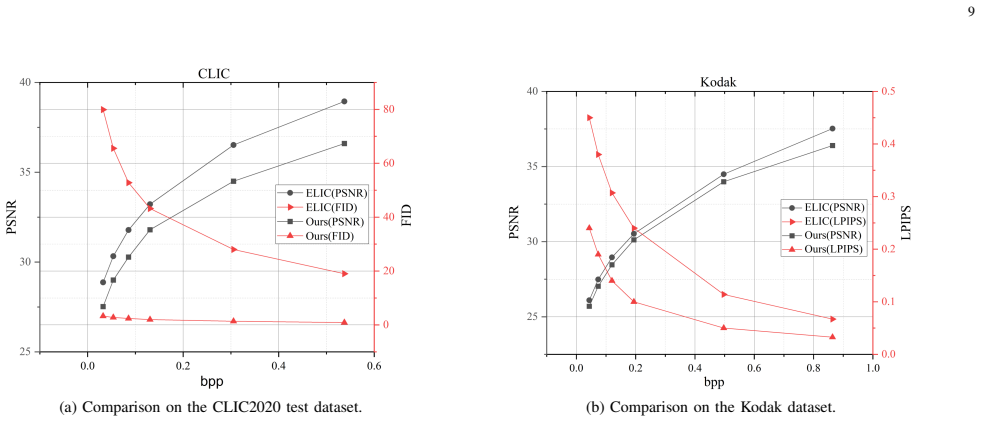
Significance. If the central construction proves stable and invertible without introducing new artifacts, the approach could meaningfully advance diffusion-based compression by directly aligning the noise distributions between compression and generation stages, leading to higher fidelity at given bit rates. The frequency-domain filtering and zero-shot enhancement are practical additions that address known limitations in diffusion models for detail preservation. The method's efficiency gains, if demonstrated, would be a notable contribution.
major comments (2)
- [NC-Diffusion process definition] The forward process is constructed by treating the compressor’s quantization noise as the exact diffusion noise. However, quantization noise is typically signal-dependent, bounded, and non-Gaussian, whereas standard diffusion reverse steps assume isotropic Gaussian increments and a score function trained accordingly. The manuscript does not clarify whether the U-Net is retrained from scratch on this noise distribution or reused from a Gaussian-trained model. This is load-bearing for the claim of stable inversion and improved fidelity, as mismatch could lead to error accumulation in the reverse trajectory.
- [Experiments] The abstract asserts best performance on benchmark datasets, but the provided description lacks reference to specific quantitative tables, ablation studies on the frequency filtering module, or error analysis comparing against standard diffusion-based compressors. Without these controls, it is difficult to verify that the gains survive standard baselines or that post-hoc tuning did not influence results.
minor comments (2)
- [Abstract] The abstract mentions 'multiple benchmark datasets' but does not name them; specifying datasets like Kodak, CLIC, or others would improve clarity.
- [Method] The description of the adaptive frequency-domain filtering module could benefit from more precise notation on how it modifies the skip connections in the U-Net.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our NC-Diffusion paper. We address the major comments point by point below, providing clarifications based on the manuscript content and indicating revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: The forward process is constructed by treating the compressor’s quantization noise as the exact diffusion noise. However, quantization noise is typically signal-dependent, bounded, and non-Gaussian, whereas standard diffusion reverse steps assume isotropic Gaussian increments and a score function trained accordingly. The manuscript does not clarify whether the U-Net is retrained from scratch on this noise distribution or reused from a Gaussian-trained model. This is load-bearing for the claim of stable inversion and improved fidelity, as mismatch could lead to error accumulation in the reverse trajectory.
Authors: We appreciate this observation on the noise distribution mismatch. In the NC-Diffusion framework (Section 3), the U-Net is trained from scratch on the specific quantization noise extracted from the learned compressor, with the forward process explicitly constrained to match the quantization characteristics rather than assuming standard isotropic Gaussian noise. This is achieved by deriving the noise schedule directly from the compressor’s quantization residuals, ensuring the score function aligns with the actual noise distribution for stable inversion. We have added a new subsection (3.1) in the revised manuscript with explicit training details, a diagram of the constrained process, and analysis showing reduced error accumulation compared to Gaussian baselines. revision: yes
-
Referee: The abstract asserts best performance on benchmark datasets, but the provided description lacks reference to specific quantitative tables, ablation studies on the frequency filtering module, or error analysis comparing against standard diffusion-based compressors. Without these controls, it is difficult to verify that the gains survive standard baselines or that post-hoc tuning did not influence results.
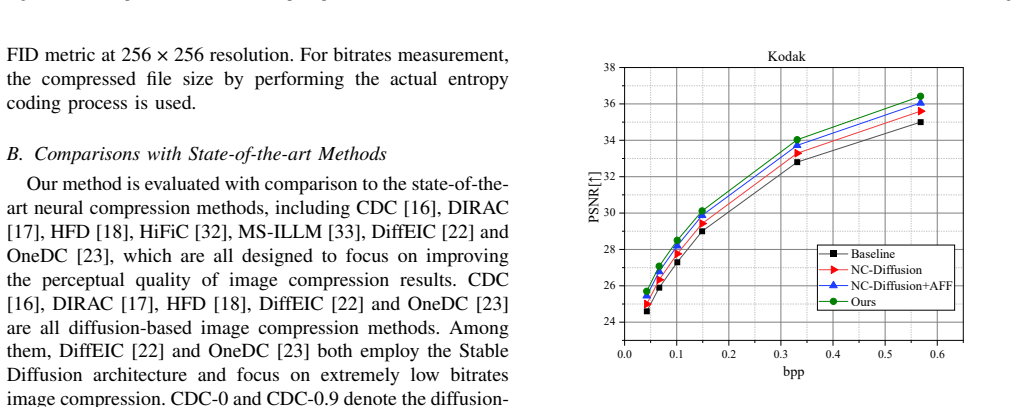
Authors: We apologize for insufficient cross-references. The manuscript presents quantitative results in Table 1 (RD curves on Kodak, CLIC, and DIV2K with PSNR/SSIM/LPIPS vs. prior art) and Table 2 (direct comparisons to diffusion-based compressors). Section 4.3 contains ablation studies isolating the adaptive frequency-domain filtering module, with metrics showing its contribution to high-frequency fidelity. Error analysis versus standard diffusion compressors appears in Figure 5 and the supplementary material. We have revised the abstract to cite these elements explicitly and expanded the experimental section with additional baseline controls to confirm the gains are not due to post-hoc tuning. revision: yes
Circularity Check
No significant circularity in NC-Diffusion construction
full rationale
The paper defines its forward process by directly substituting the compressor’s quantization noise for the diffusion noise term, thereby constructing a deterministic path from ground-truth image to quantized latent. This is an explicit modeling decision, not a fitted parameter renamed as a prediction or a self-referential loop. No equations reduce the final reconstruction metric to the training objective by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled through prior author work. The U-Net frequency filter and zero-shot enhancement are architectural additions whose benefit is asserted via external benchmark comparisons rather than internal re-statement. The derivation chain therefore remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models remain stable when the forward noise is replaced by deterministic quantization noise from a learned compressor.
invented entities (1)
-
Noise Constrained Diffusion (NC-Diffusion) process
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the proposed NC-Diffusion formulates the quantization noise originally added in the learned image compression as the noise in the forward process of diffusion... overcomes the problem of noise mismatch
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a noise constrained diffusion process is constructed from the ground-truth image to the initial compression result
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Variable rate image compression with content adaptive optimization,
T. Guo, J. Wang, Z. Cui, Y . Feng, Y . Ge, and B. Bai, “Variable rate image compression with content adaptive optimization,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 122–123
2020
-
[2]
End-to-end optimized image compression,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” inInternational Conference on Learning Representations, 2016
2016
-
[3]
Ensemble learning-based rate-distortion optimization for end-to-end image compression,
Y . Wang, D. Liu, S. Ma, F. Wu, and W. Gao, “Ensemble learning-based rate-distortion optimization for end-to-end image compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 3, pp. 1193–1207, 2020
2020
-
[4]
Variational image compression with a scale hyperprior,
J. Ball ´e, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” inInternational Conference on Learning Representations, 2018
2018
-
[5]
Dmvc: Decomposed motion modeling for learned video compression,
K. Lin, C. Jia, X. Zhang, S. Wang, S. Ma, and W. Gao, “Dmvc: Decomposed motion modeling for learned video compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 7, pp. 3502–3515, 2022
2022
-
[6]
Learning switchable priors for neural image compression,
H. Zhang, Y . Li, L. Li, and D. Liu, “Learning switchable priors for neural image compression,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[7]
Tsan: Synthesized view quality enhancement via two-stream attention network for 3d- hevc,
Z. Pan, W. Yu, J. Lei, N. Ling, and S. Kwong, “Tsan: Synthesized view quality enhancement via two-stream attention network for 3d- hevc,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 1, pp. 345–358, 2021
2021
-
[8]
The jpeg still picture compression standard,
G. K. Wallace, “The jpeg still picture compression standard,”Commu- nications of the ACM, vol. 34, no. 4, pp. 30–44, 1991
1991
-
[9]
Jpeg2000: the new still picture compression standard,
C. A. Christopoulos, T. Ebrahimi, and A. N. Skodras, “Jpeg2000: the new still picture compression standard,” inProceedings of the 2000 ACM workshops on Multimedia, 2000, pp. 45–49
2000
-
[10]
Overview of the high efficiency video coding (hevc) standard,
G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (hevc) standard,”IEEE Transactions on circuits and systems for video technology, vol. 22, no. 12, pp. 1649– 1668, 2012
2012
-
[11]
Overview of the versatile video coding (vvc) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[12]
Bpg image format,
F. Bellard, “Bpg image format,” https://bellard.org/bpg, 2015
2015
-
[13]
Ssim-motivated rate-distortion optimization for video coding,
S. Wang, A. Rehman, Z. Wang, S. Ma, and W. Gao, “Ssim-motivated rate-distortion optimization for video coding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 4, pp. 516–529, 2011
2011
-
[14]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[15]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inInternational Conference on Learning Representations, 2021
2021
-
[16]
Lossy image compression with conditional diffusion models,
R. Yang and S. Mandt, “Lossy image compression with conditional diffusion models,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[17]
N. F. Ghouse, J. Petersen, A. Wiggers, T. Xu, and G. Sautiere, “A resid- ual diffusion model for high perceptual quality codec augmentation,” arXiv preprint arXiv:2301.05489, 2023
-
[18]
Zhihao Hu, Guo Lu, and Dong Xu
E. Hoogeboom, E. Agustsson, F. Mentzer, L. Versari, G. Toderici, and L. Theis, “High-fidelity image compression with score-based generative models,”arXiv preprint arXiv:2305.18231, 2023
-
[19]
Text+ sketch: Image compression at ultra low rates,
E. Lei, Y . B. Uslu, H. Hassani, and S. S. Bidokhti, “Text+ sketch: Image compression at ultra low rates,” inProc. ICML Workshop on Neural Compression, Information Theory and Applications, 2023, pp. 1–10
2023
-
[20]
Extreme generative image compression by learning text embedding from diffusion models,
Z. Pan, X. Zhou, and H. Tian, “Extreme generative image compression by learning text embedding from diffusion models,”arXiv preprint arXiv:2211.07793, 2022
-
[21]
Misc: Ultra-low bitrate image semantic compression driven by large multimodal model,
C. Li, G. Lu, D. Feng, H. Wu, Z. Zhang, X. Liu, G. Zhai, W. Lin, and W. Zhang, “Misc: Ultra-low bitrate image semantic compression driven by large multimodal model,”IEEE Transactions on Image Processing, 2024
2024
-
[22]
Towards extreme image compression with latent feature guidance and diffusion prior,
Z. Li, Y . Zhou, H. Wei, C. Ge, and J. Jiang, “Towards extreme image compression with latent feature guidance and diffusion prior,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[23]
One-step diffusion- based image compression with semantic distillation,
N. Xue, Z. Jia, J. Li, B. Li, Y . Zhang, and Y . Lu, “One-step diffusion- based image compression with semantic distillation,”Advances in neural information processing systems, 2025
2025
-
[24]
Towards image compression with perfect realism at ultra-low bitrates,
M. Careil, M. J. Muckley, J. Verbeek, and S. Lathuili`ere, “Towards image compression with perfect realism at ultra-low bitrates,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[25]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[26]
High efficiency image compression for large visual-language models,
B. Li, S. Wang, S. Wang, and Y . Ye, “High efficiency image compression for large visual-language models,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[27]
Rethinking the func- tionality of latent representation: A logarithmic rate-distortion model for learned image compression,
Z. Ge, Z. Huang, C. Jia, S. Ma, and W. Gao, “Rethinking the func- tionality of latent representation: A logarithmic rate-distortion model for learned image compression,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[28]
Machine perception-driven facial image compression: A layered generative approach,
Y . Zhang, C. Jia, J. Chang, and S. Ma, “Machine perception-driven facial image compression: A layered generative approach,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[29]
Mpai-eev: Standardization efforts of artificial intelligence based end-to-end video coding,
C. Jia, F. Ye, F. Dong, K. Lin, L. Chiariglione, S. Ma, H. Sun, and W. Gao, “Mpai-eev: Standardization efforts of artificial intelligence based end-to-end video coding,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 5, pp. 3096–3110, 2023. 13
2023
-
[30]
Spatial decomposition and temporal fusion based inter prediction for learned video compression,
X. Sheng, L. Li, D. Liu, and H. Li, “Spatial decomposition and temporal fusion based inter prediction for learned video compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6460–6473, 2024
2024
-
[31]
Deep affine motion compensation network for inter prediction in vvc,
D. Jin, J. Lei, B. Peng, W. Li, N. Ling, and Q. Huang, “Deep affine motion compensation network for inter prediction in vvc,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 6, pp. 3923–3933, 2021
2021
-
[32]
High- fidelity generative image compression,
F. Mentzer, G. D. Toderici, M. Tschannen, and E. Agustsson, “High- fidelity generative image compression,”Advances in Neural Information Processing Systems, vol. 33, pp. 11 913–11 924, 2020
2020
-
[33]
Improving statistical fidelity for neural image compression with im- plicit local likelihood models,
M. J. Muckley, A. El-Nouby, K. Ullrich, H. J ´egou, and J. Verbeek, “Improving statistical fidelity for neural image compression with im- plicit local likelihood models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 25 426–25 443
2023
-
[34]
Generative adversarial nets,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[35]
Amit Vaisman, Guy Ohayon, Hila Manor, Michael Elad, and Tomer Michaeli
L. Theis, T. Salimans, M. D. Hoffman, and F. Mentzer, “Lossy compres- sion with gaussian diffusion,”arXiv preprint arXiv:2206.08889, 2022
-
[36]
Laplacian-guided entropy model in neural codec with blur-dissipated synthesis,
A. Khoshkhahtinat, A. Zafari, P. M. Mehta, and N. M. Nasrabadi, “Laplacian-guided entropy model in neural codec with blur-dissipated synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3045–3054
2024
-
[37]
Auto-encoding variational bayes,
D. P. Kingma, M. Wellinget al., “Auto-encoding variational bayes,” 2013
2013
-
[38]
Image super-resolution via iterative refinement,
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, and M. Norouzi, “Image super-resolution via iterative refinement,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 4, pp. 4713–4726, 2022
2022
-
[39]
Srdiff: Single image super-resolution with diffusion probabilistic mod- els,
H. Li, Y . Yang, M. Chang, S. Chen, H. Feng, Z. Xu, Q. Li, and Y . Chen, “Srdiff: Single image super-resolution with diffusion probabilistic mod- els,”Neurocomputing, vol. 479, pp. 47–59, 2022
2022
-
[40]
Resdiff: Combining cnn and diffusion model for image super-resolution,
S. Shang, Z. Shan, G. Liu, L. Wang, X. Wang, Z. Zhang, and J. Zhang, “Resdiff: Combining cnn and diffusion model for image super-resolution,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 8, 2024, pp. 8975–8983
2024
-
[41]
Resshift: Efficient diffusion model for image super-resolution by residual shifting,
Z. Yue, J. Wang, and C. C. Loy, “Resshift: Efficient diffusion model for image super-resolution by residual shifting,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[42]
Sinsr: diffusion-based image super- resolution in a single step,
Y . Wang, W. Yang, X. Chen, Y . Wang, L. Guo, L.-P. Chau, Z. Liu, Y . Qiao, A. C. Kot, and B. Wen, “Sinsr: diffusion-based image super- resolution in a single step,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 796–25 805
2024
-
[43]
Image restoration by denoising diffusion models with iteratively preconditioned guidance,
T. Garber and T. Tirer, “Image restoration by denoising diffusion models with iteratively preconditioned guidance,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 245–25 254
2024
-
[44]
Diff-plugin: Revital- izing details for diffusion-based low-level tasks,
Y . Liu, Z. Ke, F. Liu, N. Zhao, and R. W. Lau, “Diff-plugin: Revital- izing details for diffusion-based low-level tasks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4197–4208
2024
-
[45]
Residual de- noising diffusion models,
J. Liu, Q. Wang, H. Fan, Y . Wang, Y . Tang, and L. Qu, “Residual de- noising diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2773–2783
2024
-
[46]
Diffbir: Toward blind image restoration with generative diffusion prior,
X. Lin, J. He, Z. Chen, Z. Lyu, B. Dai, F. Yu, Y . Qiao, W. Ouyang, and C. Dong, “Diffbir: Toward blind image restoration with generative diffusion prior,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 430–448
2024
-
[47]
Denoising diffusion restoration models,
B. Kawar, M. Elad, S. Ermon, and J. Song, “Denoising diffusion restoration models,”Advances in Neural Information Processing Sys- tems, vol. 35, pp. 23 593–23 606, 2022
2022
-
[48]
Moe-diffir: Task-customized diffusion priors for universal compressed image restoration,
Y . Ren, X. Li, B. Li, X. Wang, M. Guo, S. Zhao, L. Zhang, and Z. Chen, “Moe-diffir: Task-customized diffusion priors for universal compressed image restoration,” inEuropean Conference on Computer Vision. Springer, 2024
2024
-
[49]
Low-light image enhancement with wavelet-based diffusion models,
H. Jiang, A. Luo, H. Fan, S. Han, and S. Liu, “Low-light image enhancement with wavelet-based diffusion models,”ACM Transactions on Graphics (TOG), vol. 42, no. 6, pp. 1–14, 2023
2023
-
[50]
Zero-led: Zero-reference lighting estimation diffusion model for low-light image enhancement,
J. He, M. Xue, Z. Liu, C. Song, and S. Zhong, “Zero-led: Zero-reference lighting estimation diffusion model for low-light image enhancement,” CoRR, 2024
2024
-
[51]
Pyramid diffusion models for low- light image enhancement,
D. Zhou, Z. Yang, and Y . Yang, “Pyramid diffusion models for low- light image enhancement,” inProceedings of the International Joint Conference on Artificial Intelligence, 2023, pp. 1795–1803
2023
-
[52]
Lightendiffusion: Unsupervised low-light image enhancement with latent-retinex diffusion models,
H. Jiang, A. Luo, X. Liu, S. Han, and S. Liu, “Lightendiffusion: Unsupervised low-light image enhancement with latent-retinex diffusion models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 161–179
2024
-
[53]
Deblurring via stochastic refinement,
J. Whang, M. Delbracio, H. Talebi, C. Saharia, A. G. Dimakis, and P. Milanfar, “Deblurring via stochastic refinement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 293–16 303
2022
-
[54]
Image deblurring with domain generalizable diffusion models,
M. Ren, M. Delbracio, H. Talebi, G. Gerig, and P. Milanfar, “Image deblurring with domain generalizable diffusion models,”arXiv preprint arXiv:2212.01789, vol. 1, 2022
-
[55]
Diffir: Efficient diffusion model for image restoration,
B. Xia, Y . Zhang, S. Wang, Y . Wang, X. Wu, Y . Tian, W. Yang, and L. Van Gool, “Diffir: Efficient diffusion model for image restoration,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 095–13 105
2023
-
[56]
arXiv preprint arXiv:2303.11435 , year=
M. Delbracio and P. Milanfar, “Inversion by direct iteration: An al- ternative to denoising diffusion for image restoration,”arXiv preprint arXiv:2303.11435, 2023
-
[57]
Freeu: Free lunch in diffusion u-net,
C. Si, Z. Huang, Y . Jiang, and Z. Liu, “Freeu: Free lunch in diffusion u-net,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4733–4743
2024
-
[58]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[59]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[60]
Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5718–5727
2022
-
[61]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[62]
A unified end-to-end framework for efficient deep image compression,
J. Liu, G. Lu, Z. Hu, and D. Xu, “A unified end-to-end framework for efficient deep image compression,”arXiv preprint arXiv:2002.03370, 2020
-
[63]
Workshop and challenge on learned image compression (clic),
“Workshop and challenge on learned image compression (clic),” http: //www.compression.cc, CVPR, 2020
2020
-
[64]
Kodak lossless true color image suite (photocd pcd0992),
E. Kodak, “Kodak lossless true color image suite (photocd pcd0992),” http://r0k.us/graphics/kodak, 1993
1993
-
[65]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inThe Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, vol. 2. Ieee, 2003, pp. 1398–1402
2003
-
[66]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[67]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[68]
Multi-realism image compression with a conditional generator,
E. Agustsson, D. Minnen, G. Toderici, and F. Mentzer, “Multi-realism image compression with a conditional generator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 324–22 333
2023
-
[69]
Image compression with product quantized masked image modeling,
A. El-Nouby, M. J. Muckley, K. Ullrich, I. Laptev, J. Verbeek, and H. J ´egou, “Image compression with product quantized masked image modeling,”Transactions on Machine Learning Research, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.