Recognition: 2 theorem links
· Lean TheoremChemVLR: Prioritizing Reasoning in Perception for Chemical Vision-Language Understanding
Pith reviewed 2026-05-10 17:47 UTC · model grok-4.3
The pith
ChemVLR builds explicit reasoning into visual perception by first naming chemical descriptors like functional groups before producing answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ChemVLR prioritizes reasoning within the perception process by explicitly identifying granular chemical descriptors such as functional groups prior to generating answers. This is achieved through a cross-modality reverse-engineering strategy combined with a rigorous filtering pipeline that curates 760k high-quality reasoning-and-captioning samples across molecular and reaction tasks, together with a three-stage training framework that systematically builds perception and reasoning capacity, resulting in state-of-the-art performance that surpasses leading proprietary models and domain-specific open-source baselines.
What carries the argument
The cross-modality reverse-engineering strategy plus filtering pipeline that generates large-scale reasoning-and-captioning data, paired with the three-stage training framework that first strengthens perception then reasoning.
If this is right
- The model generates explicit and interpretable reasoning paths instead of black-box answers for complex visual chemical problems.
- Performance gains appear on both molecular structure tasks and reaction mechanism tasks.
- Ablation results confirm that each stage of the training framework and each part of the data curation contribute measurably to the final accuracy.
- The same perception-first approach can be reused to build other domain-specific VLMs that need step-by-step feature identification.
Where Pith is reading between the lines
- Forcing granular descriptor identification early may reduce hallucinated chemical explanations even when the final answer is correct.
- If the curation method scales, similar reverse-engineering pipelines could be applied to create reasoning data for biology or materials images without manual labeling.
- The emphasis on named chemical features suggests the model could more easily adapt to new visual tasks that require recognizing the same functional groups in different contexts.
Load-bearing premise
The reverse-engineering process and filtering steps create high-quality data that teaches genuine chemical reasoning rather than artifacts of how the data was made.
What would settle it
Test the model on a fresh collection of molecular and reaction images whose underlying structures and mechanisms were never used in the reverse-engineering curation; check whether the produced reasoning paths remain accurate, consistent, and improve over baselines.
Figures











read the original abstract
While Vision-Language Models (VLMs) have demonstrated significant potential in chemical visual understanding, current models are predominantly optimized for direct visual question-answering tasks. This paradigm often results in "black-box" systems that fail to utilize the inherent capability of Large Language Models (LLMs) to infer underlying reaction mechanisms. In this work, we introduce ChemVLR, a chemical VLM designed to prioritize reasoning within the perception process. Unlike conventional chemical VLMs, ChemVLR analyzes visual inputs in a fine-grained manner by explicitly identifying granular chemical descriptors, such as functional groups, prior to generating answers. This approach ensures the production of explicit and interpretable reasoning paths for complex visual chemical problems. To facilitate this methodology, we implement a cross-modality reverse-engineering strategy, combined with a rigorous filtering pipeline, to curate a large-scale reasoning-and-captioning dataset comprising 760k high-quality samples across molecular and reaction tasks. Furthermore, we adopt a three-stage training framework that systemically builds model perception and reasoning capacity. Experiments demonstrate that ChemVLR achieves state-of-the-art (SOTA) performance, surpassing both leading proprietary models and domain-specific open-source baselines. We also provide comprehensive ablation studies to validate our training strategy and data generation designs. Code and model weights will be available at https://github.com/xxlllz/ChemVLR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChemVLR, a chemical vision-language model that prioritizes reasoning within perception by first identifying granular descriptors (e.g., functional groups) before producing answers. It curates a 760k-sample reasoning-and-captioning dataset via cross-modality reverse-engineering and a filtering pipeline, trains via a three-stage framework, and reports state-of-the-art results on molecular and reaction visual tasks that surpass proprietary and open-source baselines, with supporting ablation studies.
Significance. If the SOTA claims hold under rigorous controls for data curation bias and if the explicit reasoning paths prove more interpretable than standard VLM outputs, the work could advance domain-specific VLMs by demonstrating that perception-reasoning integration improves chemical visual understanding.
major comments (2)
- [Results] Results section (and associated tables): The abstract asserts SOTA performance surpassing proprietary and domain-specific baselines, yet no concrete metrics, baseline comparisons, error analysis, or verification that the curated data improves reasoning (rather than fitting test distributions) are visible in the provided summary; post-hoc filtering raises selection-bias risks that must be quantified with before/after performance deltas and statistical tests.
- [Data Curation] Data curation and § on cross-modality reverse-engineering: The filtering pipeline is described as rigorous, but without explicit criteria, inter-annotator agreement, or ablation showing that the 760k samples teach genuine chemical reasoning (vs. artifacts of the curation process), the central claim that this produces high-quality unbiased data remains unverified.
minor comments (2)
- [Training Framework] The three-stage training framework is outlined at a high level; a diagram or pseudocode would clarify the progression from perception to reasoning capacity.
- [Conclusion] Code and model weights are promised at a GitHub link; ensure the repository includes the exact data-generation scripts and filtering thresholds for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and the opportunity to clarify aspects of our work on ChemVLR. We address the major comments point by point below, focusing on the presentation of results and details of data curation. We are prepared to revise the manuscript accordingly to strengthen these sections.
read point-by-point responses
-
Referee: [Results] Results section (and associated tables): The abstract asserts SOTA performance surpassing proprietary and domain-specific baselines, yet no concrete metrics, baseline comparisons, error analysis, or verification that the curated data improves reasoning (rather than fitting test distributions) are visible in the provided summary; post-hoc filtering raises selection-bias risks that must be quantified with before/after performance deltas and statistical tests.
Authors: The full manuscript contains a dedicated Experiments section with tables reporting concrete metrics, direct comparisons to proprietary models (e.g., GPT-4V) and open-source baselines, plus error analysis on molecular and reaction tasks. The abstract follows convention by summarizing SOTA results without numerical values. Ablation studies already demonstrate that the reasoning-focused data yields gains on tasks requiring chemical inference, not merely test-set fitting. To directly address selection-bias concerns from filtering, we will add before/after performance deltas and statistical significance tests in the revised version. revision: partial
-
Referee: [Data Curation] Data curation and § on cross-modality reverse-engineering: The filtering pipeline is described as rigorous, but without explicit criteria, inter-annotator agreement, or ablation showing that the 760k samples teach genuine chemical reasoning (vs. artifacts of the curation process), the central claim that this produces high-quality unbiased data remains unverified.
Authors: The manuscript's data curation section details the cross-modality reverse-engineering approach and the multi-step filtering pipeline with explicit quality thresholds applied to produce the 760k samples. Ablation experiments quantify the contribution of this dataset to reasoning performance on visual chemical tasks. We will expand the section to state the filtering criteria more explicitly and elaborate on the validation steps used during curation. These elements collectively support that the data elicits genuine chemical reasoning rather than curation artifacts. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper describes an empirical system: a cross-modality data curation pipeline yielding 760k samples, a three-stage training regimen, and experimental SOTA results on external benchmarks plus ablations. No derivation chain, equations, or first-principles claims appear that could reduce to self-defined quantities, fitted parameters renamed as predictions, or self-citation load-bearing premises. Performance assertions rest on independent test sets and ablation controls rather than quantities constructed from the model's own outputs or prior author results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Explicit identification of granular chemical descriptors improves downstream reasoning accuracy and interpretability in VLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cross-modality reverse-engineering strategy... three-stage training framework... CPT, SFT, and RL
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
760k high-quality samples... molecular recognition, reaction prediction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
From generalist to specialist: A survey of large language models for chemistry. InProceedings of the 31st International Conference on Computational Linguistics, pages 1106–1123. Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. 2025. Vision-r1: Incentivizing reasoning capa- bility in multimodal large...
work page internal anchor Pith review arXiv 2025
-
[2]
Pubchem 2023 update.Nucleic acids research, 51(D1):D1373–D1380. Jiatong Li, Weida Wang, Qinggang Zhang, Junxian Li, Di Zhang, Changmeng Zheng, Shufei Zhang, Xi- aoyong Wei, and Qing Li. 2025a. Mol-r1: Towards explicit long-cot reasoning in molecule discovery. arXiv preprint arXiv:2508.08401. Junxian Li, Di Zhang, Xunzhi Wang, Zeying Hao, Jingdi Lei, Qian ...
-
[3]
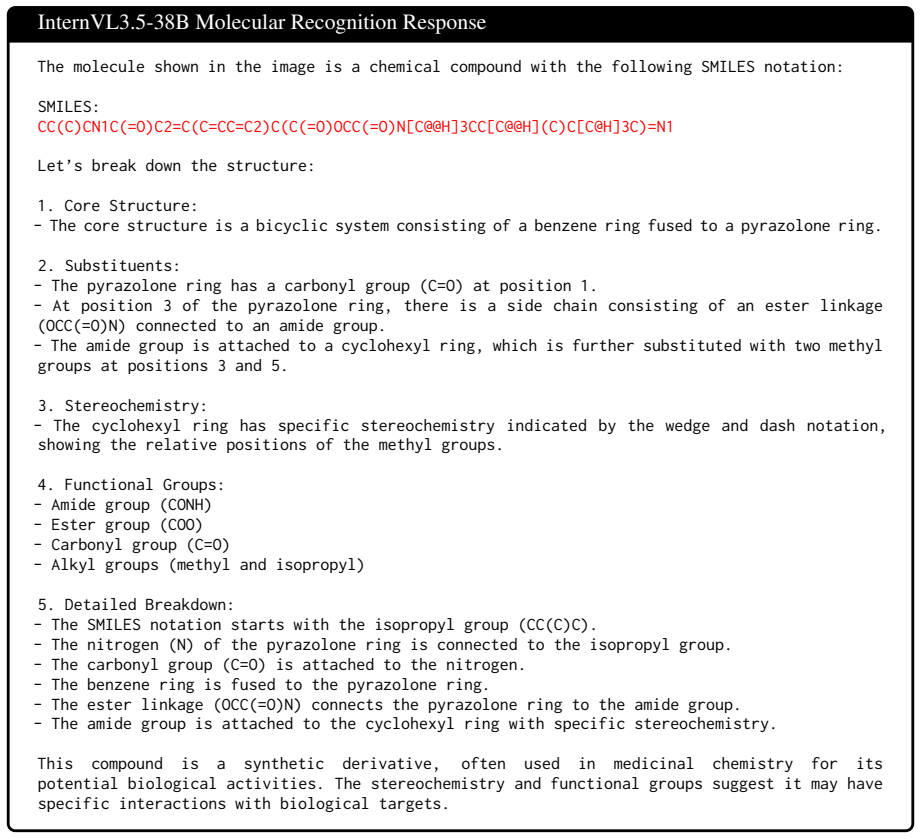
Core Structure: - The core structure is a bicyclic system consisting of a benzene ring fused to a pyrazolone ring
-
[4]
- At position 3 of the pyrazolone ring, there is a side chain consisting of an ester linkage (OCC(=O)N) connected to an amide group
Substituents: - The pyrazolone ring has a carbonyl group (C=O) at position 1. - At position 3 of the pyrazolone ring, there is a side chain consisting of an ester linkage (OCC(=O)N) connected to an amide group. - The amide group is attached to a cyclohexyl ring, which is further substituted with two methyl groups at positions 3 and 5
-
[5]
Stereochemistry: - The cyclohexyl ring has specific stereochemistry indicated by the wedge and dash notation, showing the relative positions of the methyl groups
-
[6]
Functional Groups: - Amide group (CONH) - Ester group (COO) - Carbonyl group (C=O) - Alkyl groups (methyl and isopropyl)
-
[7]
- The nitrogen (N) of the pyrazolone ring is connected to the isopropyl group
Detailed Breakdown: - The SMILES notation starts with the isopropyl group (CC(C)C). - The nitrogen (N) of the pyrazolone ring is connected to the isopropyl group. - The carbonyl group (C=O) is attached to the nitrogen. - The benzene ring is fused to the pyrazolone ring. - The ester linkage (OCC(=O)N) connects the pyrazolone ring to the amide group. - The ...
-
[8]
Based on the stereochemistry, it will be ‘C[C@@H]1CCC[C@H](C)C1‘
Cyclohexane part: I’ll start with the trans-1,2-dimethylcyclohexyl group. Based on the stereochemistry, it will be ‘C[C@@H]1CCC[C@H](C)C1‘
-
[9]
So, ‘NC(=O)COC(=O)‘
Amide linkage: The nitrogen of the cyclohexyl group is attached to a carbonyl, then a methylene, then an oxygen. So, ‘NC(=O)COC(=O)‘
-
[10]
The phthalazine itself is a benzene ring fused to a pyrazine ring with a carbonyl
Phthalazine part: The carboxylate is attached to the phthalazine. The phthalazine itself is a benzene ring fused to a pyrazine ring with a carbonyl. The nitrogen at position 2 is substituted with an isobutyl group. This translates to ‘c1nn(CC(C)C)c(=O)c2ccccc12‘
-
[11]
The ‘C(=O)‘ from the ‘COC(=O)‘ part connects to the ‘c1‘ of the phthalazine
Combining: I’m now assembling these parts, ensuring correct connectivity and ring closures. The ‘C(=O)‘ from the ‘COC(=O)‘ part connects to the ‘c1‘ of the phthalazine. Final Review: I’m performing a final check of the generated SMILES string against the mental image of the molecule. I’m verifying all atoms, bonds, stereochemistry, and ring closures. The ...
-
[12]
* The phenyl ring is also substituted with a succinimide derivative (‘N2C(=O)CC(Cl)C2=O‘)
**Analyze Reactants:** * **Main Reactant:** ‘C=CCOc1ccc(N2C(=O)CC(Cl)C2=O)cc1‘ * This molecule contains an allyloxy group (‘C=CCO-‘) attached to a phenyl ring. * The phenyl ring is also substituted with a succinimide derivative (‘N2C(=O)CC(Cl)C2=O‘). * The succinimide ring has a chlorine atom on one of its carbons, specifically at the 3-position (alpha to...
-
[13]
This is a strong, non-nucleophilic base
**Analyze Reagents and Solvent:** * **Reagent:** ‘CCN(CC)CC‘ (Triethylamine, Et3N). This is a strong, non-nucleophilic base. Its primary role is typically to deprotonate acidic protons or to facilitate elimination reactions. * **Solvent:** ‘ClCCl‘ (Dichloromethane, DCM). A common aprotic solvent, generally inert to the reaction
-
[14]
* The succinimide ring has a chlorine at the 3-position
**Predict Reaction Mechanism:** * The presence of a base (Et3N) and a chlorine atom on the succinimide ring suggests an elimination reaction. * The succinimide ring has a chlorine at the 3-position. The proton at the 4-position (alpha to the chlorine and beta to the carbonyls) is acidic due to the electron-withdrawing effects of the adjacent carbonyls and...
-
[15]
* A new five-membered dihydrofuran ring is formed, fused to the phenyl ring
**Determine Product Structure:** * The phenyl ring from the starting material remains intact. * A new five-membered dihydrofuran ring is formed, fused to the phenyl ring. The oxygen of this ring comes from the allyloxy group. * The succinimide moiety remains attached to the carbon that was originally part of the succinimide ring and is now part of the new...
-
[16]
SMILES": SMILES,
**Generate SMILES String:** * Based on the predicted structure, the SMILES string for the product is: ‘O=C1CC(c2cc3c(o2)CCCO3)C(=O)N1c1ccc(O)cc1‘. * Let’s break down the product SMILES to confirm it matches the derived structure: * ‘O=C1CC(...)C(=O)N1‘: This represents the succinimide ring. * ‘c2cc3c(o2)CCCO3‘: This represents the 2,3-dihydrobenzofuran ri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.