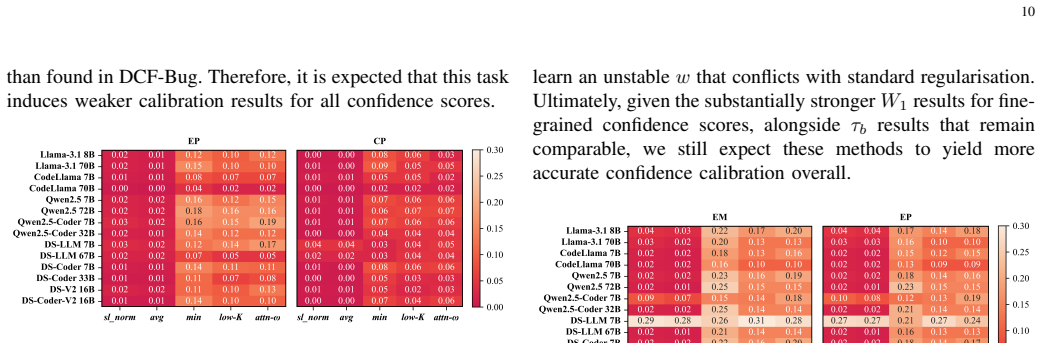
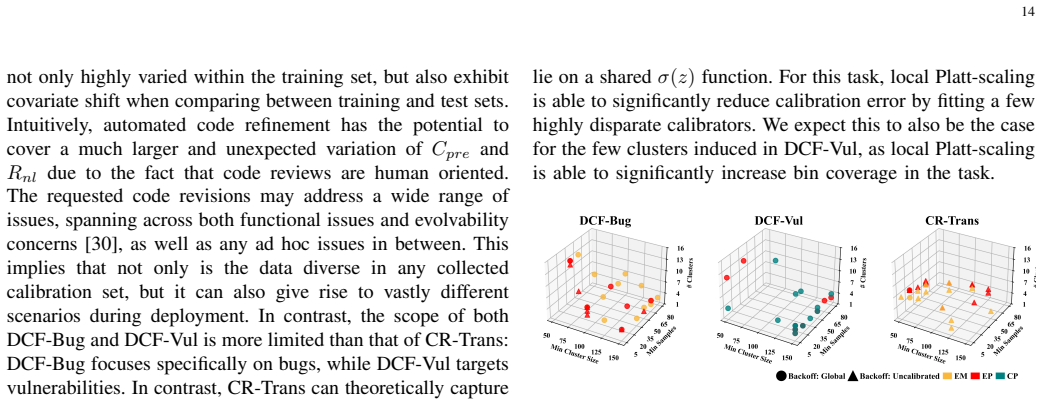
Recognition: no theorem link
Fine-grained Approaches for Confidence Calibration of LLMs in Automated Code Revision
Pith reviewed 2026-05-10 18:14 UTC · model grok-4.3
The pith
Fine-grained local calibration of confidence scores reduces error for LLMs in code revision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Local Platt-scaling applied to three distinct fine-grained confidence scores yields lower expected calibration error across probability intervals than global Platt-scaling alone, with the advantage growing when the two steps are combined, for automated code revision tasks.
What carries the argument
Local Platt-scaling performed separately on fine-grained confidence scores that capture edit-level signals rather than whole-sequence scores.
If this is right
- Developers gain a more trustworthy signal for deciding whether to accept or reject each LLM-suggested edit.
- Models can be configured to abstain from low-confidence revisions more accurately, reducing wasted review time.
- The same local-scaling step can be reused across program repair, vulnerability repair, and code refinement without task-specific redesign.
- Combining local and global scaling steps supplies a practical, post-hoc method that works on existing LLMs of varying sizes.
Where Pith is reading between the lines
- The approach may transfer to other generative software-engineering settings where correctness depends on localized changes rather than full outputs.
- Further gains could appear if the fine-grained scores were combined with temperature scaling or other non-Platt methods.
- Repeating the experiments on models trained after the study period would test whether the pattern holds as base calibration improves.
Load-bearing premise
That the main source of miscalibration in these tasks is the mismatch between global scaling and local edit decisions that determine correctness.
What would settle it
A direct head-to-head comparison in which fine-grained local scaling fails to produce lower calibration error than global scaling across the same probability intervals on the same set of models and tasks would disprove the central result.
Figures






read the original abstract
In today's AI-assisted software engineering landscape, developers increasingly depend on LLMs that are highly capable, yet inherently imperfect. The tendency of these models to produce incorrect outputs can reduce developer productivity. To this end, a canonical mitigation method is to provide calibrated confidence scores that faithfully reflect their likelihood of correctness at the instance-level. Such information allows users to make immediate decisions regarding output acceptance, abstain error-prone outputs, and better align their expectations with the model's capabilities. Since post-trained LLMs do not inherently produce well-calibrated confidence scores, researchers have developed post-hoc calibration methods, with global Platt-scaling of sequence-level confidence scores proving effective in many generative software engineering tasks but remaining unreliable or unexplored for automated code revision (ACR) tasks such as program repair, vulnerability repair, and code refinement. We hypothesise that the coarse-grained nature of this conventional method makes it ill-suited for ACR tasks, where correctness is often determined by local edit decisions and miscalibration can be sample-dependent, thereby motivating fine-grained confidence calibration. To address this, our study proposes local Platt-scaling applied separately to three different fine-grained confidence scores. Through experiments across 3 separate tasks and correctness metrics, as well as 14 different models of various sizes, we find that fine-grained confidence scores consistently achieve lower calibration error across a broader range of probability intervals, and this effect is further amplified when global Platt-scaling is applied. Our proposed approaches offer a practical solution to eliciting well-calibrated confidence scores, enabling more trustworthy and streamlined usage of imperfect models in ACR tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that conventional global Platt-scaling is ill-suited for automated code revision (ACR) tasks because correctness depends on local edit decisions and miscalibration is sample-dependent. It proposes applying local Platt-scaling separately to three fine-grained confidence scores, and reports that these achieve lower calibration error than global methods across 3 tasks, 14 models, and multiple metrics, with the benefit amplified by combining with global scaling.
Significance. If the empirical results hold under scrutiny, the work offers a practical post-hoc method to improve instance-level confidence estimates for LLMs in code revision, program repair, and related SE tasks. This could directly aid developer decision-making on whether to accept, reject, or inspect model outputs. The scale of the evaluation (multiple tasks and model sizes) is a positive feature for assessing robustness.
major comments (2)
- [Abstract / Introduction] Abstract and introduction: the central premise that 'miscalibration can be sample-dependent' and that global scaling cannot capture local-edit effects is asserted as motivation but is not supported by any diagnostic analysis (e.g., per-sample or per-edit calibration curves, variance of logits across edits, or an ablation showing where global scaling specifically fails). Without this, the reported win for fine-grained scores cannot be confidently attributed to the local-vs-global distinction rather than richer features or metric choices.
- [Experiments] Experimental section: the abstract states results across 3 tasks, 14 models, and multiple metrics, yet provides no information on datasets, statistical tests, exact definitions of the three fine-grained scores, implementation of local vs. global Platt scaling, or the precise baselines and ECE binning used. This prevents verification that the lower calibration errors actually support the claims.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We have carefully considered the comments and revised the manuscript to address the concerns regarding the motivation and experimental details. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract / Introduction] Abstract and introduction: the central premise that 'miscalibration can be sample-dependent' and that global scaling cannot capture local-edit effects is asserted as motivation but is not supported by any diagnostic analysis (e.g., per-sample or per-edit calibration curves, variance of logits across edits, or an ablation showing where global scaling specifically fails). Without this, the reported win for fine-grained scores cannot be confidently attributed to the local-vs-global distinction rather than richer features or metric choices.
Authors: We agree that explicit diagnostic analysis would better support the motivation for fine-grained calibration. In the revised manuscript, we have added a new subsection that includes per-sample calibration curves, analysis of variance in logits across different edits within samples, and an ablation comparing global scaling performance on subsets where local effects are prominent. These additions demonstrate the sample-dependent nature of miscalibration in ACR tasks and highlight specific cases where global scaling fails, thereby strengthening the attribution to the local-vs-global distinction. revision: yes
-
Referee: [Experiments] Experimental section: the abstract states results across 3 tasks, 14 models, and multiple metrics, yet provides no information on datasets, statistical tests, exact definitions of the three fine-grained scores, implementation of local vs. global Platt scaling, or the precise baselines and ECE binning used. This prevents verification that the lower calibration errors actually support the claims.
Authors: We apologize for the omission of these critical details in the initial submission. The revised paper now includes: (1) full descriptions of the datasets for each of the 3 tasks, including sources and preprocessing steps; (2) details on statistical tests performed, such as Wilcoxon signed-rank tests with reported p-values to confirm significance of improvements; (3) precise mathematical definitions and computation methods for the three fine-grained confidence scores; (4) step-by-step implementation of local Platt scaling versus global, including how local is applied per edit; (5) list of all baselines with references; and (6) ECE computation details, including the number of bins and any adaptive binning used. We believe these additions allow full verification and reproducibility of the results. revision: yes
Circularity Check
Empirical comparison with no circular derivations or self-referential predictions
full rationale
The paper reports an empirical evaluation of local versus global Platt-scaling applied to fine-grained confidence scores for automated code revision tasks. It measures calibration error (ECE) on held-out data across 3 tasks, 14 models, and multiple correctness metrics. No mathematical derivations, uniqueness theorems, or predictions appear in the provided text; the central claims rest on direct experimental comparisons rather than quantities defined in terms of the fitted parameters themselves or reduced via self-citation chains. The motivation regarding local edit decisions is stated as a hypothesis but is tested rather than assumed into the result.
Axiom & Free-Parameter Ledger
free parameters (1)
- Platt scaling parameters
axioms (1)
- domain assumption Correctness of code revisions can be reliably measured by standard automated metrics such as pass rates or edit similarity
Reference graph
Works this paper leans on
-
[1]
Repairllama: Efficient represen- tations and fine-tuned adapters for program repair,
A. Silva, S. Fang, and M. Monperrus, “Repairllama: Efficient represen- tations and fine-tuned adapters for program repair,”IEEE TSE, vol. 51, no. 8, pp. 2366–2380, 2025
2025
-
[2]
Appatch: automated adaptive prompting large language models for real-world software vulnerability patching,
Y . Nong, H. Yang, L. Cheng, H. Hu, and H. Cai, “Appatch: automated adaptive prompting large language models for real-world software vulnerability patching,” in34th USENIX, 2025
2025
-
[3]
Exploring the potential of chatgpt in automated code refinement: An empirical study,
Q. Guo, J. Cao, X. Xie, S. Liu, X. Li, B. Chen, and X. Peng, “Exploring the potential of chatgpt in automated code refinement: An empirical study,” in46th IEEE/ACM ICSE, 2024
2024
-
[4]
A large-scale survey on the usability of AI programming assistants: Successes and challenges,
J. T. Liang, C. Yang, and B. A. Myers, “A large-scale survey on the usability of AI programming assistants: Successes and challenges,” in 46th IEEE/ACM ICSE, 2024
2024
-
[5]
Expectation vs. experi- ence: Evaluating the usability of code generation tools powered by large language models,
P. Vaithilingam, T. Zhang, and E. L. Glassman, “Expectation vs. experi- ence: Evaluating the usability of code generation tools powered by large language models,” in40th ACM CHI, 2022
2022
-
[6]
Emotional strain and frustration in llm interactions in software engineering,
C. M. Montes and R. Khojah, “Emotional strain and frustration in llm interactions in software engineering,” in29th ACM EASE, 2025
2025
-
[7]
Using AI uncertainty quantification to improve human decision-making,
L. Marusich, J. Z. Bakdash, Y . Zhou, and M. Kantarcioglu, “Using AI uncertainty quantification to improve human decision-making,” in41st ICML, 2024
2024
-
[8]
Human-aligned calibration for ai- assisted decision making,
N. C. Benz and M. G. Rodriguez, “Human-aligned calibration for ai- assisted decision making,” in37th NeurIPS, 2023
2023
-
[9]
Investigating and designing for trust in ai-powered code generation tools,
R. Wang, R. Cheng, D. Ford, and T. Zimmermann, “Investigating and designing for trust in ai-powered code generation tools,” in7th ACM FAccT, 2024
2024
-
[10]
Who should I trust: AI or myself? leveraging human and AI correctness likelihood to promote appropriate trust in ai-assisted decision-making,
S. Ma, Y . Lei, X. Wang, C. Zheng, C. Shi, M. Yin, and X. Ma, “Who should I trust: AI or myself? leveraging human and AI correctness likelihood to promote appropriate trust in ai-assisted decision-making,” in41st ACM CHI, 2023
2023
-
[11]
On uncertainty calibration and selective generation in probabilistic neural summarization: A benchmark study,
P. Zablotskaia, D. Phan, J. Maynez, S. Narayan, J. Ren, and J. Z. Liu, “On uncertainty calibration and selective generation in probabilistic neural summarization: A benchmark study,” inFindings of EMNLP, 2023
2023
-
[12]
Trust dynamics in ai-assisted development: Definitions, factors, and implications,
S. Sabouri, P. Eibl, X. Zhou, M. Ziyadi, N. Medvidovic, L. Lindemann, and S. Chattopadhyay, “Trust dynamics in ai-assisted development: Definitions, factors, and implications,” in47th IEEE/ACM ICSE, 2025
2025
-
[13]
Understanding uncertainty: How lay decision-makers per- ceive and interpret uncertainty in human-ai decision making,
S. Prabhudesai, L. Yang, S. Asthana, X. Huan, Q. V . Liao, and N. Banovic, “Understanding uncertainty: How lay decision-makers per- ceive and interpret uncertainty in human-ai decision making,” in8th ACM IUI, 2023
2023
-
[14]
What guides our choices? modeling developers’ trust and behavioral intentions towards genai,
R. Choudhuri, B. Trinkenreich, R. Pandita, E. Kalliamvakou, I. Stein- macher, M. A. Gerosa, C. Sanchez, and A. Sarma, “What guides our choices? modeling developers’ trust and behavioral intentions towards genai,” in47th IEEE/ACM ICSE, 2025
2025
-
[15]
Effect of confidence and explanation on accuracy and trust calibration in ai-assisted decision making,
Y . Zhang, Q. V . Liao, and R. K. E. Bellamy, “Effect of confidence and explanation on accuracy and trust calibration in ai-assisted decision making,” in20th ACM FAT*, 2020
2020
-
[16]
On the calibration of large language models and alignment,
C. Zhu, B. Xu, Q. Wang, Y . Zhang, and Z. Mao, “On the calibration of large language models and alignment,” inFindings of EMNLP, 2023
2023
-
[17]
Enhancing language model factuality via activation-based confidence calibration and guided decoding,
X. Liu, F. F. Bayat, and L. Wang, “Enhancing language model factuality via activation-based confidence calibration and guided decoding,” in EMNLP, 2024
2024
-
[18]
Litcab: Lightweight language model calibration over short- and long-form responses,
X. Liu, M. Khalifa, and L. Wang, “Litcab: Lightweight language model calibration over short- and long-form responses,” in12th ICLR, 2024
2024
-
[19]
Thermometer: Towards universal calibration for large language models,
M. Shen, S. Das, K. H. Greenewald, P. Sattigeri, G. W. Wornell, and S. Ghosh, “Thermometer: Towards universal calibration for large language models,” in41st ICML, 2024
2024
-
[20]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” in34th ICML, 2017
2017
-
[21]
Calibration and correctness of language models for code,
C. Spiess, D. Gros, K. S. Pai, M. Pradel, M. R. I. Rabin, A. Alipour, S. Jha, P. Devanbu, and T. Ahmed, “Calibration and correctness of language models for code,” in47th IEEE/ACM ICSE, 2025
2025
-
[22]
Calibration of large language models on code summarization,
Y . Virk, P. T. Devanbu, and T. Ahmed, “Calibration of large language models on code summarization,” in33rd ACM FSE, 2025
2025
-
[23]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,
J. Plattet al., “Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods,”Adv. Large Margin Classif., vol. 10, no. 3, pp. 61–74, 1999
1999
-
[24]
Codere- viewqa: The code review comprehension assessment for large language models,
H. Y . Lin, C. Liu, H. Gao, P. Thongtanunam, and C. Treude, “Codere- viewqa: The code review comprehension assessment for large language models,” inFindings of ACL, 2025
2025
-
[25]
Large language models for software engi- neering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engi- neering: A systematic literature review,”ACM TOSEM, vol. 33, no. 8, 2024
2024
-
[26]
Repairbench: Leaderboard of frontier models for program repair,
A. Silva and M. Monperrus, “Repairbench: Leaderboard of frontier models for program repair,” in2nd IEEE/ACM LLM4Code@ICSE, 2025
2025
-
[27]
Automated program repair via conversation: Fixing 162 out of 337 bugs for$0.42 each using chatgpt,
C. S. Xia and L. Zhang, “Automated program repair via conversation: Fixing 162 out of 337 bugs for$0.42 each using chatgpt,” in33rd ACM SIGSOFT ISSTA, 2024
2024
-
[28]
Large language model for vulnerability detection and repair: Literature review and the road ahead,
X. Zhou, S. Cao, X. Sun, and D. Lo, “Large language model for vulnerability detection and repair: Literature review and the road ahead,” ACM TOSEM, vol. 34, no. 5, 2025
2025
-
[29]
Code review automation: Strengths and weaknesses of the state of the art,
R. Tufano, O. Dabic, A. Mastropaolo, M. Ciniselli, and G. Bavota, “Code review automation: Strengths and weaknesses of the state of the art,”IEEE TSE, vol. 50, no. 2, pp. 338–353, 2024
2024
-
[30]
What types of defects are really discovered in code reviews?
M. V . M ¨antyl¨a and C. Lassenius, “What types of defects are really discovered in code reviews?”IEEE TSE, vol. 35, no. 3, pp. 430–448, 2009
2009
-
[31]
A close look into the calibration of pre-trained language models,
Y . Chen, L. Yuan, G. Cui, Z. Liu, and H. Ji, “A close look into the calibration of pre-trained language models,” in61st ACL, 2023
2023
-
[32]
On the inference calibration of neural machine translation,
S. Wang, Z. Tu, S. Shi, and Y . Liu, “On the inference calibration of neural machine translation,” in58th ACL, 2020
2020
-
[33]
Model calibration in dense classification with adaptive label perturba- tion,
J. Liu, C. Ye, S. Wang, R. Cui, J. Zhang, K. Zhang, and N. Barnes, “Model calibration in dense classification with adaptive label perturba- tion,” inIEEE/CVF ICCV, 2023
2023
-
[34]
Post- hoc uncertainty calibration for domain drift scenarios,
C. Tomani, S. Gruber, M. E. Erdem, D. Cremers, and F. Buettner, “Post- hoc uncertainty calibration for domain drift scenarios,” inIEEE/CVF CVPR, 2021
2021
-
[35]
Sample- dependent adaptive temperature scaling for improved calibration,
T. Joy, F. Pinto, S.-N. Lim, P. H. Torr, and P. K. Dokania, “Sample- dependent adaptive temperature scaling for improved calibration,” in 37th AAAI, 2023
2023
-
[36]
Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers,
B. Zadrozny and C. Elkan, “Obtaining calibrated probability estimates from decision trees and naive bayesian classifiers,” in8th ICML, 2001
2001
-
[37]
Transforming classifier scores into accurate multiclass probability estimates,
——, “Transforming classifier scores into accurate multiclass probability estimates,” in8th ACM SIGKDD KDD, 2002
2002
-
[38]
Language Models (Mostly) Know What They Know
S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnsonet al., “Language models (mostly) know what they know,”arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,
K. Tian, E. Mitchell, A. Zhou, A. Sharma, R. Rafailov, H. Yao, C. Finn, and C. Manning, “Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback,” inEMNLP, 2023
2023
-
[40]
Teaching models to express their uncertainty in words,
S. Lin, J. Hilton, and O. Evans, “Teaching models to express their uncertainty in words,”TMLR, 2022
2022
-
[41]
Sampling-based multi-dimensional recalibration,
Y . Chung, I. Char, and J. Schneider, “Sampling-based multi-dimensional recalibration,” in41st ICML, 2024
2024
-
[42]
On calibration of pre-trained code models,
Z. Zhou, C. Sha, and X. Peng, “On calibration of pre-trained code models,” inIEEE/ACM 46th ICSE, 2024
2024
-
[43]
Generation probabilities are not enough: Uncertainty highlighting in ai code completions,
H. Vasconcelos, G. Bansal, A. Fourney, Q. V . Liao, and J. Wort- man Vaughan, “Generation probabilities are not enough: Uncertainty highlighting in ai code completions,”ACM TOCHI, vol. 32, no. 1, pp. 1–30, 2025
2025
-
[44]
Ru-sure? uncertainty-aware code suggestions by maximizing utility across random user intents,
D. D. Johnson, D. Tarlow, and C. Walder, “Ru-sure? uncertainty-aware code suggestions by maximizing utility across random user intents,” in 40th ICML, 2023
2023
-
[45]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,” inEMNLP, 2023
2023
-
[46]
Impact of code language models on automated program repair,
N. Jiang, K. Liu, T. Lutellier, and L. Tan, “Impact of code language models on automated program repair,” in45th IEEE/ACM ICSE, 2023
2023
-
[47]
Finding a
V . Satopaa, J. R. Albrecht, D. E. Irwin, and B. Raghavan, “Finding a ”kneedle” in a haystack: Detecting knee points in system behavior,” in 31st IEEE/ACM ICDCSW, 2011
2011
-
[48]
Contextualized sequence likelihood: En- hanced confidence scores for natural language generation,
Z. Lin, S. Trivedi, and J. Sun, “Contextualized sequence likelihood: En- hanced confidence scores for natural language generation,” inEMNLP, 2024
2024
-
[49]
Quantifying attention flow in transform- ers,
S. Abnar and W. H. Zuidema, “Quantifying attention flow in transform- ers,” in58th ACL, 2020
2020
-
[50]
On calibration and out-of-domain generalization,
Y . Wald, A. Feder, D. Greenfeld, and U. Shalit, “On calibration and out-of-domain generalization,” in35th NeurIPS, 2021
2021
-
[51]
Multicalibra- tion for confidence scoring in llms,
G. Detommaso, M. A. Bertran, R. Fogliato, and A. Roth, “Multicalibra- tion for confidence scoring in llms,” in41st ICML, 2024
2024
-
[52]
Robust calibration with multi- domain temperature scaling,
Y . Yu, S. Bates, Y . Ma, and M. Jordan, “Robust calibration with multi- domain temperature scaling,” in36th NeurIPS, 2022
2022
-
[53]
Umap: Uniform manifold approximation and projection,
L. McInnes, J. Healy, N. Saul, and L. Großberger, “Umap: Uniform manifold approximation and projection,”J. Open Source Softw., vol. 3, no. 29, p. 861, 2018
2018
-
[54]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Y . Zhang, M. Li, D. Long, X. Zhang, H. Lin, B. Yang, P. Xie, A. Yang, D. Liu, J. Lin, F. Huang, and J. Zhou, “Qwen3 embedding: 17 Advancing text embedding and reranking through foundation models,” arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Mteb: Massive text embedding benchmark,
N. Muennighoff, N. Tazi, L. Magne, and N. Reimers, “Mteb: Massive text embedding benchmark,” in17th EACL, 2023
2023
-
[56]
Density-based clustering based on hierarchical density estimates,
R. J. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical density estimates,” inSpringer PAKDD, 2013
2013
-
[57]
Obtaining well calibrated probabilities using bayesian binning,
M. P. Naeini, G. F. Cooper, and M. Hauskrecht, “Obtaining well calibrated probabilities using bayesian binning,” in29th AAAI, 2015
2015
-
[58]
Verified uncertainty calibration,
A. Kumar, P. Liang, and T. Ma, “Verified uncertainty calibration,” in 32nd NeurIPS, 2019
2019
-
[59]
Mea- suring calibration in deep learning,
J. Nixon, M. W. Dusenberry, L. Zhang, G. Jerfel, and D. Tran, “Mea- suring calibration in deep learning,” inIEEE/CVF CVPR, 2019
2019
-
[60]
Mitigating bias in calibration error estimation,
R. Roelofs, N. Cain, J. Shlens, and M. C. Mozer, “Mitigating bias in calibration error estimation,” in25th AISTATS, 2022
2022
-
[61]
Verification of forecasts expressed in terms of probability,
W. B. Glennet al., “Verification of forecasts expressed in terms of probability,”Mon. Weather Rev., vol. 78, no. 1, pp. 1–3, 1950
1950
-
[62]
Rethinking calibration of deep neural networks: Do not be afraid of overconfidence,
D. Wang, L. Feng, and M. Zhang, “Rethinking calibration of deep neural networks: Do not be afraid of overconfidence,” in34th NeurIPS, 2021
2021
-
[63]
Are large language models memorizing bug bench- marks?
D. Ramos, C. Mamede, K. Jain, P. Canelas, C. Gamboa, and C. Le Goues, “Are large language models memorizing bug bench- marks?” in2nd IEEE/ACM LLM4Code@ICSE, 2025
2025
-
[64]
Deepcode AI fix: Fixing security vulnerabilities with large language models,
B. Berabi, A. Gronskiy, V . Raychev, G. Sivanrupan, V . Chibotaru, and M. T. Vechev, “Deepcode AI fix: Fixing security vulnerabilities with large language models,”arXiv preprint arXiv.2402.13291, 2024
-
[65]
How effective are neural networks for fixing security vulnerabilities,
Y . Wu, N. Jiang, H. V . Pham, T. Lutellier, J. Davis, L. Tan, P. Babkin, and S. Shah, “How effective are neural networks for fixing security vulnerabilities,” in32nd ACM SIGSOFT ISSTA, 2023
2023
-
[66]
Automating code review activities by large-scale pre-training,
Z. Li, S. Lu, D. Guo, N. Duan, S. Jannu, G. Jenks, D. Majumder, J. Green, A. Svyatkovskiy, S. Fu, and N. Sundaresan, “Automating code review activities by large-scale pre-training,” in30th ACM ESEC/FSE, 2022
2022
-
[67]
Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,
J. Lu, L. Yu, X. Li, L. Yang, and C. Zuo, “Llama-reviewer: Advancing code review automation with large language models through parameter- efficient fine-tuning,” in34th IEEE ISSRE, 2023
2023
-
[68]
Too noisy to learn: Enhancing data quality for code review comment generation,
C. Liu, H. Y . Lin, and P. Thongtanunam, “Too noisy to learn: Enhancing data quality for code review comment generation,” in22nd IEEE/ACM MSR, 2025
2025
-
[69]
NL-EDIT: Correcting semantic parse errors through natural language interaction,
A. Elgohary, C. Meek, M. Richardson, A. Fourney, G. Ramos, and A. H. Awadallah, “NL-EDIT: Correcting semantic parse errors through natural language interaction,” inNAACL-HLT, 2021
2021
-
[70]
Generation-based code review automation: How far are we?
X. Zhou, K. Kim, B. Xu, D. Han, J. He, and D. Lo, “Generation-based code review automation: How far are we?” in31st IEEE/ACM ICPC, 2023
2023
-
[71]
Aligning offline metrics and human judgments of value for code generation models,
V . Dibia, A. Fourney, G. Bansal, F. Poursabzi-Sangdeh, H. Liu, and S. Amershi, “Aligning offline metrics and human judgments of value for code generation models,” inFindings of ACL, 2023
2023
-
[72]
Binary codes capable of correcting deletions, inser- tions, and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, inser- tions, and reversals,”Sov. Phys. Dokl., vol. 10, pp. 707–710, 1965
1965
-
[73]
Snyk code - developer-focused, real-time sast
Snyk, “Snyk code - developer-focused, real-time sast.” https://snyk.io/ product/snyk-code/, accessed: Oct. 14, 2025
2025
-
[74]
Intention is all you need: Refining your code from your intention,
Q. Guo, X. Xie, S. Liu, M. Hu, X. Li, and L. Bu, “Intention is all you need: Refining your code from your intention,” in47th IEEE/ACM ICSE, 2025
2025
-
[75]
Grounded copilot: How programmers interact with code-generating models,
S. Barke, M. B. James, and N. Polikarpova, “Grounded copilot: How programmers interact with code-generating models,” inACM OOPSLA, 2023
2023
-
[76]
A simulation study of the number of events per variable in logistic regression analysis,
P. Peduzzi, J. Concato, E. Kemper, T. R. Holford, and A. R. Feinstein, “A simulation study of the number of events per variable in logistic regression analysis,”Elsevier J. Clin. Epidemiol., vol. 49, no. 12, pp. 1373–1379, 1996
1996
-
[77]
A new measure of rank correlation,
M. G. Kendall, “A new measure of rank correlation,”Biometrika, vol. 30, no. 1-2, pp. 81–93, 1938
1938
-
[78]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,
L. Kuhn, Y . Gal, and S. Farquhar, “Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation,” in11th ICLR, 2023
2023
-
[79]
Pangu-{\Sigma}: Towards trillion parameter language model with sparse heterogeneous comput- ing,
X. Ren, P. Zhou, X. Meng, X. Huang, Y . Wang, W. Wang, P. Li, X. Zhang, A. Podolskiy, G. Arshinovet al., “Pangu-{\Sigma}: Towards trillion parameter language model with sparse heterogeneous comput- ing,”arXiv preprint arXiv:2303.10845, 2023
-
[80]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.