Recognition: no theorem link
WisdomInterrogatory (LuWen): An Open-Source Legal Large Language Model Technical Report
Pith reviewed 2026-05-10 18:37 UTC · model grok-4.3
The pith
LuWen adapts a general Chinese language model to legal work through pre-training on legal texts, instruction fine-tuning, and retrieval from a knowledge base.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
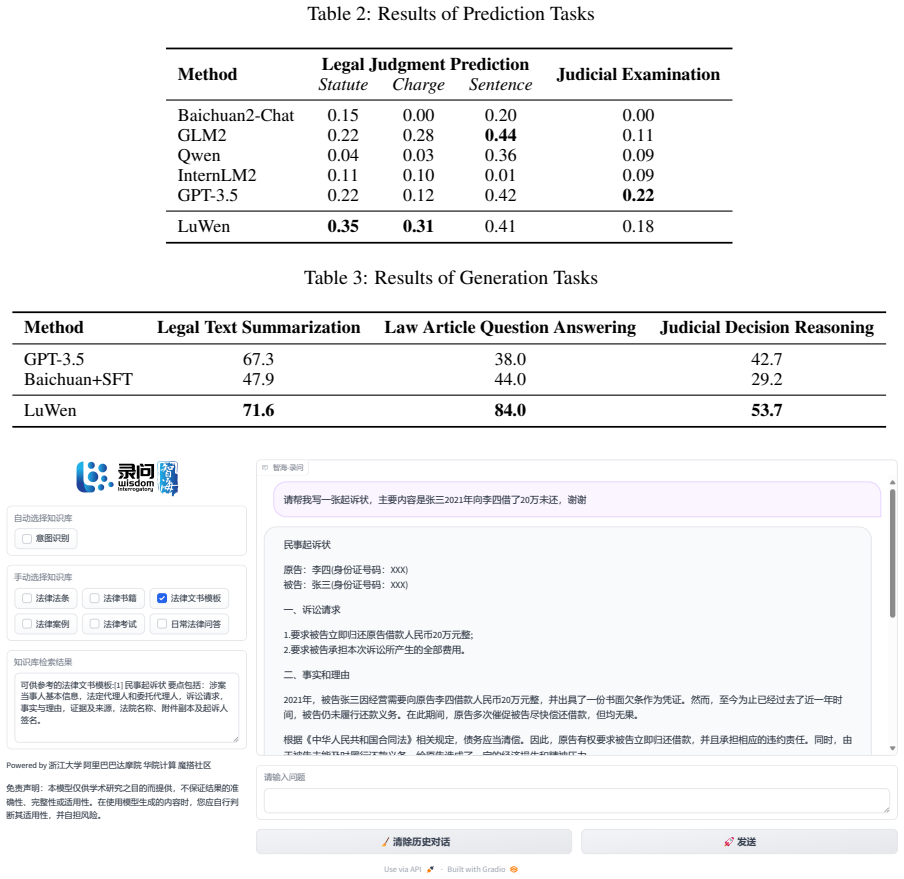
LuWen is created by continual pre-training on a large-scale legal corpus, supervised fine-tuning with legal instruction data, and retrieval-augmented generation integrated with a comprehensive legal knowledge base. On five representative legal tasks spanning prediction and generation, it outperforms strong baselines and demonstrates effective adaptation of general-purpose models to the legal domain.
What carries the argument
The three-step adaptation of continual pre-training on legal corpus, supervised fine-tuning on legal instructions, and retrieval-augmented generation from a legal knowledge base.
Load-bearing premise
That outperformance on the five selected legal tasks means the adaptation works for real-world legal demands beyond those specific tests and baselines.
What would settle it
If LuWen shows no advantage over general models when tested on a new set of legal cases, documents, or questions drawn from outside the original evaluation sets.
Figures




read the original abstract
Large language models have demonstrated remarkable capabilities across a wide range of natural language processing tasks, yet their application in the legal domain remains challenging due to the specialized terminology, complex reasoning requirements, and rapidly evolving legal knowledge involved. In this paper, we present WisdomInterrogatory (LuWen), an open-source Chinese legal language model built upon the Baichuan foundation model through three key techniques: continual pre-training on a large-scale legal corpus, supervised fine-tuning with carefully curated legal instruction data, and retrieval-augmented generation integrated with a comprehensive legal knowledge base. We evaluate LuWen on five representative legal tasks spanning both prediction and generation settings, including legal judgment prediction, judicial examination, legal text summarization, law article question answering, and judicial decision reasoning. Experimental results show that LuWen outperforms several strong baselines, demonstrating the effectiveness of our approach in adapting general-purpose language models to the legal domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents WisdomInterrogatory (LuWen), an open-source Chinese legal large language model built on the Baichuan foundation model. It applies three adaptation techniques—continual pre-training on a large-scale legal corpus, supervised fine-tuning with curated legal instruction data, and retrieval-augmented generation using a comprehensive legal knowledge base—and evaluates the resulting model on five tasks spanning prediction and generation: legal judgment prediction, judicial examination, legal text summarization, law article question answering, and judicial decision reasoning. The central claim is that LuWen outperforms several strong baselines on these tasks, thereby demonstrating the effectiveness of the adaptation approach.
Significance. If the performance claims hold under proper controls, the work supplies a publicly released Chinese legal LLM that could serve as a useful baseline and starting point for domain-specific legal NLP research. The open-source release of the model and the described pipeline constitutes a concrete, reusable artifact that lowers barriers for subsequent studies in legal AI.
major comments (1)
- [Experimental Results] Experimental Results section: no ablation variants are reported that isolate the contributions of continual pre-training, supervised fine-tuning, and retrieval-augmented generation (e.g., base model + SFT only, or + continual pre-training only). Without these controls on the same five tasks, the attribution of gains to the specific combination of techniques rather than to additional legal data exposure cannot be established, directly weakening the claim that the results demonstrate the effectiveness of the proposed approach.
minor comments (2)
- [Abstract] Abstract: the statement that LuWen 'outperforms several strong baselines' is not accompanied by any quantitative metrics, baseline identifiers, or statistical test results, making it impossible for readers to gauge the magnitude or reliability of the claimed improvements from the abstract alone.
- [Introduction] The five tasks are described as 'representative,' yet no justification or coverage analysis is provided for why these particular tasks adequately sample real-world legal reasoning demands.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the value of the open-source release of LuWen as a baseline for legal NLP research. We address the major comment below.
read point-by-point responses
-
Referee: [Experimental Results] Experimental Results section: no ablation variants are reported that isolate the contributions of continual pre-training, supervised fine-tuning, and retrieval-augmented generation (e.g., base model + SFT only, or + continual pre-training only). Without these controls on the same five tasks, the attribution of gains to the specific combination of techniques rather than to additional legal data exposure cannot be established, directly weakening the claim that the results demonstrate the effectiveness of the proposed approach.
Authors: We agree that ablation studies isolating each adaptation component would strengthen the attribution of performance gains. The current manuscript reports results only for the full LuWen model (combining continual pre-training, supervised fine-tuning, and retrieval-augmented generation) against external baselines on the five tasks. In the revised version, we will add ablation experiments evaluating the base Baichuan model with individual and partial combinations of the techniques across all five tasks (legal judgment prediction, judicial examination, legal text summarization, law article question answering, and judicial decision reasoning). These results will be incorporated into the Experimental Results section to more clearly demonstrate the contribution of each technique. revision: yes
Circularity Check
No circularity: empirical report with no derivations or self-referential predictions
full rationale
The paper is a standard empirical engineering report: it describes training LuWen via continual pre-training on legal corpus, SFT on instruction data, and RAG with a knowledge base, then reports outperformance on five fixed legal tasks versus baselines. No equations, no fitted parameters renamed as predictions, no self-citation load-bearing uniqueness theorems, and no derivation chain that reduces to its own inputs by construction. The central claim rests on experimental comparisons, which are externally falsifiable and do not contain the circular patterns enumerated. Absence of ablations is a methodological weakness but does not constitute circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
PoliLegalLM: A Technical Report on a Large Language Model for Political and Legal Affairs
PoliLegalLM, trained with continued pretraining, progressive SFT, and preference RL on a legal corpus, outperforms similar-scale models on LawBench, LexEval, and a real-world PoliLegal dataset while staying competitiv...
Reference graph
Works this paper leans on
-
[1]
Qwen technical report.CoRR, abs/2309.16609. Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Training language models to follow instruc- tions with human feedback. InAdvances in Neural Information Processing Systems 35: Annual Confer- ence on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9,
2022
-
[3]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Chain-of-thought prompting elicits rea- soning in large language models.Advances in neural information processing systems, 35:24824–24837. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023a. Auto- gen: Enabling next-gen llm applications via multi- agent conversation framework...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Baichuan 2: Open large-scale language models
Baichuan 2: Open large-scale language models. CoRR, abs/2309.10305. Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, Weng Lam Tam, Zixuan Ma, Yufei Xue, Jidong Zhai, Wenguang Chen, Zhiyuan Liu, Peng Zhang, Yuxiao Dong, and Jie Tang
-
[5]
In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
GLM-130B: an open bilingual pre-trained model. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.