Recognition: no theorem link
Evaluating LLM-Based 0-to-1 Software Generation in End-to-End CLI Tool Scenarios
Pith reviewed 2026-05-10 18:29 UTC · model grok-4.3
The pith
Current large language models achieve less than 43 percent success when tasked with generating complete command-line interface tools from scratch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
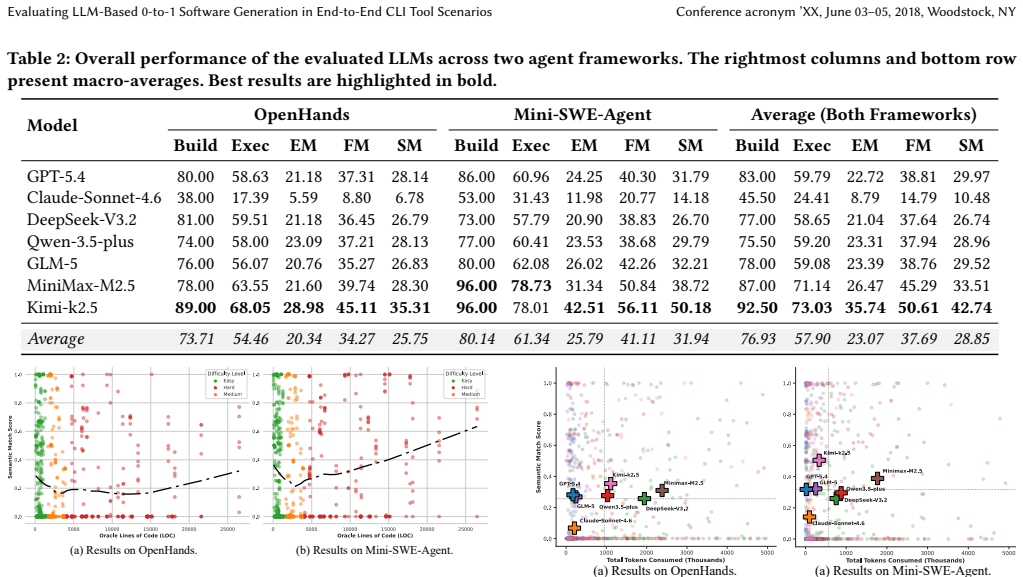
The paper claims that state-of-the-art LLMs are currently limited in their ability to perform 0-to-1 software generation, as demonstrated by success rates below 43 percent on the CLI-Tool-Bench, which tests full end-to-end creation of diverse CLI tools through black-box differential testing against human oracles.
What carries the argument
The CLI-Tool-Bench benchmark, which employs a structure-agnostic approach and a black-box differential testing framework with multi-tiered equivalence metrics to validate generated CLI tools against human-written oracles in sandboxed executions.
Load-bearing premise
The black-box differential testing framework accurately captures true functional correctness of the generated CLI tools without being affected by environment variations or gaps in the oracle test coverage.
What would settle it
Re-evaluating the same generated tools using a different set of human-written oracles or across multiple operating systems and observing if the reported success rates remain consistent or drop significantly.
Figures




read the original abstract
Large Language Models (LLMs) are driving a shift towards intent-driven development, where agents build complete software from scratch. However, existing benchmarks fail to assess this 0-to-1 generation capability due to two limitations: reliance on predefined scaffolds that ignore repository structure planning, and rigid white-box unit testing that lacks end-to-end behavioral validation. To bridge this gap, we introduce CLI-Tool-Bench, a structure-agnostic benchmark for evaluating the ground-up generation of Command-Line Interface (CLI) tools. It features 100 diverse real-world repositories evaluated via a black-box differential testing framework. Agent-generated software is executed in sandboxes, comparing system side effects and terminal outputs against human-written oracles using multi-tiered equivalence metrics. Evaluating seven state-of-the-art LLMs, we reveal that top models achieve under 43% success, highlighting the ongoing challenge of 0-to-1 generation. Furthermore, higher token consumption does not guarantee better performance, and agents tend to generate monolithic code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CLI-Tool-Bench, a structure-agnostic benchmark consisting of 100 diverse real-world repositories, to evaluate LLMs on 0-to-1 generation of complete CLI tools from natural language intent. It employs a black-box differential testing framework that runs generated tools in sandboxes and scores them against human-written oracles using multi-tiered equivalence metrics on terminal outputs and system side effects. The evaluation of seven state-of-the-art LLMs reports that top models achieve success rates below 43%, with additional findings that higher token consumption does not guarantee better performance and that generated code tends to be monolithic.
Significance. If the evaluation framework proves reliable, this work is significant for providing empirical evidence on the current limitations of LLMs in end-to-end software generation without scaffolds or white-box tests. The benchmark fills a gap in existing evaluations by emphasizing behavioral validation against real-world oracles, offering insights into planning, execution, and code structure challenges that could guide future agent-based development research.
major comments (1)
- The central claim that top models achieve under 43% success (abstract) rests on the black-box differential testing framework and multi-tiered equivalence metrics. However, the paper provides no oracle coverage metrics, inter-annotator agreement scores for oracle construction, or sensitivity analysis of the tier thresholds, leaving open the risk of systematic false negatives from incomplete coverage or environment variance that could inflate the reported failure rate.
minor comments (2)
- The abstract states the 43% figure and methodology overview but omits which specific model(s) achieve the top score and the precise definition of 'success' under the multi-tiered metrics, which would improve immediate clarity for readers.
- Repository selection criteria for the 100 real-world repositories are not detailed in the provided summary, which affects reproducibility and assessment of diversity claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of our evaluation framework's reliability. We address the major comment in detail below and have incorporated revisions to strengthen the manuscript where feasible.
read point-by-point responses
-
Referee: The central claim that top models achieve under 43% success (abstract) rests on the black-box differential testing framework and multi-tiered equivalence metrics. However, the paper provides no oracle coverage metrics, inter-annotator agreement scores for oracle construction, or sensitivity analysis of the tier thresholds, leaving open the risk of systematic false negatives from incomplete coverage or environment variance that could inflate the reported failure rate.
Authors: We agree that additional validation would further bolster confidence in the reported success rates. In the revised manuscript, we have added a sensitivity analysis of the tier thresholds (new Appendix section), demonstrating that success rates for top models remain below 45% even under relaxed equivalence criteria, indicating robustness against threshold variations. For oracle coverage, we have expanded Section 3.2 to clarify that each oracle is the complete, human-written reference CLI tool from the original repository; by construction, this provides full behavioral coverage of the intended functionality and side effects for the specified natural language intent, with differential testing directly exercising these behaviors. Regarding inter-annotator agreement for oracle construction, this was not applicable as oracles were implemented directly from the repositories' documented specifications by the authors without subjective multi-annotator interpretation; we have added a detailed description of the oracle creation process, including verification steps against repository documentation and execution logs, to address potential concerns about fidelity and environment variance. These revisions mitigate the identified risks without altering the core findings. revision: partial
Circularity Check
No circularity: empirical benchmark evaluation with external oracles
full rationale
The paper introduces CLI-Tool-Bench as a new benchmark consisting of 100 real-world repositories and evaluates seven LLMs by generating CLI tools, executing them in sandboxes, and scoring outputs/side-effects against human-written oracles via multi-tiered metrics. All reported results (e.g., top models <43% success) are direct empirical measurements from this external test harness. No equations, fitted parameters, self-citations, or ansatzes are used to derive the headline claims; the success rates are not predictions or renamings but observed pass/fail counts. This is a standard evaluation paper whose central claims rest on the benchmark construction and execution, not on any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human-written repositories in the benchmark serve as correct and representative oracles for behavioral equivalence.
- domain assumption The multi-tiered equivalence metrics reliably detect functional correctness without missing important behavioral differences.
Forward citations
Cited by 1 Pith paper
-
The Productivity-Reliability Paradox: Specification-Driven Governance for AI-Augmented Software Development
The Productivity-Reliability Paradox arises because AI code generators produce variable output while developers lack sufficient specification discipline, making governance models focused on specifications the binding ...
Reference graph
Works this paper leans on
-
[1]
Chetan Arora, John Grundy, and Mohamed Abdelrazek. 2024. Advancing re- quirements engineering through generative ai: Assessing the role of llms. In Generative AI for Effective Software Development. Springer, 129–148
2024
-
[2]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models.CoRR abs/2108.07732 (2021). arXiv:2108.07732 https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. Repairagent: An autonomous, llm-based agent for program repair. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2188–2200
2025
-
[4]
Dong Chen, Shaoxin Lin, Muhan Zeng, Daoguang Zan, Jian-Gang Wang, Anton Cheshkov, Jun Sun, Hao Yu, Guoliang Dong, Artem Aliev, Jie Wang, Xiao Cheng, Guangtai Liang, Yuchi Ma, Pan Bian, Tao Xie, and Qianxiang Wang. 2024. CodeR: Issue Resolving with Multi-Agent and Task Graphs.CoRRabs/2406.01304 (2024). arXiv:2406.01304 doi:10.48550/ARXIV.2406.01304
-
[5]
Liguo Chen, Qi Guo, Hongrui Jia, Zhengran Zeng, Xin Wang, Yijiang Xu, Jian Wu, Yidong Wang, Qing Gao, Jindong Wang, Wei Ye, and Shikun Zhang. 2024. A Survey on Evaluating Large Language Models in Code Generation Tasks.CoRR abs/2408.16498 (2024). arXiv:2408.16498 doi:10.48550/ARXIV.2408.16498
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Jingzhe Ding, Shengda Long, Changxin Pu, Huan Zhou, Hongwan Gao, Xi- ang Gao, Chao He, Yue Hou, Fei Hu, Zhaojian Li, Weiran Shi, Zaiyuan Wang, Daoguang Zan, Chenchen Zhang, Xiaoxu Zhang, Qizhi Chen, Xianfu Cheng, Bo Deng, Qingshui Gu, Kai Hua, Juntao Lin, Pai Liu, Mingchen Li, Xuanguang Pan, Zifan Peng, Yujia Qin, Yong Shan, Zhewen Tan, Weihao Xie, Zihan ...
-
[8]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al . 2024. A survey on llm-as-a-judge.The Innovation(2024)
2024
-
[9]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In The Twelfth International Conference on Learning Representatio...
2024
-
[10]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. Live- CodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. InThe Thirteenth International Conference on Learning Rep- resentations, ICLR 2025, Singapore, April 24-28, 2025. OpenRevie...
2025
-
[11]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation.CoRRabs/2406.00515 (2024). arXiv:2406.00515 doi:10.48550/ARXIV.2406.00515
work page internal anchor Pith review doi:10.48550/arxiv.2406.00515 2024
-
[12]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=VTF8yNQM66
2024
-
[13]
Wen Li, Austin Marino, Haoran Yang, Na Meng, Li Li, and Haipeng Cai. 2024. How are multilingual systems constructed: Characterizing language use and selection in open-source multilingual software.ACM Transactions on Software Engineering and Methodology33, 3 (2024), 1–46
2024
- [14]
-
[15]
Stephane H Maes. 2025. The gotchas of ai coding and vibe coding. it’s all about support and maintenance.OSF Preprints(2025)
2025
-
[16]
Zhenyy Mao, Jialong Li, Dongming Jin, Munan Li, and Kenji Tei. 2024. Multi-role consensus through llms discussions for vulnerability detection. In2024 IEEE 24th International Conference on Software Quality, Reliability, and Security Companion (QRS-C). IEEE, 1318–1319
2024
-
[17]
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al
-
[18]
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868(2026)
work page internal anchor Pith review arXiv 2026
-
[19]
Christian Meske, Tobias Hermanns, Esther Von der Weiden, Kai-Uwe Loser, and Thorsten Berger. 2025. Vibe coding as a reconfiguration of intent mediation in software development: Definition, implications, and research agenda.IEEE Access13 (2025), 213242–213259
2025
-
[20]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. ChatDev: Communicative Agents for Software Development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangk...
-
[21]
Shuofei Qiao, Ningyu Zhang, Runnan Fang, Yujie Luo, Wangchunshu Zhou, Yuchen Eleanor Jiang, Chengfei Lv, and Huajun Chen. 2024. AutoAct: Automatic Agent Learning from Scratch for QA via Self-Planning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16...
2024
-
[22]
Partha Pratim Ray. 2025. A review on vibe coding: Fundamentals, state-of-the-art, challenges and future directions.Authorea Preprints(2025)
2025
-
[23]
SWE-Agent. [n. d.]. The 100 line AI agent that solves GitHub issues or helps you in your command line. https://github.com/SWE-agent
-
[24]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, and et al. 2025. OpenHands: An Open Platform for AI Software Developers as Generalist Agents....
2025
-
[25]
Zefan Wang, Zichuan Liu, Yingying Zhang, Aoxiao Zhong, Jihong Wang, Fengbin Yin, Lunting Fan, Lingfei Wu, and Qingsong Wen. 2024. Rcagent: Cloud root cause analysis by autonomous agents with tool-augmented large language models. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 4966–4974
2024
-
[26]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu
-
[27]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub...
2024
-
[28]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Inter- faces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, Dece...
2024
-
[29]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, Maria Christakis and Michael Pradel (Eds.). ACM, 1592–1604. doi:10.1145/3650212.3680384
-
[30]
Terry Yue Zhuo, Minh Chien Vu, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen Gong, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen- Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, and et al. 2025. BigCodeBench: Benchmarking Code Generation with Diverse F...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.