Recognition: no theorem link
VASR: Variance-Aware Systematic Resampling for Reward-Guided Diffusion
Pith reviewed 2026-05-13 01:04 UTC · model grok-4.3
The pith
A variance-decomposition framework for SMC resampling prevents lineage collapse in reward-guided diffusion by using optimal mass allocation and systematic steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
High offspring-count variance under multinomial resampling drives lineage collapse in reward-guided diffusion SMC; separating continuation variance V_t^cont from residual variance V_t^res reveals that variance-optimal mass allocation m_t proportional to w_t e^{r_t} minimizes the first term while systematic resampling controls the second, and the biased VASR-Max variant handles noisy rewards in latent diffusion models.
What carries the argument
The variance-decomposition into continuation variance V_t^cont and residual variance V_t^res, together with mass allocation m_t ∝ w_t e^{r_t} followed by systematic resampling.
If this is right
- On MNIST and CIFAR-10, VASR reaches up to 26% better FID than prior SMC methods at matched compute.
- VASR runs approximately 66 times faster than MCTS-based value methods while matching their compute budget.
- On text-to-image generation, VASR-Max outperforms the strongest SMC baseline across compute budgets.
- VASR-Max reaches within 2.5-3% of MCTS reward scores at high budgets while remaining substantially faster.
Where Pith is reading between the lines
- The same variance split could be tested in non-diffusion sequential samplers such as particle filters for time-series data.
- VASR-Max bias might be tuned further for tasks where reward noise scales with model size.
- The linear overhead suggests the method could scale to video or 3D diffusion without extra training.
- Pairing the mass allocation with existing low-variance estimators from statistics might compound the gains.
Load-bearing premise
That separating continuation variance from residual variance correctly identifies the main cause of lineage collapse and that allocating mass proportional to weights times exponential rewards optimally minimizes continuation variance under the given reward guidance.
What would settle it
Measure particle diversity or effective sample size over multiple resampling steps with and without VASR on the same diffusion trajectory; if diversity still drops at the same rate or final FID shows no improvement, the variance-minimization claim does not hold.
Figures








read the original abstract
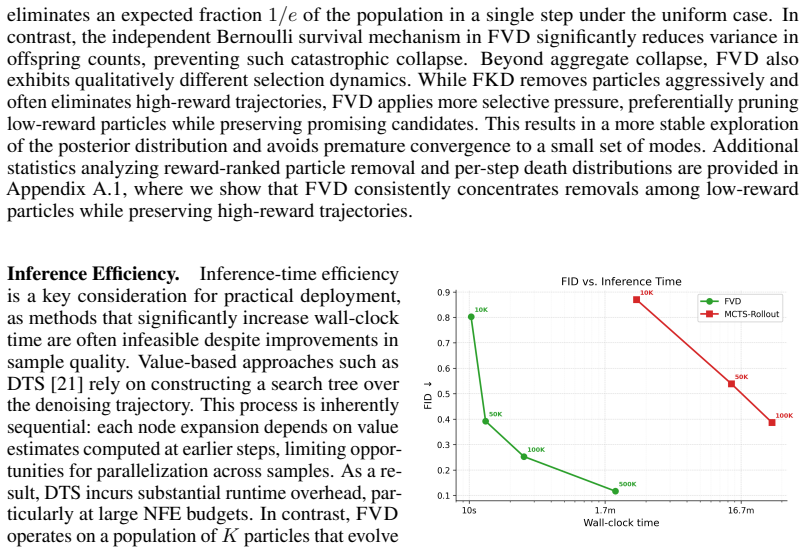
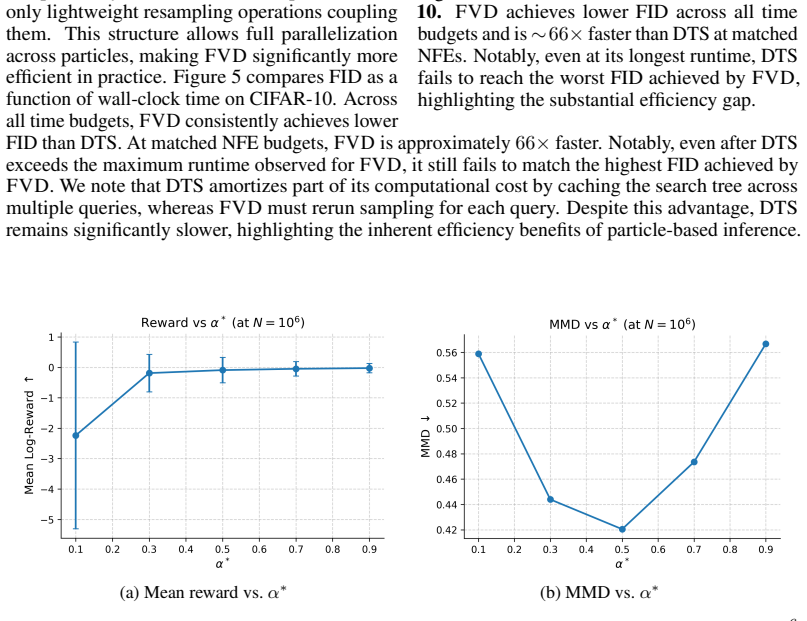
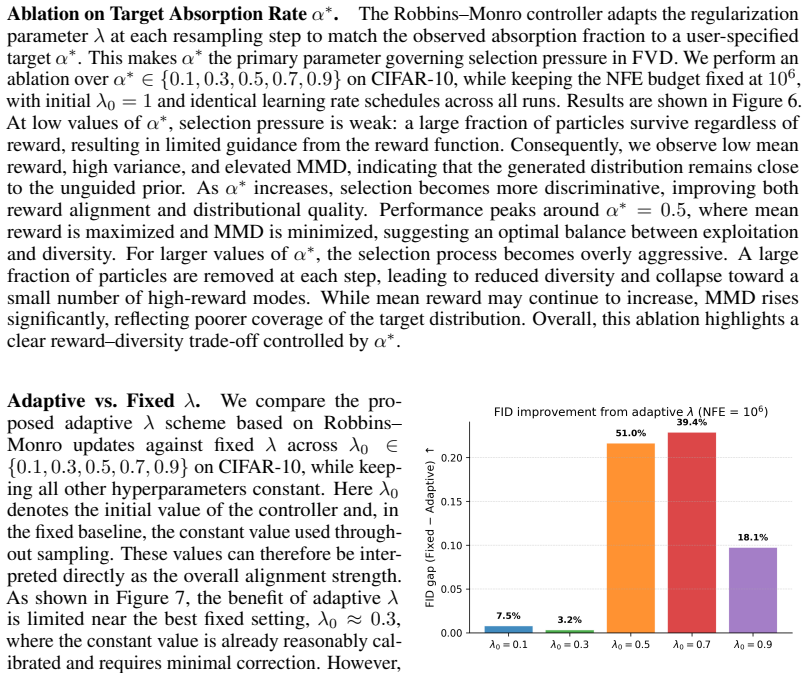
Sequential Monte Carlo (SMC) samplers for reward-guided diffusion models often suffer from rapid lineage collapse: a few high-reward particles dominate the population within a handful of resampling steps, destroying diversity and degrading sample quality. We propose a variance-decomposition framework for reward-guided diffusion SMC that separates continuation variance $V_t^{\mathrm{cont}}$ from residual variance $V_t^{\mathrm{res}}$, revealing that high offspring-count variance under the commonly used multinomial resampling drives this collapse. This motivates \textsc{VASR} (Variance-Aware Systematic Resampling), which addresses both variance terms via variance-optimal mass allocation $m_t \propto w_t e^{r_t}$ (minimizing $V_t^{\mathrm{cont}}$) and systematic resampling (controlling $V_t^{\mathrm{res}}$). For latent diffusion models where intermediate rewards are noisy due to stochastic continuations, we propose \textsc{VASR-Max}, a deliberately biased high-selection variant for variance-sensitive reward optimization. Both methods are training-free, fully parallelizable, and add only linear overhead. On MNIST and CIFAR-10, VASR achieves as high as $26\%$ better FID than prior SMC methods while remaining 66 times faster than MCTS-based value methods at matched compute. On text-to-image generation, \textsc{VASR-Max} consistently outperforms the strongest SMC baseline across compute budgets and matches MCTS-based methods within 2.5--3% reward at high budgets while being approximately times faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard multinomial resampling in SMC for reward-guided diffusion causes rapid lineage collapse due to high offspring-count variance. It introduces a variance decomposition V_t = V_t^cont + V_t^res, derives a mass allocation m_t ∝ w_t e^{r_t} claimed to minimize the continuation term, and pairs it with systematic resampling to control the residual term. This yields the training-free VASR algorithm and a biased VASR-Max variant for noisy intermediate rewards. Empirical claims include up to 26% FID improvement over prior SMC on MNIST/CIFAR-10, 66x speedup versus MCTS at matched compute, and competitive reward matching on text-to-image tasks with substantial speed gains.
Significance. If the variance decomposition is correctly minimized by the stated allocation and the empirical gains are reproducible with proper controls, the work would offer a lightweight, parallelizable improvement to SMC sampling for reward-guided diffusion that directly targets lineage collapse without retraining. The training-free property and linear overhead are practical strengths that could see adoption in latent diffusion pipelines.
major comments (3)
- [Variance-decomposition framework (around the definition of V_t^cont and the mass-allocation rule)] The central claim that m_t ∝ w_t e^{r_t} is variance-optimal for minimizing V_t^cont rests on an unverified substitution of the diffusion transition kernel and noisy reward into the continuation variance expression. No explicit critical-point calculation or convexity argument is supplied to confirm that this proportionality attains the minimum (or even a local minimum) rather than requiring additional boundedness conditions on r_t. This step is load-bearing for the motivation of VASR over multinomial resampling.
- [Experimental results on MNIST, CIFAR-10 and text-to-image] Table or results section reporting MNIST/CIFAR-10 FID: the 26% improvement is stated without error bars, number of independent runs, or ablation isolating the contribution of the variance-optimal allocation versus systematic resampling alone. At matched compute, the comparison to MCTS-based value methods also lacks protocol details (particle count N, exact diffusion schedule, reward model), preventing attribution of gains to the claimed mechanism.
- [VASR-Max variant description and text-to-image experiments] For VASR-Max, the deliberate bias introduced for variance-sensitive optimization is described but not accompanied by a quantitative bound on the introduced bias or a demonstration that the bias-variance trade-off improves reward optimization under the noisy-reward regime. This is central to the claim that VASR-Max matches MCTS reward within 2.5–3% at high budgets.
minor comments (3)
- [Abstract] Abstract contains the incomplete phrase 'being approximately times faster'; the numerical factor is missing.
- [Method overview] Notation for continuation variance V_t^cont and residual variance V_t^res is introduced without an early equation block that defines them in terms of the offspring counts and the diffusion kernel.
- [Experiments] Reproducibility would benefit from an explicit statement of the number of particles, diffusion timesteps, and reward-function implementation details in the main experimental section rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will incorporate revisions to strengthen the variance derivation, experimental reporting, and analysis of VASR-Max.
read point-by-point responses
-
Referee: [Variance-decomposition framework (around the definition of V_t^cont and the mass-allocation rule)] The central claim that m_t ∝ w_t e^{r_t} is variance-optimal for minimizing V_t^cont rests on an unverified substitution of the diffusion transition kernel and noisy reward into the continuation variance expression. No explicit critical-point calculation or convexity argument is supplied to confirm that this proportionality attains the minimum (or even a local minimum) rather than requiring additional boundedness conditions on r_t. This step is load-bearing for the motivation of VASR over multinomial resampling.
Authors: We agree that an explicit derivation would improve clarity. In the revision we will add a step-by-step critical-point calculation of the continuation variance V_t^cont under the diffusion transition kernel and reward model, together with a convexity argument and the precise boundedness conditions required on r_t. This will rigorously establish that m_t ∝ w_t e^{r_t} attains the minimum. revision: yes
-
Referee: [Experimental results on MNIST, CIFAR-10 and text-to-image] Table or results section reporting MNIST/CIFAR-10 FID: the 26% improvement is stated without error bars, number of independent runs, or ablation isolating the contribution of the variance-optimal allocation versus systematic resampling alone. At matched compute, the comparison to MCTS-based value methods also lacks protocol details (particle count N, exact diffusion schedule, reward model), preventing attribution of gains to the claimed mechanism.
Authors: We will revise the experimental section to report FID results with error bars from at least five independent random seeds, include ablations that isolate the mass-allocation rule from systematic resampling, and supply full protocol details for all MCTS baselines (particle count N, diffusion schedule, reward model architecture and compute budget). These additions will enable clear attribution of the reported gains. revision: yes
-
Referee: [VASR-Max variant description and text-to-image experiments] For VASR-Max, the deliberate bias introduced for variance-sensitive optimization is described but not accompanied by a quantitative bound on the introduced bias or a demonstration that the bias-variance trade-off improves reward optimization under the noisy-reward regime. This is central to the claim that VASR-Max matches MCTS reward within 2.5–3% at high budgets.
Authors: We will augment the VASR-Max section with additional experiments that quantify the bias-variance trade-off across a range of bias parameters and noisy-reward settings, showing improved reward optimization relative to unbiased baselines. While a closed-form theoretical bound on the bias is difficult to obtain in the general noisy-reward case, the empirical results will substantiate the practical utility of the deliberate bias at high compute budgets. revision: partial
Circularity Check
No circularity; variance decomposition and mass allocation derived independently from first principles
full rationale
The paper introduces a variance decomposition V_t = V_t^cont + V_t^res for reward-guided SMC, then proposes m_t ∝ w_t e^{r_t} as the allocation that minimizes the continuation term and pairs it with systematic resampling to control residual variance. No step reduces a claimed result to a fitted parameter, self-citation, or input by construction; the optimality claim is presented as following from the decomposition rather than presupposing the algorithm. The method is training-free and the reported gains are empirical comparisons against baselines, not internal predictions. This is a standard non-circular derivation of a new resampling rule from an explicit variance model.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reward-guided SMC variance decomposes cleanly into continuation variance V_t^cont and residual variance V_t^res
- domain assumption High offspring-count variance under multinomial resampling is the main cause of rapid lineage collapse
invented entities (2)
-
VASR
no independent evidence
-
VASR-Max
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020. URLhttps://arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution, 2020. URLhttps://arxiv.org/abs/1907.05600
-
[3]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. URLhttps://arxiv.org/abs/2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models, 2022. URL https://arxiv.org/ abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer, 2025. URLhttps://arxiv.org/abs/2408.06072
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Google DeepMind. Veo 3. https://aistudio.google.com/models/veo-3, 2025. Ac- cessed: 2026-03-15
work page 2025
-
[7]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
work page internal anchor Pith review arXiv 2025
-
[8]
Chiu, Alexander Rush, and Volodymyr Kuleshov
Subham Sekhar Sahoo, Marianne Arriola, Yair Schiff, Aaron Gokaslan, Edgar Marroquin, Justin T Chiu, Alexander Rush, and V olodymyr Kuleshov. Simple and effective masked diffusion language models, 2024. URLhttps://arxiv.org/abs/2406.07524
-
[9]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning, 2024. URLhttps://arxiv.org/abs/2305.13301
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models, 2023. URL https://arxiv.org/abs/2305. 16381
work page 2023
-
[11]
Using human feedback to fine-tune diffusion models without any reward model, 2024
Kai Yang, Jian Tao, Jiafei Lyu, Chunjiang Ge, Jiaxin Chen, Qimai Li, Weihan Shen, Xiaolong Zhu, and Xiu Li. Using human feedback to fine-tune diffusion models without any reward model, 2024. URLhttps://arxiv.org/abs/2311.13231
-
[12]
Diffusion model alignment using direct preference optimization, 2023
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization, 2023. URLhttps://arxiv.org/abs/2311.12908
-
[13]
Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards, 2024. URLhttps://arxiv.org/abs/2309.17400
-
[14]
Universal guidance for diffusion models, 2023
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models, 2023. URL https://arxiv.org/abs/2302.07121
-
[15]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T. Mccann, Marc L. Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems, 2024. URL https://arxiv. org/abs/2209.14687. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Monte carlo guided diffusion for bayesian linear inverse problems, 2023
Gabriel Cardoso, Yazid Janati El Idrissi, Sylvain Le Corff, and Eric Moulines. Monte carlo guided diffusion for bayesian linear inverse problems, 2023. URL https://arxiv.org/abs/ 2308.07983
-
[17]
Diffusion posterior sampling for linear inverse problem solving: A filtering perspective
Zehao Dou and Yang Song. Diffusion posterior sampling for linear inverse problem solving: A filtering perspective. InThe Twelfth International Conference on Learning Representations,
-
[18]
URLhttps://openreview.net/forum?id=tplXNcHZs1
-
[19]
arXiv preprint arXiv:2501.06848 (2025)
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models, 2025. URLhttps://arxiv.org/abs/2501.06848
-
[20]
arXiv preprint arXiv:2408.08252 , year =
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gokcen Eraslan, Surag Nair, Tommaso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, and Masatoshi Uehara. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding, 2024. URLhttps://arxiv.org/abs/2408.08252
-
[21]
Dynamic search for inference-time alignment in diffusion models, 2025
Xiner Li, Masatoshi Uehara, Xingyu Su, Gabriele Scalia, Tommaso Biancalani, Aviv Regev, Sergey Levine, and Shuiwang Ji. Dynamic search for inference-time alignment in diffusion models, 2025. URLhttps://arxiv.org/abs/2503.02039
-
[22]
Diffusion tree sampling: Scalable inference-time alignment of diffusion models, 2025
Vineet Jain, Kusha Sareen, Mohammad Pedramfar, and Siamak Ravanbakhsh. Diffusion tree sampling: Scalable inference-time alignment of diffusion models, 2025. URL https: //arxiv.org/abs/2506.20701
-
[23]
Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J. Zico Kolter, Ruslan Salakhutdinov, and Stefano Ermon. Manifold preserving guided diffusion, 2023. URLhttps://arxiv.org/abs/2311.16424
-
[24]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv.org/abs/2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis, 2021. URL https://arxiv.org/abs/2105.05233
work page internal anchor Pith review arXiv 2021
-
[26]
Pseudoinverse-guided diffusion models for inverse problems
Jiaming Song, Arash Vahdat, Morteza Mardani, and Jan Kautz. Pseudoinverse-guided diffusion models for inverse problems. InInternational Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=9_gsMA8MRKQ
work page 2023
-
[27]
Practi- cal and asymptotically exact conditional sampling in diffusion models
Luhuan Wu, Brian Trippe, Christian Naesseth, David Blei, and John P Cunningham. Practi- cal and asymptotically exact conditional sampling in diffusion models. In A. Oh, T. Nau- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 31372–31403. Curran Associates, Inc., 2023. UR...
work page 2023
-
[28]
Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi Jaakkola
Brian L. Trippe, Jason Yim, Doug Tischer, David Baker, Tamara Broderick, Regina Barzilay, and Tommi Jaakkola. Diffusion probabilistic modeling of protein backbones in 3d for the motif-scaffolding problem, 2023. URLhttps://arxiv.org/abs/2206.04119
-
[29]
Pierre Del Moral.Feynman-Kac Formulae: Genealogical and Interacting Particle Systems With Applications, volume 100. 05 2004. ISBN 0387202684. doi: 10.1007/978-1-4684-9393-1
-
[30]
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, and Saining Xie. Inference-time scaling for diffusion models beyond scaling denoising steps, 2025. URL https://arxiv.org/abs/2501.09732
-
[31]
Vfscale: Intrinsic reasoning through verifier- free test-time scalable diffusion model, 2026
Tao Zhang, Jia-Shu Pan, Ruiqi Feng, and Tailin Wu. Vfscale: Intrinsic reasoning through verifier- free test-time scalable diffusion model, 2026. URLhttps://arxiv.org/abs/2502.01989
-
[32]
Controllable graph generation with diffusion models via inference-time tree search guidance, 2026
Jiachi Zhao, Zehong Wang, Yamei Liao, Chuxu Zhang, and Yanfang Ye. Controllable graph generation with diffusion models via inference-time tree search guidance, 2026. URL https: //arxiv.org/abs/2510.10402. 13
-
[33]
Diffusion language model inference with monte carlo tree search, 2026
Zheng Huang, Kiran Ramnath, Yueyan Chen, Aosong Feng, Sangmin Woo, Balasubramaniam Srinivasan, Zhichao Xu, Kang Zhou, Shuai Wang, Haibo Ding, and Lin Lee Cheong. Diffusion language model inference with monte carlo tree search, 2026. URL https://arxiv.org/ abs/2512.12168
-
[34]
Monte carlo tree diffusion for system 2 planning, 2026
Jaesik Yoon, Hyeonseo Cho, Doojin Baek, Yoshua Bengio, and Sungjin Ahn. Monte carlo tree diffusion for system 2 planning, 2026. URLhttps://arxiv.org/abs/2502.07202
-
[35]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models, 2022. URLhttps://arxiv.org/abs/2010.02502
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
S. N. Ethier and Thomas G. Kurtz. Fleming–viot processes in population genetics.SIAM Journal on Control and Optimization, 31(2):345–386, 1993. doi: 10.1137/0331019. URL https://doi.org/10.1137/0331019
-
[37]
Fleming-viot processes : two explicit examples, 2016
Bertrand Cloez and Marie-Noémie Thai. Fleming-viot processes : two explicit examples, 2016. URLhttps://arxiv.org/abs/1603.04670
-
[38]
Robbins-Monro Algorithm, pages 1–24. Springer US, Boston, MA, 2002. ISBN 978- 0-306-48166-6. doi: 10.1007/0-306-48166-9_1. URL https://doi.org/10.1007/ 0-306-48166-9_1
-
[39]
Test-time alignment of diffusion models without reward over-optimization, 2025
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization, 2025. URLhttps://arxiv.org/abs/2501.05803
-
[40]
See-dpo: Self entropy enhanced direct preference optimization, 2025
Shivanshu Shekhar, Shreyas Singh, and Tong Zhang. See-dpo: Self entropy enhanced direct preference optimization, 2025. URLhttps://arxiv.org/abs/2411.04712
-
[41]
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in Neural Information Processing Systems, 35:36479–36494, 2022
work page 2022
-
[42]
Imagereward: Learning and evaluating human preferences for text-to-image generation,
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation,
- [43]
-
[44]
Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau
Zijie J. Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. Large-scale prompt gallery dataset for text-to-image generative models. arXiv:2210.14896 [cs], 2022. URLhttps://arxiv.org/abs/2210.14896. 14 A Additional Experiments Figure 8:Qualitative comparison on aesthetic optimization.Samples from each method for a 50K ...
-
[45]
the number of particles satisfiesK→ ∞
-
[46]
the dependencies induced by the birth–death interaction become negligible in the large-K limit, as predicted by the usual mean-field / propagation-of-chaos theory for interacting particle systems [28, 35]. Then the empirical measure of particles produced byFVDshould converge to a reward-tilted distribution of the form π∗ t (xt:T )∝p θ(xt:T ) T−1Y s=t Gs(x...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.