Recognition: no theorem link
MedDialBench: Benchmarking LLM Diagnostic Robustness under Parametric Adversarial Patient Behaviors
Pith reviewed 2026-05-10 18:44 UTC · model grok-4.3
The pith
Fabricating symptoms causes 1.7-3.4 times larger accuracy drops in LLM medical diagnosis than withholding information, and alone triggers super-additive interaction effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
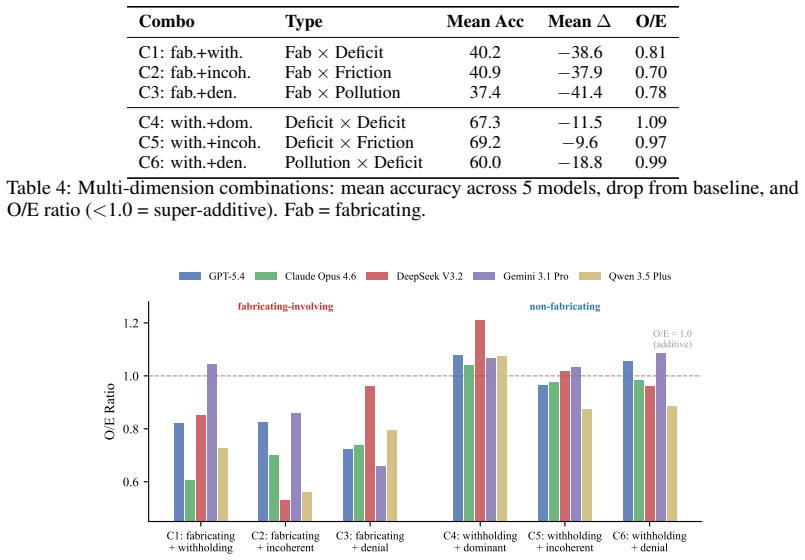
The benchmark decomposes patient non-cooperation into five dimensions—Logic Consistency, Health Cognition, Expression Style, Disclosure, and Attitude—each equipped with graded severity levels and case-specific behavioral scripts. In 7,225 dialogues across five frontier LLMs, information pollution through fabricating symptoms produces 1.7-3.4x larger accuracy drops than information deficit through withholding, with fabricating the only configuration reaching statistical significance in all models. Fabricating is the sole driver of super-additive interactions in dimension pairs, while inquiry strategies moderate deficit effects but cannot offset pollution.
What carries the argument
MedDialBench's five-dimension factorial design with graded severity levels and case-specific behavioral scripts, which supports dose-response profiling and cross-dimension interaction measurement in medical dialogues.
If this is right
- Inquiry strategies recover performance from withheld information but provide no compensation for fabricated symptoms.
- Super-additive accuracy losses appear only in behavior combinations that include fabrication, producing O/E ratios of 0.70-0.81.
- Each model shows a distinct vulnerability profile, with worst-case accuracy drops ranging from 38.8 to 54.1 percentage points.
- Fabrication is the only patient behavior that reaches statistical significance for accuracy drops across all five tested models.
Where Pith is reading between the lines
- Medical LLMs may benefit from explicit training on detecting and discounting invented symptoms rather than relying only on follow-up questions.
- The observed asymmetry implies that data augmentation focused on fabricated symptom examples could yield larger robustness gains than efforts targeting incomplete patient histories.
- Similar parametric decomposition of user behaviors could be applied to other high-stakes dialogue domains to test for parallel fabrication-driven vulnerabilities.
Load-bearing premise
The five patient behavior dimensions and their scripted severity levels accurately represent the range of real-world non-cooperative behaviors that occur in actual medical consultations.
What would settle it
A direct comparison of LLM accuracy drops in the scripted benchmark dialogues versus real recorded medical conversations with non-cooperative patients, checking whether the 1.7-3.4x asymmetry and super-additive pattern for fabrication hold in magnitude and direction.
Figures



read the original abstract
Interactive medical dialogue benchmarks have shown that LLM diagnostic accuracy degrades significantly when interacting with non-cooperative patients, yet existing approaches either apply adversarial behaviors without graded severity or case-specific grounding, or reduce patient non-cooperation to a single ungraded axis, and none analyze cross-dimension interactions. We introduce MedDialBench, a benchmark enabling controlled, dose-response characterization of how individual patient behavior dimensions affect LLM diagnostic robustness. It decomposes patient behavior into five dimensions -- Logic Consistency, Health Cognition, Expression Style, Disclosure, and Attitude -- each with graded severity levels and case-specific behavioral scripts. This controlled factorial design enables graded sensitivity analysis, dose-response profiling, and cross-dimension interaction detection. Evaluating five frontier LLMs across 7,225 dialogues (85 cases x 17 configurations x 5 models), we find a fundamental asymmetry: information pollution (fabricating symptoms) produces 1.7-3.4x larger accuracy drops than information deficit (withholding information), and fabricating is the only configuration achieving statistical significance across all five models (McNemar p < 0.05). Among six dimension combinations, fabricating is the sole driver of super-additive interaction: all three fabricating-involving pairs produce O/E ratios of 0.70-0.81 (35-44% of eligible cases fail under the combination despite succeeding under each dimension alone), while all non-fabricating pairs show purely additive effects (O/E ~ 1.0). Inquiry strategy moderates deficit but not pollution: exhaustive questioning recovers withheld information, but cannot compensate for fabricated inputs. Models exhibit distinct vulnerability profiles, with worst-case drops ranging from 38.8 to 54.1 percentage points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedDialBench, a benchmark for evaluating LLM diagnostic robustness in interactive medical dialogues under non-cooperative patient behaviors. It decomposes behaviors into five dimensions (Logic Consistency, Health Cognition, Expression Style, Disclosure, Attitude) each with graded severity levels and case-specific scripts, enabling a factorial design. Across 85 cases, 17 configurations, and five frontier LLMs (7,225 total dialogues), it claims information pollution (fabricating symptoms) causes 1.7-3.4x larger accuracy drops than information deficit (withholding), is the only configuration statistically significant across all models (McNemar p<0.05), drives all super-additive interactions (O/E 0.70-0.81 for fabricating pairs vs. additive for others), and that inquiry strategies mitigate deficit but not pollution effects.
Significance. If the simulation holds, the work offers a controlled, scalable framework for quantifying LLM vulnerabilities in medical dialogues, highlighting a key asymmetry favoring robustness to fabrication over deficit and identifying super-additive risks. The large-scale factorial evaluation, dose-response profiling, and interaction metrics (O/E ratios) provide actionable insights for model development and prompting strategies. Strengths include the explicit statistical testing and model-specific vulnerability profiles, which could inform safer deployment in clinical settings.
major comments (3)
- [Methods (patient simulation)] Methods (patient simulation subsection): The headline asymmetry (1.7-3.4x drops) and super-additivity claims rest entirely on the LLM-generated case-specific scripts faithfully modeling real patient fabrication without introducing detectable artifacts (e.g., inconsistent symptom clusters or unnatural phrasing) that real patients rarely produce. No validation against human dialogues or expert ratings is described; if fabrication scripts are systematically more detectable or incoherent, this directly confounds the differential robustness and O/E findings.
- [Results (interaction analysis)] Results (interaction analysis): The O/E ratios of 0.70-0.81 are reported only for the three fabricating-involving pairs, with 35-44% of eligible cases failing the combination despite succeeding on each alone. The exact definition of 'expected' (additive baseline) and how 'eligible cases' are selected must be specified, as any correlation between dimensions or case-specific script quality could artifactually produce the reported super-additivity.
- [Results (statistical tests)] Results (statistical tests): McNemar tests are claimed to reach p<0.05 for fabricating across all five models, but with 85 cases and 17 configurations the paper should report whether multiple-comparison correction was applied and confirm per-model sample sizes/power, as uncorrected tests across many pairwise comparisons could inflate the 'only fabricating achieves significance' claim.
minor comments (2)
- [Abstract] Abstract: The phrase 'dose-response profiling' is introduced without a one-sentence definition or example; adding this would improve immediate clarity for readers unfamiliar with the design.
- [Abstract] The 17 configurations are mentioned but not enumerated or diagrammed in the abstract; a brief parenthetical (e.g., 'including single-dimension, pairwise, and triple combinations') would help readers parse the factorial scope.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond point-by-point to the major concerns, providing clarifications on our methods and analysis while committing to revisions that address the raised issues without misrepresenting the current manuscript.
read point-by-point responses
-
Referee: Methods (patient simulation): The headline asymmetry (1.7-3.4x drops) and super-additivity claims rest entirely on the LLM-generated case-specific scripts faithfully modeling real patient fabrication without introducing detectable artifacts (e.g., inconsistent symptom clusters or unnatural phrasing) that real patients rarely produce. No validation against human dialogues or expert ratings is described; if fabrication scripts are systematically more detectable or incoherent, this directly confounds the differential robustness and O/E findings.
Authors: We acknowledge that the manuscript does not describe explicit validation of the generated scripts against real human patient dialogues or expert ratings. Scripts were produced via structured prompts grounded in clinical case details and medical guidelines to ensure behavioral fidelity and minimize artifacts. However, this leaves open the possibility of systematic differences in detectability. In revision we will expand the Methods section with the full generation protocol and add results from a new pilot expert rating study (n=20 scripts per dimension) assessing coherence, naturalness, and medical plausibility. We maintain that the consistent asymmetry across five models and the factorial isolation of effects provide supporting evidence, but agree human validation will strengthen the claims. revision: yes
-
Referee: Results (interaction analysis): The O/E ratios of 0.70-0.81 are reported only for the three fabricating-involving pairs, with 35-44% of eligible cases failing the combination despite succeeding on each alone. The exact definition of 'expected' (additive baseline) and how 'eligible cases' are selected must be specified, as any correlation between dimensions or case-specific script quality could artifactually produce the reported super-additivity.
Authors: We will revise the Results section to define 'expected' under additivity explicitly as the product of the individual-dimension success rates (assuming independence) and to specify that eligible cases are those in which the model succeeded on both singleton configurations but failed on the paired configuration. We will also report inter-dimension correlations and an auxiliary analysis showing that case-level script quality metrics do not predict the observed super-additivity pattern. The fact that only fabricating-involving pairs exhibit O/E < 1.0, while all other pairs are additive, and that this holds uniformly across models, argues against a pure artifact from correlations or script quality. revision: yes
-
Referee: Results (statistical tests): McNemar tests are claimed to reach p<0.05 for fabricating across all five models, but with 85 cases and 17 configurations the paper should report whether multiple-comparison correction was applied and confirm per-model sample sizes/power, as uncorrected tests across many pairwise comparisons could inflate the 'only fabricating achieves significance' claim.
Authors: Each McNemar test used the full set of 85 cases for that specific configuration versus baseline (per-model n=85). We will add explicit power calculations (all >0.80 for observed effect sizes) and report all raw p-values. The 17 configurations were pre-specified rather than exploratory, so no correction was applied; we will nevertheless discuss the multiple-testing issue as a limitation and note that the 'only fabricating reaches significance across all models' pattern remains even under a conservative Bonferroni threshold for the five models. Sample-size and power details will be added to the revised Results and supplementary material. revision: partial
Circularity Check
No circularity: purely empirical benchmark with direct measurements
full rationale
The paper introduces MedDialBench as a controlled factorial benchmark and reports empirical results from 7,225 dialogues (85 cases × 17 configurations × 5 models). All key claims—accuracy drops, 1.7-3.4× asymmetry between fabrication and withholding, McNemar significance, and super-additive O/E ratios—are direct statistical outcomes of running the LLMs on the scripted dialogues. No equations, fitted parameters, predictions, or derivations appear; the design compares configurations on the same cases without reducing any quantity to a self-defined or self-cited input. The study is self-contained against its own experimental data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Patient non-cooperation in medical dialogues can be decomposed into the five independent dimensions of Logic Consistency, Health Cognition, Expression Style, Disclosure, and Attitude
- domain assumption The 85 medical cases and 17 configurations are sufficient to detect general patterns of LLM diagnostic robustness
Reference graph
Works this paper leans on
-
[1]
Bean, Ryan Payne, George Parsons, Hannah Rose Kirk, et al
Andrew M. Bean, Ryan Payne, George Parsons, Hannah Rose Kirk, et al. Clinical knowledge in LLMs does not translate to human interactions.arXiv preprint arXiv:2504.18919,
-
[2]
MedPI: Evaluating AI systems in medical patient-facing interactions.medRxiv preprint 2025.12.24.25342982,
David Fajardo V ., Oleksandr Proniakin, Veronika-Elisabeth Gruber, and Razvan Marinescu. MedPI: Evaluating AI systems in medical patient-facing interactions.medRxiv preprint 2025.12.24.25342982,
2025
-
[3]
Robert Fang et al. MedFuzz: Exploring the robustness of large language models in medical question answering.arXiv preprint arXiv:2406.06573,
-
[4]
Linjie Gong, Ao Wang, Yun Lai, Wei Ma, and Yang Liu. The dialogue that heals: A comprehensive evaluation of doctor agents’ inquiry capability.arXiv preprint arXiv:2509.24958,
-
[5]
arXiv preprint arXiv:2601.03023 , year=
Linjie Gong, Wei Fang, Tao Yang, et al. MedDialogRubrics: A comprehensive benchmark and evaluation framework for multi-turn medical consultations in large language models.arXiv preprint arXiv:2601.03023,
-
[6]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, and Xinghua Lu. PubMedQA: A dataset for biomedical research question answering.arXiv preprint arXiv:1909.06146,
-
[7]
Yahan Li, Xinyi Jie, Wanjia Ruan, Xubei Zhang, Huaijie Zhu, Yicheng Gao, Chaohao Du, and Ruishan Liu. Beyond idealized patients: Evaluating LLMs under challenging patient behaviors in medical consultations.arXiv preprint arXiv:2603.29373,
-
[8]
Capa- bilities of gpt-4 on medical challenge problems
Harsha Nori, Nicholas King, Scott Mayer McKinney, Dean Carignan, and Eric Horvitz. Capabilities of GPT-4 on medical competency examinations.arXiv preprint arXiv:2303.13375,
-
[9]
arXiv preprint arXiv:2404.18416 (2024)
Khaled Saab, Tao Tu, Wei-Hung Weng, et al. Capabilities of Gemini models in medicine.arXiv preprint arXiv:2404.18416,
-
[10]
Agentclinic: a multimodal agent benchmark to evaluate ai in simulated clinical environments
10 Samuel Schmidgall, Rojin Ziaei, Carl Harris, Eduardo Reis, Jeffrey Jopling, and Michael Moor. AgentClinic: A multimodal agent benchmark to evaluate AI in simulated clinical environments. arXiv preprint arXiv:2405.07960,
-
[11]
SycoEval-EM Authors. Sycophancy evaluation of large language models in simulated clinical encounters for emergency care.arXiv preprint arXiv:2601.16529,
-
[12]
Shuai Xu, Ting Zhou, Jie Ma, et al. LingxiDiagBench: A multi-agent framework for benchmarking LLMs in Chinese psychiatric consultation and diagnosis.arXiv preprint arXiv:2602.09379,
-
[13]
Huanzhuo Yu, Jianing Zhou, Lehan Li, Siru Chen, et al. Simulated patient systems powered by large language model-based AI agents offer potential for transforming medical education.arXiv preprint arXiv:2409.18924,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.