Lumbermark: Resistant Clustering by Chopping Up Mutual Reachability Minimum Spanning Trees
Pith reviewed 2026-05-10 18:08 UTC · model grok-4.3
The pith
Lumbermark detects clusters of varying sizes, densities, and shapes by iteratively chopping protruding segments from a mutual reachability minimum spanning tree.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lumbermark is a robust divisive clustering algorithm capable of detecting clusters of varying sizes, densities, and shapes. It works by iteratively chopping off large limbs connected by protruding segments of a dataset's mutual reachability minimum spanning tree. The use of mutual reachability distances smoothens the data distribution and decreases the influence of low-density objects, such as noise points between clusters or outliers at their peripheries. The algorithm produces partitions with user-specified sizes and serves as an alternative to HDBSCAN.
What carries the argument
The mutual reachability minimum spanning tree, which the algorithm repeatedly severs at protruding segments to isolate clusters while reducing the effect of density variations and noise.
If this is right
- The method separates clusters even when they differ substantially in size, density, and shape.
- Low-density noise and peripheral outliers exert reduced influence on the final partition.
- Users obtain direct control over the sizes of the clusters in the output.
- A fast implementation exists that can serve as a drop-in alternative when HDBSCAN output sizes are not controllable.
Where Pith is reading between the lines
- The tree-chopping view may connect to other graph-based clustering techniques that operate on minimum spanning trees.
- The user-specified size control suggests utility in applications where balanced or constrained group sizes are required.
- Benchmark performance indicates the approach could extend to domains with high-dimensional or irregularly shaped data groups.
Load-bearing premise
Mutual reachability distances smooth the data distribution enough for the chopping process to separate clusters accurately despite the presence of noise and outliers.
What would settle it
Running the algorithm on benchmark datasets with known ground-truth partitions and user-specified sizes, then checking whether the recovered clusters match the true structure in cases with added noise bridges or density gradients.
Figures

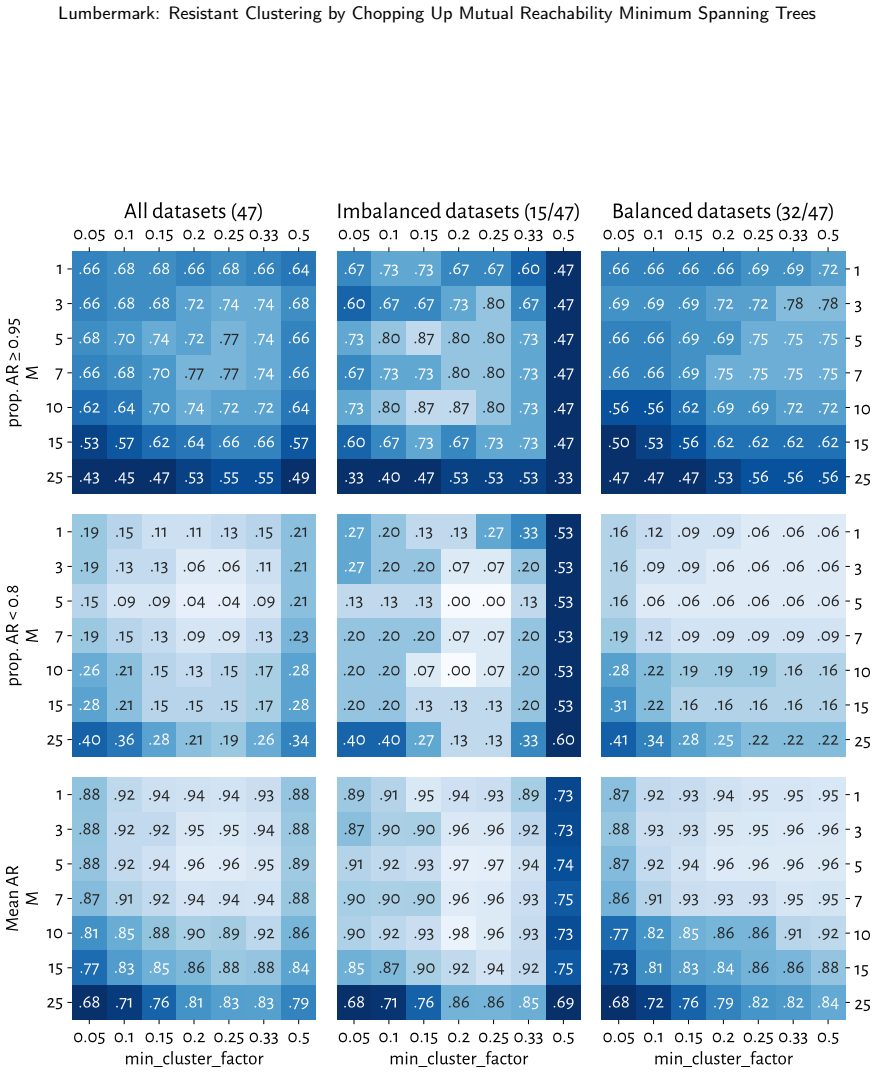
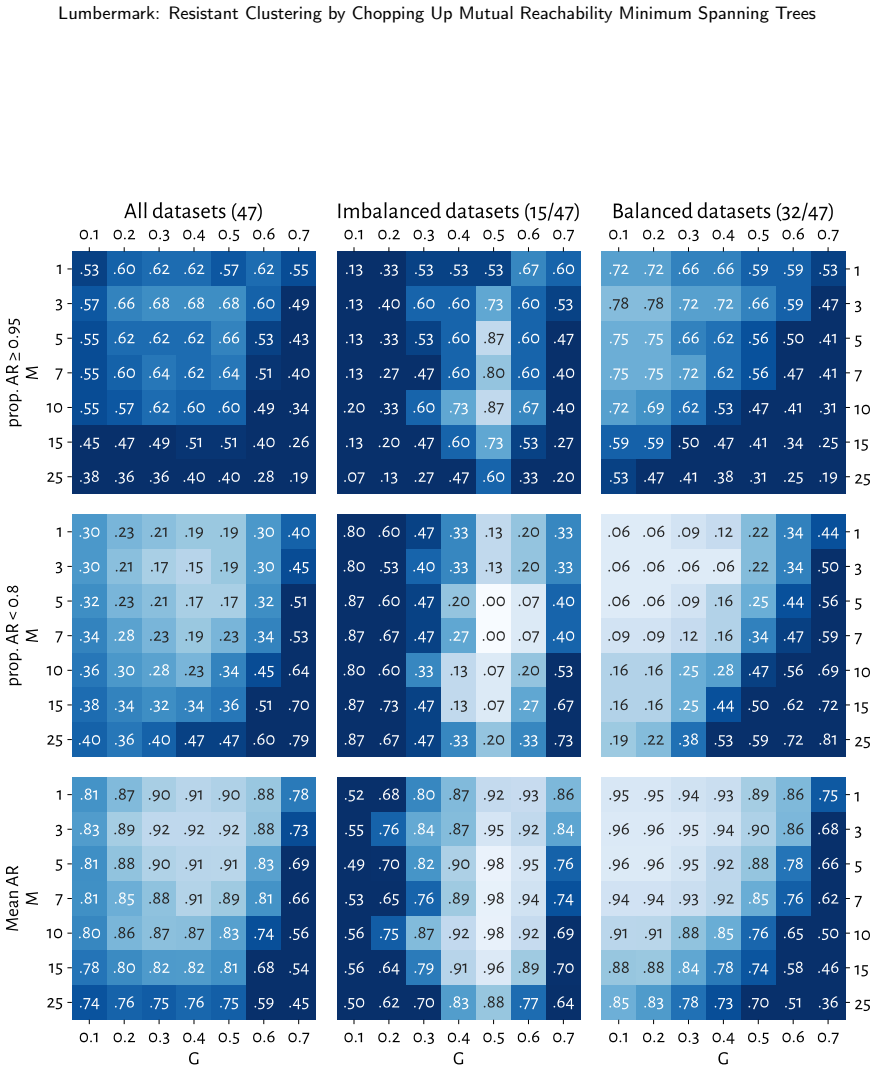
read the original abstract
We introduce Lumbermark, a robust divisive clustering algorithm capable of detecting clusters of varying sizes, densities, and shapes. Lumbermark iteratively chops off large limbs connected by protruding segments of a dataset's mutual reachability minimum spanning tree. The use of mutual reachability distances smoothens the data distribution and decreases the influence of low-density objects, such as noise points between clusters or outliers at their peripheries. The algorithm can be viewed as an alternative to HDBSCAN that produces partitions with user-specified sizes. A fast, easy-to-use implementation of the new method is available in the open-source 'lumbermark' package for Python and R. We show that Lumbermark performs well on benchmark data and hope it will prove useful to data scientists and practitioners across different fields.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Lumbermark, a divisive clustering algorithm that iteratively chops large limbs from the mutual reachability minimum spanning tree (MR-MST) of a dataset to identify clusters of varying sizes, densities, and shapes. It claims that mutual reachability distances smooth the distribution and reduce the effect of noise/outliers, positioning the method as a user-specified-size alternative to HDBSCAN. An open-source Python/R implementation is provided, with claims of good performance on benchmarks.
Significance. If the robustness claims hold, Lumbermark would offer a practical, interpretable alternative for noisy clustering tasks where cluster-size control is desired, extending MST-based ideas from HDBSCAN with a chopping heuristic. The open-source package supports reproducibility and adoption by practitioners.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method description): The central robustness claim—that mutual reachability distances 'smoothens the data distribution and decreases the influence of low-density objects' enabling accurate limb separation—lacks any theoretical analysis, bounds, or controlled failure-mode tests (e.g., for bridge noise, density gradients, or high dimensions), leaving the key assumption unverified despite being load-bearing for the 'resistant' guarantee.
- [§4] §4 (Experiments): Benchmark results are asserted without reported details on datasets, baselines (including HDBSCAN variants), metrics, or ablation tests isolating the mutual-reachability smoothing effect, so the performance claims cannot be assessed for support.
minor comments (2)
- [§3] The manuscript would benefit from pseudocode or a clear algorithmic listing of the chopping procedure (limb identification and cut criteria) to aid implementation and understanding.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the evaluation metrics and number of runs for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline revisions to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method description): The central robustness claim—that mutual reachability distances 'smoothens the data distribution and decreases the influence of low-density objects' enabling accurate limb separation—lacks any theoretical analysis, bounds, or controlled failure-mode tests (e.g., for bridge noise, density gradients, or high dimensions), leaving the key assumption unverified despite being load-bearing for the 'resistant' guarantee.
Authors: We agree that the manuscript provides no formal theoretical analysis or bounds on the smoothing effect of mutual reachability distances. This property is drawn from the established use in HDBSCAN, where it reduces outlier influence via core-distance augmentation. In revision, we will expand §3 with additional intuition and controlled synthetic experiments (e.g., datasets with bridge noise, varying density gradients, and moderate dimensions) to demonstrate limb separation behavior empirically. Deriving general theoretical guarantees for the full heuristic procedure is beyond the current scope and noted as future work. revision: partial
-
Referee: [§4] §4 (Experiments): Benchmark results are asserted without reported details on datasets, baselines (including HDBSCAN variants), metrics, or ablation tests isolating the mutual-reachability smoothing effect, so the performance claims cannot be assessed for support.
Authors: The experimental section uses standard clustering benchmarks and compares against HDBSCAN, but we acknowledge the details may not have been presented with sufficient explicitness. In the revised manuscript, we will expand §4 to include: (i) a table of all datasets with sizes and characteristics, (ii) precise baseline configurations (HDBSCAN with multiple min_cluster_size settings), (iii) the full set of metrics (adjusted Rand index, normalized mutual information, etc.), and (iv) an ablation comparing results with and without mutual reachability distances. The open-source package already enables full reproduction of the reported runs. revision: yes
Circularity Check
No circularity; algorithm is a direct procedural description built on external MST concepts
full rationale
The paper presents Lumbermark as an iterative chopping procedure on a mutual reachability MST, stating its properties (smoothing low-density points) as a direct consequence of the established mutual reachability distance definition from prior literature. No equations, parameters, or steps are defined in terms of the target outputs; no predictions are fitted then renamed; no uniqueness theorems or ansatzes are smuggled via self-citation; the central claim does not reduce to its inputs by construction. The derivation chain is self-contained as a new algorithmic recipe rather than a tautological re-expression of fitted data or prior self-references.
Axiom & Free-Parameter Ledger
free parameters (1)
- user-specified cluster sizes
axioms (1)
- domain assumption Mutual reachability distances smoothen the data distribution and decrease the influence of low-density objects
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lumbermark iteratively chops off large limbs connected by protruding segments of a dataset's mutual reachability minimum spanning tree. The use of mutual reachability distances smoothens the data distribution...
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Algorithm 1. Lumbermark... Let (min_cluster_size) s = f |T'| / k ... For each edge e in T' in decreasing order of weights
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Asystematicreviewofmachinelearningmethodsinsoftware testing
Ajorloo,S.,Jamarani,A.,Kashfi,M.,HaghiKashani,M.,Najafizadeh,A.,2024. Asystematicreviewofmachinelearningmethodsinsoftware testing. Applied Soft Computing 162, 111805. DOI:10.1016/j.asoc.2024.111805
-
[2]
Breunig, Hans-Peter Kriegel, and Joerg Sander
Ankerst, M., Breunig, M., Kriegel, H.P., Sander, J., 1999. OPTICS: Ordering points to identify the clustering structure, in: Proc. ACM Intl. Conf. Management of Data (SIGMOD), pp. 49–60. DOI:10.1145/304182.304187
-
[3]
Communications of the ACM18(9), 509–517 (1975).https://doi.org/10.1145/ 361002.361007
Bentley, J., 1975. Multidimensional binary search trees used for associative searching. Communications of the ACM 18, 509–517. DOI:10. 1145/361002.361007
-
[4]
Blum, A., Hopcroft, J., Kannan, R., 2020. Foundations of Data Science. Cambridge University Press. URL:https://www.cs.cornell. edu/jeh/book.pdf
work page 2020
-
[5]
Borůvka, O., 1926. O jistém problému minimálním. Práce Moravské Přírodovědecké Společnosti v Brně 3, 37–58
work page 1926
-
[6]
In: Advances in Knowledge Discovery and Data Mining
Campello, R.J., Moulavi, D., Sander, J., 2013. Density-based clustering based on hierarchical density estimates. LNAI 7819, 160–172. DOI:10.1007/978-3-642-37456-2_14
-
[7]
Campello,R.J.,Moulavi,D.,Zimek,A.,Sander,J.,2015.Hierarchicaldensityestimatesfordataclustering,visualization,andoutlierdetection. ACM Transactions on Knowledge Discovery from Data 10, 5:1–5:51. DOI:10.1145/2733381
-
[8]
Rates of convergence for the cluster tree, in: Advances in Neural Information Processing Systems, pp
Chaudhuri, K., Dasgupta, S., 2010. Rates of convergence for the cluster tree, in: Advances in Neural Information Processing Systems, pp. 343–351
work page 2010
-
[9]
Cluster expansions:T-walks, labeled pose=ts and matrix calculations
Dogan, A., Birant, D., 2021. Machinelearninganddatamininginmanufacturing. ExpertSystemswithApplications166. DOI:10.1016/j. eswa.2020.114060
work page doi:10.1016/j 2021
-
[10]
A density-based algorithm for discovering clusters in large spatial databases with noise, in: Proc
Ester, M., Kriegel, H.P., Sander, J., Xu, X., 1996. A density-based algorithm for discovering clusters in large spatial databases with noise, in: Proc. KDD’96, pp. 226–231
work page 1996
-
[11]
Florek,K.,Łukaszewicz,J.,Perkal,J.,Steinhaus,H.,Zubrzycki,S.,1951.Surlaliaisonetladivisiondespointsd’unensemblefini.Colloquium Mathematicum 2, 282–285
work page 1951
-
[12]
Iterative shrinking method for clustering problems
Fränti, P., Virmajoki, O., 2006. Iterative shrinking method for clustering problems. Pattern Recognition 39, 761–765
work page 2006
-
[13]
Fu, X., Feng, L., Zhang, L., 2022. Data-driven estimation of tbm performance in soft soils using density-based spatial clustering and random forest. Applied Soft Computing 120, 108686. DOI:10.1016/j.asoc.2022.108686
-
[14]
A framework for benchmarking clustering algorithms
Gagolewski, M., 2022. A framework for benchmarking clustering algorithms. SoftwareX 20, 101270. URL:https:// clustering-benchmarks.gagolewski.com/, DOI:10.1016/j.softx.2022.101270. M. Gagolewski:Preprint; Last updated on 9 April 2026Page 9 of 13 Lumbermark: Resistant Clustering by Chopping Up Mutual Reachability Minimum Spanning Trees
-
[15]
Genie: A new, fast, and outlier-resistant hierarchical clustering algorithm
Gagolewski, M., Bartoszuk, M., Cena, A., 2016. Genie: A new, fast, and outlier-resistant hierarchical clustering algorithm. Information Sciences 363, 8–23
work page 2016
-
[16]
Clustering with minimum spanning trees: How good can it be? Journal of Classification 42, 90–112
Gagolewski, M., Cena, A., Bartoszuk, M., Brzozowski, L., 2025. Clustering with minimum spanning trees: How good can it be? Journal of Classification 42, 90–112. DOI:10.1007/s00357-024-09483-1
-
[17]
Minimum spanning trees and single linkage cluster analysis
Gower, J., Ross, G., 1969. Minimum spanning trees and single linkage cluster analysis. Journal of the Royal Statistical Society. Series C (Applied Statistics) 18, 54–64
work page 1969
-
[18]
Kernel-based fuzzy clustering: A comparative experimental study
Graves, D., Pedrycz, W., 2010. Kernel-based fuzzy clustering: A comparative experimental study. Fuzzy Sets and Systems 161, 522–543
work page 2010
-
[19]
What are the true clusters? Pattern Recognition Letters 64, 53–62
Hennig, C., 2015. What are the true clusters? Pattern Recognition Letters 64, 53–62. DOI:10.1016/j.patrec.2015.04.009
-
[20]
Hubert, L., Arabie, P., 1985. Comparing partitions. Journal of Classification 2, 193–218
work page 1985
-
[21]
Cluster analysis: A modern statistical review
Jaeger, A., Banks, D., 2023. Cluster analysis: A modern statistical review. Wiley Interdisciplinary Reviews: Computational Statistics 15, e1597. DOI:10.1002/wics.1597
-
[22]
Data clustering: A user’s dilemma
Jain, A., Law, M., 2005. Data clustering: A user’s dilemma. Lecture Notes in Computer Science 3776, 1–10
work page 2005
-
[23]
CHAMELEON: Hierarchical clustering using dynamic modeling
Karypis, G., Han, E., Kumar, V., 1999. CHAMELEON: Hierarchical clustering using dynamic modeling. Computer 32, 68–75. DOI:10. 1109/2.781637
work page 1999
-
[24]
Ontheshortestspanningsubtreeofagraphandthetravelingsalesmanproblem
Kruskal,J.,1956. Ontheshortestspanningsubtreeofagraphandthetravelingsalesmanproblem. ProceedingsoftheAmericanMathematical Society 7, 48–50
work page 1956
-
[25]
A probability theory of cluster analysis
Ling, R.F., 1973. A probability theory of cluster analysis. Journal of the American Statistical Association 68, 159–164
work page 1973
-
[26]
A multi-stage hierarchical clustering algorithm based on centroid of tree and cut edge constraint
Ma, Y., Lin, H., Wang, Y., Huang, H., He, X., 2021. A multi-stage hierarchical clustering algorithm based on centroid of tree and cut edge constraint. Information Sciences 557, 194–219. DOI:10.1016/j.ins.2020.12.016
-
[27]
It’sokaytobeskinny,ifyourfriendsarefat,in: The4thCGCWorkshoponComputationalGeometry
Maneewongvatana,S.,Mount,D.,1999. It’sokaytobeskinny,ifyourfriendsarefat,in: The4thCGCWorkshoponComputationalGeometry
work page 1999
-
[28]
McInnes, L., Healy, J., 2017. Accelerated hierarchical density clustering, in: IEEE International Conference on Data Mining Workshops (ICDMW), pp. 33–42. DOI:10.1109/ICDMW.2017.12. see the extended version athttps://arxiv.org/pdf/1705.07321
-
[29]
URL https://doi.org/10.21105/joss.00205
McInnes, L., Healy, J., Astels, S., 2017. hdbscan: Hierarchical density based clustering. The Journal of Open Source Software 2, 205. DOI:10.21105/joss.00205
-
[30]
Information theoretic clustering using minimum spanning trees, in: Proc
Müller, A., Nowozin, S., Lampert, C., 2012. Information theoretic clustering using minimum spanning trees, in: Proc. German Conference on Pattern Recognition.https://github.com/amueller/information-theoretic-mst
work page 2012
-
[31]
Parallel algorithms for hierarchical clustering
Olson, C.F., 1995. Parallel algorithms for hierarchical clustering. Parallel Computing 21, 1313–1325
work page 1995
-
[32]
Scikit-learn: Machine learning in Python
Pedregosa, F., et al., 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12, 2825–2830
work page 2011
-
[33]
Prim,R.C.,1957. Shortestconnectionnetworksandsomegeneralizations. BellSystemTechnicalJournal36,1389–1401. DOI:10.1002/j. 1538-7305.1957.tb01515.x
work page doi:10.1002/j 1957
-
[34]
The ArborX library: Version 2.0
Prokopenko, A., Arndt, D., Lebrun-Grandié, D., Turcksin, B., 2025. The ArborX library: Version 2.0. ACM Transactions on Mathematical Software 51, 30. DOI:10.1145/3772288
-
[35]
Asingle-treealgorithmtocomputetheEuclideanminimumspanningtreeonGPUs
Prokopenko,A.,Sao,P.,Lebrun-Grandié,D.,2023. Asingle-treealgorithmtocomputetheEuclideanminimumspanningtreeonGPUs. Proc. ICPP’22 , 14DOI:10.1145/3545008.3546185
-
[36]
Optimizing search strategies in K-d trees, in: 5th WSES/IEEE Conf
Sample, N., Haines, M., Arnold, M., Purcell, T., 2001. Optimizing search strategies in K-d trees, in: 5th WSES/IEEE Conf. on Circuits, Systems, Communications & Computers (CSCC’01)
work page 2001
-
[37]
Clustering benchmark datasets exploiting the fundamental clustering problems
Thrun, M., Ultsch, A., 2020. Clustering benchmark datasets exploiting the fundamental clustering problems. Data in Brief 30, 105501. DOI:10.1016/j.dib.2020.105501
-
[38]
A white paper on good research practices in benchmarking: The case of cluster analysis
van Mechelen, I., Boulesteix, A.L., Dangl, R., et al., 2023. A white paper on good research practices in benchmarking: The case of cluster analysis. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery , e1511DOI:10.1002/widm.1511
-
[39]
ResTune: Resource oriented tuning boosted by meta-learning for cloud databases
Wang,Y.,Yu,S.,Gu,Y.,Shun,J.,2021. FastparallelalgorithmsforEuclideanminimumspanningtreeandhierarchicalspatialclustering,in: Proc. SIGMOD’21, pp. 1982–1995. DOI:10.1145/3448016.3457296
-
[40]
Expert Systems with Applications238, 122229 (2024) https://doi
Wei,Z.,Gao,Y.,Zhang,X.,Li,X.,Han,Z.,2024. Adaptivemarinetrafficbehaviourpatternrecognitionbasedonmultidimensionaldynamic time warping and dbscan algorithm. Expert Systems with Applications 238. URL:https://www.scopus.com/inward/record.uri? eid=2-s2.0-85174700827&doi=10.1016%2fj.eswa.2023.122229&partnerID=40&md5=5cdf395548b9461bc74e462f9df4332d, DOI:10.101...
-
[41]
Modern algorithms of cluster analysis
Wierzchoń, S., Kłopotek, M., 2018. Modern algorithms of cluster analysis. Springer
work page 2018
-
[42]
Integrating semi-supervised learning with density tree structures for scalable clustering
Yang, H., Feng, Y., Cai, J., Wang, J., Li, Y., Zhao, X., Xun, Y., 2026. Integrating semi-supervised learning with density tree structures for scalable clustering. Applied Soft Computing 186, 114147. DOI:10.1016/j.asoc.2025.114147
-
[43]
Densitypeakclusteringalgorithmbasedonboundaryeliminationandbackboneconstruction
Zhao,Z., Chen,S.,Hu, C.,2025. Densitypeakclusteringalgorithmbasedonboundaryeliminationandbackboneconstruction. AppliedSoft Computing 185, 113880. DOI:10.1016/j.asoc.2025.113880. M. Gagolewski:Preprint; Last updated on 9 April 2026Page 10 of 13 Lumbermark: Resistant Clustering by Chopping Up Mutual Reachability Minimum Spanning Trees 0.05 0.1 0.15 0.2 0.25...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.