Recognition: unknown
BRIDGE: Multimodal-to-Text Retrieval via Reinforcement-Learned Query Alignment
Pith reviewed 2026-05-10 17:23 UTC · model grok-4.3
The pith
The bottleneck in multimodal-to-text retrieval is query misalignment rather than the retriever model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
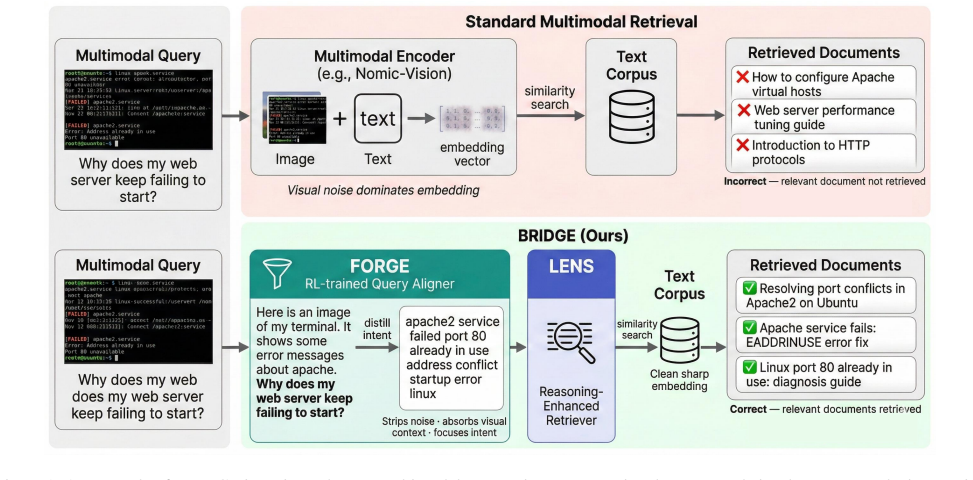
By training a query generator with reinforcement learning to produce compact search strings from multimodal inputs and pairing it with a reasoning retriever, BRIDGE resolves the embedding mismatch in multimodal-to-text retrieval, yielding higher nDCG scores than both multimodal and text-only baselines on MM-BRIGHT.
What carries the argument
FORGE, the focused retrieval query generator trained via reinforcement learning to distill noisy multimodal queries into optimized text, and LENS, the language-enhanced neural search retriever fine-tuned for reasoning-intensive queries.
If this is right
- Multimodal-to-text retrieval can succeed without relying on vision-language encoders by first converting queries to text format.
- Reinforcement learning provides an effective way to optimize queries specifically for retrieval performance.
- Plugging query alignment into existing retrievers can yield gains beyond training new multimodal models.
- Handling intent-rich queries benefits from a separate reasoning-enhanced retriever component.
Where Pith is reading between the lines
- Similar query alignment techniques could address mismatches in other retrieval settings, such as noisy user logs or cross-lingual searches.
- The results suggest prioritizing query reformulation over scaling up encoder sizes for cross-modal tasks.
- Future systems might combine this with larger language models to further improve the quality of generated search strings.
Load-bearing premise
The observed improvements are caused by the reinforcement learning query alignment mechanism itself and not by other unmentioned factors such as larger training datasets or different model architectures.
What would settle it
Reproducing the experiments with identical base models, data, and hyperparameters but without the FORGE RL component or LENS fine-tuning, and checking if the nDCG@10 gains disappear.
Figures


read the original abstract
Multimodal retrieval systems struggle to resolve image-text queries against text-only corpora: the best vision-language encoder achieves only 27.6 nDCG@10 on MM-BRIGHT, underperforming strong text-only retrievers. We argue the bottleneck is not the retriever but the query -- raw multimodal queries entangle visual descriptions, conversational noise, and retrieval intent in ways that systematically degrade embedding similarity. We present \textbf{BRIDGE}, a two-component system that resolves this mismatch without multimodal encoders. \textbf{FORGE} (\textbf{F}ocused Retrieval Query Generato\textbf{r}) is a query alignment model trained via reinforcement learning, which distills noisy multimodal queries into compact, retrieval-optimized search strings. \textbf{LENS} (\textbf{L}anguage-\textbf{E}nhanced \textbf{N}eural \textbf{S}earch) is a reasoning-enhanced dense retriever fine-tuned on reasoning-intensive retrieval data to handle the intent-rich queries FORGE produces. Evaluated on MM-BRIGHT (2,803 queries, 29 domains), BRIDGE achieves \textbf{29.7} nDCG@10, surpassing all multimodal encoder baselines including Nomic-Vision (27.6). When FORGE is applied as a plug-and-play aligner on top of Nomic-Vision, the combined system reaches \textbf{33.3} nDCG@10 -- exceeding the best text-only retriever (32.2) -- demonstrating that \textit{query alignment} is the key bottleneck in multimodal-to-text retrieval. https://github.com/mm-bright/multimodal-reasoning-retrieval
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BRIDGE, a two-component system for multimodal-to-text retrieval consisting of FORGE (a reinforcement-learned query alignment model that distills noisy multimodal queries into compact retrieval-optimized strings) and LENS (a reasoning-enhanced dense retriever fine-tuned on intent-rich data). On the MM-BRIGHT benchmark (2,803 queries across 29 domains), BRIDGE reports 29.7 nDCG@10, outperforming multimodal encoder baselines at 27.6; applying FORGE to Nomic-Vision yields 33.3 nDCG@10, exceeding the best text-only retriever at 32.2. The authors conclude that query alignment, rather than the retriever itself, is the primary bottleneck.
Significance. If the reported gains can be causally attributed to the RL-based query alignment and reasoning components, the work offers a practical alternative to multimodal encoders for cross-modal retrieval, with potential impact on IR systems handling image-text queries. The public code release at https://github.com/mm-bright/multimodal-reasoning-retrieval is a clear strength for reproducibility.
major comments (2)
- [Evaluation on MM-BRIGHT] The central claim that query alignment is the key bottleneck (and that gains arise specifically from RL in FORGE plus reasoning fine-tuning in LENS) rests on aggregate nDCG@10 numbers without ablations, controls for training data volume/quality, base model scale, or hyperparameter differences. This leaves the attribution unsecured.
- [Method] No details are provided on the reward design, policy optimization procedure, or training objectives for the reinforcement learning component of FORGE, nor on data splits or statistical significance of the 29.7 and 33.3 scores (including error bars). These omissions directly affect assessment of the performance claims.
minor comments (1)
- [Introduction] The abstract and introduction would benefit from explicit comparison to prior query reformulation or RL-based retrieval work to better situate the novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation and support the claims.
read point-by-point responses
-
Referee: [Evaluation on MM-BRIGHT] The central claim that query alignment is the key bottleneck (and that gains arise specifically from RL in FORGE plus reasoning fine-tuning in LENS) rests on aggregate nDCG@10 numbers without ablations, controls for training data volume/quality, base model scale, or hyperparameter differences. This leaves the attribution unsecured.
Authors: We agree that the attribution of performance gains specifically to the RL-based query alignment in FORGE and the reasoning fine-tuning in LENS would be more secure with additional controls and ablations. The current results show that applying FORGE to Nomic-Vision yields 33.3 nDCG@10, exceeding the best text-only retriever, which provides some evidence for the importance of query alignment. In the revised manuscript, we will add ablation studies comparing FORGE to non-RL query generation baselines, control for training data volume and quality by matching dataset sizes across conditions, evaluate across different base model scales, and discuss hyperparameter sensitivity to better isolate the contributions of each component. revision: yes
-
Referee: [Method] No details are provided on the reward design, policy optimization procedure, or training objectives for the reinforcement learning component of FORGE, nor on data splits or statistical significance of the 29.7 and 33.3 scores (including error bars). These omissions directly affect assessment of the performance claims.
Authors: We acknowledge that the current manuscript omits key implementation details for the RL component of FORGE and lacks statistical analysis for the reported scores. The revised version will include a full description of the reward design (a composite of nDCG@10 and relevance signals optimized for retrieval), the policy optimization procedure (PPO with specified hyperparameters and training objectives), and the data splits used for MM-BRIGHT. We will also report error bars derived from multiple runs or bootstrap resampling and include statistical significance tests for the 29.7 and 33.3 nDCG@10 scores to allow rigorous evaluation of the results. revision: yes
Circularity Check
No circularity: empirical performance claims on external benchmark
full rationale
The paper's claims rest entirely on measured nDCG@10 results for BRIDGE (29.7), FORGE+Nomic-Vision (33.3), and baselines on the MM-BRIGHT benchmark (2,803 queries, 29 domains). No equations, derivations, fitted parameters, or self-referential definitions appear; FORGE is described as an RL-trained model and LENS as a fine-tuned retriever, but their outputs are evaluated directly against held-out test data rather than constructed from the method itself. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The attribution of gains to query alignment is an empirical interpretation, not a circular reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning with suitable rewards can distill noisy multimodal queries into compact retrieval-optimized text strings without critical loss of intent.
- domain assumption Fine-tuning a dense retriever on reasoning-intensive data measurably improves handling of intent-rich queries produced by alignment.
invented entities (2)
-
FORGE
no independent evidence
-
LENS
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Think-to-detect: Rationale-driven vision–language anomaly detection.Mathematics, 13(24): 3920, 2025
Mahmoud Abdalla, Mahmoud SalahEldin Kasem, Mohamed Mahmoud, Mostafa Farouk Senussi, Abdelrahman Abdal- lah, and Hyun-Soo Kang. Think-to-detect: Rationale-driven vision–language anomaly detection.Mathematics, 13(24): 3920, 2025. 1
2025
-
[2]
Arabicaqa: A comprehensive dataset for arabic question answering
Abdelrahman Abdallah, Mahmoud Kasem, Mahmoud Ab- dalla, Mohamed Mahmoud, Mohamed Elkasaby, Yasser El- bendary, and Adam Jatowt. Arabicaqa: A comprehensive dataset for arabic question answering. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2049–2059, 2024
2049
-
[3]
Abdelrahman Abdallah, Jamshid Mozafari, Bhawna Piryani, and Adam Jatowt. Dear: Dual-stage document reranking with reasoning agents via LLM distillation.arXiv preprint arXiv:2508.16998, 2025. 1
-
[4]
Abdelrahman Abdallah, Bhawna Piryani, Jamshid Mozafari, Mohammed Ali, and Adam Jatowt. Rankify: A comprehen- sive python toolkit for retrieval, re-ranking, and retrieval- augmented generation.arXiv preprint arXiv:2502.02464,
-
[5]
Abdelrahman Abdallah, Mohammed Ali, Muhammad Abdul-Mageed, and Adam Jatowt. TEMPO: A realistic multi-domain benchmark for temporal reasoning-intensive retrieval.arXiv preprint arXiv:2601.09523, 2026. 2
-
[6]
Mm-bright: A multi-task multimodal benchmark for reasoning-intensive retrieval
Abdelrahman Abdallah, Mohamed Darwish Mounis, Mahmoud Abdalla, Mahmoud SalahEldin Kasem, Mostafa Farouk Senussi, Mohamed Mahmoud, Mohammed Ali, Adam Jatowt, and Hyun-Soo Kang. MM-BRIGHT: A multi-task multimodal benchmark for reasoning-intensive retrieval.arXiv preprint arXiv:2601.09562, 2026. 1, 2, 5, 6
-
[7]
Reasoning-focused Multi-turn Conversational Retrieval Benchmark
Mohammed Ali, Abdelrahman Abdallah, Amit Agarwal, Hitesh Laxmichand Patel, and Adam Jatowt. Recor: Reasoning-focused multi-turn conversational retrieval benchmark.arXiv preprint arXiv:2601.05461, 2026. 1, 2
-
[8]
arXiv preprint arXiv:2507.23242 , year=
Sungguk Cha et al. Annotation-free reinforcement learning query rewriting via verifiable search reward.arXiv preprint arXiv:2507.23242, 2025. 3
-
[9]
Re-invoke: Tool invocation rewriting for zero- shot tool retrieval,
Yanfei Chen, Jinsung Yoon, Chanyeol Lee, et al. Re-invoke: Tool retrieval via reversed instructions.arXiv preprint arXiv:2408.01875, 2024. 3
-
[10]
Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, and Chen Zhao
Debrup Das, Sam O’Nuallain, and Razieh Rahimi. RaDeR: Reasoning-aware dense retrieval models.arXiv preprint arXiv:2505.18405, 2025. 2
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI et al. DeepSeek-R1: Incentivizing reason- ing capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C ´eline Hudelot, and Pierre Colombo. Col- Pali: Efficient document retrieval with vision language mod- els.arXiv preprint arXiv:2407.01449, 2024. 1, 2
work page internal anchor Pith review arXiv 2024
-
[13]
Precise zero-shot dense retrieval without relevance labels,
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. arXiv preprint arXiv:2212.10496, 2022. 3, 8
-
[14]
Pengcheng Jiang, Jiacheng Lin, Lang Cao, Runchu Tian, SeongKu Kang, Zifeng Wang, Jimeng Sun, and Jiawei Han. DeepRetrieval: Hacking real search engines and retriev- ers with large language models via reinforcement learning. arXiv preprint arXiv:2503.00223, 2025. 3
- [15]
-
[16]
Billion- scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
Jeff Johnson, Matthijs Douze, and Herv ´e J ´egou. Billion- scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021. 2
2021
-
[17]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen- tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Em- pirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online, 2020. Association for Computa- tional Linguistics. 1, 2
2020
-
[18]
Jina clip: Your clip model is also your text retriever.arXiv preprint arXiv:2405.20204, 2024
Andreas Koukounas et al. Jina CLIP: Your CLIP model is also your text retriever.arXiv preprint arXiv:2405.20204,
-
[19]
Thinkqe: Query expansion via an evolving thinking process.arXiv preprint arXiv:2506.09260, 2025
Yibin Lei, Tao Shen, and Andrew Yates. ThinkQE: Query expansion via an evolving thinking process.arXiv preprint arXiv:2506.09260, 2025. 2, 3
-
[20]
Retrieval-augmented gener- ation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨aschel, Sebas- tian Riedel, and Douwe Kiela. Retrieval-augmented gener- ation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, pages 9459–9474,
-
[21]
arXiv preprint arXiv:2508.07995 , year=
Dingkun Long et al. DIVER: A multi-stage approach for reasoning-intensive information retrieval.arXiv preprint arXiv:2508.07995, 2025. 3
-
[22]
arXiv preprint arXiv:2305.14283 , year=
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large lan- guage models.arXiv preprint arXiv:2305.14283, 2023. 3
-
[23]
Unifying multimodal retrieval via document screenshot embedding.arXiv preprint arXiv:2406.11251,
Xueguang Ma, Jimmy Lin, Minghan Zhang, and Sheng- Chieh Lin. Unifying multimodal retrieval via document screenshot embedding.arXiv preprint arXiv:2406.11251,
-
[24]
M2unet: A segmentation-guided gan with attention- enhanced u2-net for face unmasking.Mathematics, 14(3): 477, 2026
Mohamed Mahmoud, Mostafa Farouk Senussi, Mahmoud Abdalla, Mahmoud SalahEldin Kasem, and Hyun-Soo Kang. M2unet: A segmentation-guided gan with attention- enhanced u2-net for face unmasking.Mathematics, 14(3): 477, 2026. 1
2026
-
[25]
Kelong Mao, Zhicheng Dou, Fengran Mo, Jian-Yun Wen, et al. ConvGQR: Generative query reformulation for con- versational search.arXiv preprint arXiv:2305.15645, 2023. 3
-
[26]
How good are llm-based rerankers? an empirical analysis of state-of-the-art reranking models
Abdelrahman Abdallah Bhawna Piryani Jamshid Mozafari and Mohammed Ali Adam Jatowt. How good are llm-based rerankers? an empirical analysis of state-of-the-art reranking models. 2025. 1
2025
-
[27]
MTEB: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. In Proceedings of the 17th Conference of the European Chap- ter of the Association for Computational Linguistics, pages 9 2014–2037, Dubrovnik, Croatia, 2023. Association for Com- putational Linguistics. 2
2014
-
[28]
Duc Anh Nguyen et al. RL-based query rewriting with dis- tilled LLM for online e-commerce systems.arXiv preprint arXiv:2501.18056, 2025. 3
-
[29]
Large dual encoders are generalizable retrievers
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Her- nandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, and Yinfei Yang. Large dual encoders are generalizable retrievers. InProceedings of the 2022 Confer- ence on Empirical Methods in Natural Language Processing, pages 9844–9855, Abu Dhabi, United Arab Emirates, 2022. Association for...
2022
-
[30]
Zach Nussbaum, John X. Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder.arXiv preprint arXiv:2402.01613,
-
[31]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Car- roll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instruc- tions with human fe...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763. PMLR, 2021. 2, 6
2021
-
[34]
Sentence-BERT: Sen- tence embeddings using Siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sen- tence embeddings using Siamese BERT-networks. InPro- ceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pages 3982–3992, Hong Kong, China, 2019. As- sociation for Computational Lin...
2019
-
[35]
Robertson and Hugo Zaragoza
Stephen E. Robertson and Hugo Zaragoza. The probabilistic relevance framework: BM25 and beyond.Foundations and Trends in Information Retrieval, 3(4):333–389, 2009. 2
2009
-
[36]
Reasonir: Training retrievers for reasoning tasks.arXiv preprint arXiv:2504.20595,
Rulin Shao, Rui Qiao, Varsha Kishore, Niklas Muennighoff, Xi Victoria Lin, Daniela Rus, Bryan Kian Hsiang Low, Se- won Min, Wen-tau Yih, Pang Wei Koh, and Luke Zettle- moyer. ReasonIR: Training retrievers for reasoning tasks. arXiv preprint arXiv:2504.20595, 2025. 2
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han-yu Wang, Haisu Liu, Quan Shi, Zachary S. Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan ¨O. Arik, Danqi Chen, and Tao Yu. BRIGHT: A real- istic and challenging benchmark for reasoning-intensive re- trieval.arXiv preprint arXiv:2407.12883, 2024. 2
-
[39]
Is ChatGPT good at search? Investigating large language models as re-ranking agents,
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. Is ChatGPT good at search? investigating large language models as re-ranking agents.arXiv preprint arXiv:2304.09542, 2023. 1
-
[40]
BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models
Nandan Thakur, Nils Reimers, Andreas R ¨uckl´e, Abhishek Srivastava, and Iryna Gurevych. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. InProceedings of the Neural Information Process- ing Systems Track on Datasets and Benchmarks 1 (NeurIPS Datasets and Benchmarks 2021), 2021. 2
2021
-
[41]
Query2doc: Query expansion with large language models
Liang Wang, Nan Yang, and Furu Wei. Query2doc: Query expansion with large language models.arXiv preprint arXiv:2303.07678, 2023. 2, 3, 8
-
[42]
Few-shot generative con- versational query rewriting
Shi Yu, Jiahua Liu, Jingqing Yang, Chenyan Xu, Huan Yu, Zhiyuan Liu, and Maosong Sun. Few-shot generative con- versational query rewriting. InProceedings of the 43rd In- ternational ACM SIGIR Conference on Research and Devel- opment in Information Retrieval (SIGIR ’20), 2020. 3
2020
-
[43]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, and Maosong Sun. VisRAG: Vision-based retrieval- augmented generation on multi-modality documents.arXiv preprint arXiv:2410.10594, 2024. 2
-
[44]
Sigmoid loss for language image pre-training, 2023
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. arXiv preprint arXiv:2303.15343, 2023. 1, 2, 6
-
[45]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. GME: Improving universal multimodal retrieval by multimodal LLMs.arXiv preprint arXiv:2412.16855,
work page internal anchor Pith review arXiv
-
[46]
Megapairs: Massive data synthesis for universal multi- modal retrieval
Junjie Zhou, Yongping Xiong, Zheng Liu, Ze Liu, Shitao Xiao, Yueze Wang, Bo Zhao, Chen Jason Zhang, and Defu Lian. Megapairs: Massive data synthesis for universal multi- modal retrieval. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19076–19095, 2025. 6
2025
-
[47]
Changtai Zhu, Siyin Wang, Ruijun Feng, Kai Song, and Xipeng Qiu. ConvSearch-R1: Enhancing query reformula- tion for conversational search with reasoning via reinforce- ment learning.arXiv preprint arXiv:2505.15776, 2025. 3 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.