Recognition: 2 theorem links
· Lean TheoremINSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Pith reviewed 2026-05-10 19:02 UTC · model grok-4.3
The pith
INSPATIO-WORLD uses a spatiotemporal autoregressive architecture to generate high-fidelity 4D interactive scenes in real time from a single video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
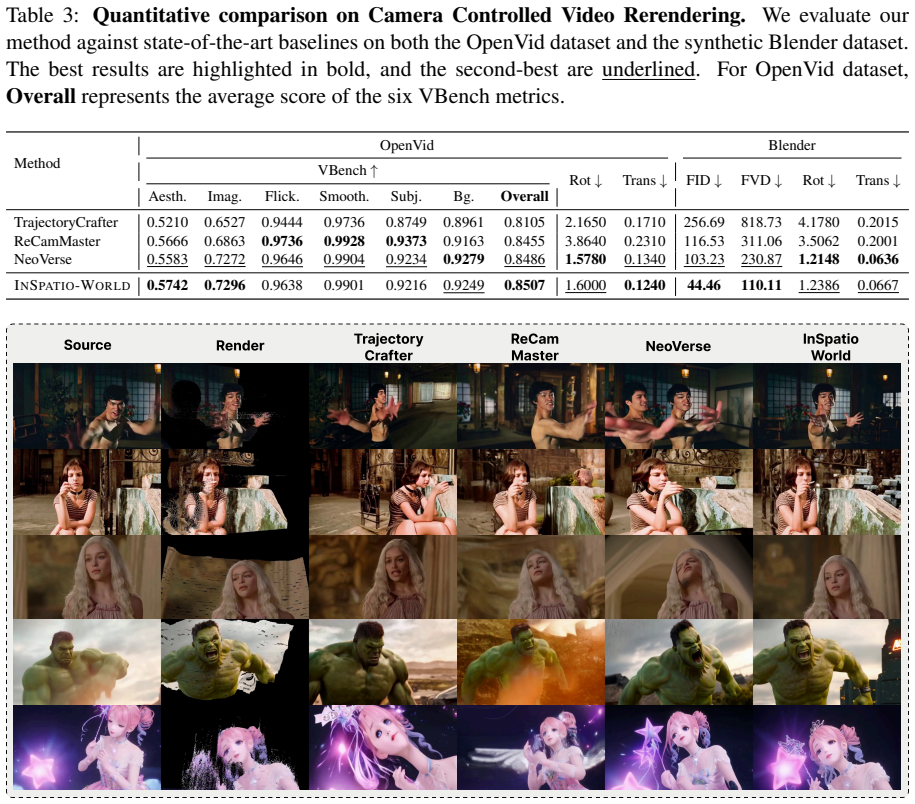
INSPATIO-WORLD recovers and generates high-fidelity, dynamic interactive scenes from a single reference video through a Spatiotemporal Autoregressive architecture. This architecture uses an Implicit Spatiotemporal Cache to aggregate reference and historical observations into a latent world representation for global consistency, and an Explicit Spatial Constraint Module to enforce geometric structure and translate user interactions into precise, physically plausible camera trajectories. Joint Distribution Matching Distillation uses real-world data distributions to prevent fidelity loss from synthetic data reliance. Experiments show it outperforms state-of-the-art models in spatial consistency
What carries the argument
Spatiotemporal Autoregressive (STAR) architecture consisting of an Implicit Spatiotemporal Cache for maintaining latent world representations and an Explicit Spatial Constraint Module for geometric enforcement and interaction handling.
If this is right
- Real-time navigation in 4D environments becomes possible using only monocular video input.
- Global consistency is maintained over long-horizon scene generations without external references.
- User interactions translate directly into physically plausible trajectories.
- Realism is preserved through regularization against real data distributions despite synthetic training components.
Where Pith is reading between the lines
- Such a system could lower the barrier for creating interactive simulations in fields like robotics or gaming by relying on readily available video footage.
- The cache mechanism might inspire similar consistency-preserving techniques in other sequential generation tasks.
- Testing on diverse real-world videos beyond the benchmark could reveal the limits of the spatial consistency claims.
Load-bearing premise
The Implicit Spatiotemporal Cache and Explicit Spatial Constraint Module can together preserve global consistency and physical plausibility in trajectories over long time horizons without losing visual fidelity.
What would settle it
A long navigation sequence generated by the model where object positions drift or geometries become inconsistent with the reference video, or where user-controlled camera paths produce non-physical results.
Figures




read the original abstract
Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces INSPATIO-WORLD, a real-time 4D world simulator that recovers and generates high-fidelity dynamic interactive scenes from a single reference video. Its core is a Spatiotemporal Autoregressive (STAR) architecture comprising an Implicit Spatiotemporal Cache that aggregates reference and historical observations into a latent world representation for global consistency, an Explicit Spatial Constraint Module that enforces geometric structure and translates user interactions into physically plausible camera trajectories, and Joint Distribution Matching Distillation (JDMD) that uses real-world data distributions to counteract fidelity degradation from synthetic data. The central claim is that the method significantly outperforms existing SOTA models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark.
Significance. If the long-horizon consistency and benchmark superiority claims are substantiated with quantitative evidence, the work would constitute a meaningful step toward practical real-time interactive 4D world models from monocular video, with potential utility in robotics, VR/AR, and simulation. The JDMD regularization approach and the coupling of implicit caching with explicit spatial constraints represent potentially reusable ideas for mitigating drift in autoregressive generation.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments: The central claim that the Implicit Spatiotemporal Cache (coupled with the Explicit Spatial Constraint Module) maintains global spatial consistency and produces physically plausible trajectories over long horizons without fidelity loss is load-bearing, yet the manuscript supplies no quantitative scaling analysis. No metrics such as spatial error, reprojection consistency, or trajectory drift are reported as functions of increasing autoregressive steps, navigation length, or video duration on WorldScore-Dynamic or any other benchmark.
- [Abstract] Abstract: The assertion of benchmark superiority and first-place ranking among real-time interactive methods is stated without any numerical results, error bars, ablation tables, or comparison details (e.g., exact WorldScore-Dynamic scores versus prior methods). This absence prevents assessment of effect size or whether gains are driven by short-horizon test cases.
minor comments (2)
- [Abstract] The abstract introduces three new named components (Implicit Spatiotemporal Cache, Explicit Spatial Constraint Module, Joint Distribution Matching Distillation) without a concise one-sentence definition or pointer to the corresponding section for each.
- [Methods] Notation for the STAR architecture and cache update rules should be introduced with a single equation or diagram reference early in the methods to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional quantitative evidence can strengthen the presentation of our long-horizon consistency claims and benchmark results. We address each major comment below and will revise the manuscript accordingly to incorporate the requested analyses and numerical details.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The central claim that the Implicit Spatiotemporal Cache (coupled with the Explicit Spatial Constraint Module) maintains global spatial consistency and produces physically plausible trajectories over long horizons without fidelity loss is load-bearing, yet the manuscript supplies no quantitative scaling analysis. No metrics such as spatial error, reprojection consistency, or trajectory drift are reported as functions of increasing autoregressive steps, navigation length, or video duration on WorldScore-Dynamic or any other benchmark.
Authors: We agree that an explicit scaling analysis would better substantiate the long-horizon claims. The current manuscript reports aggregate performance metrics and qualitative results across navigation sequences but does not plot or tabulate spatial error, reprojection consistency, or trajectory drift as functions of autoregressive steps or video duration. In the revision we will add a dedicated scaling study in the Experiments section, including these metrics evaluated on WorldScore-Dynamic for increasing horizons (e.g., 50, 100, 200 steps) with corresponding figures and tables. revision: yes
-
Referee: [Abstract] Abstract: The assertion of benchmark superiority and first-place ranking among real-time interactive methods is stated without any numerical results, error bars, ablation tables, or comparison details (e.g., exact WorldScore-Dynamic scores versus prior methods). This absence prevents assessment of effect size or whether gains are driven by short-horizon test cases.
Authors: The full manuscript contains comparison tables in Section 4 that report exact WorldScore-Dynamic scores, standard deviations, and ablations against prior real-time methods. The abstract currently summarizes the outcome without these numbers. We will revise the abstract to include the key quantitative results (top score and margins versus the next-best real-time baseline) while retaining the overall claim, thereby allowing readers to assess effect size directly from the abstract. revision: yes
Circularity Check
No significant circularity in architecture or benchmark claims
full rationale
The paper introduces a Spatiotemporal Autoregressive (STAR) architecture with described components (Implicit Spatiotemporal Cache, Explicit Spatial Constraint Module, JDMD) and reports empirical outperformance on the external WorldScore-Dynamic benchmark. No equations, parameter fits, or derivations are shown that reduce by construction to the target metrics or self-referential definitions. Claims rest on experimental results rather than self-citation chains, uniqueness theorems, or renamed known patterns. The central consistency assertions are presented as design goals validated by benchmarks, not forced by internal construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Spatiotemporal autoregressive models can maintain global consistency across long-horizon navigation
- domain assumption Real-world data distributions can serve as an effective regularizer for synthetic generation via distillation
invented entities (3)
-
Implicit Spatiotemporal Cache
no independent evidence
-
Explicit Spatial Constraint Module
no independent evidence
-
Joint Distribution Matching Distillation (JDMD)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearSpatiotemporal Autoregressive (STAR) architecture... Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation... Explicit Spatial Constraint Module enforces geometric structure
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearlong-horizon navigation... spatial consistency... 24 FPS real-time
Reference graph
Works this paper leans on
-
[1]
Block diffusion: Interpolating between autoregressive and diffusion language models
Marianne Arriola, Aaron Gokaslan, Justin T Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between autoregressive and diffusion language models. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[2]
arXiv preprint arXiv:2407.12781 , year=
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.arXiv preprint arXiv:2407.12781, 2024
-
[3]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22875–22889, 2025
2025
-
[4]
ReCamMaster: Camera-Controlled Generative Rendering from A Single Video.IEEE/CVF International Conference on Computer Vision (ICCV), 2025
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. ReCamMaster: Camera-Controlled Generative Rendering from A Single Video.IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[5]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Mar- jorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, and Jessica Yu...
2025
-
[6]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15791–15801, 2025
2025
-
[7]
Weikang Bian, Zhaoyang Huang, Xiaoyu Shi, Yijin Li, Fu-Yun Wang, and Hongsheng Li. GS-DiT: Ad- vancing Video Generation with Pseudo 4D Gaussian Fields through Efficient Dense 3D Point Tracking. arXiv preprint arXiv:2501.02690, 2025
-
[8]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[9]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[10]
TAEHV: Tiny AutoEncoder for Hunyuan Video.https://github.com/ madebyollin/taehv, 2025
Ollin Boer Bohan. TAEHV: Tiny AutoEncoder for Hunyuan Video.https://github.com/ madebyollin/taehv, 2025
2025
-
[11]
Video generation models as world simulators, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators, 2024. URLhttps://openai.com/research/ video-generation-models-as-world-simulators
2024
-
[12]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InInt. Conf. Mach. Learn., 2024
2024
-
[13]
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
Chenjie Cao, Chaohui Yu, Shang Liu, Fan Wang, Xiangyang Xue, and Yanwei Fu. MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model. InIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 6045–6056, 2025. 14
2025
-
[14]
Dif- fusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Dif- fusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[15]
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model, 2025
Yabo Chen, Yuanzhi Liang, Jiepeng Wang, Tingxi Chen, Junfei Cheng, Zixiao Gu, Yuyang Huang, Zicheng Jiang, Wei Li, Tian Li, et al. TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model, 2025
2025
-
[16]
Yipeng Chen, Zhichao Ye, Zhenzhou Fang, Xinyu Chen, Xiaoyu Zhang, Jialing Liu, Nan Wang, Haomin Liu, and Guofeng Zhang. PostCam: Camera-Controllable Novel-View Video Generation with Query- Shared Cross-Attention.arXiv preprint arXiv:2511.17185, 2025
-
[17]
arXiv preprint arXiv:2509.21657 (2025)
Yixiang Dai, Fan Jiang, Chiyu Wang, Mu Xu, and Yonggang Qi. Fantasyworld: Geometry-consistent world modeling via unified video and 3d prediction.arXiv preprint arXiv:2509.21657, 2025
-
[18]
arXiv preprint arXiv:2412.12095 , year=
Chaorui Deng, Deyao Zhu, Kunchang Li, Shi Guang, and Haoqi Fan. Causal diffusion transformers for generative modeling.arXiv preprint arXiv:2412.12095, 2024
-
[19]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yong- gang Qi, and Xinlong Wang. Autoregressive Video Generation without Vector Quantization. InInterna- tional Conference on Learning Representations (ICLR), 2025
2025
-
[20]
WorldScore: A unified evaluation benchmark for world generation
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. WorldScore: A unified evaluation benchmark for world generation. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 27713–27724, 2025
2025
-
[21]
arXiv preprint arXiv:2411.06525 , year=
Wanquan Feng, Jiawei Liu, Pengqi Tu, Tianhao Qi, Mingzhen Sun, Tianxiang Ma, Songtao Zhao, Siyu Zhou, and Qian He. I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength. arXiv preprint arXiv:2411.06525, 2024
-
[22]
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao, and Long Chen. Ca2-VDM: Effi- cient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing.arXiv preprint arXiv:2411.16375, 2024
-
[23]
VGGT: Visual Geometry Grounded Transformer for One-Shot 3D Reconstruction.arXiv preprint arXiv:2512.xxxxx, 2025
Juan Garrido, Jeremy Reizenstein, Ignacio Rocco, Andrea Vedaldi, et al. VGGT: Visual Geometry Grounded Transformer for One-Shot 3D Reconstruction.arXiv preprint arXiv:2512.xxxxx, 2025
2025
-
[24]
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-Context Autoregressive Video Modeling with Next- Frame Prediction.arXiv preprint arXiv:2503.19325, 2025
-
[25]
arXiv preprint arXiv:2501.03847 (2025)
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as Shader: 3D-aware Video Diffusion for Versatile Video Generation Control. arXiv preprint arXiv:2501.03847, 2025
-
[26]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Long context tuning for video generation.arXiv preprint arXiv:2503.10589, 2025
Yuwei Guo, Ceyuan Yang, Ziyan Yang, Zhibei Ma, Zhijie Lin, Zhenheng Yang, Dahua Lin, and Lu Jiang. Long context tuning for video generation.arXiv preprint arXiv:2503.10589, 2025
-
[28]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[29]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review arXiv 2024
-
[30]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Camerac- trl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 15
work page internal anchor Pith review arXiv 2024
-
[31]
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffu- sion models.arXiv preprint arXiv:2503.10592, 2025
-
[32]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey A. Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, and Tim Salimans. Imagen Video: High Definition Video Generation with Diffusion Models.ArXiv, abs/2210.02303, 2022. URLhttps: //api.semanticscholar.org/CorpusID:252715883
work page internal anchor Pith review arXiv 2022
-
[34]
Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models.Advances in Neural Information Processing Systems, 35:8633–8646, 2022
2022
-
[35]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[36]
Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
Chen Hou, Guoqiang Wei, Yan Zeng, and Zhibo Chen. Training-free camera control for video generation. arXiv preprint arXiv:2406.10126, 2024
-
[37]
Jinyi Hu, Shengding Hu, Yuxuan Song, Yufei Huang, Mingxuan Wang, Hao Zhou, Zhiyuan Liu, Wei- Ying Ma, and Maosong Sun. ACDiT: Interpolating Autoregressive Conditional Modeling and Diffusion Transformer.arXiv preprint arXiv:2412.07720, 2024
-
[38]
Motionmaster: Training-free camera motion transfer for video generation,
Teng Hu, Jiangning Zhang, Ran Yi, Yating Wang, Hongrui Huang, Jieyu Weng, Yabiao Wang, and Lizhuang Ma. Motionmaster: Training-free camera motion transfer for video generation.arXiv preprint arXiv:2404.15789, 2024
-
[39]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self-Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
VBench: Comprehensive Benchmark Suite for Video Generation
Zanyi Huang, Haoxin He, Chao Jiang, Cuicui Luan, Kai Wang, Xingzhe Wang, Zehuan Yuan, and Zi- wei Liu. VBench: Comprehensive Benchmark Suite for Video Generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[41]
Pyramidal Flow Matching for Efficient Video Generative Modeling
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal Flow Matching for Efficient Video Generative Modeling. InInterna- tional Conference on Learning Representations (ICLR), 2025
2025
-
[42]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
2023
-
[43]
FIFO-Diffusion: Generating Infinite Videos from Text without Training
Jihwan Kim, Junoh Kang, Jinyoung Choi, and Bohyung Han. FIFO-Diffusion: Generating Infinite Videos from Text without Training. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[44]
VideoPoet: A Large Language Model for Zero- Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jose Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vighnesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. VideoPoet: A Large Language Model for Zero- Shot Video Generation. InInt. Conf. Mach. Learn., 2024
2024
-
[45]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Collaborative video diffusion: Consistent multi-video generation with camera control.Advances in Neural Information Processing Systems, 37:16240–16271, 2024
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control.Advances in Neural Information Processing Systems, 37:16240–16271, 2024
2024
-
[47]
Mirage 2.https://www.mirage2.org/, 2025
World Labs. Mirage 2.https://www.mirage2.org/, 2025. Accessed: 2026-03-11. 16
2025
-
[48]
Teng Li, Guangcong Zheng, Rui Jiang, Tao Wu, Yehao Lu, Yining Lin, Xi Li, et al. Realcam- i2v: Real-world image-to-video generation with interactive complex camera control.arXiv preprint arXiv:2502.10059, 2025
-
[49]
Autoregressive image generation without vector quantization
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[50]
Arlon: Boosting diffusion transformers with autoregressive models for long video generation
Zongyi Li, Shujie Hu, Shujie Liu, Long Zhou, Jeongsoo Choi, Lingwei Meng, Xun Guo, Jinyu Li, Hefei Ling, and Furu Wei. Arlon: Boosting diffusion transformers with autoregressive models for long video generation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[51]
Wonderland: Navigating 3d scenes from a single image
Hanwen Liang, Junli Cao, Vidit Goel, Guocheng Qian, Sergei Korolev, Demetri Terzopoulos, Konstanti- nos N Plataniotis, Sergey Tulyakov, and Jian Ren. Wonderland: Navigating 3d scenes from a single image. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 798–810, 2025
2025
-
[52]
LTX-Video: A DiT-based Video Generation Model.https://github.com/ Lightricks/LTX-Video, 2024
Lightricks. LTX-Video: A DiT-based Video Generation Model.https://github.com/ Lightricks/LTX-Video, 2024
2024
-
[53]
arXiv preprint arXiv:2501.08316 (2025) 2, 3, 4
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation.arXiv preprint arXiv:2501.08316, 2025
-
[54]
arXiv preprint arXiv:2406.05338 , year=
Pengyang Ling, Jiazi Bu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Tong Wu, Huaian Chen, Jiaqi Wang, and Yi Jin. Motionclone: Training-free motion cloning for controllable video generation.arXiv preprint arXiv:2406.05338, 2024
-
[55]
Haozhe Liu, Shikun Liu, Zijian Zhou, Mengmeng Xu, Yanping Xie, Xiao Han, Juan C Pérez, Ding Liu, Kumara Kahatapitiya, Menglin Jia, et al. Mardini: Masked autoregressive diffusion for video generation at scale.arXiv preprint arXiv:2410.20280, 2024
-
[56]
Yaofang Liu, Yumeng Ren, Xiaodong Cun, Aitor Artola, Yang Liu, Tieyong Zeng, Raymond H Chan, and Jean-michel Morel. Redefining Temporal Modeling in Video Diffusion: The Vectorized Timestep Approach.arXiv preprint arXiv:2410.03160, 2024
-
[57]
Autoregressive diffusion transformer for text-to-speech synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, and Haizhou Li. Autoregressive diffusion transformer for text-to-speech synthesis.arXiv preprint arXiv:2406.05551, 2024
-
[58]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jianzhong Wang, and Hang Zhao. Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference.arXiv preprint arXiv:2310.04378, 2023. URLhttps://arxiv.org/abs/2310.04378
work page internal anchor Pith review arXiv 2023
-
[59]
Osv: One step is enough for high-quality image to video generation
Xiaofeng Mao, Zhengkai Jiang, Fu-Yun Wang, Jiangning Zhang, Hao Chen, Mingmin Chi, Yabiao Wang, and Wenhan Luo. Osv: One step is enough for high-quality image to video generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[60]
arXiv preprint arXiv:2503.05638 (2025) 18 Liu et al
YU Mark, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2, 2025
-
[61]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65 (1):99–106, 2021
2021
-
[62]
Hailuo.https://hailuoai.video/, 2024
MiniMax. Hailuo.https://hailuoai.video/, 2024
2024
-
[63]
Sicheng Mo, Thao Nguyen, Xun Huang, Siddharth Srinivasan Iyer, Yijun Li, Yuchen Liu, Abhishek Tan- don, Eli Shechtman, Krishna Kumar Singh, Yong Jae Lee, et al. X-Fusion: Introducing New Modality to Frozen Large Language Models.arXiv preprint arXiv:2504.20996, 2025
-
[64]
Multidiff: Consistent novel view synthesis from a single image
Norman Müller, Katja Schwarz, Barbara Rössle, Lorenzo Porzi, Samuel Rota Bulò, Matthias Nießner, and Peter Kontschieder. Multidiff: Consistent novel view synthesis from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10258–10268, 2024
2024
-
[65]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371, 2024. 17
work page internal anchor Pith review arXiv 2024
-
[66]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review arXiv 2024
-
[67]
Stefan Popov, Amit Raj, Michael Krainin, Yuanzhen Li, William T Freeman, and Michael Rubin- stein. CamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control.arXiv preprint arXiv:2501.06006, 2025
-
[68]
Shuhuai Ren, Shuming Ma, Xu Sun, and Furu Wei. Next Block Prediction: Video Generation via Semi- Auto-Regressive Modeling.arXiv preprint arXiv:2502.07737, 2025
-
[69]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6121–6132, 2025
2025
-
[70]
Rolling diffusion models
David Ruhe, Jonathan Heek, Tim Salimans, and Emiel Hoogeboom. Rolling diffusion models. InInt. Conf. Mach. Learn., 2024
2024
-
[71]
Gen-3 Alpha: High-Fidelity Video Generation.https://runwayml.com/research/ gen-3-alpha, 2024
Runway. Gen-3 Alpha: High-Fidelity Video Generation.https://runwayml.com/research/ gen-3-alpha, 2024
2024
-
[72]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive Distillation for Fast Sampling of Diffusion Models. InInter- national Conference on Learning Representations (ICLR), 2022
2022
-
[73]
MAGI-1: Autoregressive Video Generation at Scale, 2025
Sand-AI. MAGI-1: Autoregressive Video Generation at Scale, 2025. URLhttps://static.magi. world/static/files/MAGI_1.pdf
2025
-
[74]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review arXiv 2022
-
[75]
AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion
Mingzhen Sun, Weining Wang, Gen Li, Jiawei Liu, Jiahui Sun, Wanquan Feng, Shanshan Lao, SiYu Zhou, Qian He, and Jing Liu. AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[76]
Worldplay: Towards long-term geometric consistency for real-time interactive world modeling,
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling.arXiv preprint arXiv:2512.14614, 2025
-
[77]
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
InSpatio Team. InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model.arXiv preprint arXiv:2603.11911, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
Advancing open-source world models,
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, et al. Advancing Open-source World Models.arXiv preprint arXiv:2601.20540, 2026
-
[79]
Phenaki: Variable Length Video Generation from Open Domain Textual Descriptions
R Villegas, H Moraldo, S Castro, M Babaeizadeh, H Zhang, J Kunze, PJ Kindermans, MT Saffar, and D Er- han. Phenaki: Variable Length Video Generation from Open Domain Textual Descriptions. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[80]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.