Recognition: 2 theorem links
· Lean TheoremDiffusion Processes on Implicit Manifolds
Pith reviewed 2026-05-10 19:07 UTC · model grok-4.3
The pith
Point-cloud diffusions converge in law to their manifold counterparts as sample size increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central construction is a data-driven SDE defined in ambient space whose coefficients derive from estimates of the diffusion generator and carré-du-champ on a proximity graph of the data points. The authors prove convergence in law of the induced process on the space of probability paths to the corresponding process on the smooth manifold. Numerical simulation is achieved via Euler-Maruyama integration of this SDE.
What carries the argument
Implicit Manifold-valued Diffusions (IMDs): SDEs in ambient space driven by data-estimated generator and carré-du-champ from the proximity graph, which together encode the local stochastic and geometric structure.
If this is right
- The construction admits practical numerical simulation through Euler-Maruyama integration.
- It supplies a rigorous justification for applying diffusion dynamics to point-cloud data for sampling and exploration.
- New avenues open for manifold-aware generative modeling based on these processes.
Where Pith is reading between the lines
- The convergence may justify using such models on finite but large datasets from real-world manifolds like image spaces or molecular configurations.
- Combining this with existing generative diffusion frameworks could enforce geometric consistency in generated outputs.
- The framework might generalize to other Markov processes beyond diffusions if the generator estimation extends accordingly.
Load-bearing premise
The point cloud is drawn from a distribution supported near a smooth low-dimensional manifold and the proximity graph approximates the intrinsic geometry and diffusion operator sufficiently well.
What would settle it
Sampling points from a known smooth manifold such as a torus, running the IMD simulation for increasing sample sizes, and verifying whether the distribution of paths approaches the analytically known manifold diffusion would test the claim; failure to converge would falsify it.
Figures






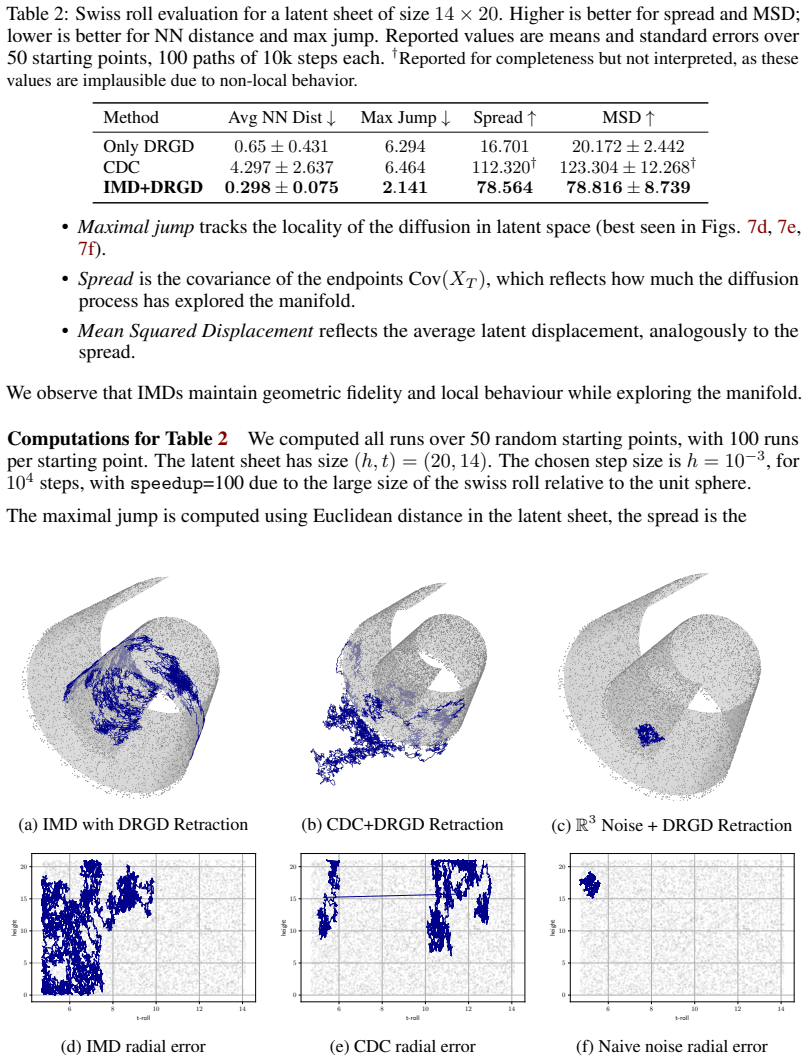
read the original abstract
High-dimensional data are often modeled as lying near a low-dimensional manifold. We study how to construct diffusion processes on this data manifold in the implicit setting. That is, using only point cloud samples and without access to charts, projections, or other geometric primitives. Our main contribution is a data-driven SDE that captures intrinsic diffusion on the underlying manifold while being defined in ambient space. The construction relies on estimating the diffusion's infinitesimal generator and its carr\'e-du-champ (CDC) from a proximity graph built from the data. The generator and CDC together encode the local stochastic and geometric structure of the intended diffusion. We show that, as the number of samples grows, the induced process converges in law on the space of probability paths to its smooth manifold counterpart. We call this construction Implicit Manifold-valued Diffusions (IMDs), and furthermore present a numerical simulation procedure using Euler-Maruyama integration. This gives a rigorous basis for practical implementations of diffusion dynamics on data manifolds, and opens new directions for manifold-aware sampling, exploration, and generative modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Implicit Manifold-valued Diffusions (IMDs), a data-driven construction of an SDE on an implicit manifold from point-cloud samples. A proximity graph is used to estimate the infinitesimal generator and carré-du-champ operator; these estimates define an ambient-space SDE whose paths are claimed to converge in law (on the space of probability measures on paths) to the diffusion process on the underlying smooth manifold as the number of samples tends to infinity. An Euler-Maruyama discretization is also supplied for numerical simulation.
Significance. If the convergence result holds under standard manifold-learning assumptions, the work supplies a rigorous bridge between graph-based operator approximation and path-space stochastic processes. This could support manifold-aware sampling and generative modeling without requiring explicit charts or projections, extending classical graph-Laplacian techniques to the SDE setting.
major comments (2)
- [§4] §4, Theorem 4.1 (path-space convergence): the statement requires the proximity-graph scale parameter to be chosen as a function of sample size n (e.g., h_n → 0 at a specific rate) so that the estimated generator and CDC converge to their manifold counterparts at a rate sufficient for tightness and limit identification; the current presentation leaves this choice as a free parameter, which risks making the approximation non-uniform and undermines the claimed convergence.
- [§3.2] §3.2 (graph construction): the carré-du-champ estimator is defined via local averages on the proximity graph, but no explicit error bound is given that accounts for both the ambient dimension and the manifold curvature; without such a bound the passage from generator/CDC approximation to path-space convergence cannot be verified.
minor comments (2)
- [Abstract] The abbreviation CDC is introduced in the abstract but used inconsistently in the main text; spell out 'carré-du-champ' on first use in each section.
- [§5] Algorithm 1 (Euler-Maruyama scheme): a pseudocode listing with explicit step-size and projection handling would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight important points for rigorizing the convergence result. We address each major comment below and will revise the manuscript to incorporate the necessary clarifications and bounds.
read point-by-point responses
-
Referee: [§4] §4, Theorem 4.1 (path-space convergence): the statement requires the proximity-graph scale parameter to be chosen as a function of sample size n (e.g., h_n → 0 at a specific rate) so that the estimated generator and CDC converge to their manifold counterparts at a rate sufficient for tightness and limit identification; the current presentation leaves this choice as a free parameter, which risks making the approximation non-uniform and undermines the claimed convergence.
Authors: We agree that the scale parameter must be tied to n for the claimed convergence in law to hold uniformly. Theorem 4.1 is stated under the assumption that the graph estimators converge to the manifold generator and CDC, but the manuscript does not explicitly list the required rate for h_n (such as h_n = O(n^{-1/(d+4)}) or similar, depending on manifold dimension d). We will revise the theorem statement and its proof sketch to include these conditions explicitly, drawing on standard rates from graph Laplacian approximation literature. This ensures tightness and limit identification are verified. revision: yes
-
Referee: [§3.2] §3.2 (graph construction): the carré-du-champ estimator is defined via local averages on the proximity graph, but no explicit error bound is given that accounts for both the ambient dimension and the manifold curvature; without such a bound the passage from generator/CDC approximation to path-space convergence cannot be verified.
Authors: The referee is correct that §3.2 defines the CDC estimator via local averages but provides no quantitative error bound that incorporates ambient dimension and curvature effects. Such bounds are needed to control the approximation error in the path-space metric. We will add a supporting lemma in §3.2 (or an appendix) that supplies or derives these error bounds under standard assumptions (e.g., bounded curvature, uniform sampling density), citing relevant results from manifold learning if appropriate. This will directly support the passage to the path-space convergence in Theorem 4.1. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a data-driven SDE on an implicit manifold by estimating the infinitesimal generator and carré-du-champ from a proximity graph on point-cloud samples, then proves convergence in law of the induced process to the independently defined diffusion on the underlying smooth manifold. The limit object is external (the smooth-manifold diffusion), not constructed from the estimates themselves. Standard manifold-learning assumptions (dense sampling near the manifold, graph approximating intrinsic geometry) are invoked but do not create a definitional loop or fitted-input prediction. No self-citations, uniqueness theorems, or ansatz smuggling appear in the provided abstract or description. Tunable graph scales are part of the approximation scheme rather than forcing the convergence result by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- proximity graph scale parameter
axioms (2)
- domain assumption Point cloud samples are drawn from a distribution supported near a smooth low-dimensional Riemannian manifold.
- domain assumption The estimated infinitesimal generator and carré-du-champ from the proximity graph converge to their manifold counterparts as sample size increases.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
estimating the diffusion's infinitesimal generator and its carré-du-champ (CDC) from a proximity graph... LN converges to ... the scaled infinitesimal generator ... Xt =⇒ Yt in C([0,T],F(M))
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
graph-to-manifold convergence in Theorem 2 ... Mosco convergence of Dirichlet forms
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Generative models on phase space
Generative diffusion and flow models are constructed to remain exactly on the Lorentz-invariant massless N-particle phase space manifold during sampling for particle physics applications.
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, 2008
2008
-
[2]
Manifold learning by mixture models of vaes for inverse problems.Journal of Machine Learning Research, 25(202):1–35, 2024
Giovanni S Alberti, Johannes Hertrich, Matteo Santacesaria, and Silvia Sciutto. Manifold learning by mixture models of vaes for inverse problems.Journal of Machine Learning Research, 25(202):1–35, 2024
2024
-
[3]
Springer Science & Business Media, 2013
Dominique Bakry, Ivan Gentil, and Michel Ledoux.Analysis and geometry of Markov diffusion operators, volume 348. Springer Science & Business Media, 2013
2013
-
[4]
Bronstein, Pierre Vandergheynst, and Adam Gosztolai
Jacob Bamberger, Iolo Jones, Dennis Duncan, Michael M. Bronstein, Pierre Vandergheynst, and Adam Gosztolai. Carré du champ flow matching: better quality-generalisation tradeoff in generative models, 2025. URLhttps://arxiv.org/abs/2510.05930
-
[5]
Riemannian metric matching for scalable geometric modelling of distributions
Jacob Bamberger, Adam Gosztolai, Pierre Vandergheynst, Michael M Bronstein, and Iolo Jones. Riemannian metric matching for scalable geometric modelling of distributions. InICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling, 2026
2026
-
[6]
Laplacian eigenmaps for dimensionality reduction and data representation.Neural computation, 15(6):1373–1396, 2003
Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation.Neural computation, 15(6):1373–1396, 2003
2003
-
[7]
Semi-supervised learning on riemannian manifolds.Machine learning, 56(1):209–239, 2004
Mikhail Belkin and Partha Niyogi. Semi-supervised learning on riemannian manifolds.Machine learning, 56(1):209–239, 2004
2004
-
[8]
Towards a theoretical foundation for laplacian-based manifold methods.Journal of Computer and System Sciences, 74(8):1289–1308, 2008
Mikhail Belkin and Partha Niyogi. Towards a theoretical foundation for laplacian-based manifold methods.Journal of Computer and System Sciences, 74(8):1289–1308, 2008
2008
-
[9]
Sampling and estimation on manifolds using the langevin diffusion.Journal of Machine Learning Research, 26(71):1–50, 2025
Karthik Bharath, Alexander Lewis, Akash Sharma, and Michael V Tretyakov. Sampling and estimation on manifolds using the langevin diffusion.Journal of Machine Learning Research, 26(71):1–50, 2025
2025
-
[10]
John Wiley & Sons, 2013
Patrick Billingsley.Convergence of probability measures. John Wiley & Sons, 2013
2013
-
[11]
Dynamical regimes of diffusion models.Nature Communications, 15(1):9957, 2024
Giulio Biroli, Tony Bonnaire, Valentin De Bortoli, and Marc Mézard. Dynamical regimes of diffusion models.Nature Communications, 15(1):9957, 2024
2024
-
[12]
Stochastic gradient descent on riemannian manifolds.IEEE Transactions on Automatic Control, 58(9):2217–2229, 2013
Silvere Bonnabel. Stochastic gradient descent on riemannian manifolds.IEEE Transactions on Automatic Control, 58(9):2217–2229, 2013
2013
-
[13]
arXiv preprint arXiv:2505.17638 , year=
Tony Bonnaire, Raphaël Urfin, Giulio Biroli, and Marc Mézard. Why diffusion models don’t memorize: The role of implicit dynamical regularization in training.arXiv preprint arXiv:2505.17638, 2025
-
[14]
Nicolas Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, 2023. doi: 10.1017/9781009166164. URL https://www.nicolasboumal.net/book
-
[15]
On the edge of memorization in diffusion models.arXiv preprint arXiv:2508.17689, 2025
Sam Buchanan, Druv Pai, Yi Ma, and Valentin De Bortoli. On the edge of memorization in diffusion models.arXiv preprint arXiv:2508.17689, 2025
-
[16]
A graph discretization of the laplace– beltrami operator.Journal of Spectral Theory, 4(4):675–714, 2015
Dmitri Burago, Sergei Ivanov, and Yaroslav Kurylev. A graph discretization of the laplace– beltrami operator.Journal of Spectral Theory, 4(4):675–714, 2015
2015
-
[17]
Generalization Properties of Score-matching Diffusion Models for Intrinsically Low-dimensional Data
Saptarshi Chakraborty, Quentin Berthet, and Peter L Bartlett. Generalization properties of score-matching diffusion models for intrinsically low-dimensional data.arXiv preprint arXiv:2603.03700, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Flow matching on general geometries.arXiv preprint arXiv:2302.03660, 2023
Ricky TQ Chen and Yaron Lipman. Flow matching on general geometries.arXiv preprint arXiv:2302.03660, 2023
-
[19]
Efficient sampling on riemannian manifolds via langevin mcmc
Xiang Cheng, Jingzhao Zhang, and Suvrit Sra. Efficient sampling on riemannian manifolds via langevin mcmc. InProceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY , USA, 2022. Curran Associates Inc. ISBN 9781713871088. 10
2022
-
[20]
Theory and a lgorithms for diffusion processes on Riemannian manifolds
Xiang Cheng, Jingzhao Zhang, and Suvrit Sra. Theory and algorithms for diffusion processes on riemannian manifolds.arXiv preprint arXiv:2204.13665, 2022
-
[21]
Sinho Chewi.Log-Concave Sampling. 2025. URLhttps://chewisinho.github.io/
2025
-
[22]
American Mathematical Soc., 1997
Fan RK Chung.Spectral graph theory, volume 92. American Mathematical Soc., 1997
1997
-
[23]
Diffusion maps.Applied and computational harmonic analysis, 21(1):5–30, 2006
Ronald R Coifman and Stéphane Lafon. Diffusion maps.Applied and computational harmonic analysis, 21(1):5–30, 2006
2006
-
[24]
Convergence of denoising diffusion models under the manifold hypothesis
Valentin De Bortoli. Convergence of denoising diffusion models under the manifold hypothesis. arXiv preprint arXiv:2208.05314, 2022
-
[25]
Riemannian score-based generative modelling.Advances in neural information processing systems, 35:2406–2422, 2022
Valentin De Bortoli, Emile Mathieu, Michael Hutchinson, James Thornton, Yee Whye Teh, and Arnaud Doucet. Riemannian score-based generative modelling.Advances in neural information processing systems, 35:2406–2422, 2022
2022
-
[26]
Springer, 1992
Manfredo Perdigao Do Carmo and J Flaherty Francis.Riemannian geometry, volume 2. Springer, 1992
1992
-
[27]
John Wiley & Sons, 2009
Stewart N Ethier and Thomas G Kurtz.Markov processes: characterization and convergence. John Wiley & Sons, 2009
2009
-
[28]
Testing the manifold hypothesis
Charles Fefferman, Sanjoy Mitter, and Hariharan Narayanan. Testing the manifold hypothesis. Journal of the American Mathematical Society, 29(4):983–1049, 2016
2016
-
[29]
Data-driven efficient solvers for langevin dynamics on manifold in high dimensions.Applied and Computational Harmonic Analysis, 62:261–309, 2023
Yuan Gao, Jian-Guo Liu, and Nan Wu. Data-driven efficient solvers for langevin dynamics on manifold in high dimensions.Applied and Computational Harmonic Analysis, 62:261–309, 2023
2023
-
[30]
Continuum limit of total variation on point clouds
Nicolás García Trillos and Dejan Slepˇcev. Continuum limit of total variation on point clouds. Archive for rational mechanics and analysis, 220(1):193–241, 2016
2016
-
[31]
Nicolás García Trillos, Moritz Gerlach, Matthias Hein, and Dejan Slepˇcev. Error estimates for spectral convergence of the graph laplacian on random geometric graphs toward the laplace– beltrami operator.Foundations of Computational Mathematics, 20(4):827–887, 2020
2020
-
[32]
Generative learning of densities on manifolds.Computer Methods in Applied Mechanics and Engineering, 446:118266, 2025
Dimitris G Giovanis, Ellis Crabtree, Roger G Ghanem, and Ioannis G Kevrekidis. Generative learning of densities on manifolds.Computer Methods in Applied Mechanics and Engineering, 446:118266, 2025
2025
-
[33]
American Mathemat- ical Soc., 2009
Alexander Grigoryan.Heat kernel and analysis on manifolds, volume 47. American Mathemat- ical Soc., 2009
2009
-
[34]
Geometric numerical integration.Oberwolfach Reports, 3(1):805–882, 2006
Ernst Hairer, Marlis Hochbruck, Arieh Iserles, and Christian Lubich. Geometric numerical integration.Oberwolfach Reports, 3(1):805–882, 2006
2006
-
[35]
Graph laplacians and their convergence on random neighborhood graphs.Journal of Machine Learning Research, 8(6), 2007
Matthias Hein, Jean-Yves Audibert, and Ulrike von Luxburg. Graph laplacians and their convergence on random neighborhood graphs.Journal of Machine Learning Research, 8(6), 2007
2007
-
[36]
Molecular dynamics simulation for all.Neuron, 99(6): 1129–1143, 2018
Scott A Hollingsworth and Ron O Dror. Molecular dynamics simulation for all.Neuron, 99(6): 1129–1143, 2018
2018
-
[37]
Number 38
Elton P Hsu.Stochastic analysis on manifolds. Number 38. American Mathematical Soc., 2002
2002
-
[38]
Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(24):695–709, 2005
Aapo Hyvärinen. Estimation of non-normalized statistical models by score matching.Journal of Machine Learning Research, 6(24):695–709, 2005. URL http://jmlr.org/papers/v6/ hyvarinen05a.html
2005
-
[39]
Springer Science & Business Media, 2011
Jean Jacod and Philip Protter.Discretization of processes, volume 67. Springer Science & Business Media, 2011
2011
-
[40]
Diffusion geometry.arXiv preprint arXiv:2405.10858, 2024
Iolo Jones. Diffusion geometry, 2024. URLhttps://arxiv.org/abs/2405.10858. 11
-
[41]
Computing diffusion geometry.arXiv preprint arXiv:2602.06006, 2026
Iolo Jones and David Lanners. Computing diffusion geometry.arXiv preprint arXiv:2602.06006, 2026
-
[42]
Landing with the score: Riemannian optimization through denoising, 2025
Andrey Kharitenko, Zebang Shen, Riccardo de Santi, Niao He, and Florian Doerfler. Landing with the score: Riemannian optimization through denoising, 2025. URL https://arxiv. org/abs/2509.23357
-
[43]
Low Rank Approximation Lecture 9
Daniel Kressner. Low Rank Approximation Lecture 9. 2018. URL https://www.epfl.ch/ labs/anchp/wp-content/uploads/2018/12/lecture9-slides.pdf
2018
-
[44]
Kazuhiro Kuwae and Takashi Shioya. Convergence of spectral structures: A functional analytic theory and its applications to spectral geometry.Communications in Analysis and Geometry, 11 (4):599–673, September 2003. ISSN 1019-8385. doi: 10.4310/CAG.2003.v11.n4.a1
-
[45]
John Wiley & Sons, 2014
Peter D Lax.Functional analysis. John Wiley & Sons, 2014
2014
-
[46]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
2002
-
[47]
Diffusion map particle systems for generative modeling.arXiv preprint arXiv:2304.00200, 2023
Fengyi Li and Youssef Marzouk. Diffusion map particle systems for generative modeling.arXiv preprint arXiv:2304.00200, 2023
-
[48]
Stochastic lie group integrators.SIAM Journal on Scientific Computing, 30(2):597–617, 2008
Simon JA Malham and Anke Wiese. Stochastic lie group integrators.SIAM Journal on Scientific Computing, 30(2):597–617, 2008
2008
-
[49]
Stochastic gradient descent as approximate bayesian inference.Journal of Machine Learning Research, 18(134):1–35, 2017
Stephan Mandt, Matthew D Hoffman, and David M Blei. Stochastic gradient descent as approximate bayesian inference.Journal of Machine Learning Research, 18(134):1–35, 2017
2017
-
[50]
John Wiley & Sons, 2009
Kanti V Mardia and Peter E Jupp.Directional statistics. John Wiley & Sons, 2009
2009
-
[51]
Mcmc using hamiltonian dynamics.Handbook of markov chain monte carlo, pages 47–95, 2011
Radford M Neal. Mcmc using hamiltonian dynamics.Handbook of markov chain monte carlo, pages 47–95, 2011
2011
-
[52]
Intrinsic gaussian process on unknown manifolds with probabilistic metrics.Journal of Machine Learning Research, 24(104): 1–42, 2023
Mu Niu, Zhenwen Dai, Pokman Cheung, and Yizhu Wang. Intrinsic gaussian process on unknown manifolds with probabilistic metrics.Journal of Machine Learning Research, 24(104): 1–42, 2023
2023
-
[53]
Stochastic differential equations
Bernt Øksendal. Stochastic differential equations. InStochastic differential equations: an introduction with applications, pages 38–50. Springer, 2003
2003
-
[54]
A neural manifold view of the brain
Matthew G Perich, Devika Narain, and Juan A Gallego. A neural manifold view of the brain. Nature Neuroscience, 28(8):1582–1597, 2025
2025
-
[55]
Score-based generative models detect manifolds.Advances in Neural Information Processing Systems, 35:35852–35865, 2022
Jakiw Pidstrigach. Score-based generative models detect manifolds.Advances in Neural Information Processing Systems, 35:35852–35865, 2022
2022
-
[56]
U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation.CoRR, abs/1505.04597, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[57]
Learning stable robotic skills on riemannian manifolds.Robotics and Autonomous Systems, 169:104510, 2023
Matteo Saveriano, Fares J Abu-Dakka, and Ville Kyrki. Learning stable robotic skills on riemannian manifolds.Robotics and Autonomous Systems, 169:104510, 2023
2023
-
[58]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[59]
Improved techniques for training score-based generative models
Yang Song and Stefano Ermon. Improved techniques for training score-based generative models. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 12438–12448. Curran Associates, Inc., 2020
2020
-
[60]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations, 2021. URLhttps://arxiv.org/abs/2011.13456. 12
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[61]
Springer, 2007
Daniel W Stroock and SR Srinivasa Varadhan.Multidimensional diffusion processes. Springer, 2007
2007
-
[62]
Iglesias
Johanna Tengler, Christoph Brune, and José A. Iglesias. Manifold limit for the training of shallow graph convolutional neural networks, 2026. URL https://arxiv.org/abs/2601. 06025
2026
-
[63]
On the rate of convergence of empirical measures in ∞-transportation distance.Canadian Journal of Mathematics, 67(6):1358–1383, 2015
Nicolás Garcia Trillos and Dejan Slepˇcev. On the rate of convergence of empirical measures in ∞-transportation distance.Canadian Journal of Mathematics, 67(6):1358–1383, 2015
2015
-
[64]
A variational approach to the consistency of spectral clustering.Applied and Computational Harmonic Analysis, 45(2):239–281, 2018
Nicolas Garcia Trillos and Dejan Slepˇcev. A variational approach to the consistency of spectral clustering.Applied and Computational Harmonic Analysis, 45(2):239–281, 2018
2018
-
[65]
Springer science & business media, 2013
Vladimir Vapnik.The nature of statistical learning theory. Springer science & business media, 2013
2013
-
[66]
On the convergence of sample probability distributions.Sankhy ¯a: The Indian Journal of Statistics (1933-1960), 19(1/2):23–26, 1958
Veeravalli S Varadarajan. On the convergence of sample probability distributions.Sankhy ¯a: The Indian Journal of Statistics (1933-1960), 19(1/2):23–26, 1958
1933
-
[67]
Springer, 2009
Cédric Villani et al.Optimal transport: old and new, volume 338. Springer, 2009
2009
-
[68]
Bayesian learning via stochastic gradient langevin dynamics
Max Welling and Yee W Teh. Bayesian learning via stochastic gradient langevin dynamics. InProceedings of the 28th international conference on machine learning (ICML-11), pages 681–688, 2011
2011
-
[69]
Spectral convergence of diffusion maps: Improved error bounds and an alternative normalization.SIAM Journal on Numerical Analysis, 59(3): 1687–1734, 2021
Caroline L Wormell and Sebastian Reich. Spectral convergence of diffusion maps: Improved error bounds and an alternative normalization.SIAM Journal on Numerical Analysis, 59(3): 1687–1734, 2021
2021
-
[70]
Global convergence of langevin dynamics based algorithms for nonconvex optimization.Advances in Neural Information Processing Systems, 31, 2018
Pan Xu, Jinghui Chen, Difan Zou, and Quanquan Gu. Global convergence of langevin dynamics based algorithms for nonconvex optimization.Advances in Neural Information Processing Systems, 31, 2018
2018
-
[71]
Se (3) diffusion model with application to protein backbone generation
Jason Yim, Brian L Trippe, Valentin De Bortoli, Emile Mathieu, Arnaud Doucet, Regina Barzilay, and Tommi Jaakkola. Se (3) diffusion model with application to protein backbone generation. InProceedings of the 40th International Conference on Machine Learning, pages 40001–40039, 2023
2023
-
[72]
Olga Zaghen, Floor Eijkelboom, Alison Pouplin, Cong Liu, Max Welling, Jan-Willem van de Meent, and Erik J. Bekkers. Riemannian variational flow matching for material and protein design, 2025. URLhttps://arxiv.org/abs/2502.12981. A Aesthetically pleasing plots (a) 2-dimensional sphere (b) The TorusT 2 (c) Swiss Roll Figure 5: Step size is 1e-3, simulated o...
-
[73]
3Note that anyf∈H 1(M)is automatically inC(M)
For allf∈H 1(M),3 we have EN(PN f)≤(1 +C ′ 1ϵ+C ′ 2 ε ϵ +C ′ 3ϵ2) | {z } =:δ′ N E(f),(46) and C ′ 1 =CαL p, C ′ 2 =C d+ 2d+1Lkϵ(1 +αL p) kϵ(1/2) , C ′ 3 =Cd(K+R −2) andCis a universal constant. 3Note that anyf∈H 1(M)is automatically inC(M). 16
-
[74]
data approximation
For anyu∈H N , we have E(I N u)≤(1 +C ′′ 1 ϵ+C ′′ 2 ε ϵ +C ′′ 3 ϵ2) | {z } =:δ′′ N EN(u),(47) whereI N is the interpolation map and C ′′ 1 =αL p, C ′′ 2 =C(d+C ′ 2), C ′′ 3 = (1 + 1 σkϵ )dK. Corollary 1.We immediately notice that from Appendix C hN ∝ √ϵ, implying that ϵ, ε ϵ and ϵ2 all go to zero as sample sizeN→ ∞, implying that all terms involvingC ′ i ...
-
[75]
We thus disclaim here that the MNIST experiments should be interpreted as empirical evidence, rather than fully theorem-backed instantiations
indicates the current framework should appeal to such kernels. We thus disclaim here that the MNIST experiments should be interpreted as empirical evidence, rather than fully theorem-backed instantiations. We compute the random walk graph Laplacian in the same way in both cases, using Eq. (14). The CDC operator is computed by considering its action on coo...
-
[76]
physical time
and inject it as a bias into the first linear layer (MLP for synthetic data) or as a per-channel bias at every convolutional block (U-Net for MNIST). We use a geometric schedule of noise levels with 20 different noise levels ranging (σmin = 0.005, σmax = 1) for the synthetic examples and 100 noise levels ranging (σmin = 0.01, σmax = 15) for MNIST. Trainin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.