Recognition: no theorem link
A Systematic Study of Retrieval Pipeline Design for Retrieval-Augmented Medical Question Answering
Pith reviewed 2026-05-10 17:48 UTC · model grok-4.3
The pith
Retrieval augmentation with dense retrieval, query reformulation, and reranking lifts medical question answering accuracy to 60.49 percent on USMLE questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Retrieval augmentation significantly improves zero-shot medical question answering performance. The best-performing configuration was dense retrieval with query reformulation and reranking and achieved 60.49% accuracy. Domain-specialized language models were also found to better utilize retrieved medical evidence than general-purpose models. The analysis further reveals a clear tradeoff between retrieval effectiveness and computational cost, with simpler dense retrieval configurations providing strong performance while maintaining higher throughput.
What carries the argument
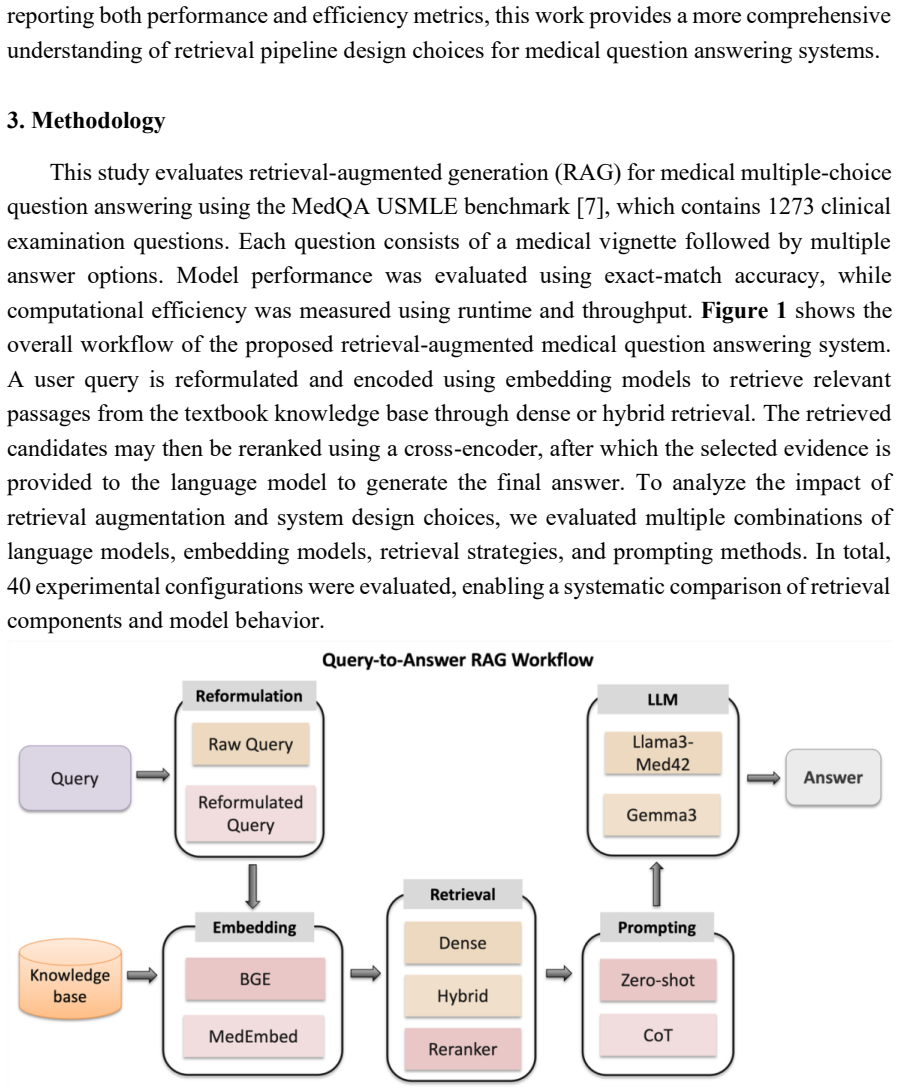
The unified experimental framework of forty configurations that tests the interactions among language models, embedding models, retrieval strategies, query reformulation, and cross-encoder reranking.
If this is right
- Retrieval augmentation significantly improves zero-shot medical question answering performance.
- Dense retrieval combined with query reformulation and reranking reaches 60.49 percent accuracy.
- Domain-specialized language models make better use of retrieved medical evidence than general-purpose models.
- Simpler dense retrieval configurations deliver strong results while preserving higher throughput.
- Systematic evaluation of retrieval-augmented medical QA systems is feasible on a single consumer-grade GPU.
Where Pith is reading between the lines
- Medical QA systems may reach higher reliability by tuning retrieval steps rather than scaling model size alone.
- The same component-wise testing approach could map effective designs for question answering in other technical domains.
- Query reformulation appears to offer higher returns than more elaborate retrieval methods when compute is limited.
Load-bearing premise
The structured textbook-based knowledge corpus is representative of the external knowledge needed to answer MedQA USMLE questions.
What would settle it
Re-running the forty configurations on a different medical knowledge corpus or benchmark and observing that accuracy gains disappear or that a different pipeline ranks highest.
Figures



read the original abstract
Large language models (LLMs) have demonstrated strong capabilities in medical question answering; however, purely parametric models often suffer from knowledge gaps and limited factual grounding. Retrieval-augmented generation (RAG) addresses this limitation by integrating external knowledge retrieval into the reasoning process. Despite increasing interest in RAG-based medical systems, the impact of individual retrieval components on performance remains insufficiently understood. This study presents a systematic evaluation of retrieval-augmented medical question answering using the MedQA USMLE benchmark and a structured textbook-based knowledge corpus. We analyze the interaction between language models, embedding models, retrieval strategies, query reformulation, and cross-encoder reranking within a unified experimental framework comprising forty configurations. Results show that retrieval augmentation significantly improves zero-shot medical question answering performance. The best-performing configuration was dense retrieval with query reformulation and reranking achieved 60.49% accuracy. Domain-specialized language models were also found to better utilize retrieved medical evidence than general-purpose models. The analysis further reveals a clear tradeoff between retrieval effectiveness and computational cost, with simpler dense retrieval configurations providing strong performance while maintaining higher throughput. All experiments were conducted on a single consumer-grade GPU, demonstrating that systematic evaluation of retrieval-augmented medical QA systems can be performed under modest computational resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a systematic empirical evaluation of 40 retrieval-augmented generation (RAG) pipeline configurations for zero-shot medical question answering on the MedQA USMLE benchmark, using a structured textbook-based knowledge corpus. It varies language models (domain-specific vs. general-purpose), embedding models, retrieval strategies (dense vs. sparse), query reformulation techniques, and cross-encoder reranking within a unified framework. Key results include that RAG significantly improves performance over baselines, the best configuration (dense retrieval with query reformulation and reranking) achieves 60.49% accuracy, domain-specialized models better utilize retrieved evidence, and simpler dense setups provide favorable performance-cost tradeoffs, with all experiments runnable on a single consumer-grade GPU.
Significance. If the empirical results hold under scrutiny, this work supplies a practical reference map of RAG design choices in the medical domain, which is timely given rising interest in grounded medical AI systems. The identification of strong performance-cost tradeoffs and the feasibility on modest hardware are particularly useful for guiding resource-aware implementations. The public benchmark and explicit configuration count support reproducibility, though the limited sampling of the full design space constrains how broadly the component rankings can be generalized.
major comments (1)
- The unified experimental framework comprising forty configurations: the design space encompasses interacting choices across embedding models, retrieval type (dense/sparse), reformulation method, reranker, top-k, chunking strategy, and prompt format. Testing only 40 points without a factorial design, explicit sampling justification, or sensitivity analysis leaves open whether untested combinations could yield higher accuracy or change which components appear most important. This directly affects the load-bearing claim that dense retrieval with query reformulation and reranking is the best-performing configuration and that simpler dense setups offer strong tradeoffs.
minor comments (1)
- The abstract states that retrieval augmentation 'significantly improves' performance but does not report the exact zero-shot baseline accuracy or any statistical significance tests for the 60.49% figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our systematic study of RAG pipelines for medical QA. The major comment raises a valid point about the scope of our experimental design, which we address directly below. We have revised the manuscript to incorporate additional justification and caveats.
read point-by-point responses
-
Referee: The unified experimental framework comprising forty configurations: the design space encompasses interacting choices across embedding models, retrieval type (dense/sparse), reformulation method, reranker, top-k, chunking strategy, and prompt format. Testing only 40 points without a factorial design, explicit sampling justification, or sensitivity analysis leaves open whether untested combinations could yield higher accuracy or change which components appear most important. This directly affects the load-bearing claim that dense retrieval with query reformulation and reranking is the best-performing configuration and that simpler dense setups offer strong tradeoffs.
Authors: We agree that the full combinatorial space is larger than the 40 configurations tested and that we did not conduct a complete factorial design or sensitivity analysis across all possible interactions (including top-k, chunking, and prompt format, some of which were fixed to standard values to isolate the effects of the primary variables). Our 40 points were selected to cover representative combinations drawn from established RAG practices in the medical domain, with explicit focus on varying language models, embeddings, retrieval type, reformulation, and reranking within a unified framework. We do not claim that the identified best configuration (dense retrieval + reformulation + reranking at 60.49%) is optimal over the entire untested space, only that it was the strongest among those evaluated. In the revised manuscript we will add: (1) an explicit description of the sampling rationale in Section 3, (2) a statement clarifying that results are relative to the tested set, and (3) an expanded limitations paragraph acknowledging that other combinations could potentially outperform or alter component rankings. These changes temper the claims without altering the core empirical findings or the practical utility of the performance-cost tradeoffs observed. revision: partial
Circularity Check
No circularity: purely empirical comparison of RAG configurations
full rationale
The paper reports an empirical sweep of 40 fixed RAG pipeline variants on the public MedQA USMLE benchmark using a textbook corpus. Performance numbers (e.g., 60.49 % accuracy for the best dense+reformulation+rerank setup) are obtained by direct measurement, not by any equation, fitted parameter, or derivation that reduces to the inputs by construction. No self-citation is invoked to justify uniqueness or to close a logical loop; the design-space critique concerns coverage rather than circular reasoning. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MedQA USMLE is an appropriate benchmark for evaluating medical question answering performance.
- domain assumption The structured textbook corpus supplies the external knowledge needed for the questions.
Reference graph
Works this paper leans on
-
[1]
Attention Is All You Need,
A. Vaswani et al., “Attention Is All You Need,” in Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[2]
Language Models are Few-Shot Learners,
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, and others, “Language Models are Few-Shot Learners,” in Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[3]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, and others, “LLaMA: Open and Efficient Foundation Language Models,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
BioBERT: a pre -trained biomedical language representation model for biomedical text mining,
J. Lee et al., “BioBERT: a pre -trained biomedical language representation model for biomedical text mining,” Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020
2020
-
[5]
arXiv preprint arXiv:1904.05342 , year =
K. Huang, J. Altosaar, and R. Ranganath, “ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission,” arXiv preprint arXiv:1904.05342, 2019
-
[6]
Domain -Specific Language Model Pretraining for Biomedical Natural Language Processing,
Y. Gu, R. Tinn, H. Cheng, M. Lucas, and others, “Domain -Specific Language Model Pretraining for Biomedical Natural Language Processing,” in ACL, 2021
2021
-
[7]
D. Jin, Z. Lu, and P. Szolovits, “What Disease does this Patient Have? A Large -scale Open Domain Question Answering Dataset from Medical Exams,” arXiv preprint arXiv:2009.13081, 2020
-
[8]
PubMedQA: A Dataset for Biomedical Research Question Answering,
Q. Jin, B. Dhingra, Z. Liu, W. Cohen, and X. Lu, “PubMedQA: A Dataset for Biomedical Research Question Answering,” in EMNLP, 2019
2019
-
[9]
MedMCQA: A Large-Scale Multi-Subject Multi-Choice Dataset for Medical Domain Question Answering,
A. Pal, L. Umapathi, and M. Sankarasubbu, “MedMCQA: A Large-Scale Multi-Subject Multi-Choice Dataset for Medical Domain Question Answering,” in AAAI, 2022
2022
-
[10]
On the Opportunities and Risks of Foundation Models
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, and others, “On the Opportunities and Risks of Foundation Models,” arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Survey of Hallucination in Natural Language Generation,
Z. Ji et al., “Survey of Hallucination in Natural Language Generation,” ACM Comput. Surv., 2023
2023
-
[12]
V. Rawte, A. Sheth, and A. Das, “Hallucination in Large Language Models: A Survey,” arXiv preprint arXiv:2309.05922, 2023
-
[13]
KevinGBecker,KathleenCBarnes,TiffaniJBright, and S Alex Wang
Y. Bang, S. Cahyawijaya, N. Lee, and others, “A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity,” arXiv preprint arXiv:2302.04023, 2023
-
[14]
Retrieval - Augmented Generation for Knowledge-Intensive NLP Tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, and others, “Retrieval - Augmented Generation for Knowledge-Intensive NLP Tasks,” in NeurIPS, 2020
2020
-
[15]
Leveraging passage retrieval with generative models for open domain question answering
G. Izacard and E. Grave, “Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering,” arXiv preprint arXiv:2007.01282, 2021
-
[16]
Improving Language Models by Retrieving from Trillions of Tokens,
S. Borgeaud, A. Mensch, J. Hoffmann, T. Cai, and others, “Improving Language Models by Retrieving from Trillions of Tokens,” in ICML, 2022
2022
-
[17]
ArXiv preprint abs/2302.00083 (2023)
O. Ram, Y. Levine, I. Dalmedigos, and others, “In -Context Retrieval -Augmented Language Models,” arXiv preprint arXiv:2302.00083, 2023
-
[18]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y. Gao, Y. Xiong, X. Gao, K. Jia, and others, “Retrieval -Augmented Generation for Large Language Models: A Survey,” arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Large Language Models Encode Clinical Knowledge,
K. Singhal, T. Tu, J. Gottweis, and others, “Large Language Models Encode Clinical Knowledge,” Nature, 2023
2023
-
[20]
Towards Expert -Level Medical Question Answering with Med-PaLM 2,
K. Singhal, S. Azizi, T. Tu, and others, “Towards Expert -Level Medical Question Answering with Med-PaLM 2,” Nature, 2024
2024
-
[21]
Capa- bilities of gpt-4 on medical challenge problems
H. Nori, N. King, S. McKinney, D. Carignan, and E. Horvitz, “Capabilities of GPT-4 on Medical Challenge Problems,” arXiv preprint arXiv:2303.13375, 2023
-
[22]
Can Large Language Models Reason About Medical Questions?,
V. Lievén, C. E. Hother, and O. Winther, “Can Large Language Models Reason About Medical Questions?,” arXiv preprint, 2024
2024
-
[23]
Chain -of-Thought Prompting Elicits Reasoning in Large Language Models,
J. Wei, X. Wang, D. Schuurmans, and others, “Chain -of-Thought Prompting Elicits Reasoning in Large Language Models,” in NeurIPS, 2022
2022
-
[24]
Large Language Models are Zero-Shot Reasoners,
T. Kojima, S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large Language Models are Zero-Shot Reasoners,” in NeurIPS, 2022
2022
-
[25]
doi:10.48550/arXiv.2002.08909 , abstract =
K. Guu, K. Lee, Z. Tung, P. Pasupat, and M. -W. Chang, “REALM: Retrieval - Augmented Language Model Pre-Training,” arXiv preprint arXiv:2002.08909, 2020
-
[26]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
N. Thakur, N. Reimers, J. Daxenberger, and I. Gurevych, “BEIR: A Heterogeneous Benchmark for Zero -shot Evaluation of Information Retrieval Models,” arXiv preprint arXiv:2104.08663, 2021
work page internal anchor Pith review arXiv 2021
-
[27]
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking,
T. Formal, C. Lassance, B. Piwowarski, and S. Clinchant, “SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking,” in SIGIR, 2021
2021
-
[28]
Hybrid Dense -Sparse Retrieval for Open -Domain Question Answering,
X. Ma and J. Lin, “Hybrid Dense -Sparse Retrieval for Open -Domain Question Answering,” arXiv preprint, 2021
2021
-
[29]
R. Nogueira and K. Cho, “Passage Re -ranking with BERT,” arXiv preprint arXiv:1901.04085, 2019
work page internal anchor Pith review arXiv 1901
-
[30]
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT,
O. Khattab and M. Zaharia, “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT,” in SIGIR, 2020
2020
-
[31]
Pretrained Transformers for Text Ranking: BERT and Beyond,
J. Lin and X. Ma, “Pretrained Transformers for Text Ranking: BERT and Beyond,” arXiv preprint, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.