Recognition: 2 theorem links
· Lean TheoremAndroid Coach: Improve Online Agentic Training Efficiency with Single State Multiple Actions
Pith reviewed 2026-05-11 00:48 UTC · model grok-4.3
The pith
A learned critic lets Android agents sample multiple actions from each emulator state, raising success rates while cutting training steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
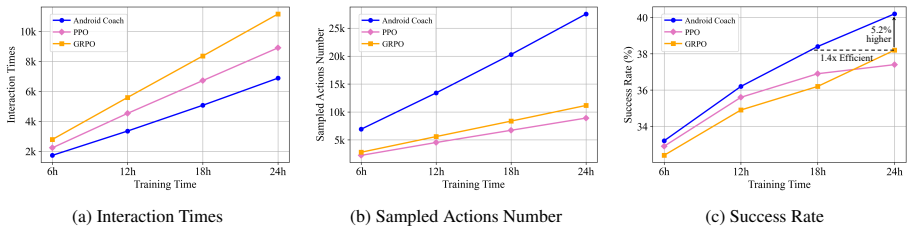
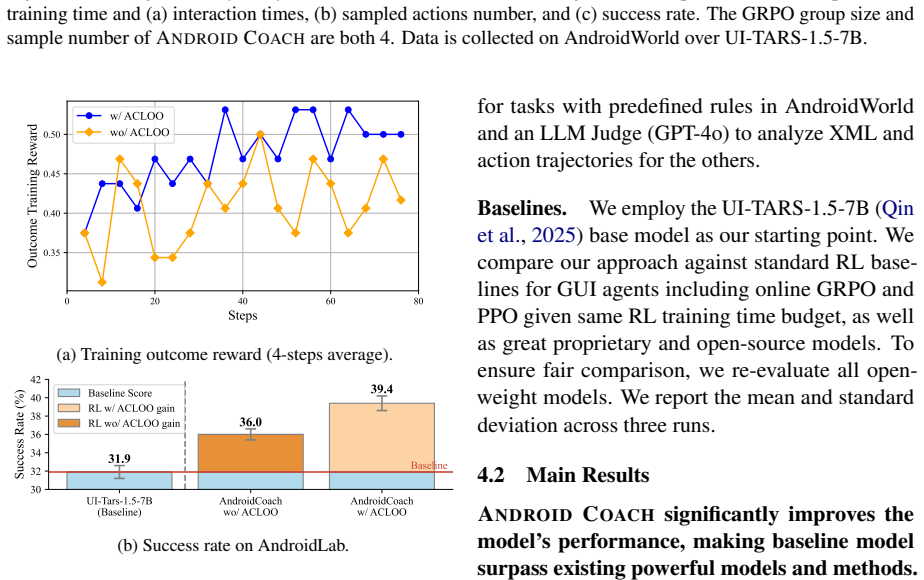
Android Coach replaces the single-state single-action rollout pattern with single-state multiple-actions by training a critic to estimate action values. A process reward model and group-wise averaging of critic outputs supply reliable advantages for policy updates. This yields 7.5% and 8.3% higher success rates on AndroidLab and AndroidWorld while requiring 1.4 times less training effort than PPO or GRPO to reach the same performance level.
What carries the argument
The critic network that estimates action values for multiple candidate actions from one state, combined with a process reward model and group-wise advantage estimation to replace direct emulator rollouts.
If this is right
- Success rates improve by 7.5 percent on AndroidLab and 8.3 percent on AndroidWorld compared to the baseline UI-TARS-1.5-7B.
- Training reaches matched success rates with 1.4 times higher efficiency than standard PPO and GRPO methods.
- The method avoids extra emulator overhead while still exploring more actions per state.
- Policy updates rely on averaged critic outputs rather than single action outcomes.
Where Pith is reading between the lines
- The critic-coach pattern could reduce total environment steps in other high-latency agent domains where each rollout is costly.
- Group-wise averaging of value estimates might stabilize training in other actor-critic setups that suffer from sparse rewards.
- If the critic generalizes across tasks, the same trained coach could be reused for new Android apps without retraining from scratch.
Load-bearing premise
The critic must give accurate enough value estimates that replacing direct emulator rollouts with its predictions does not introduce harmful bias or instability in the policy updates.
What would settle it
Train two versions of the agent to the same success rate, one using only real emulator feedback for every action and one using the critic for multiple actions; if the critic version takes more total emulator steps or reaches lower final performance, the claim fails.
Figures









read the original abstract
Online reinforcement learning (RL) serves as an effective method for enhancing the capabilities of Android agents. However, guiding agents to learn through online interaction is prohibitively expensive due to the high latency of emulators and the sample inefficiency of existing RL algorithms. We identify a fundamental limitation in current approaches: the Single State Single Action paradigm, which updates the policy with one-to-one state-action pairs from online one-way rollouts without fully exploring each costly emulator state. In this paper, we propose Android Coach, a novel framework that shifts the training paradigm to Single State Multiple Actions, allowing the agent to sample and utilize multiple actions for a single online state. We enable this without additional emulator overhead by learning a critic that estimates action values. To ensure the critic serves as a reliable coach, we integrate a process reward model and introduce a group-wise advantage estimator based on the averaged critic outputs. Extensive experiments demonstrate the effectiveness and efficiency of Android Coach: it achieves 7.5% and 8.3% success rate improvements on AndroidLab and AndroidWorld over UI-TARS-1.5-7B, and attains 1.4x higher training efficiency than Single State Single Action methods PPO and GRPO at matched success rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Android Coach, a framework that replaces the Single State Single Action (SSSA) paradigm in online RL for Android agents with Single State Multiple Actions (SSMA). By training a critic to estimate action values for multiple actions per emulator state, combined with a process reward model and group-wise advantage estimation via averaged critic outputs, the method claims to enable fuller exploration of each costly state without additional emulator rollouts. Experiments report 7.5% and 8.3% absolute success-rate gains on AndroidLab and AndroidWorld over the UI-TARS-1.5-7B baseline, plus 1.4x training efficiency relative to PPO and GRPO at matched success rates.
Significance. If the efficiency and performance claims hold under rigorous verification, the SSMA paradigm with critic-based multi-action sampling could meaningfully reduce the sample and wall-clock cost of online RL for high-latency agent environments. The integration of process rewards with group-wise averaging offers a concrete mechanism for turning a learned critic into an advantage estimator, which is a potentially reusable idea for other sparse-reward, long-horizon settings. The work also supplies a clear empirical comparison point against standard on-policy baselines.
major comments (3)
- [Method and Experiments] The central efficiency claim (1.4x over PPO/GRPO at matched success rates) is load-bearing on the assumption that the learned critic supplies sufficiently accurate and low-bias Q-value estimates to replace direct multi-action rollouts. No section provides critic accuracy metrics, calibration plots, or a controlled comparison of critic-derived advantages versus ground-truth advantages obtained from additional emulator steps; without this, the reported gains cannot be confidently attributed to the SSMA mechanism rather than to other implementation details.
- [Advantage Estimator] The group-wise advantage estimator (averaged critic outputs plus process reward) is presented as unbiased, yet the manuscript contains no derivation or analysis showing that the estimator remains unbiased under policy shift or compounding value errors typical of long-horizon Android tasks. A concrete test—e.g., correlation between critic rankings and actual rollout returns on a held-out set of states—would be required to support the claim that SSMA updates are not simply noisy off-policy corrections.
- [Experiments] Table or figure reporting the 7.5 % / 8.3 % success-rate improvements and 1.4x efficiency multiplier does not include variance across seeds, number of emulator steps per method, or an ablation that isolates the contribution of the critic versus the process reward model. These omissions make it impossible to assess whether the efficiency multiplier is robust or sensitive to hyper-parameter choices.
minor comments (2)
- [Method] Notation for the critic (e.g., whether it is a separate network or shares parameters with the policy) and the exact form of the group-wise averaging should be stated explicitly with equations.
- [Introduction] The abstract and introduction repeatedly contrast “Single State Single Action” with the proposed method, but the manuscript does not define the baseline SSSA implementation in sufficient detail for readers to reproduce the efficiency comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments correctly identify areas where additional validation would strengthen the attribution of gains to the SSMA paradigm and the reliability of the advantage estimator. We address each major comment below and commit to revisions that incorporate the requested analyses and reporting.
read point-by-point responses
-
Referee: The central efficiency claim (1.4x over PPO/GRPO at matched success rates) is load-bearing on the assumption that the learned critic supplies sufficiently accurate and low-bias Q-value estimates to replace direct multi-action rollouts. No section provides critic accuracy metrics, calibration plots, or a controlled comparison of critic-derived advantages versus ground-truth advantages obtained from additional emulator steps; without this, the reported gains cannot be confidently attributed to the SSMA mechanism rather than to other implementation details.
Authors: We agree that direct validation of the critic is needed to confidently attribute the efficiency gains to the SSMA mechanism. In the revised manuscript we will add a dedicated subsection reporting critic accuracy via mean squared error on held-out states, calibration plots of predicted versus empirical returns, and a controlled comparison of critic-derived advantages against advantages computed from additional emulator rollouts on a subset of states. These additions will clarify the contribution of the critic-based multi-action sampling. revision: yes
-
Referee: The group-wise advantage estimator (averaged critic outputs plus process reward) is presented as unbiased, yet the manuscript contains no derivation or analysis showing that the estimator remains unbiased under policy shift or compounding value errors typical of long-horizon Android tasks. A concrete test—e.g., correlation between critic rankings and actual rollout returns on a held-out set of states—would be required to support the claim that SSMA updates are not simply noisy off-policy corrections.
Authors: The estimator combines averaged critic outputs with process rewards to reduce variance in long-horizon settings, but we acknowledge the lack of formal bias analysis. In the revision we will include a short derivation of the estimator under the on-policy training regime of the critic and add an empirical correlation study between critic rankings and actual rollout returns on held-out states. This will demonstrate that the updates are not merely noisy off-policy corrections and will address concerns about compounding value errors. revision: yes
-
Referee: Table or figure reporting the 7.5 % / 8.3 % success-rate improvements and 1.4x efficiency multiplier does not include variance across seeds, number of emulator steps per method, or an ablation that isolates the contribution of the critic versus the process reward model. These omissions make it impossible to assess whether the efficiency multiplier is robust or sensitive to hyper-parameter choices.
Authors: We agree that variance, step counts, and component ablations are essential for assessing robustness. The revised manuscript will update the relevant tables and figures to report success rates with standard deviations across three random seeds, explicitly state the number of emulator steps used for each baseline and our method, and add an ablation study that isolates the critic from the process reward model. These changes will allow readers to evaluate sensitivity to design choices. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper proposes an empirical RL framework shifting from Single State Single Action to Single State Multiple Actions via a learned critic, process reward model, and group-wise advantage estimator. No equations, derivations, or first-principles results are shown that reduce any prediction or advantage estimate to the method's own fitted inputs by construction. Reported gains (7.5%/8.3% success rate, 1.4x efficiency) are validated against independent baselines (PPO, GRPO, UI-TARS-1.5-7B) rather than self-defined quantities. The approach relies on standard RL components and experimental comparisons without self-citation load-bearing or ansatz smuggling that would force equivalence to inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose ANDROIDCOACH, a novel actor-critic framework that adopts Single State Multiple Actions (SSMA) paradigm... by learning a critic that estimates action values... group-wise advantage estimator based on the averaged critic outputs.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearOnline reinforcement learning (RL) serves as an effective method for enhancing the capabilities of Android agents... high latency of emulators and the sample inefficiency of existing RL algorithms.
Reference graph
Works this paper leans on
-
[1]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Chris Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell- Ajala, Daniel Toyama, Robert Berry, Divya Tyam- agundlu, Timoth...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others
Learning from delayed rewards. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elic- its reasoning in large language models.Advances in neural information processing systems, 35:24824– 24837. Jinbiao Wei, Yilun Zhao, Kangqi Ni, and Arman Cohan
2022
-
[3]
ANCHOR: Branch-Point Data Generation for GUI Agents
Anchor: Branch-point data generation for gui agents.arXiv preprint arXiv:2602.07153. Zhepei Wei, Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang, Bing Yin, Hyokun Yun, and Lihong Li. 2025. WebAgent-r1: Training web agents via end-to-end multi-turn reinforcement learning. InProceedings of the 2025 Conference on Emp...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GUI-explorer: Autonomous exploration and mining of transition-aware knowledge for GUI agent. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 5650–5667, Vienna, Austria. Association for Computational Linguistics. Yifan Xu, Xiao Liu, Xinghan Liu, Jiaqi Fu, Hanchen Zhang, Bohao Jing, S...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Mai-ui technical report: Real-world centric foundation gui agents.Preprint, arXiv:2512.22047. Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. 2024. Archer: training language model agents via hierarchical multi-turn rl. InPro- ceedings of the 41st International Conference on Ma- chine Learning, ICML’24. JMLR.org. A Implementation De...
-
[6]
The task description
-
[7]
F3tb_presentation.m4a
Mobile and UI Agent Interaction History including the step-by-step page state in compressed XML format and the agent’s action for each step. Scoring Rule: You need to judge if the UI Agent completed the task based on the interaction trajectory. You should return True or False according to your judgment. Output Format: <analysis> [Your analysis] </analysis...
-
[8]
It receives a high-level instruction from a user and attempts to complete it by performing a sequence of actions on the device’s GUI
Context The agent interacts with an android operating system. It receives a high-level instruction from a user and attempts to complete it by performing a sequence of actions on the device’s GUI. The process is sequential: observe screen → generate thought/action → execute action → repeat. The agent’s interaction is restricted to predefined actions: click...
-
[9]
Your task is to critically evaluate the agent’s step using an analytical process: 1) Understand the instruction
Your Task You will be provided with four pieces of information for a single step: instruction, screenshot, historical actions, ground truth action, agent’s thought and action and ground truth judgment. Your task is to critically evaluate the agent’s step using an analytical process: 1) Understand the instruction. 2) Analyze the History and Screenshot. 3) ...
-
[10]
Output Format Your response MUST be a valid JSON object with two keys:
-
[11]
"result": Integer (1 for Correct, 0 for Incorrect)
-
[12]
"reason": Concise string explaining your judgment
-
[13]
result": 1, “reason
Examples Example 1:Correctly Handling an Obstacle (Correct) Instruction:Open a new private tab in the browser. Agent’s Thought and Action:Thought: A system dialog has appeared asking to set the default browser. This is not required for my current task. I will dismiss this dialog by clicking ‘Cancel’ to continue. Action: click(start_box=‘(700, 1300)’) Expe...
-
[14]
Analyzing the first term:Since a(i) is a sample drawn from πθ(·|st), the first term is, by definition, the true policy gradient: E[Q(st,a (i))∇θ logπ θ(a(i)|st)] =∇ θJ(θ)
-
[15]
• The baseline bi = 1 k−1 P j̸=i Q(st,a (j)) is a random variable that depends only on the samples {a(j)}j̸=i
Analyzing the second term (the bias termB): B=E[b i · ∇θ logπ θ(a(i)|st)] The key insight is that ourksamples are i.i.d. • The baseline bi = 1 k−1 P j̸=i Q(st,a (j)) is a random variable that depends only on the samples {a(j)}j̸=i. • The gradient term∇ θ logπ θ(a(i)|st)is a random variable that depends only on the samplea (i). Because a(i) isstatistically...
-
[16]
Thus, the expectation of our estimator is the true policy gradient: E[gi] =∇ θJ(θ)−0 =∇ θJ(θ) This proves the estimator isunbiased
Conclusion:The bias term is zero. Thus, the expectation of our estimator is the true policy gradient: E[gi] =∇ θJ(θ)−0 =∇ θJ(θ) This proves the estimator isunbiased. D.2 Proof of Variance Reduction (via Shift-Invariance) Lemma 2(Variance Reduction).The advantage estimator ˆA(i) is invariant to an arbitrary constant shift Cadded to the Q-function, which ce...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.