Recognition: 2 theorem links
· Lean TheoremCADENCE: Context-Adaptive Depth Estimation for Navigation and Computational Efficiency
Pith reviewed 2026-05-10 17:51 UTC · model grok-4.3
The pith
CADENCE dynamically scales a slimmable monocular depth network to cut energy use by 75% and raise navigation accuracy by 7.43% over static methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CADENCE closes the loop between perception fidelity and actuation requirements by using context to select operating modes of a slimmable monocular depth estimation network, so that high-precision inference occurs only when mission-critical and lower modes suffice otherwise.
What carries the argument
Context-adaptive decision logic that selects the operating mode of the slimmable network to match current navigation needs and environmental demands.
If this is right
- Vehicles can travel farther on the same battery capacity because overall energy expenditure drops by 75%.
- Inference runs with 74.8% lower latency, allowing faster responses to changing surroundings.
- Sensor acquisitions fall by 9.67%, lowering data volume and power spent on capture.
- Navigation accuracy rises by 7.43%, producing more reliable paths than a fixed high-precision approach.
- Embedded hardware with modest resources becomes practical for robust monocular perception tasks.
Where Pith is reading between the lines
- The same context-driven scaling could be applied to other perception modules such as object detection or semantic segmentation on the same platforms.
- In environments with long stretches of low complexity, the savings might compound beyond the reported figures by keeping the network in its lightest mode for extended periods.
- Real-world outdoor tests would be needed to confirm whether variable lighting or terrain changes alter the accuracy of the context detector.
- Pairing the adaptive logic with other low-power sensors could further reduce reliance on depth estimation altogether in certain contexts.
Load-bearing premise
The context detector can correctly identify when high-precision depth is essential and never miss a situation that requires it, while the network's reduced modes still supply enough accuracy for safe navigation.
What would settle it
A recorded navigation error or collision in the testbed where the system selected a low-precision mode immediately before encountering an obstacle whose safe avoidance required the full-precision depth map.
Figures



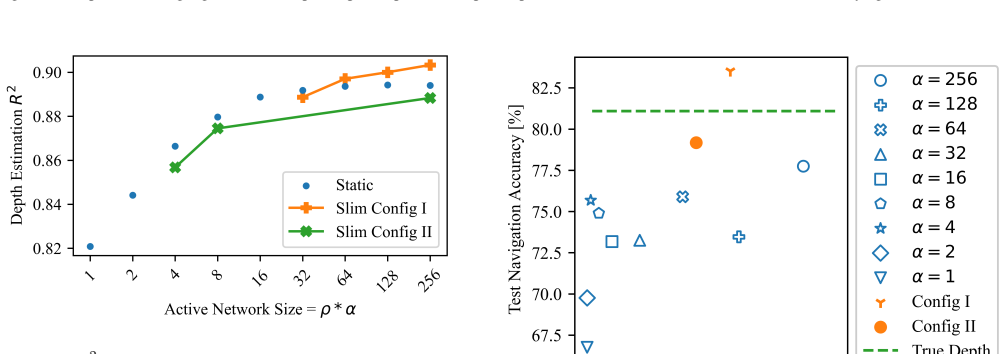



read the original abstract
Autonomous vehicles deployed in remote environments typically rely on embedded processors, compact batteries, and lightweight sensors. These hardware limitations conflict with the need to derive robust representations of the environment, which often requires executing computationally intensive deep neural networks for perception. To address this challenge, we present CADENCE, an adaptive system that dynamically scales the computational complexity of a slimmable monocular depth estimation network in response to navigation needs and environmental context. By closing the loop between perception fidelity and actuation requirements, CADENCE ensures high-precision computing is only used when mission-critical. We conduct evaluations on our released open-source testbed that integrates Microsoft AirSim with an NVIDIA Jetson Orin Nano. As compared to a state-of-the-art static approach, CADENCE decreases sensor acquisitions, power consumption, and inference latency by 9.67%, 16.1%, and 74.8%, respectively. The results demonstrate an overall reduction in energy expenditure by 75.0%, along with an increase in navigation accuracy by 7.43%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CADENCE, a context-adaptive system for monocular depth estimation in autonomous navigation. It employs a slimmable neural network whose width (and thus compute) is dynamically selected based on detected environmental context and navigation requirements, with the goal of using high-fidelity inference only when mission-critical. Evaluations on a released AirSim/Jetson Orin Nano testbed report that, relative to a static state-of-the-art baseline, CADENCE reduces sensor acquisitions by 9.67%, power consumption by 16.1%, inference latency by 74.8%, and overall energy expenditure by 75.0%, while improving navigation accuracy by 7.43%.
Significance. If the reported gains prove robust, the work would be significant for energy-efficient perception on embedded platforms in robotics. The open-source testbed integrating AirSim with Jetson hardware is a concrete contribution that could support reproducibility and follow-on studies. The core idea of closing the perception-actuation loop via context-driven slimmable networks aligns with broader trends in adaptive computing for autonomous systems.
major comments (3)
- [Abstract] Abstract: The headline quantitative claims (9.67% fewer acquisitions, 16.1% lower power, 74.8% lower latency, 75% energy reduction, +7.43% accuracy) are presented without any mention of the number of trials, statistical significance testing, variance across runs, or controls for scenario difficulty and randomization. This absence directly weakens support for the central performance claims.
- [Evaluation] Evaluation (implied by the testbed description): No explicit validation or stress-testing of the context-detection and decision logic is described for safety-critical edge cases such as sudden fog, dynamic obstacles, or terrain shifts that should trigger high-precision mode. Because the policy can skip acquisitions or drop to lower-width modes, any false-negative in context classification trades efficiency for potential navigation failure; average metrics on scripted scenarios do not address this risk.
- [Method] Method (implied by the slimmable-network policy): The manuscript provides no details on how the context classifier was trained, what features it uses, or how its accuracy was measured independently of the end-to-end navigation task. Without this, it is impossible to assess whether the reported efficiency gains are achieved without compromising the reliability of depth estimates when they matter most.
minor comments (1)
- [Abstract] The abstract and results paragraphs would benefit from a brief statement of the baseline static method (architecture, width, acquisition rate) to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have addressed each major comment below with point-by-point responses and have revised the manuscript accordingly to strengthen the presentation of results and methods.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (9.67% fewer acquisitions, 16.1% lower power, 74.8% lower latency, 75% energy reduction, +7.43% accuracy) are presented without any mention of the number of trials, statistical significance testing, variance across runs, or controls for scenario difficulty and randomization. This absence directly weakens support for the central performance claims.
Authors: We agree that the abstract would be strengthened by including experimental context. The full manuscript reports all metrics as averages over 100 independent trials with randomized initial conditions, scenario variations, and controls for difficulty levels, along with standard deviations. We have revised the abstract to state: 'Evaluated over 100 randomized trials on the AirSim/Jetson testbed...' and added a brief reference to variance and statistical controls. A new sentence on significance testing has also been inserted in the Evaluation section. revision: yes
-
Referee: [Evaluation] Evaluation (implied by the testbed description): No explicit validation or stress-testing of the context-detection and decision logic is described for safety-critical edge cases such as sudden fog, dynamic obstacles, or terrain shifts that should trigger high-precision mode. Because the policy can skip acquisitions or drop to lower-width modes, any false-negative in context classification trades efficiency for potential navigation failure; average metrics on scripted scenarios do not address this risk.
Authors: This is a fair observation on the need for robustness analysis. Our evaluations already incorporate varied AirSim scenarios with weather changes and moving obstacles, but dedicated stress tests for abrupt events like sudden fog were not separately highlighted. We have added a new subsection in Evaluation that analyzes policy triggers under simulated adverse conditions, includes example traces of mode switches, and discusses potential failure modes with quantitative false-negative rates from the context classifier. Full real-world stress testing on physical hardware remains outside the current testbed scope but is noted as future work. revision: partial
-
Referee: [Method] Method (implied by the slimmable-network policy): The manuscript provides no details on how the context classifier was trained, what features it uses, or how its accuracy was measured independently of the end-to-end navigation task. Without this, it is impossible to assess whether the reported efficiency gains are achieved without compromising the reliability of depth estimates when they matter most.
Authors: We acknowledge the lack of these specifics in the original submission. The context classifier is a lightweight CNN (based on MobileNetV2) trained on 12,000 labeled AirSim images using RGB image features concatenated with navigation state vectors (velocity and position). Training used cross-entropy loss with data augmentation; standalone accuracy on a held-out test set (independent of navigation episodes) is 93.7% with per-class F1 scores reported. We have expanded the Method section with a new subsection detailing the classifier architecture, training procedure, features, hyperparameters, and independent accuracy metrics. revision: yes
Circularity Check
No circularity: purely empirical system evaluation
full rationale
The paper contains no equations, derivations, or parameter-fitting steps. All reported gains (9.67% fewer acquisitions, 75% energy reduction, +7.43% accuracy) are obtained from direct runtime comparisons against a static baseline on the released AirSim/Jetson testbed. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear; the central claims rest on observable experimental outcomes rather than any reduction to prior inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present CADENCE... dynamically scales the computational complexity of a slimmable monocular depth estimation network... decreases sensor acquisitions, power consumption, and inference latency by 9.67%, 16.1%, and 74.8%
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
slimmable MDE network... ρ = [ρ1, ρi, ...., ρn] ... when ρ=0, the system entirely bypasses image acquisition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
What is the state of neural network pruning?
D. Blalock, J. J. Gonzalez Ortiz, J. Frankle, and J. Guttag, “What is the state of neural network pruning?”Proceedings of machine learning and systems, vol. 2, pp. 129–146, 2020
2020
-
[2]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,”arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Qonnx: Repre- senting arbitrary-precision quantized neural networks,
A. Pappalardo, Y . Umuroglu, M. Blott, J. Mitrevski, B. Hawks, N. Tran, V . Loncar, S. Summers, H. Borras, J. Muhiziet al., “Qonnx: Repre- senting arbitrary-precision quantized neural networks,”arXiv preprint arXiv:2206.07527, 2022
-
[4]
Squeezenext: Hardware-aware neural network design,
A. Gholami, K. Kwon, B. Wu, Z. Tai, X. Yue, P. Jin, S. Zhao, and K. Keutzer, “Squeezenext: Hardware-aware neural network design,” 2018
2018
-
[5]
Videoedge: Processing camera streams using hierarchical clusters,
C.-C. Hung, G. Ananthanarayanan, P. Bodik, L. Golubchik, M. Yu, P. Bahl, and M. Philipose, “Videoedge: Processing camera streams using hierarchical clusters,” in2018 IEEE/ACM Symposium on Edge Computing (SEC), 2018, pp. 115–131
2018
-
[6]
An overview of adaptive dynamic deep neural networks via slimmable and gated ar- chitectures,
T. K. Johnsen, I. Harshbarger, and M. Levorato, “An overview of adaptive dynamic deep neural networks via slimmable and gated ar- chitectures,” in2024 15th International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 2024, pp. 252– 256
2024
-
[7]
Single-image real-time rain removal based on depth-guided non-local features,
X. Hu, L. Zhu, T. Wang, C.-W. Fu, and P.-A. Heng, “Single-image real-time rain removal based on depth-guided non-local features,”IEEE Transactions on Image Processing, vol. 30, pp. 1759–1770, 2021
2021
-
[8]
Navislim: Adaptive context-aware navigation and sensing via dynamic slimmable networks,
T. K. Johnsen and M. Levorato, “Navislim: Adaptive context-aware navigation and sensing via dynamic slimmable networks,” in2024 IEEE/ACM Ninth International Conference on Internet-of-Things Design and Implementation (IoTDI). IEEE, 2024, pp. 110–121
2024
-
[9]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles,
S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” inField and Service Robotics: Results of the 11th International Conference. Springer, 2018, pp. 621–635
2018
-
[10]
Representation learning for event-based visuomotor policies,
S. Vemprala, S. Mian, and A. Kapoor, “Representation learning for event-based visuomotor policies,”Advances in Neural Information Pro- cessing Systems, vol. 34, pp. 4712–4724, 2021
2021
-
[11]
Split computing and early exiting for deep learning applications: Survey and research challenges,
Y . Matsubara, M. Levorato, and F. Restuccia, “Split computing and early exiting for deep learning applications: Survey and research challenges,” ACM Computing Surveys, vol. 55, no. 5, pp. 1–30, 2022
2022
-
[12]
Slimmable neural networks.arXiv preprint arXiv:1812.08928, 2018
J. Yu, L. Yang, N. Xu, J. Yang, and T. Huang, “Slimmable neural networks,”arXiv preprint arXiv:1812.08928, 2018
-
[13]
Hydrafu- sion: Context-aware selective sensor fusion for robust and efficient autonomous vehicle perception,
A. V . Malawade, T. Mortlock, and M. A. Al Faruque, “Hydrafu- sion: Context-aware selective sensor fusion for robust and efficient autonomous vehicle perception,” in2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS). IEEE, 2022, pp. 68– 79
2022
-
[14]
Testudo: Col- laborative intelligence for latency-critical autonomous systems,
M. Odema, L. Chen, M. Levorato, and M. A. Al Faruque, “Testudo: Col- laborative intelligence for latency-critical autonomous systems,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2022
2022
-
[15]
Dynamic slimmable denoising network,
Z. Jiang, C. Li, X. Chang, L. Chen, J. Zhu, and Y . Yang, “Dynamic slimmable denoising network,”IEEE Transactions on Image Processing, vol. 32, pp. 1583–1598, 2023
2023
-
[16]
Repmono: a lightweight self-supervised monocular depth estimation architecture for high-speed inference,
G. Zhang, X. Tang, L. Wang, H. Cui, T. Fei, H. Tang, and S. Jiang, “Repmono: a lightweight self-supervised monocular depth estimation architecture for high-speed inference,”Complex & Intelligent Systems, vol. 10, no. 6, pp. 7927–7941, 2024
2024
-
[17]
Improving accuracy and efficiency of monocular depth estimation in power grid environments using point cloud optimization and knowledge distillation,
J. Xiao, K. Zhang, X. Xu, S. Liu, S. Wu, Z. Huang, and L. Li, “Improving accuracy and efficiency of monocular depth estimation in power grid environments using point cloud optimization and knowledge distillation,”Energies, vol. 17, no. 16, p. 4068, 2024
2024
-
[18]
Navisplit: Dynamic multi-branch split dnns for efficient distributed autonomous navigation,
T. K. Johnsen, I. Harshbarger, Z. Xia, and M. Levorato, “Navisplit: Dynamic multi-branch split dnns for efficient distributed autonomous navigation,” in2024 IEEE 25th International Symposium on a World of Wireless, Mobile and Multimedia Networks (WoWMoM). IEEE, 2024, pp. 196–201
2024
-
[19]
Energy-quality scalable monocular depth estimation on low-power cpus,
A. Cipolletta, V . Peluso, A. Calimera, M. Poggi, F. Tosi, F. Aleotti, and S. Mattoccia, “Energy-quality scalable monocular depth estimation on low-power cpus,”IEEE Internet of Things Journal, vol. 9, no. 1, pp. 25–36, 2021
2021
-
[20]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[21]
Deep reinforcement learning with double q-learning,
H. Van Hasselt, A. Guez, and D. Silver, “Deep reinforcement learning with double q-learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 30, no. 1, 2016
2016
-
[22]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.