Recognition: no theorem link
FORGE: Fine-grained Multimodal Evaluation for Manufacturing Scenarios
Pith reviewed 2026-05-10 19:19 UTC · model grok-4.3
The pith
FORGE evaluations show that insufficient domain knowledge, not visual grounding, is the main bottleneck for MLLMs in manufacturing tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
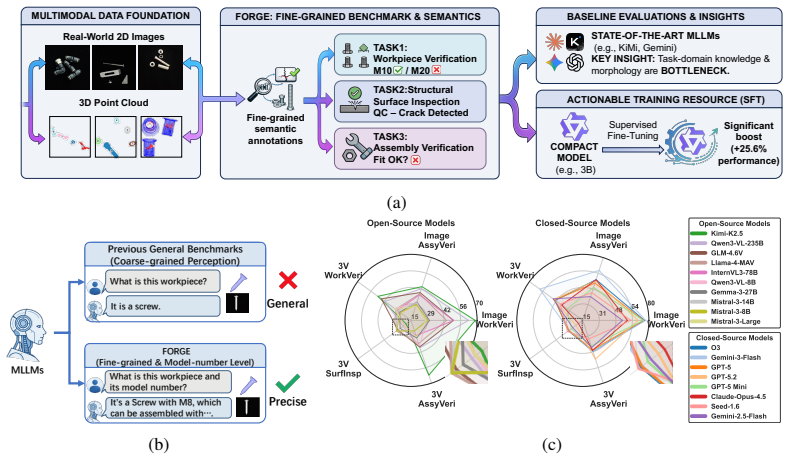
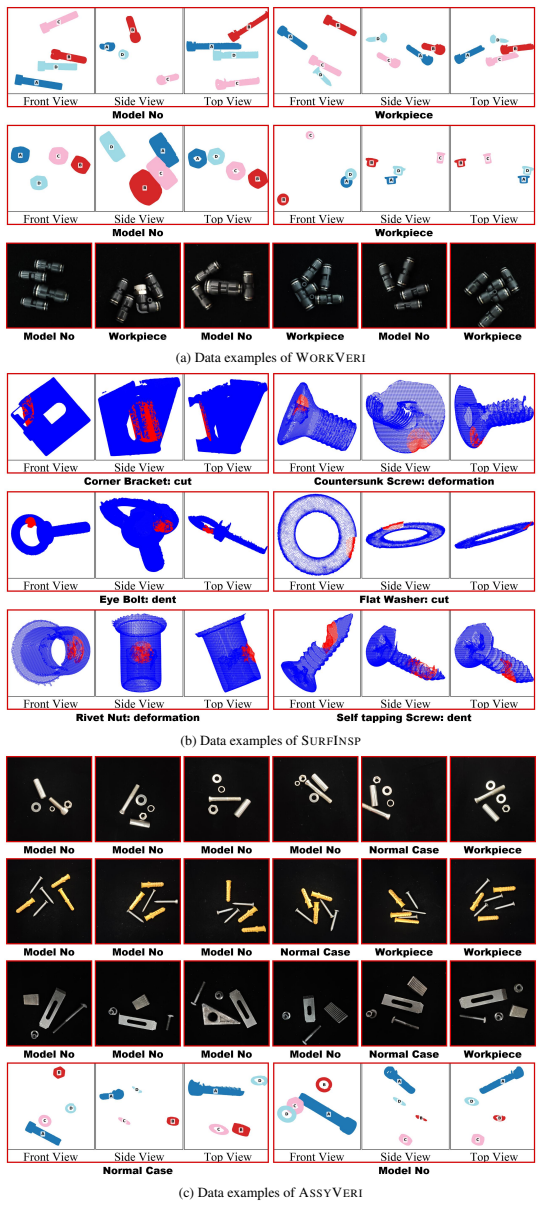
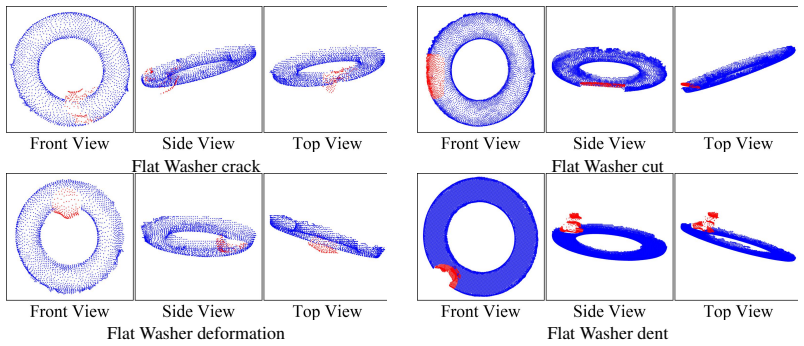
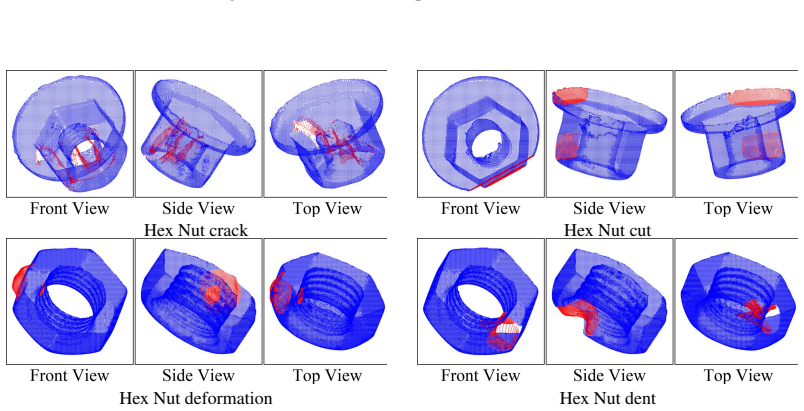
The central claim is that current multimodal large language models exhibit large performance gaps on manufacturing scenarios because they lack domain-specific knowledge rather than because of shortcomings in visual grounding. This conclusion rests on systematic testing across workpiece verification, structural surface inspection, and assembly verification using the new FORGE dataset that pairs real images and point clouds with fine-grained semantic labels. The paper further shows that these same structured annotations function as an effective training resource, producing up to 90.8 percent relative accuracy gains when a compact 3B-parameter model is fine-tuned on held-out manufacturing data.
What carries the argument
The FORGE dataset of multimodal manufacturing data with fine-grained domain annotations, together with the error analysis that isolates knowledge gaps from visual-grounding failures across 18 models.
If this is right
- Future work on manufacturing MLLMs should prioritize methods for embedding domain knowledge over further scaling of visual encoders.
- Compact models become viable for specialized verification once fine-tuned on structured annotations that include exact model numbers and part relations.
- Benchmarks for industrial multimodal models must incorporate fine-grained semantics and paired 2D-3D data to expose real limitations.
- The observed relative gains demonstrate a direct route to domain-adapted models without requiring massive new pretraining.
Where Pith is reading between the lines
- Analogous fine-grained datasets for adjacent sectors such as automotive assembly or aerospace inspection could test whether the knowledge bottleneck appears across other technical domains.
- The gains from supervised fine-tuning imply that targeted data collection may be more cost-effective than continued scaling for narrow industrial applications.
- Extending the dataset with additional 3D reasoning annotations could further reduce errors in spatial assembly tasks that remain challenging even after fine-tuning.
Load-bearing premise
The three chosen tasks and the collected images, point clouds, and annotations faithfully represent the demands and error patterns of actual manufacturing environments.
What would settle it
A re-analysis of model errors that finds visual-grounding mistakes explain most failures, or a fine-tuning trial on the same data that produces no substantial accuracy lift on held-out cases, would disprove the knowledge-bottleneck claim.
Figures












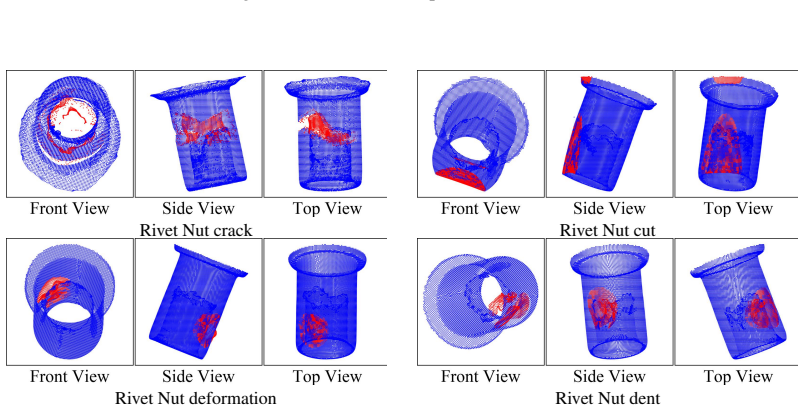




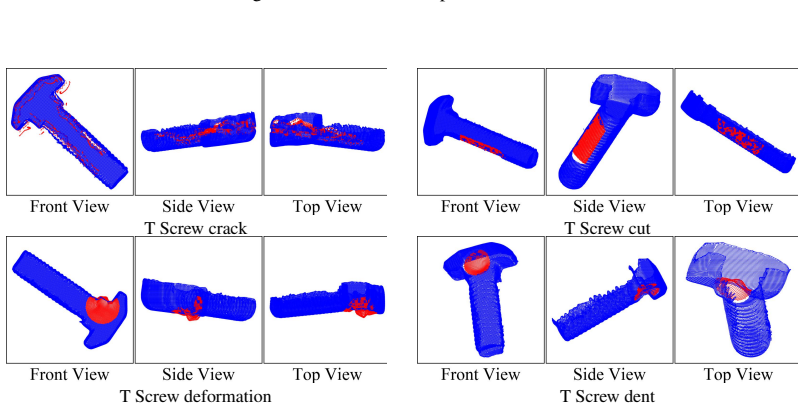
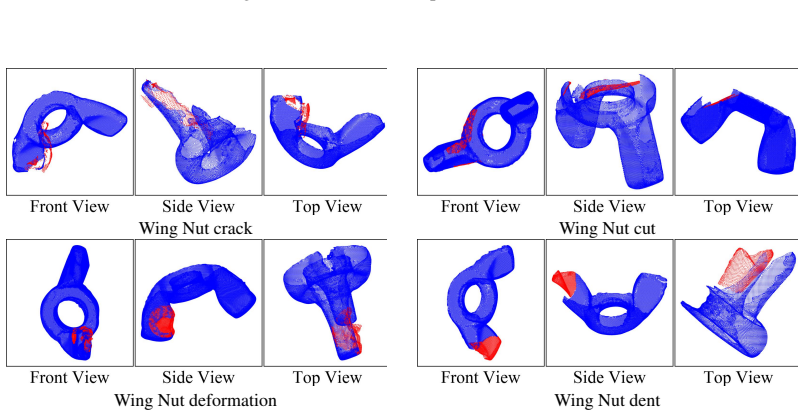









read the original abstract
The manufacturing sector is increasingly adopting Multimodal Large Language Models (MLLMs) to transition from simple perception to autonomous execution, yet current evaluations fail to reflect the rigorous demands of real-world manufacturing environments. Progress is hindered by data scarcity and a lack of fine-grained domain semantics in existing datasets. To bridge this gap, we introduce FORGE. Wefirst construct a high-quality multimodal dataset that combines real-world 2D images and 3D point clouds, annotated with fine-grained domain semantics (e.g., exact model numbers). We then evaluate 18 state-of-the-art MLLMs across three manufacturing tasks, namely workpiece verification, structural surface inspection, and assembly verification, revealing significant performance gaps. Counter to conventional understanding, the bottleneck analysis shows that visual grounding is not the primary limiting factor. Instead, insufficient domain-specific knowledge is the key bottleneck, setting a clear direction for future research. Beyond evaluation, we show that our structured annotations can serve as an actionable training resource: supervised fine-tuning of a compact 3B-parameter model on our data yields up to 90.8% relative improvement in accuracy on held-out manufacturing scenarios, providing preliminary evidence for a practical pathway toward domain-adapted manufacturing MLLMs. The code and datasets are available at https://ai4manufacturing.github.io/forge-web.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the FORGE dataset, which pairs real-world 2D images and 3D point clouds with fine-grained manufacturing annotations (e.g., exact model numbers). It evaluates 18 MLLMs on three tasks—workpiece verification, structural surface inspection, and assembly verification—reports substantial performance gaps, and concludes via bottleneck analysis that insufficient domain-specific knowledge rather than visual grounding is the primary limitation. It further shows that supervised fine-tuning of a 3B-parameter model on the dataset yields up to 90.8% relative accuracy gains on held-out scenarios.
Significance. If the bottleneck diagnosis and SFT results hold, the work supplies a concrete, publicly released resource and empirical direction for adapting MLLMs to manufacturing, moving beyond generic perception benchmarks. The multi-model evaluation and the reported relative improvement on held-out data provide actionable evidence that domain knowledge injection can produce large gains even with compact models.
major comments (2)
- [Bottleneck Analysis] Bottleneck Analysis section: the inference that visual grounding is not the primary limiting factor rests on observing larger errors on knowledge-heavy subtasks (exact model numbers, assembly semantics) than on localization. Because current MLLMs entangle vision, reasoning, and retrieval, this remains correlational; an explicit ablation (oracle visual features, knowledge-augmented prompting without SFT, or separate vision-only baselines) is required to isolate the two factors and support the central claim.
- [SFT Experiments] SFT Experiments: the 90.8% relative improvement is reported for a 3B model on held-out scenarios, yet the manuscript does not provide baseline absolute accuracies, variance across runs, or the precise composition of the held-out set. These details are load-bearing for assessing whether the gain is robust or sensitive to particular data splits.
minor comments (2)
- [Abstract] Abstract: 'Wefirst' should be 'We first'.
- [Dataset Construction] Dataset description: clarify the total number of images/point clouds, the annotation protocol, and inter-annotator agreement to allow readers to judge selection bias and annotation quality.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful and constructive review of our work on the FORGE benchmark. The comments have helped us identify areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that will incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Bottleneck Analysis] Bottleneck Analysis section: the inference that visual grounding is not the primary limiting factor rests on observing larger errors on knowledge-heavy subtasks (exact model numbers, assembly semantics) than on localization. Because current MLLMs entangle vision, reasoning, and retrieval, this remains correlational; an explicit ablation (oracle visual features, knowledge-augmented prompting without SFT, or separate vision-only baselines) is required to isolate the two factors and support the central claim.
Authors: We acknowledge that our bottleneck analysis, while based on a detailed breakdown of errors across subtasks with varying knowledge demands, is indeed correlational due to the entangled nature of MLLMs. To provide stronger evidence, we will conduct and report additional experiments in the revised manuscript, including knowledge-augmented prompting (providing domain-specific information via prompts without SFT) and comparisons to vision-only baselines on localization tasks. These ablations will help better isolate the impact of domain knowledge versus visual grounding capabilities. revision: yes
-
Referee: [SFT Experiments] SFT Experiments: the 90.8% relative improvement is reported for a 3B model on held-out scenarios, yet the manuscript does not provide baseline absolute accuracies, variance across runs, or the precise composition of the held-out set. These details are load-bearing for assessing whether the gain is robust or sensitive to particular data splits.
Authors: We thank the referee for this feedback. In the revised version of the manuscript, we will explicitly include the baseline absolute accuracies for the 3B model before SFT in the main text. We will also report the variance across multiple runs by providing results with standard deviations from repeated experiments. Additionally, we will add a precise description of the held-out set composition, including how the split was performed to ensure held-out scenarios are distinct (no shared model numbers or assembly types) and the number of instances per task. revision: yes
Circularity Check
No significant circularity in empirical evaluation and SFT results
full rationale
The paper's chain consists of constructing a new multimodal dataset with fine-grained annotations, evaluating 18 external MLLMs on three manufacturing tasks, inferring bottlenecks from performance gaps on held-out scenarios, and measuring SFT gains on the same held-out data. None of these steps reduce by construction to fitted inputs, self-definitions, or self-citation chains; the bottleneck claim is an inference from comparative task results rather than a renaming or ansatz. The central results remain independent of the paper's own fitted values.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard accuracy metrics appropriately measure performance on workpiece verification, structural surface inspection, and assembly verification tasks in manufacturing.
Reference graph
Works this paper leans on
-
[1]
MVTec AD – A comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. MVTec AD – A comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019
2019
-
[2]
Sequencing mixed-model assembly lines: Sur- vey, classification and model critique.European Journal of Operational Research, 192(2):349– 373, 2009
Nils Boysen, Malte Fliedner, and Armin Scholl. Sequencing mixed-model assembly lines: Sur- vey, classification and model critique.European Journal of Operational Research, 192(2):349– 373, 2009
2009
-
[3]
Christodoulos Constantinides, Dhaval Patel, Shuxin Lin, Claudio Guerrero, Sunil Dagajirao Patil, and Jayant Kalagnanam. FailureSensorIQ: A multi-choice QA dataset for understanding sensor relationships and failure modes.arXiv preprint arXiv:2506.03278, 2025. 11
-
[4]
Padim: a patch distribution modeling framework for anomaly detection and localization
Thomas Defard, Aleksandr Setkov, Angelique Loesch, and Romaric Audigier. Padim: a patch distribution modeling framework for anomaly detection and localization. InInternational conference on pattern recognition, pages 475–489. Springer, 2021
2021
-
[5]
Anna C Doris, Daniele Grandi, Ryan Tomich, Md Ferdous Alam, Mohammadmehdi Ataei, Hyunmin Cheong, and Faez Ahmed. Designqa: A multimodal benchmark for evaluating large language models’ understanding of engineering documentation.Journal of Computing and Information Science in Engineering, 25(2):021009, 2025
2025
-
[6]
LLM-MANUF: An integrated framework of fine-tuning large language models for intelligent decision-making in manufacturing.Advanced Engineering Informatics, 65:103263, 2025
Kaze Du, Bo Yang, Keqiang Xie, Nan Dong, Zhengping Zhang, Shilong Wang, and Fan Mo. LLM-MANUF: An integrated framework of fine-tuning large language models for intelligent decision-making in manufacturing.Advanced Engineering Informatics, 65:103263, 2025
2025
-
[7]
Mavila: Unlocking new potentials in smart manufacturing through vision language models.Journal of Manufacturing Systems, 80:258–271, 2025
Haolin Fan, Chenshu Liu, Neville Elieh Janvisloo, Shijie Bian, Jerry Ying Hsi Fuh, Wen Feng Lu, and Bingbing Li. Mavila: Unlocking new potentials in smart manufacturing through vision language models.Journal of Manufacturing Systems, 80:258–271, 2025
2025
-
[8]
Haolin Fan, Hongji Zhang, Changyu Ma, Tongzi Wu, Jerry Ying Hsi Fuh, and Bingbing Li. Enhancing metal additive manufacturing training with the advanced vision language model: A pathway to immersive augmented reality training for non-experts.Journal of Manufacturing Systems, 75:257–269, 2024
2024
-
[9]
Rodriguez, Nicolas Chapados, David Vazquez, Adriana Romero-Soriano, Reihaneh Rabbany, Perouz Taslakian, Christopher Pal, Spandana Gella, and Sai Rajeswar
Aarash Feizi, Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Kaixin Li, Rabiul Awal, Xing Han Lù, Johan Obando-Ceron, Juan A. Rodriguez, Nicolas Chapados, David Vazquez, Adriana Romero-Soriano, Reihaneh Rabbany, Perouz Taslakian, Christopher Pal, Spandana Gella, and Sai Rajeswar. Grounding computer use agents on human demonstrations, 2025
2025
-
[10]
Huihui Gao, Xiaoran Zhang, Xuejin Gao, Fangyu Li, and Honggui Han. A hierarchical coarse- to-fine fault diagnosis method for industrial processes based on decision fusion of class-specific stacked autoencoders.IEEE Transactions on Instrumentation and Measurement, 2024
2024
-
[11]
IIoT-enabled digital twin for legacy and smart factory machines with LLM integration.Journal of Manufacturing Systems, 80:511–523, 2025
Anuj Gautam, Manish Raj Aryal, Sourabh Deshpande, Shailesh Padalkar, Mikhail Nikolaenko, Ming Tang, and Sam Anand. IIoT-enabled digital twin for legacy and smart factory machines with LLM integration.Journal of Manufacturing Systems, 80:511–523, 2025
2025
-
[12]
A synthesis of decision models for tool management in automated manufacturing.Management Science, 39(5):549–567, 1993
Ann E Gray, Abraham Seidmann, and Kathryn E Stecke. A synthesis of decision models for tool management in automated manufacturing.Management Science, 39(5):549–567, 1993
1993
-
[13]
Wei Guan, Jun Lan, Jian Cao, Hao Tan, Huijia Zhu, and Weiqiang Wang. EMIT: Enhanc- ing MLLMs for industrial anomaly detection via difficulty-aware GRPO.arXiv preprint arXiv:2507.21619, 2025
-
[14]
PCT: Point cloud transformer
Meng-Hao Guo, Jun-Xiong Cai, Zheng-Ning Liu, Tai-Jiang Mu, Ralph R Martin, and Shi-Min Hu. PCT: Point cloud transformer. volume 7, pages 187–199, 2021
2021
-
[15]
Toward Engineering AGI: Benchmarking the Engineering Design Capabilities of LLMs, November 2025
Xingang Guo, Yaxin Li, Xiangyi Kong, Yilan Jiang, Xiayu Zhao, Zhihua Gong, Yufan Zhang, Daixuan Li, Tianle Sang, Beixiao Zhu, et al. Toward engineering AGI: Benchmarking the engineering design capabilities of LLMs.arXiv preprint arXiv:2509.16204, 2025
-
[16]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[17]
CUA-suite: Expert trajectories and pixel-precise grounding for computer-use agents
Xiangru Jian, Shravan Nayak, Kevin Qinghong Lin, Aarash Feizi, Kaixin Li, Patrice Bechard, Spandana Gella, and Sai Rajeswar. CUA-suite: Expert trajectories and pixel-precise grounding for computer-use agents. InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026
2026
-
[18]
LazyVLM: Neuro-symbolic approach to video analytics.arXiv preprint arXiv:2505.21459, 2025
Xiangru Jian, Wei Pang, Zhengyuan Dong, Chao Zhang, and M Tamer Özsu. LazyVLM: Neuro-symbolic approach to video analytics.arXiv preprint arXiv:2505.21459, 2025
-
[19]
InvGC: Robust cross-modal retrieval by inverse graph convo- lution
Xiangru Jian and Yimu Wang. InvGC: Robust cross-modal retrieval by inverse graph convo- lution. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 836–865, Singapore, December 2023. Association for Computational Linguistics. 12
2023
-
[20]
Xi Jiang, Jian Li, Hanqiu Deng, Yong Liu, Bin-Bin Gao, Yifeng Zhou, Jialin Li, Chengjie Wang, and Feng Zheng. MMAD: A comprehensive benchmark for multimodal large language models in industrial anomaly detection.arXiv preprint arXiv:2410.09453, 2024
-
[21]
Product family design and platform- based product development: a state-of-the-art review.Journal of Intelligent Manufacturing, 18(1):5–29, 2007
Jianxin Jiao, Timothy W Simpson, and Zahed Siddique. Product family design and platform- based product development: a state-of-the-art review.Journal of Intelligent Manufacturing, 18(1):5–29, 2007
2007
-
[22]
Leveraging vision-language models for manufacturing feature recognition in computer-aided designs.Journal of Computing and Information Science in Engineering, 25(10):104501, 2025
Muhammad Tayyab Khan, Lequn Chen, Ye Han Ng, Wenhe Feng, Nicholas Yew Jin Tan, and Seung Ki Moon. Leveraging vision-language models for manufacturing feature recognition in computer-aided designs.Journal of Computing and Information Science in Engineering, 25(10):104501, 2025
2025
-
[23]
Yejin Kwon, Daeun Moon, Youngje Oh, and Hyunsoo Yoon. Logicqa: Logical anomaly detection with vision language model generated questions.arXiv preprint arXiv:2503.20252, 2025
-
[24]
Jay Lee and Hanqi Su. A unified industrial large knowledge model framework in industry 4.0 and smart manufacturing.arXiv preprint arXiv:2312.14428, 2023
-
[25]
A survey of state of the art large vision language models: Benchmark evaluations and challenges
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. A survey of state of the art large vision language models: Benchmark evaluations and challenges. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 1587–1606, 2025
2025
-
[26]
A VLM-based Method for Visual Anomaly Detection in Robotic Scientific Laboratories
Shiwei Lin, Chenxu Wang, Xiaozhen Ding, Yi Wang, Boyuan Du, Lei Song, Chenggang Wang, and Huaping Liu. A VLM-based method for visual anomaly detection in robotic scientific laboratories.arXiv preprint arXiv:2506.05405, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine- grained visual classification of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review arXiv 2013
-
[28]
Shravan Nayak, Xiangru Jian, Kevin Qinghong Lin, Juan A. Rodriguez, Montek Kalsi, Rabiul Awal, Nicolas Chapados, M. Tamer Özsu, Aishwarya Agrawal, David Vazquez, Christopher Pal, Perouz Taslakian, Spandana Gella, and Sai Rajeswar. UI-Visio: A desktop-centric GUI benchmark for visual perception and interaction.arXiv preprint arXiv:2503.15661, 2025
-
[29]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[30]
Wei Pang, Kevin Qinghong Lin, Xiangru Jian, Xi He, and Philip Torr. Paper2Poster: Towards multimodal poster automation from scientific papers.arXiv preprint arXiv:2505.21497, 2025
-
[31]
Picard, K
C. Picard, K. M. Edwards, A. C. Doris, B. Man, G. Giannone, M. F. Alam, and F. Ahmed. From concept to manufacturing: Evaluating vision-language models for engineering design.Artificial Intelligence Review, 58(9):288, 2025
2025
-
[32]
Qi, Li Yi, Hao Su, and Leonidas J
Charles R. Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: deep hierarchical feature learning on point sets in a metric space. InProceedings of the 31st International Conference on Neural Information Processing Systems, page 5105–5114, 2017
2017
-
[33]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
2015
-
[34]
Özsu, Siva Reddy, Marco Pedersoli, Yoshua Bengio, Christopher Pal, Issam Laradji, Spandana Gella, Perouz Taslakian, David Vazquez, and Sai Rajeswar
Juan Rodriguez, Xiangru Jian, Siba Smarak Panigrahi, Tianyu Zhang, Aarash Feizi, Abhay Puri, Akshay Kalkunte, François Savard, Ahmed Masry, Shravan Nayak, Rabiul Awal, Mahsa Massoud, Amirhossein Abaskohi, Zichao Li, Suyuchen Wang, Pierre-André Noël, Mats Leon Richter, Saverio Vadacchino, Shubham Agarwal, Sanket Biswas, Sara Shanian, Ying Zhang, Noah Bolge...
2025
-
[35]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022
2022
-
[36]
Manufacturing execution system–a literature review.Production Planning and Control, 20(6):525–539, 2009
B Saenz de Ugarte, Abdelhakim Artiba, and Robert Pellerin. Manufacturing execution system–a literature review.Production Planning and Control, 20(6):525–539, 2009
2009
-
[37]
Robust condition-based produc- tion and maintenance planning for degradation management.Production and Operations Management, 32(12):3951–3967, 2023
Qiuzhuang Sun, Piao Chen, Xin Wang, and Zhi-Sheng Ye. Robust condition-based produc- tion and maintenance planning for degradation management.Production and Operations Management, 32(12):3951–3967, 2023
2023
-
[38]
Optimal inspection and replacement policies for multi-unit systems subject to degradation.IEEE Transactions on Reliability, 67(1):401–413, 2017
Qiuzhuang Sun, Zhi-Sheng Ye, and Nan Chen. Optimal inspection and replacement policies for multi-unit systems subject to degradation.IEEE Transactions on Reliability, 67(1):401–413, 2017
2017
-
[39]
G2sf: Geometry-guided score fusion for multimodal industrial anomaly detection
Chengyu Tao, Xuanming Cao, and Juan Du. G2sf: Geometry-guided score fusion for multimodal industrial anomaly detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20551–20560, 2025
2025
-
[40]
Pointsgrade: Sparse learning with graph representation for anomaly detection by using unstructured 3D point cloud data.IISE Transactions, 57(2):131–144, 2025
Chengyu Tao and Juan Du. Pointsgrade: Sparse learning with graph representation for anomaly detection by using unstructured 3D point cloud data.IISE Transactions, 57(2):131–144, 2025
2025
-
[41]
Anomaly detection for fabricated artifact by using unstructured 3D point cloud data.IISE Transactions, 55(11):1174–1186, 2023
Chengyu Tao, Juan Du, and Tzyy-Shuh Chang. Anomaly detection for fabricated artifact by using unstructured 3D point cloud data.IISE Transactions, 55(11):1174–1186, 2023
2023
-
[42]
Chengyu Tao, Hao Xu, and Juan Du. F2PAD: A general optimization framework for feature- level to pixel-level anomaly detection.arXiv preprint arXiv:2407.06519, 2024
-
[43]
Deep learning for smart manufacturing: Methods and applications.Journal of Manufacturing Systems, 48:144– 156, 2018
Jinjiang Wang, Yulin Ma, Laibin Zhang, Robert X Gao, and Dazhong Wu. Deep learning for smart manufacturing: Methods and applications.Journal of Manufacturing Systems, 48:144– 156, 2018
2018
-
[44]
An LLM-based vision and language cobot navigation approach for human-centric smart manufacturing.Journal of Manufacturing Systems, 75:299– 305, 2024
Tian Wang, Junming Fan, and Pai Zheng. An LLM-based vision and language cobot navigation approach for human-centric smart manufacturing.Journal of Manufacturing Systems, 75:299– 305, 2024
2024
-
[45]
FoundationPose: Unified 6D pose estimation and tracking of novel objects
Bowen Wen, Wei Yang, Jan Kautz, and Stan Birchfield. FoundationPose: Unified 6D pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17868–17879, 2024
2024
-
[46]
PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes
Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. Posecnn: A convo- lutional neural network for 6d object pose estimation in cluttered scenes.arXiv preprint arXiv:1711.00199, 2017
work page Pith review arXiv 2017
-
[47]
Hao Xu, Juan Du, and Andi Wang. Ano-SuPs: Multi-size anomaly detection for manufactured products by identifying suspected patches.arXiv preprint arXiv:2309.11120, 2023
-
[48]
Hao Xu, Xiangru Jian, Xinjian Zhao, Wei Pang, Chao Zhang, Suyuchen Wang, Qixin Zhang, Zhengyuan Dong, Joao Monteiro, Bang Liu, et al. GraphOmni: A comprehensive and extendable benchmark framework for large language models on graph-theoretic tasks.arXiv preprint arXiv:2504.12764, 2025
-
[49]
Modelling of flexible manufacturing system: a review
Anupma Yadav and SC Jayswal. Modelling of flexible manufacturing system: a review. International Journal of Production Research, 56(7):2464–2487, 2018
2018
-
[50]
Set-of-mark prompting unleashes extraordinary visual grounding in GPT-4V, 2023
Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in GPT-4V, 2023
2023
-
[51]
MME-industry: A cross-industry multimodal evaluation benchmark.arXiv preprint arXiv:2501.16688, 2025
Dongyi Yi, Guibo Zhu, Chenglin Ding, Zongshu Li, Dong Yi, and Jinqiao Wang. MME-industry: A cross-industry multimodal evaluation benchmark.arXiv preprint arXiv:2501.16688, 2025. 14
-
[52]
Chat with MES: LLM-driven user interface for manipulating garment manufacturing system through natural language.Journal of Manufacturing Systems, 2025
Zhaolin Yuan, Ming Li, Chang Liu, Fangyuan Han, Haolun Huang, and Hong-Ning Dai. Chat with MES: LLM-driven user interface for manipulating garment manufacturing system through natural language.Journal of Manufacturing Systems, 2025
2025
-
[53]
An LLM-based knowledge and function-augmented approach for optimal design of remanufacturing process.Advanced Engineering Informatics, 65:103206, 2025
Haiyang Zhang, Wei Yan, Huicong Hu, Xumei Zhang, Qingtao Liu, Hong Xia, Yingguang Zhang, and Yuhao Lin. An LLM-based knowledge and function-augmented approach for optimal design of remanufacturing process.Advanced Engineering Informatics, 65:103206, 2025
2025
-
[54]
LogiCode: An LLM-driven framework for logical anomaly detection.IEEE Transactions on Automation Science and Engineering, 2024
Yiheng Zhang, Yunkang Cao, Xiaohao Xu, and Weiming Shen. LogiCode: An LLM-driven framework for logical anomaly detection.IEEE Transactions on Automation Science and Engineering, 2024
2024
-
[55]
Industrial foundation models (IFMs) for intelligent manufacturing: A systematic review.Journal of Manufacturing Systems, 82:420–448, 2025
Shuxuan Zhao, Sichao Liu, Yishuo Jiang, Bo Zhao, Youlong Lv, Jie Zhang, Lihui Wang, and Ray Y Zhong. Industrial foundation models (IFMs) for intelligent manufacturing: A systematic review.Journal of Manufacturing Systems, 82:420–448, 2025
2025
-
[56]
Xinjian Zhao, Wei Pang, Zhongkai Xue, Xiangru Jian, Lei Zhang, Yaoyao Xu, Xiaozhuang Song, Shu Wu, and Tianshu Yu. The underappreciated power of vision models for graph structural understanding.arXiv preprint arXiv:2510.24788, 2025
-
[57]
When vision meets graphs: A survey on graph reasoning and learning.Authorea Preprints, 2026
Xinjian Zhao, Wei Pang, Zhixuan Yu, Xiangru Jian, Xiaozhuang Song, Yaoyao Xu, Zhongkai Xue, Dingshuo Chen, Shu Wu, Philip Torr, et al. When vision meets graphs: A survey on graph reasoning and learning.Authorea Preprints, 2026. 15 Appendix Contents A Extended Related Works, Main Results and Task Description 17 A.1 Related Works . . . . . . . . . . . . . ....
2026
-
[58]
employs graph representations and sparse learning to detect anomalies directly from 3D point clouds. CV models also play a critical role in geometric metrology and robotic manipulation. Key applications include 6D pose estimation for component assembly [ 46] and precise dimensional measurement for quality control. These models provide spatial coordinates ...
-
[59]
A serrated/step block (left side, [0.29, 0.58])
-
[60]
A T-slot bolt (center, [0.45, 0.40])
-
[61]
A strap clamp (right side, [0.70, 0.44])
-
[62]
The standard nut used in a T-slot clamping set is a **flange nut** (or sometimes a coupling nut or standard hex nut, depending on the specific kit)
A nut (bottom right, [0.69, 0.81]). The standard nut used in a T-slot clamping set is a **flange nut** (or sometimes a coupling nut or standard hex nut, depending on the specific kit). A flange nut has a wide flange at one end that acts as an integrated washer, distributing the pressure over a larger area. The part at location B ([0.69, 0.81]) is a nut. H...
-
[63]
This is a required component
Sleeve (leftmost cylindrical part): Part at [0.30, 0.51] (D). This is a required component
-
[64]
This is a required component
Bolt (long threaded part with a conical head): Part at [0.49, 0.47] (C). This is a required component
-
[65]
This is a required component
Nut (large hexagonal part): Part at [0.69, 0.52] (B). This is a required component
-
[66]
This is a required component
Flat Washer (large white/translucent ring): Part at [0.63, 0.43] (E). This is a required component
-
[67]
No part is missing
Small Ring (small metal ring): Part at [0.77, 0.44] (A). This appears to be a small metal washer, likely a Spring Washer (or a second, smaller flat washer). A Spring Washer is a required component. The image contains five parts, which matches the expected number of components (Bolt, Nut, Flat Washer, Spring Washer, Sleeve). However, upon closer inspection...
1900
-
[68]
**Part B [0.41, 0.27] (Top-left connector):** This connector appears to have two ends of the same size (straight union)
-
[69]
**Part D [0.51, 0.44] (Top-right connector):** This connector also appears to have two ends of the same size (straight union)
-
[70]
**Part A [0.59, 0.66] (Bottom-right connector):** This connector appears to have two ends of the same size (straight union)
-
[71]
B" or "D
**Part C [0.32, 0.71] (Bottom-left connector):** This connector appears to have two ends of the same size (straight union). All four parts in the image appear to be straight unions (connecting two tubes of the same diameter, e.g., 8mm to 8mm or 6mm to 6mm). The query specifies a **reducing union (8mm to 6mm)**. Since none of the parts show a clear differe...
-
[72]
**Bolt** (Hex socket cap screw type, different from the references but still a bolt) at approximately [0.43, 0.32] (D)
-
[73]
The nut is at [0.48, 0.24] in the previous example, or here at [0.48, 0.53] (A)
**Nut** at approximately [0.43, 0.32] (D) - Wait, D is the bolt. The nut is at [0.48, 0.24] in the previous example, or here at [0.48, 0.53] (A)
-
[74]
**Sleeve** at approximately [0.50, 0.42] (C)
-
[75]
**Flat Washer** (large) at approximately [0.53, 0.64] (B)
-
[76]
Answer: X
**Small Washer** (likely a Spring Washer or a second Flat Washer, but much smaller than the others) at approximately [0.66, 0.56] (E). Let’s re-examine the components based on the standard assembly and the reference images: * **Reference Images Components:** Bolt (with a conical end), Nut, Sleeve, Flat Washer (large), and Spring Washer (small, split ring)...
-
[77]
**Bolt**: The threaded component with a cylindrical head (Socket Cap Screw style). (Approx. [0.50, 0.42]) - Matches C
-
[78]
**Nut**: The hexagonal threaded fastener. (Approx. [0.48, 0.53]) - Matches A
-
[79]
**Sleeve**: The long cylindrical expansion tube. (Approx. [0.53, 0.64]) - Matches B
-
[80]
**Flat Washer**: The large, solid ring. (Approx. [0.43, 0.32]) - Matches D
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.