Recognition: no theorem link
Personalizing Text-to-Image Generation to Individual Taste
Pith reviewed 2026-05-10 18:02 UTC · model grok-4.3
The pith
A multi-rater dataset lets models predict what one person will like in generated images more accurately than most methods predict average appeal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
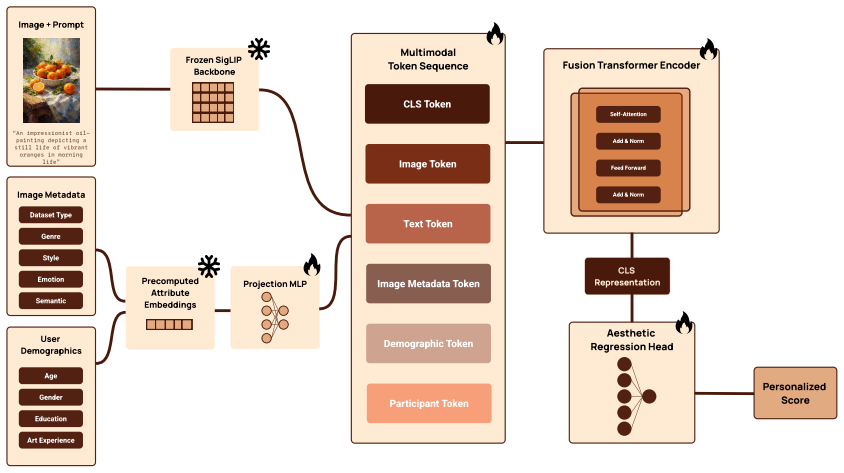
We introduce the PAMELA dataset of 70,000 ratings across 5,000 images generated by state-of-the-art text-to-image models, where each image receives ratings from 15 unique users, and train a personalized reward model jointly on these annotations and existing aesthetic assessment subsets. This model predicts individual liking with higher accuracy than the majority of current state-of-the-art methods predict population-level preferences, and enables simple prompt optimization to steer generations toward an individual user's preferences.
What carries the argument
The personalized reward model trained jointly on the new 15-rater-per-image dataset and existing aesthetic subsets to output user-specific liking predictions.
If this is right
- Simple prompt optimization guided by the personalized predictor can steer text-to-image outputs to better match a specific user's taste.
- The model achieves higher accuracy on individual predictions than most existing methods achieve on population averages.
- High-quality, multi-rater annotations per image are required to model subjective preferences instead of averaged scores.
- Joint training with existing aesthetic datasets supports the personalization task without major performance loss.
Where Pith is reading between the lines
- If individual preferences remain consistent over time, the same model could support persistent user profiles for repeated generation tasks.
- Similar dense multi-rater collection could be applied to personalize other generative domains such as video or 3D content.
- Population-averaged reward models may systematically fail in settings where taste diversity is large, such as creative tools or design assistance.
Load-bearing premise
That 15 ratings per image from distinct users on 5,000 generated images capture stable individual aesthetic preferences and that joint training with existing subsets does not introduce biases that undermine personalization.
What would settle it
If the same users re-rate the same images after several weeks, the personalized model's accuracy on those new individual ratings drops to the level of population-based models.
Figures















read the original abstract
Modern text-to-image (T2I) models generate high-fidelity visuals but remain indifferent to individual user preferences. While existing reward models optimize for "average" human appeal, they fail to capture the inherent subjectivity of aesthetic judgment. In this work, we introduce a novel dataset and predictive framework, called PAMELA, designed to model personalized image evaluations. Our dataset comprises 70,000 ratings across 5,000 diverse images generated by state-of-the-art models (Flux 2 and Nano Banana). Each image is evaluated by 15 unique users, providing a rich distribution of subjective preferences across domains such as art, design, fashion, and cinematic photography. Leveraging this data, we propose a personalized reward model trained jointly on our high-quality annotations and existing aesthetic assessment subsets. We demonstrate that our model predicts individual liking with higher accuracy than the majority of current state-of-the-art methods predict population-level preferences. Using our personalized predictor, we demonstrate how simple prompt optimization methods can be used to steer generations towards individual user preferences. Our results highlight the importance of data quality and personalization to handle the subjectivity of user preferences. We release our dataset and model to facilitate standardized research in personalized T2I alignment and subjective visual quality assessment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PAMELA, a dataset of 70,000 ratings on 5,000 T2I-generated images (each rated by 15 users) spanning art, design, fashion, and photography, along with a reward model trained jointly on this data and existing aesthetic assessment subsets. It claims this personalized model predicts individual user liking with higher accuracy than most current SOTA methods achieve on population-level preferences and demonstrates its utility via prompt optimization to steer generations toward personal taste. The dataset and model are released publicly.
Significance. If substantiated, the work would meaningfully advance personalized T2I alignment by supplying a benchmark dataset that explicitly captures inter-user subjectivity rather than averaging it away, plus a practical demonstration of prompt-based steering. The public release of data and model is a clear strength for reproducibility and follow-on research in subjective visual quality assessment.
major comments (3)
- [Abstract] Abstract: The central claim states that the model 'predicts individual liking with higher accuracy than the majority of current state-of-the-art methods predict population-level preferences,' yet no metrics (accuracy, correlation, etc.), baselines, test splits, cross-validation, or significance tests are described. This information is load-bearing for assessing whether the reported gains reflect true personalization.
- [Abstract] Abstract (dataset description): With 5,000 images each rated by 15 users (70k total ratings), the manuscript provides no statistics on the number of unique users or ratings per user. If most users contribute only a handful of ratings, the model cannot reliably separate stable individual taste from noise or image-specific effects, directly threatening the personalization claim.
- [Abstract] Abstract: The model is 'trained jointly on our high-quality annotations and existing aesthetic assessment subsets,' but no ablation studies, regularization analysis, or embedding comparisons are reported to show that user-specific signals are preserved rather than collapsed toward population averages. This joint objective is load-bearing for the claim that gains arise from personalization rather than the joint training procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract would benefit from greater specificity on metrics, dataset statistics, and training ablations. We will revise the abstract and add supporting material to the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim states that the model 'predicts individual liking with higher accuracy than the majority of current state-of-the-art methods predict population-level preferences,' yet no metrics (accuracy, correlation, etc.), baselines, test splits, cross-validation, or significance tests are described. This information is load-bearing for assessing whether the reported gains reflect true personalization.
Authors: The abstract summarizes the main findings at a high level. The full manuscript describes the evaluation protocol, including accuracy and correlation metrics, baselines, user-based test splits, cross-validation, and significance tests in the experimental section. We will revise the abstract to incorporate key quantitative results and a brief reference to the evaluation setup so that the central claim is supported within the abstract itself. revision: yes
-
Referee: [Abstract] Abstract (dataset description): With 5,000 images each rated by 15 users (70k total ratings), the manuscript provides no statistics on the number of unique users or ratings per user. If most users contribute only a handful of ratings, the model cannot reliably separate stable individual taste from noise or image-specific effects, directly threatening the personalization claim.
Authors: We agree that explicit statistics on unique users and ratings per user are necessary to substantiate the personalization claim. We will add these figures to the revised abstract and expand the dataset description section to report the total number of unique users along with the distribution (minimum, average, and maximum ratings per user). revision: yes
-
Referee: [Abstract] Abstract: The model is 'trained jointly on our high-quality annotations and existing aesthetic assessment subsets,' but no ablation studies, regularization analysis, or embedding comparisons are reported to show that user-specific signals are preserved rather than collapsed toward population averages. This joint objective is load-bearing for the claim that gains arise from personalization rather than the joint training procedure.
Authors: We acknowledge that ablations would help isolate the benefit of the joint objective and confirm preservation of user-specific signals. We will add ablation experiments to the revised manuscript that compare the joint model against single-dataset variants, together with analysis of user embeddings to demonstrate that individual signals are retained rather than averaged out. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new dataset of 70,000 ratings from 15 users per image across 5,000 generated images and trains PAMELA jointly on this data plus existing aesthetic subsets. The central claim of superior individual-liking prediction is evaluated against this newly collected data rather than reducing by construction to prior fitted quantities or self-citations. No self-definitional, fitted-input-called-prediction, or load-bearing self-citation steps are identifiable in the provided text; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User ratings on generated images capture true individual aesthetic preferences
Reference graph
Works this paper leans on
- [1]
-
[2]
Babakhin, Y., Osmulski, R., Ak, R., Moreira, G., Xu, M., Schifferer, B., Liu, B., Oldridge, E.: Llama-embed- nemotron-8b: A universal text embedding model for multilingual and cross-lingual tasks (2025),https://arxiv. org/abs/2511.070253, 6
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., et al.: Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al.: Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073 (2022) 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
OpenAI Technical Report (2023) 1
Betker, J., Goh, G., Jing, L., Brooks, T., Wang, J., Li, L., Ouyang, L., Zhuang, J., Lee, J., Guo, Y., et al.: Improving image generation with better captions. OpenAI Technical Report (2023) 1
2023
-
[6]
Black Forest Labs: FLUX.2.https://github.com/black-forest-labs/flux(2025) 1, 4
2025
-
[7]
In: ECCV (2024) 4
Chen, C., Wang, A., Wu, H., Liao, L., Sun, W., Yan, Q., Lin, W.: Enhancing diffusion models with text-encoder reinforcement learning. In: ECCV (2024) 4
2024
-
[8]
Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
Chen, J., Ge, C., Xie, E., Wu, Y., Yao, L., Ren, X., Wang, Z., Luo, P., Lu, H., Li, Z.: Pixart-sigma: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. arXiv preprint arXiv:2403.04692 (2024) 1
-
[9]
In: CVPR (2024) 3
Chen, Z., Zhang, L., Weng, F., Pan, L., Lan, Z.: Tailored visions: Enhancing text-to-image generation with personalized prompt rewriting. In: CVPR (2024) 3
2024
-
[10]
NIPS (2017) 3
Christiano, P.F., Leike, J., Brown, T., Martic, M., Legg, S., Amodei, D.: Deep reinforcement learning from human preferences. NIPS (2017) 3
2017
-
[11]
In: ICLR (2024) 4
Clark, K., Vicol, P., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards. In: ICLR (2024) 4
2024
-
[12]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Dang, M., Singh, A., Zhou, L., Ermon, S., Song, J.: Personalized preference fine-tuning of diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 8020–8030 (2025) 4
2025
-
[13]
Dunlop, C., Zheng, M., Venkatesh, K., Yanardag, P.: Personalized image editing in text-to-image diffusion models via collaborative direct preference optimization. arXiv preprint arXiv:2511.05616 (2025) 4
-
[14]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. arXiv preprint arXiv:2403.03206 (2024) 1
work page internal anchor Pith review arXiv 2024
-
[15]
NeurIPS (2024) 4
Eyring, L., Karthik, S., Roth, K., Dosovitskiy, A., Akata, Z.: Reno: Enhancing one-step text-to-image models through reward-based noise optimization. NeurIPS (2024) 4
2024
-
[16]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022) 1
work page internal anchor Pith review arXiv 2022
-
[17]
googleblog.com/en/introducing-gemini-2-5-flash-image/(Aug 2025) 4
Google DeepMind: Introducing Gemini 2.5 Flash Image, our state-of-the-art image model.https://developers. googleblog.com/en/introducing-gemini-2-5-flash-image/(Aug 2025) 4
2025
-
[18]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Goree, S., Khoo, W., Crandall, D.J.: Correct for whom? subjectivity and the evaluation of personalized image aesthetics assessment models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 11818–11827 (2023) 3
2023
-
[19]
Grattafiori, A., Dubey, A., Jauhri, A., et al.: The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024), https://arxiv.org/abs/2407.217838
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) 4 15
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Hong, J., Paul, S., Lee, N., Rasul, K., Thorne, J., Jeong, J.: Margin-aware preference optimization for aligning diffusion models without reference. arXiv preprint arXiv:2406.06424 (2024) 4
-
[22]
IEEE Transactions on Multimedia25, 5263–5278 (2022) 3
Hou, J., Lin, W., Yue, G., Liu, W., Zhao, B.: Interaction-matrix based personalized image aesthetics assessment. IEEE Transactions on Multimedia25, 5263–5278 (2022) 3
2022
-
[23]
Karthik, S., Coskun, H., Akata, Z., Tulyakov, S., Ren, J., Kag, A.: Scalable ranked preference optimization for text-to-image generation. arXiv preprint arXiv:2410.18013 (2024) 1, 4
-
[24]
Karthik, S., Roth, K., Mancini, M., Akata, Z.: If at first you don’t succeed, try, try again: Faithful diffusion-based text-to-image generation by selection. arXiv preprint arXiv:2305.13308 (2023) 4
-
[25]
NeurIPS (2023) 3
Kirstain, Y., Polyak, A., Singer, U., Matiana, S., Penna, J., Levy, O.: Pick-a-pic: An open dataset of user preferences for text-to-image generation. NeurIPS (2023) 3
2023
-
[26]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F.: Flux.1 kontext: Flow matching for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025) 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
Lee, H., Phatale, S., Mansoor, H., Lu, K., Mesnard, T., Bishop, C., Carbune, V., Rastogi, A.: Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267 (2023) 3
work page internal anchor Pith review arXiv 2023
-
[28]
arXiv preprint arXiv:2511.19458 (2025),https://arxiv.org/abs/2511.194583, 4
Lee, J., Park, D., Kim, H.J.: Personalized reward modeling for text-to-image generation. arXiv preprint arXiv:2511.19458 (2025),https://arxiv.org/abs/2511.194583, 4
-
[29]
IEEE Transactions on Circuits and Systems for Video Technology (2023) 3
Li, C., Zhang, Z., Wu, H., Sun, W., Min, X., Liu, X., Zhai, G., Lin, W.: AGIQA-3K: An open database for AI-generated image quality assessment. IEEE Transactions on Circuits and Systems for Video Technology (2023) 3
2023
-
[30]
IEEE Transactions on Image Processing29, 3898–3910 (2020) 3
Li, L., Zhu, H., Zhao, S., Ding, G., Lin, W.: Personality-assisted multi-task learning for generic and personalized image aesthetics assessment. IEEE Transactions on Image Processing29, 3898–3910 (2020) 3
2020
-
[31]
Aligning diffusion models by optimizing human utility
Li, S., Kallidromitis, K., Gokul, A., Kato, Y., Kozuka, K.: Aligning diffusion models by optimizing human utility. arXiv preprint arXiv:2404.04465 (2024) 4
-
[32]
In: Proceedings of the 11th International Conference on Quality of Multimedia Experience (QoMEX)
Lin, H., Hosu, V., Saupe, D.: KADID-10k: A large-scale artificially distorted IQA database. In: Proceedings of the 11th International Conference on Quality of Multimedia Experience (QoMEX). pp. 1–3. IEEE (2019). https://doi.org/10.1109/QoMEX.2019.87432523
-
[33]
Flow-GRPO: Training Flow Matching Models via Online RL
Liu, J., Liu, G., Liang, J., Li, Y., Liu, J., Wang, X., Wan, P., Zhang, D., Ouyang, W.: Flow-grpo: Training flow matching models via online rl. arXiv preprint arXiv:2505.05470 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[34]
In: Proceedings of the 26th ACM international conference on Multimedia
Lv, P., Wang, M., Xu, Y., Peng, Z., Sun, J., Su, S., Zhou, B., Xu, M.: Usar: An interactive user-specific aesthetic ranking framework for images. In: Proceedings of the 26th ACM international conference on Multimedia. pp. 1328–1336 (2018) 3
2018
-
[35]
Inference-time scaling for diffusion models beyond scaling denoising steps,
Ma, N., Tong, S., Jia, H., Hu, H., Su, Y.C., Zhang, M., Yang, X., Li, Y., Jaakkola, T., Jia, X., et al.: Inference-time scaling for diffusion models beyond scaling denoising steps. arXiv preprint arXiv:2501.09732 (2025) 4
-
[36]
In: ICCV (2025) 3, 7, 8, 9, 11
Ma, Y., Wu, X., Sun, K., Li, H.: Hpsv3: Towards wide-spectrum human preference score. In: ICCV (2025) 3, 7, 8, 9, 11
2025
-
[37]
In: CVPR Workshops (2025) 3, 4, 6
Maerten, A.S., Chen, L.W., De Winter, S., Bossens, C., Wagemans, J.: Lapis: A novel dataset for personalized image aesthetic assessment. In: CVPR Workshops (2025) 3, 4, 6
2025
-
[38]
Mañas, O., Astolfi, P., Hall, M., Ross, C., Urbanek, J., Williams, A., Agrawal, A., Romero-Soriano, A., Drozdzal, M.: Improving text-to-image consistency via automatic prompt optimization. arXiv preprint arXiv:2403.17804 (2024) 2, 4
-
[39]
In: CVPR (2012) 3
Murray, N., Marchesotti, L., Perronnin, F.: Ava: A large-scale database for aesthetic visual analysis. In: CVPR (2012) 3
2012
-
[40]
In: 2017 IEEE Winter Conference on Applications of Computer Vision (WACV)
Park, K., Hong, S., Baek, M., Han, B.: Personalized image aesthetic quality assessment by joint regression and ranking. In: 2017 IEEE Winter Conference on Applications of Computer Vision (WACV). pp. 1206–1214 (2017). https://doi.org/10.1109/WACV.2017.1393
-
[41]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis (2023) 1
2023
-
[42]
Prabhudesai, M., Goyal, A., Pathak, D., Fragkiadaki, K.: Aligning text-to-image diffusion models with reward backpropagation. arXiv preprint arXiv:2310.03739 (2023) 1, 4
-
[43]
Pressman, J.D., Crowson, K., Simulacra Captions Contributors: Simulacra aesthetic captions. Tech. Rep. Version 1.0, Stability AI (2022),https://github.com/JD-P/simulacra-aesthetic-captions3
2022
-
[44]
arXiv preprint arXiv:2602.02388 (2026) 4
Rajagopalan, R., Dutta, D., Wei, Y.L., Choudhury, R.R.: Personalized image generation via human-in-the-loop bayesian optimization. arXiv preprint arXiv:2602.02388 (2026) 4
-
[45]
In: Proceedings of the IEEE international conference on computer vision
Ren, J., Shen, X., Lin, Z., Mech, R., Foran, D.J.: Personalized image aesthetics. In: Proceedings of the IEEE international conference on computer vision. pp. 638–647 (2017) 3
2017
-
[46]
In: CVPR (2023) 1 16
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: CVPR (2023) 1 16
2023
-
[47]
In: European Conference on Computer Vision
Salehi, S., Shafiei, M., Yeo, T., Bachmann, R., Zamir, A.: Viper: Visual personalization of generative models via individual preference learning. In: European Conference on Computer Vision. pp. 391–406. Springer (2024) 4
2024
-
[48]
com / christophschuhmann / improved - aesthetic-predictor(2022) 7
Schuhmann, C.: Improved aesthetic predictor.https : / / github . com / christophschuhmann / improved - aesthetic-predictor(2022) 7
2022
-
[49]
NeurIPS (2022) 2
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large-scale dataset for training next generation image-text models. NeurIPS (2022) 2
2022
-
[50]
Sheikh, H.R., Sabir, M.F., Bovik, A.C.: A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Transactions on Image Processing15(11), 3440–3451 (2006).https://doi.org/10.1109/TIP. 2006.8819593
work page doi:10.1109/tip 2006
-
[51]
Knowledge-Based Systems294, 111749 (2024) 3
Shi, H., Guo, J., Ke, Y., Wang, K., Yang, S., Qin, F., Chen, L.: Personalized image aesthetics assessment based on graph neural network and collaborative filtering. Knowledge-Based Systems294, 111749 (2024) 3
2024
-
[52]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., Hénaff, O., Harmsen, J., Steiner, A., Zhai, X.: SigLIP 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features (2025),https://arxiv.org/ abs/2502.147863, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Uehara, M., Zhao, Y., Black, K., Hajiramezanali, E., Scalia, G., Diamant, N.L., Tseng, A.M., Biancalani, T., Levine,S.:Fine-tuningofcontinuous-timediffusionmodelsasentropy-regularizedcontrol(2024),https://arxiv. org/abs/2402.151944
-
[54]
In: CVPR (2024) 1, 4
Wallace, B., Dang, M., Rafailov, R., Zhou, L., Lou, A., Purushwalkam, S., Ermon, S., Xiong, C., Joty, S., Naik, N.: Diffusion model alignment using direct preference optimization. In: CVPR (2024) 1, 4
2024
-
[55]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Wu, H., Zhang, Z., Zhang, W., Chen, C., Liao, L., Li, C., Gao, Y., Wang, A., Zhang, E., Sun, W., et al.: Q-align: Teaching lmms for visual scoring via discrete text-defined levels. In: arXiv preprint arXiv:2312.17090 (2024) 3, 7, 8, 9, 11
work page internal anchor Pith review arXiv 2024
-
[56]
Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023) 3
work page internal anchor Pith review arXiv 2023
-
[57]
In: ICCV (2023) 3
Wu, X., Sun, K., Zhu, F., Zhao, R., Li, H.: Better aligning text-to-image models with human preference. In: ICCV (2023) 3
2023
-
[58]
NeurIPS (2023) 3, 7
Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. NeurIPS (2023) 3, 7
2023
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yang, Y., Xu, L., Li, L., Qie, N., Li, Y., Zhang, P., Guo, Y.: Personalized image aesthetics assessment with rich attributes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19861–19869 (2022) 3, 6
2022
-
[60]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
You, Z., Cai, X., Gu, J., Xue, T., Dong, C.: Teaching large language models to regress accurate image quality scores using score distribution. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14483–14494 (2025) 3, 7
2025
-
[61]
In: CVPR (2024) 3
Zhang, S., Wang, B., Wu, J., Li, Y., Gao, T., Zhang, D., Wang, Z.: Learning multi-dimensional human preference for text-to-image generation. In: CVPR (2024) 3
2024
-
[62]
In: ECCV (2024) 4
Zhang, Y., Tzeng, E., Du, Y., Kislyuk, D.: Large-scale reinforcement learning for diffusion models. In: ECCV (2024) 4
2024
-
[63]
IEEE Transactions on Multimedia25, 179–190 (2021) 3
Zhu, H., Zhou, Y., Li, L., Li, Y., Guo, Y.: Learning personalized image aesthetics from subjective and objective attributes. IEEE Transactions on Multimedia25, 179–190 (2021) 3
2021
-
[64]
how beautiful the image is, how much they like it, prefer it and are drawn to it
Zhu, H., Zhou, Y., Shao, Z., Du, W., Wang, G., Li, Q.: Personalized image aesthetics assessment via multi- attribute interactive reasoning. Mathematics10(22), 4181 (2022) 3 17 A PAM∃LA Predictor A.1 Ablations T able 3:Ablation study results on seen and unseen users. Unseen users are matched via kNN (k=15, top-K=5, τ=0.1). The generalization gap is defined...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.