Recognition: unknown
Cross-Tokenizer LLM Distillation through a Byte-Level Interface
Pith reviewed 2026-05-10 17:18 UTC · model grok-4.3
The pith
Converting teacher outputs to byte-level probabilities lets a simple decoder head enable competitive cross-tokenizer distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By mapping a teacher's output distribution over its own tokens onto byte-level probabilities and training through an added lightweight byte decoder head on the student, the distillation process becomes tokenizer-agnostic. Experiments across multiple tasks show this Byte-Level Distillation matches or exceeds the performance of more elaborate cross-tokenizer methods on several benchmarks while using models from 1B to 8B parameters.
What carries the argument
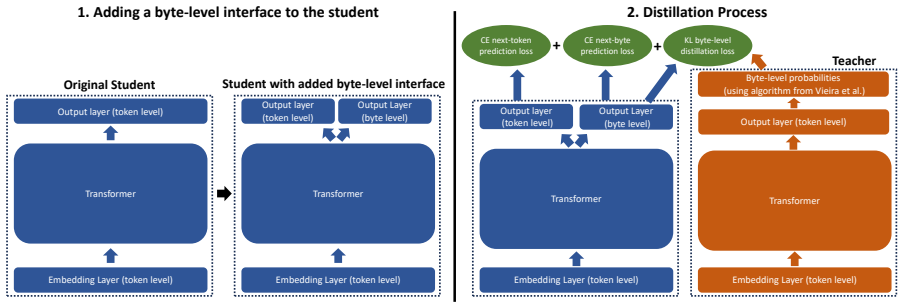
The byte-level probability conversion combined with a lightweight byte decoder head that creates a shared distillation interface independent of each model's tokenizer.
If this is right
- The approach scales to model sizes between 1B and 8B parameters without requiring tokenizer-specific adjustments.
- Distillation pipelines become simpler because heuristic vocabulary mappings are no longer needed.
- The byte level serves as a workable common ground that captures sufficient predictive information for language modeling tasks.
- Consistent gains do not appear on every task, leaving cross-tokenizer distillation as an open problem.
Where Pith is reading between the lines
- Teams could apply the same byte conversion to adapt a fixed teacher to entirely new tokenizers without retraining the core model.
- The method might extend to cross-lingual or cross-domain settings where tokenizers differ sharply.
- Further gains could come from combining the byte interface with existing alignment techniques rather than replacing them.
Load-bearing premise
Converting token probabilities to byte probabilities preserves enough of the teacher's knowledge that the student can learn effectively without major information loss or extensive extra training.
What would settle it
A controlled experiment in which Byte-Level Distillation falls well below sophisticated cross-tokenizer methods on a benchmark where those methods already succeed would show the byte interface loses critical signal.
Figures

read the original abstract
Cross-tokenizer distillation (CTD), the transfer of knowledge from a teacher to a student language model when the two use different tokenizers, remains a largely unsolved problem. Existing approaches rely on heuristic strategies to align mismatched vocabularies, introducing considerable complexity. In this paper, we propose a simple but effective baseline called Byte-Level Distillation (BLD) which enables CTD by operating at a common interface across tokenizers: the byte level. In more detail, we convert the teacher's output distribution to byte-level probabilities, attach a lightweight byte-level decoder head to the student, and distill through this shared byte-level interface. Despite its simplicity, BLD performs competitively with--and on several benchmarks surpasses--significantly more sophisticated CTD methods, across a range of distillation tasks with models from 1B to 8B parameters. Our results suggest that the byte level is a natural common ground for cross-tokenizer knowledge transfer, while also highlighting that consistent improvements across all tasks and benchmarks remain elusive, underscoring that CTD is still an open problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Byte-Level Distillation (BLD) as a simple baseline for cross-tokenizer distillation (CTD) between LLMs with mismatched vocabularies. It converts the teacher's token-level output distribution to byte-level probabilities, attaches a lightweight byte-level decoder head to the student, and performs distillation at this shared byte interface. The central empirical claim is that BLD performs competitively with—and on several benchmarks surpasses—more sophisticated CTD methods across distillation tasks involving models from 1B to 8B parameters, suggesting the byte level provides a natural common ground for knowledge transfer while noting that consistent gains remain elusive.
Significance. If the results hold under rigorous verification, the work supplies a valuable, low-complexity baseline for CTD research. It demonstrates that a byte-level interface can sidestep heuristic vocabulary alignment without sacrificing much performance, thereby lowering the barrier for future comparisons and highlighting that CTD is still an open problem rather than a solved one. The empirical scope (1B–8B models, multiple tasks) adds practical relevance for practitioners working with heterogeneous tokenizers.
major comments (3)
- [Method (byte-level probability conversion)] The central claim that BLD preserves sufficient teacher knowledge rests on the byte-level conversion step, yet the manuscript provides no explicit quantification of information loss (e.g., entropy increase or KL divergence between original token and derived byte distributions). Without this, it is impossible to rule out that the lightweight decoder head is compensating for smeared probability mass rather than simply learning a new interface.
- [Experiments] The abstract and experimental description report competitive or superior results but omit exact benchmark names, baseline implementations, number of runs, statistical significance tests, or ablation studies on the byte decoder head. This absence makes it difficult to assess whether the reported gains are robust or attributable to the byte interface itself.
- [Method (lightweight byte decoder head)] The claim that BLD is 'simple' and 'parameter-free' at the interface level is undercut if the byte decoder head requires non-trivial training or hyperparameter tuning to recover tokenizer-specific distinctions; the manuscript should clarify the training cost and capacity of this head relative to the student.
minor comments (2)
- [Method] Notation for byte-level probabilities (e.g., whether marginalization is over tokens or token sequences) should be formalized with a short equation or pseudocode for reproducibility.
- [Figures/Tables] Figure or table captions should explicitly list the model sizes, tokenizers, and datasets used in each comparison to allow quick cross-reference with the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Method (byte-level probability conversion)] The central claim that BLD preserves sufficient teacher knowledge rests on the byte-level conversion step, yet the manuscript provides no explicit quantification of information loss (e.g., entropy increase or KL divergence between original token and derived byte distributions). Without this, it is impossible to rule out that the lightweight decoder head is compensating for smeared probability mass rather than simply learning a new interface.
Authors: We agree that explicit quantification of information loss would strengthen the central claim. In the revised manuscript we will add a dedicated paragraph (or short subsection) in the Method section reporting KL divergence and entropy increase between the teacher's original token-level distribution and the derived byte-level distribution, computed on held-out samples from the models used in our experiments. This analysis will be performed post-hoc on existing teacher outputs and included with the next version. revision: yes
-
Referee: [Experiments] The abstract and experimental description report competitive or superior results but omit exact benchmark names, baseline implementations, number of runs, statistical significance tests, or ablation studies on the byte decoder head. This absence makes it difficult to assess whether the reported gains are robust or attributable to the byte interface itself.
Authors: We acknowledge that additional experimental details are needed for reproducibility and assessment. We will expand both the abstract and the Experiments section to explicitly name all benchmarks, describe baseline re-implementations (with references), report the number of runs performed, include statistical significance testing, and add ablation studies isolating the byte decoder head. These changes will appear in the main text and a new supplementary table. revision: yes
-
Referee: [Method (lightweight byte decoder head)] The claim that BLD is 'simple' and 'parameter-free' at the interface level is undercut if the byte decoder head requires non-trivial training or hyperparameter tuning to recover tokenizer-specific distinctions; the manuscript should clarify the training cost and capacity of this head relative to the student.
Authors: We will revise the Method section to clarify the byte decoder head's design, parameter count, training procedure, and computational cost relative to the student model. The head is intentionally lightweight; we will quantify its size and training overhead to show that the core interface remains simple and avoids vocabulary-alignment heuristics. This addresses the concern while preserving the paper's emphasis on simplicity at the distillation interface. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper proposes BLD as a simple empirical baseline: convert teacher token probabilities to byte-level, attach a lightweight decoder head, and distill. No equations, derivations, or 'predictions' are presented that reduce to inputs by construction. Competitiveness claims rest on experimental benchmarks across model sizes, not on fitted parameters renamed as results or self-citations that bear the central load. The approach is self-contained as a practical method without self-definitional loops or imported uniqueness theorems. This is the expected non-finding for an empirical methods paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SimCT: Recovering Lost Supervision for Cross-Tokenizer On-Policy Distillation
SimCT recovers discarded teacher signal in cross-tokenizer on-policy distillation by enlarging supervision to jointly realizable multi-token continuations, yielding consistent gains on math reasoning and code generati...
Reference graph
Works this paper leans on
-
[1]
From bytes to ideas: Language modeling with autoregressive u-nets
Openmathinstruct-2: Accelerating AI for math with massive open-source instruction data. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS’24. Mathurin Videau, Badr Youbi Idrissi, Alessandro Leite, Marc Schoenauer, Olivier Teytaud, and David Lopez-Paz. 2025. From bytes to ideas: Language modeling with autoregressive u-nets.Preprint, arXiv:2506...
-
[2]
We then looked at training and val- idation losses over both bytes and tokens
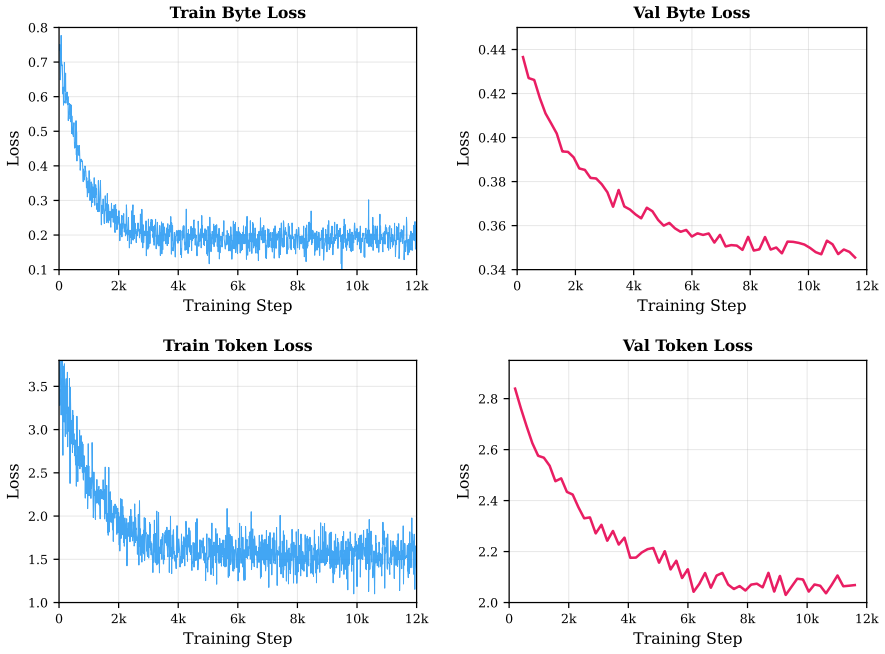
on a subset the TULU-3 dataset (Lambert et al., 2024). We then looked at training and val- idation losses over both bytes and tokens. We re- port the plots in Figure 2. We observe that, not only do the training and validation losses decrease smoothly for the byte level, but, surprisingly, they decrease also for the token level, demonstrating the effective...
2024
-
[3]
The beam maintains a set of can- didate tokenization paths, each with an associ- ated probability weight
Initialization:Create a beam state with pa- rameters K (beam width) and ϵ (pruning threshold). The beam maintains a set of can- didate tokenization paths, each with an associ- ated probability weight. 2.For each byte positioni: • Compute distribution:Call logp_next() to obtain the log prob- ability distribution over the next 256 possible byte values. This...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.