Recognition: no theorem link
SimCT: Recovering Lost Supervision for Cross-Tokenizer On-Policy Distillation
Pith reviewed 2026-05-11 02:57 UTC · model grok-4.3
The pith
SimCT restores supervision lost under heterogeneous tokenizers by supervising over short multi-token continuations in on-policy distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
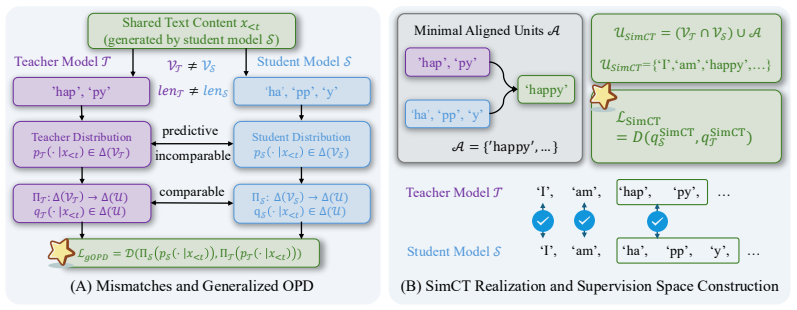
By comparing teacher and student predictions over short multi-token continuations that both can realize, SimCT recovers the supervision signal discarded by exact shared-token matching in cross-tokenizer on-policy distillation, and these multi-token units preserve teacher-student distinctions that coarser interfaces remove.
What carries the argument
short multi-token continuations as the finest jointly tokenizable supervision interface
If this is right
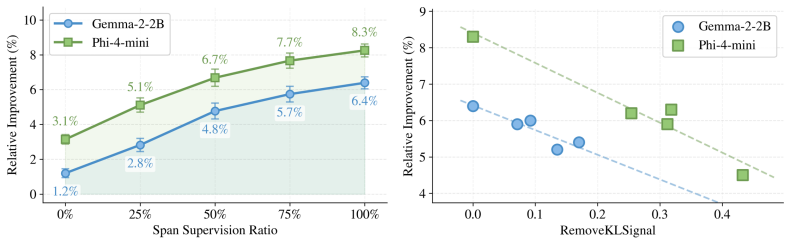
- SimCT yields consistent gains over shared-vocabulary OPD and other cross-tokenizer baselines on math reasoning and code generation benchmarks.
- Ablations confirm the gains come from recovering supervision discarded by exact shared-token matching.
- Coarser alternatives to these units remove useful distinctions for on-policy learning.
Where Pith is reading between the lines
- This suggests exact token alignment is not required for effective distillation when short continuations provide a common interface.
- The same recovery principle may apply to other distillation settings that currently discard mismatched positions.
Load-bearing premise
Short multi-token continuations supply teacher-student distinctions that are useful for on-policy learning and free of misalignment noise that would degrade the student.
What would settle it
A controlled experiment on a benchmark where tokenizer differences are extreme, showing that SimCT either matches or underperforms shared-token OPD due to introduced noise.
Figures

read the original abstract
On-policy distillation (OPD) is a standard tool for transferring teacher behavior to a smaller student, but it implicitly assumes that teacher and student predictions are comparable token by token, an assumption that fails whenever the two models tokenize the same text differently. Under heterogeneous tokenizers, exact shared-token matching silently discards a large fraction of the teacher signal at precisely the positions where vocabularies disagree. We propose \textbf{\underline{Sim}ple \underline{C}ross-\underline{T}okenizer OPD (SimCT)}, which restores this signal by enlarging the supervision space: alongside shared tokens, SimCT compares teacher and student over short multi-token continuations that both tokenizers can realize, leaving the OPD loss form itself unchanged. We show that these units are the finest jointly tokenizable supervision interface, and that coarser alternatives remove teacher-student distinctions that are useful for on-policy learning. Across three heterogeneous teacher-student pairs on mathematical reasoning and code-generation benchmarks, SimCT shows consistent gains over shared-vocabulary OPD and representative cross-tokenizer baselines, with ablations confirming that the improvements come from recovering supervision discarded by exact shared-token matching. Code is available at \href{https://github.com/sunjie279/SimCT-}{https://github.com/sunjie279/SimCT-}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SimCT for on-policy distillation (OPD) between teacher and student models with heterogeneous tokenizers. It enlarges the supervision space to include short multi-token continuations realizable by both tokenizers alongside exact shared tokens, without altering the OPD loss form. The authors argue these units form the finest jointly tokenizable supervision interface, demonstrate consistent gains over shared-vocabulary OPD and cross-tokenizer baselines on mathematical reasoning and code-generation benchmarks across three heterogeneous pairs, and use ablations to attribute improvements to recovery of supervision discarded by exact matching. Code is released.
Significance. If the central claim holds, SimCT offers a practical solution to a common limitation in LLM distillation where tokenizer mismatch discards teacher signal. The empirical consistency across tasks and the explicit code release strengthen the contribution by enabling verification. The approach preserves the standard OPD loss while modifying only the supervision units, which could generalize to other heterogeneous settings if the no-misalignment assumption is validated.
major comments (2)
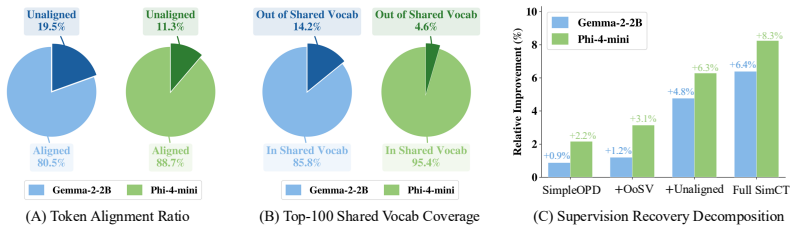
- [Abstract, §3] Abstract and method description: the central assumption that short multi-token continuations recover clean supervision 'free of misalignment noise' is load-bearing for leaving the OPD loss unchanged, yet the selection process aligns only on surface strings or token sequences without reported semantic equivalence checks or divergence quantification. This risks introducing contradictory targets precisely where vocabularies disagree, directly threatening the claim that gains derive solely from recovered exact-match discards.
- [§4.3] §4.3, ablation results: while ablations confirm gains from including multi-token units over exact shared-token matching, they do not report the fraction of selected continuations exhibiting segmentation divergence or measure any resulting target conflict rate, leaving open whether the observed improvements could be sensitive to implementation choices in continuation selection.
minor comments (2)
- [Abstract] The abstract states 'consistent gains' but does not specify the exact metrics, statistical significance thresholds, or number of runs; these details should be added for clarity.
- [§3] Notation for the enlarged supervision space (shared tokens vs. multi-token continuations) could be formalized with an equation in the method section to improve precision.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment point by point below, providing our response and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and method description: the central assumption that short multi-token continuations recover clean supervision 'free of misalignment noise' is load-bearing for leaving the OPD loss unchanged, yet the selection process aligns only on surface strings or token sequences without reported semantic equivalence checks or divergence quantification. This risks introducing contradictory targets precisely where vocabularies disagree, directly threatening the claim that gains derive solely from recovered exact-match discards.
Authors: The selection of multi-token continuations is performed by exact surface-string matching on the teacher's generated text, ensuring that both tokenizers realize the identical linguistic continuation. Consequently, the OPD loss compares the teacher and student probabilities assigned to the same text-level event rather than to potentially misaligned token sequences. This recovers the discarded supervision signal without introducing contradictory targets, as the supervision unit is defined in the shared string space. We acknowledge that explicit quantification of segmentation divergence was not reported. In the revised manuscript we will add this analysis (including divergence rates and any observed target conflict statistics) to the method and ablation sections to further substantiate the assumption. revision: yes
-
Referee: [§4.3] §4.3, ablation results: while ablations confirm gains from including multi-token units over exact shared-token matching, they do not report the fraction of selected continuations exhibiting segmentation divergence or measure any resulting target conflict rate, leaving open whether the observed improvements could be sensitive to implementation choices in continuation selection.
Authors: We agree that reporting the fraction of continuations with segmentation divergence and any associated target conflict rates would increase transparency and address potential sensitivity concerns. In the revised version we will augment §4.3 with these statistics across the evaluated teacher-student pairs, confirming that the observed gains remain attributable to recovered supervision rather than implementation artifacts. revision: yes
Circularity Check
No circularity: empirical validation of new supervision interface
full rationale
The paper defines SimCT as an enlargement of the supervision space to short multi-token continuations (both tokenizers can realize them) while leaving the OPD loss form unchanged. It then reports benchmark gains and ablations attributing improvements to recovered exact-match discards. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the 'finest jointly tokenizable' claim is presented as an empirical and conceptual finding supported by heterogeneous tokenizer experiments rather than definitional equivalence. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Distilling the Knowledge in a Neural Network
Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network.arXiv preprint, arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models.Transactions of the Association for Computational Linguistics (TACL), 2024
work page 2024
-
[3]
Caixia Yan, Xiaojun Chang, Minnan Luo, Huan Liu, Xiaoqin Zhang, and Qinghua Zheng
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distillation of large language models.arXiv preprint, arXiv:2402.13116, 2024
-
[4]
Chuanpeng Yang, Wang Lu, Yao Zhu, Yidong Wang, Qian Chena, Chenlong Gao, Bingjie Yan, and Yiqiang Chen. Survey on knowledge distillation for large language models: Methods, evaluation, and application.arXiv preprint, arXiv:2407.01885, 2024
-
[5]
DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. InProceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing (NeurIPS 2019), Vancouver, Canada, 2019
work page 2019
-
[6]
TinyBERT: Distilling BERT for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: Distilling BERT for natural language understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online Event, 2020
work page 2020
-
[7]
Compact language models via pruning and knowledge distillation
Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, and Pavlo Molchanov. Compact language models via pruning and knowledge distillation. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024
work page 2024
-
[8]
Scheduled sampling for sequence prediction with recurrent neural networks
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled sampling for sequence prediction with recurrent neural networks. InAdvances in Neural Information Processing Systems 28 (NeurIPS 2015), 2015
work page 2015
-
[9]
Bridging the gap between training and inference for neural machine translation
Wen Zhang, Yang Feng, Fandong Meng, Di You, and Qun Liu. Bridging the gap between training and inference for neural machine translation. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019), pages 4334–4343, Florence, Italy, 2019
work page 2019
-
[10]
Autoregressive knowledge distillation through imitation learning
Alexander Lin, Jeremy Wohlwend, Howard Chen, and Tao Lei. Autoregressive knowledge distillation through imitation learning. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), pages 6121–6133, Online Event, 2020
work page 2020
-
[11]
SequenceMatch: Imitation learning for autoregressive sequence modelling with backtracking
Chris Cundy and Stefano Ermon. SequenceMatch: Imitation learning for autoregressive sequence modelling with backtracking. InProceedings of the 12th International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 2024
work page 2024
-
[12]
Stéphane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS 2011), pages 627–635, Fort Lauderdale, FL, USA, 2011
work page 2011
-
[13]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InProceedings of the 12th International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 2024
work page 2024
-
[14]
MiniLLM: On-policy distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: On-policy distillation of large language models. InProceedings of the 12th International Conference on Learning Representations (ICLR 2024), Vienna, Austria, 2024. 10
work page 2024
-
[15]
DistiLLM: Towards streamlined distillation for large language models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. DistiLLM: Towards streamlined distillation for large language models. InProceedings of the 41st International Conference on Machine Learning (ICML 2024), volume 235, Vienna, Austria, 2024
work page 2024
-
[16]
DistiLLM-2: A contrastive approach boosts the distillation of LLMs
Jongwoo Ko, Tianyi Chen, Sungnyun Kim, Tianyu Ding, Luming Liang, Ilya Zharkov, and Se-Young Yun. DistiLLM-2: A contrastive approach boosts the distillation of LLMs. In Proceedings of the 42nd International Conference on Machine Learning (ICML 2025), 2025
work page 2025
-
[17]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint, arXiv:2511.10643, 2025
-
[18]
Yecheng Wu, Song Han, and Hai Cai. Lightning OPD: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint, arXiv:2604.13010, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint, arXiv:2601.07155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy dis- tillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint, arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint, arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[22]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint, arXiv:2604.00626, 2026
work page internal anchor Pith review arXiv 2026
-
[23]
Nicolas Boizard, Kevin El Haddad, Céline Hudelot, and Pierre Colombo. Towards cross- tokenizer distillation: The universal logit distillation loss for LLMs.Transactions on Machine Learning Research (TMLR), 2025
work page 2025
-
[24]
Dual-space knowledge distillation for large language models
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, and Jinan Xu. Dual-space knowledge distillation for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), pages 18164–18181, Miami, Florida, USA, 2024
work page 2024
-
[25]
CTPD: Cross-tokenizer preference distillation
Truong Nguyen, Phi Van Dat, Ngan Nguyen, Linh Ngo Van, Trung Le, and Thanh Hong Nguyen. CTPD: Cross-tokenizer preference distillation. InProceedings of the 40th AAAI Conference on Artificial Intelligence (AAAI 2026), Philadelphia, PA, USA, 2026
work page 2026
-
[26]
Cross-Tokenizer LLM Distillation through a Byte-Level Interface
Avyav Kumar Singh, Yen-Chen Wu, Alexandru Cioba, Alberto Bernacchia, and Davide Buffelli. Cross-tokenizer LLM distillation through a byte-level interface.arXiv preprint, arXiv:2604.07466, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Cross-tokenizer likelihood scoring algorithms for language model distillation
Buu Phan, Ashish Khisti, and Karen Ullrich. Cross-tokenizer likelihood scoring algorithms for language model distillation. InProceedings of the 14th International Conference on Learning Representations (ICLR 2026), Rio de Janeiro, Brazil, 2026
work page 2026
-
[28]
Xiao Cui, Mo Zhu, Yulei Qin, Liang Xie, Wengang Zhou, and Houqiang Li. Multi-level optimal transport for universal cross-tokenizer knowledge distillation on language models. In Proceedings of the 39th AAAI Conference on Artificial Intelligence (AAAI 2025), Philadelphia, PA, 2025
work page 2025
-
[29]
Unlocking on-policy distillation for any model family.Hugging Face Tech- nical Report, 2025
César Miguel Patiño, Kashif Rasul, Quentin Gallouédec, Ben Burtenshaw, Sergio Paniego, Vaishakh Srivastav, Thomas Frere, Edward Beeching, Lewis Tunstall, Leandro von Werra, and Thomas Wolf. Unlocking on-policy distillation for any model family.Hugging Face Tech- nical Report, 2025. https://huggingfaceh4-on-policy-distillation.hf. space/unlocking-on-policy...
work page 2025
-
[30]
A dual-space framework for general knowledge distillation of large language models
Xue Zhang, Songming Zhang, Yunlong Liang, Fandong Meng, Yufeng Chen, Jinan Xu, and Jie Zhou. A dual-space framework for general knowledge distillation of large language models. arXiv preprint, arXiv:2504.11426, 2025. 11
-
[31]
Universal cross-tokenizer distil- lation via approximate likelihood matching
Benjamin Minixhofer, Ivan Vuli´c, and Edoardo Maria Ponti. Universal cross-tokenizer distil- lation via approximate likelihood matching. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2025), 2025
work page 2025
-
[32]
Enhancing cross-tokenizer knowledge distillation with contextual dynamical mapping
Yijie Chen, Yijin Liu, Fandong Meng, Yufeng Chen, Jinan Xu, and Jie Zhou. Enhancing cross-tokenizer knowledge distillation with contextual dynamical mapping. InFindings of the Association for Computational Linguistics: ACL 2025, pages 8005–8018, Vienna, Austria, 2025
work page 2025
-
[33]
arXiv preprint arXiv:2603.07079 , year =
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint, arXiv:2603.07079, 2026
-
[34]
https://thinkingmachines.ai/blog/ on-policy-distillation/
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/ on-policy-distillation
-
[35]
Rethinking kullback- leibler divergence in knowledge distillation for large language models
Taiqiang Wu, Chaofan Tao, Jiahao Wang, Zhe Zhao, and Ngai Wong. Rethinking kullback- leibler divergence in knowledge distillation for large language models. InProceedings of the 31st International Conference on Computational Linguistics (COLING 2025), 2025
work page 2025
-
[36]
Hoang-Chau Luong, Dat Ba Tran, and Lingwei Chen. Diversity-aware reverse kullback-leibler divergence for large language model distillation.arXiv preprint, arXiv:2604.00223, 2026
-
[37]
Yeongmin Kim, Donghyeok Shin, Mina Kang, Byeonghu Na, and Il-Chul Moon. Distillation of large language models via concrete score matching.arXiv preprint, arXiv:2509.25837, 2025
-
[38]
arXiv preprint arXiv:2510.24021 , year =
Haiduo Huang, Jiangcheng Song, Yadong Zhang, and Pengju Ren. SelecTKD: Selective token-weighted knowledge distillation for LLMs.arXiv preprint, arXiv:2510.24021, 2025
-
[39]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. TIP: Token importance in on-policy distillation.arXiv preprint, arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Anh Duc Le, Tu Vu, Nam Le Hai, Nguyen Thi Ngoc Diep, Linh Ngo Van, Trung Le, and Thien Huu Nguyen. CoT2Align: Cross-chain of thought distillation via optimal transport alignment for language models with different tokenizers.arXiv preprint, arXiv:2502.16806, 2025
-
[41]
Stella Eva Tsiapali, Cong-Thanh Do, and Kate Knill. Dual-space knowledge distillation with key-query matching for large language models with vocabulary mismatch. InProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2026), 2026
work page 2026
-
[42]
Haebin Shin, Lei Ji, Xiao Liu, and Yeyun Gong. Overcoming vocabulary mismatch: V ocabulary- agnostic teacher guided language modeling.arXiv preprint, arXiv:2503.19123, 2025
-
[43]
Hai An Vu, Minh-Phuc Truong, Tu Vu, and Linh Ngo Van. MoL: Mixture of layers in cross- tokenizer embedding model distillation.Knowledge-Based Systems, 2026
work page 2026
-
[44]
Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V . Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason ...
work page internal anchor Pith review arXiv 2016
-
[45]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Microsoft: Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, Dong Chen, Dongdong Chen, Jun-Kun Chen, Weizhu Chen, Yen-Chun Chen, Yi-ling Chen, Qi Dai, Xiyang Dai, Ruchao Fan, Mei Gao, Min Gao, Amit Garg, Abhishek Goswami, Junheng Hao, Amr Hendy, Yuxuan...
work page internal anchor Pith review arXiv 2025
-
[47]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.arXiv preprint, arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint, arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
arXiv preprint arXiv:2402.14830 , year=
Arindam Mitra, Hamed Khanpour, Corby Rosset, and Ahmed Awadallah. Orca-math: Unlocking the potential of SLMs in grade school math.arXiv preprint, arXiv:2402.14830, 2024
-
[50]
Openmathinstruct-1: A 1.8 million math instruction tuning dataset
Shubham Toshniwal, Ivan Moshkov, Sean Narenthiran, Daria Gitman, Fei Jia, and Igor Git- man. OpenMathInstruct-1: A 1.8 million math instruction tuning dataset.arXiv preprint, arXiv:2402.10176, 2024
-
[51]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems 34 (NeurIPS 2021), 2021
work page 2021
- [52]
-
[53]
Kodcode: A diverse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. KodCode: A di- verse, challenging, and verifiable synthetic dataset for coding.arXiv preprint, arXiv:2503.02951, 2025
-
[54]
Taco: Topics in algorithmic code generation dataset.arXiv preprint arXiv:2312.14852, 2023
Rongao Li, Jie Fu, Bo-Wen Zhang, Tao Huang, Zhihong Sun, Chen Lyu, Guang Liu, Zhi Jin, and Ge Li. TACO: Topics in algorithmic COde generation dataset.arXiv preprint, arXiv:2312.14852, 2023
-
[55]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
work page 2022
-
[56]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InProceedings of the 12th International Conference on Learning Representations (ICLR 2024), 2024
work page 2024
-
[57]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models.arXiv preprint, arXiv:2108.07732, 2021. 13
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[58]
LiveCodeBench: Holistic and contamina- tion free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamina- tion free evaluation of large language models for code. InProceedings of the 13th International Conference on Learning Representations (ICLR 2025), 2025
work page 2025
-
[59]
Songming Zhang, Xue Zhang, Tong Zhang, Bojie Hu, Yufeng Chen, and Jinan Xu. KDFlow: A user-friendly and efficient knowledge distillation framework for large language models.arXiv preprint, arXiv:2603.01875, 2026
-
[60]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[61]
Since 10000 = 7×1428 + 4 , the remainder is 4
= 10000 . Since 10000 = 7×1428 + 4 , the remainder is 4. Answer:4 ✓Correct SimpleOPD Correctly identifies 100 terms and computes the sum as 10000. However, makes an arithmetic error in the final modular division step, computing10000÷7 = 1428remainder3instead of4. Answer:3 ✗Incorrect ALM Incorrectly counts the number of terms as 199 (confusing the last ter...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.