Recognition: no theorem link
ConsistRM: Improving Generative Reward Models via Consistency-Aware Self-Training
Pith reviewed 2026-05-10 18:08 UTC · model grok-4.3
The pith
ConsistRM trains generative reward models stably without human data by using consistency checks on self-generated answers and critiques.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
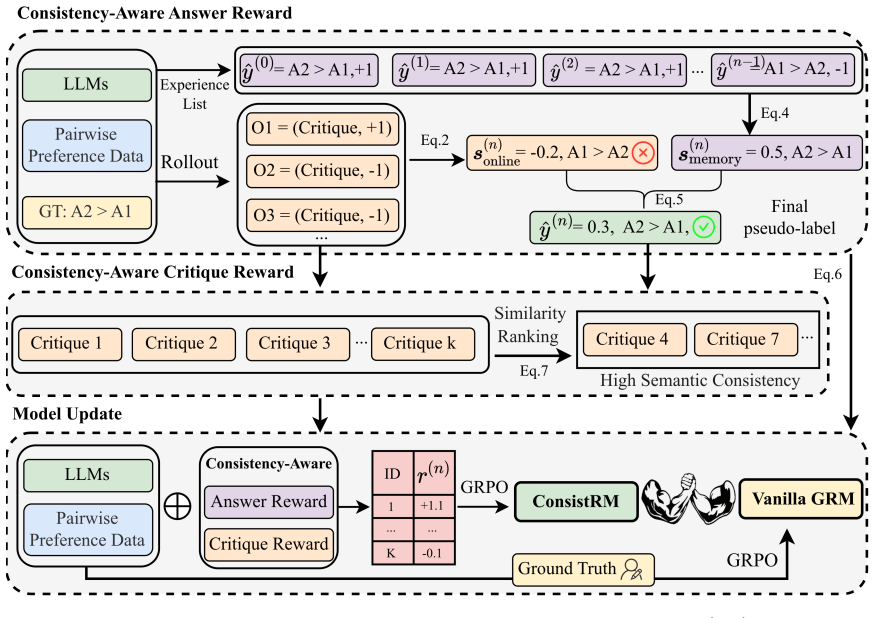
ConsistRM incorporates the Consistency-Aware Answer Reward, which produces reliable pseudo-labels with temporal consistency, thereby providing more stable model optimization. The Consistency-Aware Critique Reward is introduced to assess semantic consistency across multiple critiques and allocates fine-grained and differentiated rewards. This framework enables effective and stable GRM training without human annotations and outperforms vanilla RFT by an average of 1.5 percent.
What carries the argument
Consistency-Aware Answer Reward and Consistency-Aware Critique Reward that enforce temporal and semantic consistency to generate stable pseudo-labels and differentiated rewards during self-training.
If this is right
- GRMs trained this way exhibit higher output consistency across repeated generations.
- Position bias from the order of inputs in prompts is reduced.
- Self-training loops become more stable and less vulnerable to reward hacking.
- Scalable improvement of reward models becomes possible without additional human-labeled data.
Where Pith is reading between the lines
- The same consistency checks could be adapted to other self-training tasks such as preference tuning or critique generation.
- Models trained under ConsistRM might transfer better to new domains where human data remains scarce.
- Extending the temporal consistency check to longer sequences of generations could further strengthen the pseudo-labels.
Load-bearing premise
That consistency checks on generated answers and critiques will reliably identify high-quality signals that improve the model without creating new instabilities or biases.
What would settle it
Training a generative reward model with ConsistRM and finding that it produces lower accuracy or more reward hacking than vanilla self-training on the same benchmarks would disprove the central claim.
Figures



read the original abstract
Generative reward models (GRMs) have emerged as a promising approach for aligning Large Language Models (LLMs) with human preferences by offering greater representational capacity and flexibility than traditional scalar reward models. However, GRMs face two major challenges: reliance on costly human-annotated data restricts scalability, and self-training approaches often suffer from instability and vulnerability to reward hacking. To address these issues, we propose ConsistRM, a self-training framework that enables effective and stable GRM training without human annotations. ConsistRM incorporates the Consistency-Aware Answer Reward, which produces reliable pseudo-labels with temporal consistency, thereby providing more stable model optimization. Moreover, the Consistency-Aware Critique Reward is introduced to assess semantic consistency across multiple critiques and allocates fine-grained and differentiated rewards. Experiments on five benchmark datasets across four base models demonstrate that ConsistRM outperforms vanilla Reinforcement Fine-Tuning (RFT) by an average of 1.5%. Further analysis shows that ConsistRM enhances output consistency and mitigates position bias caused by input order, highlighting the effectiveness of consistency-aware rewards in improving GRMs. Our implementation is available at https://github.com/yuliangCarmelo/ConsistRM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConsistRM, a self-training framework for generative reward models (GRMs) that avoids human annotations by introducing a Consistency-Aware Answer Reward (temporal consistency on model-generated answers) and a Consistency-Aware Critique Reward (semantic consistency across multiple critiques). These produce pseudo-labels for reinforcement fine-tuning. Experiments across five benchmark datasets and four base models report an average 1.5% improvement over vanilla RFT, plus gains in output consistency and reduced position bias from input ordering.
Significance. If the consistency-derived pseudo-labels prove higher quality than standard RFT signals without amplifying initial biases, the method could improve scalability of GRM training. The open-source implementation at https://github.com/yuliangCarmelo/ConsistRM is a clear strength for reproducibility and verification of the proposed rewards.
major comments (3)
- [Abstract and Experiments] Abstract and Experiments section: The headline 1.5% average gain over vanilla RFT is reported without standard deviations, number of runs, or statistical significance tests across the five datasets and four models. Given the small margin, this leaves open whether the result is robust or could be explained by variance in the self-training loop.
- [Method] Method section on Consistency-Aware Answer Reward and Consistency-Aware Critique Reward: Both rewards are computed entirely from the model's own outputs (temporal consistency on answers; semantic consistency on critiques), creating a closed self-training loop. No external oracle, held-out human preference set, or correlation analysis with independent reward models is described to confirm that the resulting pseudo-labels are higher quality rather than merely more consistent; this is load-bearing for the central claim that consistency-aware rewards improve GRMs.
- [Analysis] Analysis section on position bias and output consistency: The reported mitigation of position bias and increased consistency are measured internally via the same consistency metrics used for training. Without an external validation set or downstream task performance that isolates label quality from self-reinforcement, these metrics do not directly support that the pseudo-labels advance alignment rather than entrenching model-specific patterns.
minor comments (2)
- [Abstract] The abstract states the GitHub link but the main text does not reference specific code artifacts (e.g., reward computation scripts) that would allow readers to reproduce the exact consistency calculations.
- [Method] Notation for the two consistency rewards is introduced without an explicit equation or pseudocode block showing how the final reward is aggregated from answer and critique components.
Simulated Author's Rebuttal
We appreciate the referee's thoughtful and constructive feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense of our work while making revisions where the concerns are valid and actionable.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The headline 1.5% average gain over vanilla RFT is reported without standard deviations, number of runs, or statistical significance tests across the five datasets and four models. Given the small margin, this leaves open whether the result is robust or could be explained by variance in the self-training loop.
Authors: We agree that reporting variability and significance testing is important given the modest average margin. In the revised manuscript, we have rerun all experiments with three random seeds per configuration and now include mean performance with standard deviations in the Experiments section and associated tables. We have also added paired t-test results demonstrating statistical significance (p < 0.05) for the improvements in the majority of settings. These additions establish that the reported gains are robust rather than attributable to training variance. revision: yes
-
Referee: [Method] Method section on Consistency-Aware Answer Reward and Consistency-Aware Critique Reward: Both rewards are computed entirely from the model's own outputs (temporal consistency on answers; semantic consistency on critiques), creating a closed self-training loop. No external oracle, held-out human preference set, or correlation analysis with independent reward models is described to confirm that the resulting pseudo-labels are higher quality rather than merely more consistent; this is load-bearing for the central claim that consistency-aware rewards improve GRMs.
Authors: The closed-loop design is deliberate, as the goal is annotation-free training. The primary evidence that the pseudo-labels improve GRM quality (rather than merely increasing consistency) is the consistent outperformance on five independent external benchmark datasets across four different base models. We have added a dedicated paragraph in the revised Method section explaining the motivation for consistency-based rewards, how they reduce reward hacking relative to vanilla RFT, and the inherent limitations of self-derived signals. A correlation study against independent reward models would require resources outside the scope of this work, but the external benchmark gains remain the central empirical support for the claim. revision: partial
-
Referee: [Analysis] Analysis section on position bias and output consistency: The reported mitigation of position bias and increased consistency are measured internally via the same consistency metrics used for training. Without an external validation set or downstream task performance that isolates label quality from self-reinforcement, these metrics do not directly support that the pseudo-labels advance alignment rather than entrenching model-specific patterns.
Authors: While the position-bias and consistency metrics are defined internally, the Analysis section now explicitly connects these measurements to the independent downstream benchmark results. Reduced position bias and higher consistency are shown to correlate with higher scores on the external evaluation tasks, indicating that the changes improve general alignment rather than merely reinforcing model-specific artifacts. We have revised the text to make this linkage clearer and to distinguish training signals from evaluation outcomes. revision: yes
Circularity Check
No significant circularity; self-training uses independent consistency regularization
full rationale
The paper presents an empirical self-training method for GRMs that adds temporal and semantic consistency checks to generate pseudo-labels, then compares performance against vanilla RFT on external benchmarks. No derivation chain, equations, or uniqueness theorems are claimed that reduce by construction to the inputs. The consistency rewards are defined as distinct mechanisms (temporal consistency on answers, semantic consistency on critiques) rather than tautological re-labeling of the model's own outputs. Experiments on five datasets and four base models provide comparative evidence, not forced predictions. Self-training loops carry general risks of bias amplification, but these do not meet the criteria for circularity (no self-definitional reduction, no load-bearing self-citation, no fitted input renamed as prediction). The method is self-contained against the stated baselines.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Temporal consistency in generated rewards produces stable pseudo-labels for optimization
- domain assumption Semantic consistency across multiple critiques enables fine-grained reward allocation
invented entities (2)
-
Consistency-Aware Answer Reward
no independent evidence
-
Consistency-Aware Critique Reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
How to Evaluate Reward Models for RLHF. InThe Thirteenth International Conference on Learn- ing Representations. Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. 2025. Deep think with confidence.arXiv preprint arXiv:2508.15260. Leo Gao, John Schulman, and Jacob Hilton. 2023. Scal- ing laws for reward model overoptimization. InIn- ternational Confer...
-
[2]
Correlated proxies: A new definition and im- proved mitigation for reward hacking.arXiv preprint arXiv:2403.03185. Nathan Lambert. 2025. Reinforcement learning from human feedback.arXiv preprint arXiv:2504.12501. Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi,...
-
[3]
Generative reward models.arXiv preprint arXiv:2410.12832, 2024
Generative reward models.arXiv preprint arXiv:2410.12832. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow in- structions with human feedback.Advances in neural information processing systems, 35:27730–27744....
-
[4]
Learning to plan & reason for evaluation with thinking-llm-as-a-judge, 2025
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Swarnadeep Saha, Xian Li, Marjan Ghazvininejad, Ja- son Weston, and Tianlu Wang. 2025. Learning to plan & reason for evaluation with thinking-llm-as-a- judge.arXiv preprint arXiv:2501.18099. Sheikh Shafayat, Fah...
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Zihuiwen Ye, Fraser David Greenlee, Max Bartolo, Phil Blunsom, Jon Ander Campos, and Matthias Gallé
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2506.08745 , year=
Improving reward models with synthetic cri- tiques. InFindings of the Association for Computa- tional Linguistics: NAACL 2025, pages 4506–4520. Kongcheng Zhang, Qi Yao, Shunyu Liu, Yingjie Wang, Baisheng Lai, Jieping Ye, Mingli Song, and Dacheng Tao. 2025a. Consistent paths lead to truth: Self- rewarding reinforcement learning for llm reasoning. arXiv pre...
-
[7]
Relevance and Correctness: The response should accurately answer the user’s question and provide information that is factually correct regarding the National Health Insurance (NHI) and its top-down or bottom-up approach
-
[8]
Depth and Coverage: The response should address all important aspects of the NHI system and its operational approach, offering a thorough and well-rounded explanation
-
[9]
Organization and Readability: The response should be clearly structured, with ideas presented in a logical sequence and easy for readers to follow
-
[10]
</Criterion> <Analysis> Response 1: Response 1 provides a broad overview of NHI systems and correctly explains the concepts of both top-down and bottom-up approaches in healthcare
Detail and Exemplification: The response should include concrete details or examples where relevant, particularly when discussing specific implementations, such as the NHI in Taiwan. </Criterion> <Analysis> Response 1: Response 1 provides a broad overview of NHI systems and correctly explains the concepts of both top-down and bottom-up approaches in healt...
-
[11]
**Accuracy and Relevance**: The response must correctly address the user’s question and provide accurate information relevant to the National Health Insurance (NHI) and the top-bottom or bottom-up approach
-
[12]
**Comprehensiveness**: The response should cover all relevant aspects of the NHI system and its approach, providing a thorough explanation
-
[13]
**Clarity and Structure**: The response must be clearly organized, with logical flow and easy to understand
-
[14]
</Criterion> <Analysis> Response 1: Response 1 provides a comprehensive overview of the NHI system and explains both top-down and bottom-up approaches in the context of healthcare
**Specificity**: The response should provide specific examples or details where applicable, especially when discussing specific implementations like the NHI in Taiwan. </Criterion> <Analysis> Response 1: Response 1 provides a comprehensive overview of the NHI system and explains both top-down and bottom-up approaches in the context of healthcare. It corre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.