Recognition: 2 theorem links
· Lean TheoremROZA Graphs: Self-Improving Near-Deterministic RAG through Evidence-Centric Feedback
Pith reviewed 2026-05-10 17:19 UTC · model grok-4.3
The pith
ROZA graphs let RAG systems reuse prior evidence judgments to raise accuracy and cut variance while keeping the base model frozen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
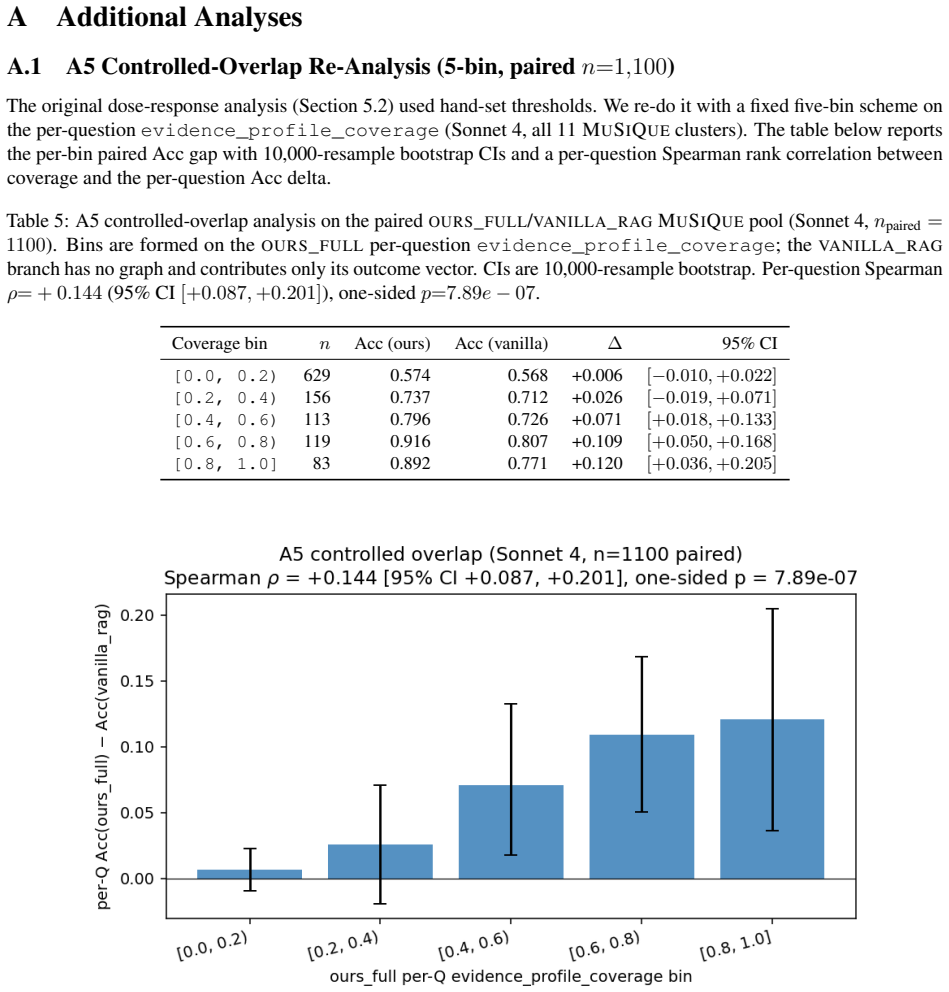
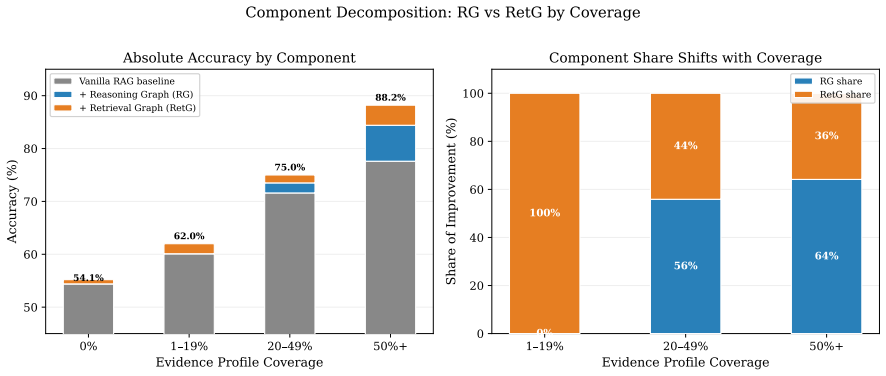
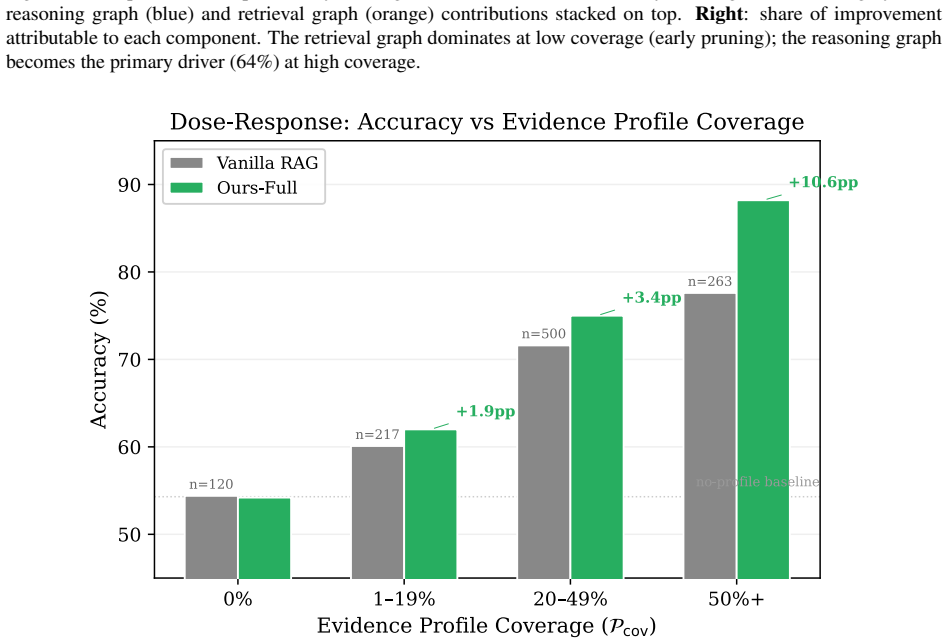
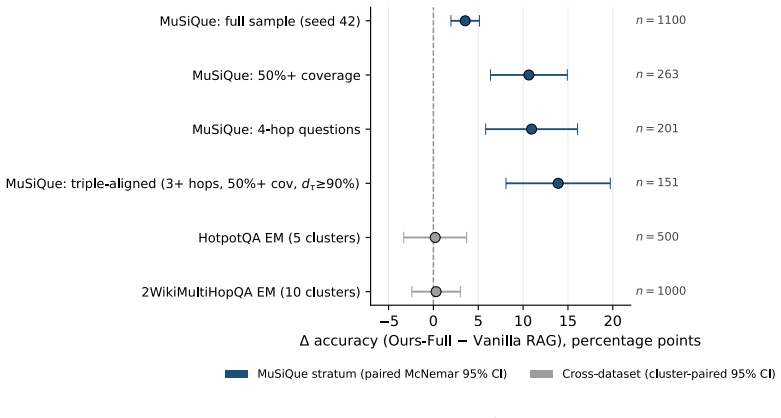
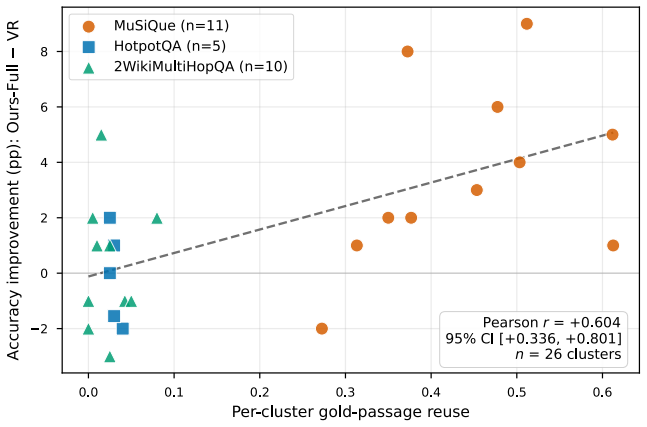
The central claim is that combining reasoning graphs, which persist per-evidence chain-of-thought evaluations as traversable edges for evidence-centric feedback, with retrieval graphs that prune consistently rejected candidates forms a self-improving ROZA graph. This structure produces monotonic accuracy gains that scale with evidence-profile coverage, reaching +10.6 percentage points over vanilla RAG at 50 percent or higher coverage on identical questions for a 47 percent error reduction, larger gains on multi-hop questions, and substantially higher decision consistency across runs, all while the base model remains unchanged and gains derive solely from graph traversal.
What carries the argument
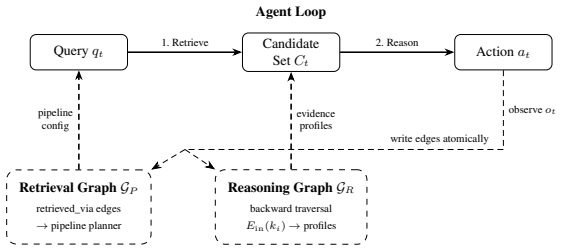
ROZA graph, a dual structure of reasoning graphs that link evaluation edges to specific evidence for feedback traversal and retrieval graphs that prune poor candidates over runs, which drives accuracy scaling with gold-passage reuse and efficiency scaling with candidate overlap.
If this is right
- Accuracy rises monotonically with increasing evidence-profile coverage on the same questions.
- Multi-hop question accuracy improves by 11 percentage points.
- Gains at the cluster level are predicted by the density of gold-passage reuse.
- High-reuse deployments achieve top accuracy together with 46 percent lower cost and latency.
- Per-passage decision consistency across repeated runs increases by 8 to 21 percentage points.
Where Pith is reading between the lines
- The same graph structure could accumulate useful memory in other agent loops that repeat similar subtasks.
- Graphs built on one model family might transfer partial value when swapping to another family without full retraining.
- Explicit edge-based reuse of reasoning could substitute for some increases in model size on repeated tasks.
- Extending the graphs to non-QA tasks like code generation or planning would test whether the reuse benefit generalizes.
Load-bearing premise
The measured accuracy and consistency improvements are produced by the evidence-centric graph traversal and pruning rather than by longer contexts, changed prompts, or dataset quirks.
What would settle it
An experiment that matches total context length and prompt text exactly but disables graph traversal and pruning, then checks whether the accuracy, error reduction, and consistency gains vanish.
Figures






read the original abstract
Language model agents reason from scratch on every query, discarding their chain of thought after each run. The result is lower accuracy and high run-to-run variance. We introduce reasoning graphs, which persist the per-evidence chain of thought as structured edges. Unlike prior memory that retrieves distilled strategies by query similarity, reasoning graphs enable evidence-centric feedback: for every candidate item, the system traverses all incoming evaluation edges across prior runs to surface how that specific item has been judged before. We further introduce retrieval graphs, which feed a planner that prunes consistently-rejected candidates over successive runs. Together they form a ROZA graph: a self-improving feedback loop in which accuracy gains scale with gold-passage reuse (reasoning graph) and efficiency gains scale with candidate-pool overlap (retrieval graph). The base model remains frozen; all gains come from context engineering via graph traversal. We evaluate on MuSiQue and HotpotQA, plus a high-reuse deployment subset. Four findings stand out. (1) Dose-response: accuracy improves monotonically with evidence-profile coverage, reaching +10.6pp over Vanilla RAG at 50%+ coverage on the same questions (47% error reduction, $p<0.0001$; per-question Spearman $\rho=+0.144$, $p<10^{-6}$, $n=1{,}100$). (2) Multi-hop scaling: 4-hop accuracy improves by +11.0pp ($p=0.0001$). (3) Cross-cluster prediction: the cluster-level gain is predicted by gold-passage reuse density ($r=0.604$, $p=0.001$, $n=26$ clusters). (4) High-reuse Pareto dominance: highest or tied-for-highest accuracy alongside 46% lower cost and 46% lower latency. Per-passage decision consistency across repeated runs ($N=73$ paired probes, $K=10$ runs each, two model families, three temperatures) rises by +8 to +13pp on a fixed 20-passage context and by +12 to +21pp when the retrieval graph also prunes (all $p<0.005$).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ROZA graphs, which combine reasoning graphs (persisting per-evidence chain-of-thought judgments as structured edges for evidence-centric feedback) and retrieval graphs (pruning consistently rejected candidates via a planner). This forms a self-improving feedback loop for RAG where accuracy scales with gold-passage reuse and efficiency with candidate-pool overlap. All gains are attributed to context engineering via graph traversal with a frozen base model. Evaluations on MuSiQue, HotpotQA, and a high-reuse subset report dose-response accuracy gains (+10.6pp at 50%+ coverage, 47% error reduction, p<0.0001), multi-hop scaling (+11.0pp), cross-cluster predictions (r=0.604), Pareto dominance in cost/latency, and consistency improvements (+8 to +21pp across runs).
Significance. If the accuracy, consistency, and efficiency gains are causally due to the evidence-centric traversal and pruning mechanics rather than incidental factors, the work provides a structured, reusable memory mechanism that could meaningfully improve deterministic behavior in RAG and agent systems. The dose-response curves, Spearman correlations, cluster-level analysis, and high-reuse Pareto results offer falsifiable empirical patterns on standard multi-hop QA benchmarks. The parameter-free framing (no model updates) and focus on persisted judgments distinguish it from similarity-based memory approaches.
major comments (2)
- [Abstract] Abstract: The central attribution that 'all gains come from context engineering via graph traversal' (with monotonic accuracy scaling by evidence-profile coverage) is load-bearing but not isolated from confounds. Higher coverage inherently supplies more historical CoT text to the prompt; without an ablation that holds total context length, number of passages, and prompt template fixed while removing only the traversal/pruning logic (e.g., unstructured concatenation of prior runs), it remains possible that gains arise from increased context volume or prompt changes rather than the graph structure itself. This directly affects the causal claim for the +10.6pp and consistency results.
- [Results] Results (dose-response and consistency sections): The reported per-question Spearman correlation (rho=+0.144) and consistency gains (+8 to +21pp, p<0.005) across N=73 probes do not rule out the context-length confound, as the manuscript provides no matched-length baseline that substitutes non-graph prior-run text. This weakens the claim that gains scale specifically with gold-passage reuse density and retrieval-graph pruning.
minor comments (2)
- [Methods] The definition of 'evidence-profile coverage' and how exactly incoming evaluation edges are traversed and surfaced in the prompt should be formalized with pseudocode or an equation to improve reproducibility.
- [Figures/Tables] Figure captions and table legends could more explicitly state the exact prompt templates and token budgets used for each condition to allow direct comparison with Vanilla RAG.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the causal attribution in our work. We address each major comment below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central attribution that 'all gains come from context engineering via graph traversal' (with monotonic accuracy scaling by evidence-profile coverage) is load-bearing but not isolated from confounds. Higher coverage inherently supplies more historical CoT text to the prompt; without an ablation that holds total context length, number of passages, and prompt template fixed while removing only the traversal/pruning logic (e.g., unstructured concatenation of prior runs), it remains possible that gains arise from increased context volume or prompt changes rather than the graph structure itself. This directly affects the causal claim for the +10.6pp and consistency results.
Authors: We agree that an ablation isolating the graph traversal from raw context volume is necessary to strengthen the causal claim. The ROZA mechanism selectively traverses and includes only evidence-specific prior judgments via the graph edges, rather than indiscriminately adding all prior CoT text. This targeted inclusion is a key distinction from unstructured concatenation. However, we acknowledge the current results do not fully control for total token count. In the revised manuscript, we will add a baseline condition that concatenates prior-run CoTs without graph-based selection or pruning, while matching the average context length to the ROZA condition. This will allow direct comparison of the structured traversal effect. revision: yes
-
Referee: [Results] Results (dose-response and consistency sections): The reported per-question Spearman correlation (rho=+0.144) and consistency gains (+8 to +21pp, p<0.005) across N=73 probes do not rule out the context-length confound, as the manuscript provides no matched-length baseline that substitutes non-graph prior-run text. This weakens the claim that gains scale specifically with gold-passage reuse density and retrieval-graph pruning.
Authors: The per-question Spearman correlation measures the relationship between gold-passage reuse density and accuracy improvement on the same questions, which is designed to link gains to evidence reuse rather than overall context size. Nevertheless, we recognize that without a matched-length control, alternative explanations remain possible. We will incorporate the proposed ablation in the revision, ensuring that the non-graph baseline uses equivalent total context length by sampling or truncating prior text as needed. This should clarify whether the structured feedback and pruning provide benefits beyond volume. revision: yes
Circularity Check
No circularity in claimed derivations
full rationale
The paper reports empirical dose-response relationships (accuracy vs. evidence-profile coverage, gold-passage reuse density correlations) on standard MuSiQue and HotpotQA benchmarks, with all gains attributed to graph traversal on persisted judgments while keeping the base model frozen. No equations, definitions, or self-citations reduce any reported lift, prediction, or uniqueness claim to a quantity defined by the same fitted inputs or prior author work; the central results remain independent statistical observations rather than tautological renamings or self-referential fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Persisting per-evidence chain-of-thought as graph edges enables useful feedback that improves future retrieval and reasoning
invented entities (1)
-
ROZA graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[2]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[3]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
-
[4]
Case-based reasoning: Foundational issues, methodological variations, and system approaches
Agnar Aamodt and Enric Plaza. Case-based reasoning: Foundational issues, methodological variations, and system approaches. In AI Communications, volume 7, pages 39--59, 1994
1994
-
[5]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self- RAG : Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Larson, and Cody Truitt. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Case-Based Reasoning
Janet Kolodner. Case-Based Reasoning. Morgan Kaufmann, 1993
1993
-
[9]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459--9474, 2020
2020
-
[10]
Self-improving reactive agents based on reinforcement learning, planning and teaching
Long-Ji Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine Learning, 8 0 (3--4): 0 293--321, 1992
1992
-
[11]
When agents disagree with themselves: Measuring behavioral consistency in LLM -based agents
Aman Mehta. When agents disagree with themselves: Measuring behavioral consistency in LLM -based agents. arXiv preprint arXiv:2602.11619, 2026 a
-
[12]
Consistency Amplifies: How Behavioral Variance Shapes Agent Accuracy
Aman Mehta. Consistency amplifies: How behavioral variance shapes agent accuracy. arXiv preprint arXiv:2603.25764, 2026 b
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Human-level control through deep reinforcement learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning. Nature, 518 0 (7540): 0 529--533, 2015
2015
-
[14]
ReasoningBank : Scaling agent self-evolving with reasoning memory
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. ReasoningBank : Scaling agent self-evolving with reasoning memory. In International Conference on Learning Representations, 2026
2026
-
[15]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph C O'Brien, Carrie J Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023
2023
-
[16]
arXiv preprint arXiv:2408.08921 (2024) A CQ-Driven RAG Workflow for Digital Storytelling 19
Boci Peng, Yun Zhu, Yongchao Liu, Xiaohe Bo, Haizhou Shi, Chuntao Hong, Yan Yan, and Youzhi Li. Graph retrieval-augmented generation: A survey. arXiv preprint arXiv:2408.08921, 2024
-
[17]
Exploring the pre-conditions for memory-learning agents
Vishwa Shah, Vishruth Veerendranath, Graham Neubig, Daniel Fried, and Zora Zhiruo Wang. Exploring the pre-conditions for memory-learning agents. In ICLR 2025 Workshop on Self-Improving Foundation Models, 2025
2025
-
[18]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. In Advances in Neural Information Processing Systems, volume 36, 2023
2023
-
[19]
Evaluate-as-action: Self-evaluated process rewards for retrieval-augmented agents
Jiangming Shu, Yuxiang Zhang, Ye Ma, Xueyuan Lin, and Jitao Sang. Evaluate-as-action: Self-evaluated process rewards for retrieval-augmented agents. arXiv preprint arXiv:2603.09203, 2026
-
[20]
and Yao, Shunyu and Narasimhan, Karthik and Griffiths, Thomas L
Theodore R Sumers, Shunyu Yao, Karthik Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents. Transactions on Machine Learning Research, 2024. arXiv preprint arXiv:2309.02427, 2023
-
[21]
MuSiQue : Multihop questions via single hop question composition
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue : Multihop questions via single hop question composition. Transactions of the Association for Computational Linguistics, 10: 0 539--554, 2022
2022
-
[22]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
GAM-RAG : Gain-adaptive memory for evolving retrieval in retrieval-augmented generation
Yifan Wang, Mingxuan Jiang, Zhihao Sun, Yixin Cao, Yicun Liu, Keyang Chen, Guangnan Ye, and Hongfeng Chai. GAM-RAG : Gain-adaptive memory for evolving retrieval in retrieval-augmented generation. arXiv preprint arXiv:2603.01783, 2026
-
[24]
When to use graphs in RAG : A comprehensive analysis for graph retrieval-augmented generation
Zhishang Xiang, Chuanjie Wu, Qinggang Zhang, Shengyuan Chen, Zijin Hong, Xiao Huang, and Jinsong Su. When to use graphs in RAG : A comprehensive analysis for graph retrieval-augmented generation. In International Conference on Learning Representations, 2026
2026
-
[25]
HotpotQA : A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. HotpotQA : A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380, 2018
2018
-
[26]
ReAct : Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations, 2023
2023
-
[27]
MEM1 : Learning to synergize memory and reasoning for efficient long-horizon agents
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. MEM1 : Learning to synergize memory and reasoning for efficient long-horizon agents. In International Conference on Learning Representations, 2026
2026
-
[28]
LinearRAG : Linear graph retrieval augmented generation on large-scale corpora
Luyao Zhuang, Shengyuan Chen, Yilin Xiao, Huachi Zhou, Yujing Zhang, Hao Chen, Qinggang Zhang, and Xiao Huang. LinearRAG : Linear graph retrieval augmented generation on large-scale corpora. In International Conference on Learning Representations, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.