Recognition: no theorem link
Auto-Configured Networks for Multi-Scale Multi-Output Time-Series Forecasting
Pith reviewed 2026-05-10 17:42 UTC · model grok-4.3
The pith
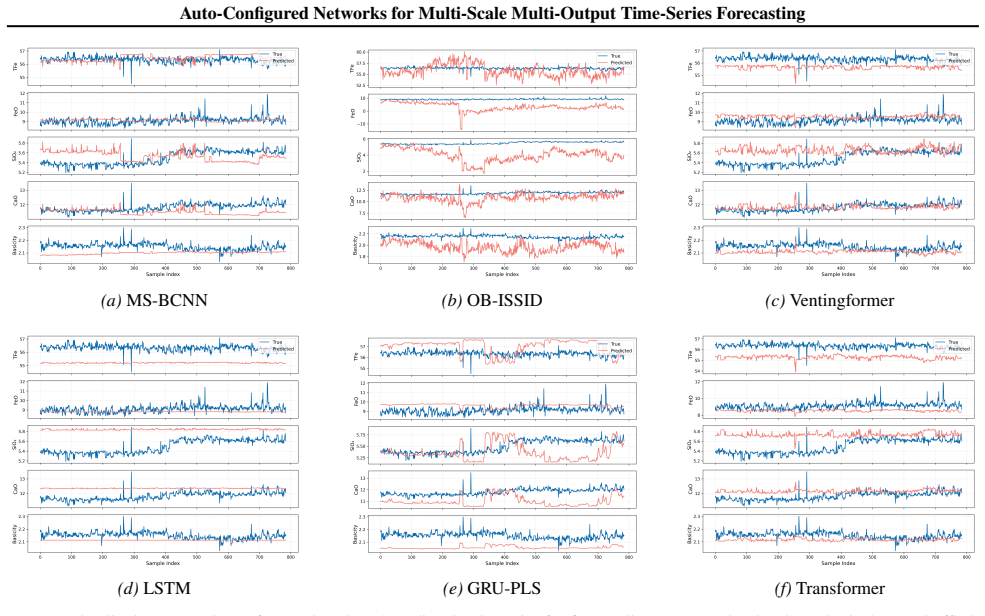
An auto-configuration framework searches a mixed space of alignments, MS-BCNN architectures, and hyperparameters to produce Pareto sets of forecasting models that trade prediction error against complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By unifying alignment operators, architectural choices for the MS-BCNN, and training hyperparameters into a hierarchical-conditional mixed configuration space and searching it with the Player-based Hybrid Multi-Objective Evolutionary Algorithm, the framework approximates the error-complexity Pareto frontier and produces deployable models that outperform competitive baselines under the same budget on hierarchical synthetic benchmarks and a real-world sintering dataset.
What carries the argument
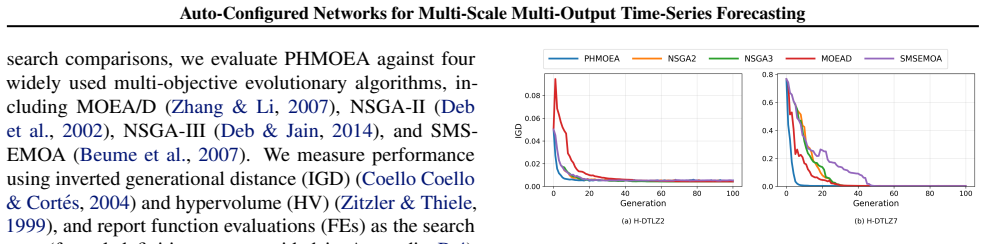
The Player-based Hybrid Multi-Objective Evolutionary Algorithm (PHMOEA) searching the hierarchical-conditional mixed configuration space of alignment operators, MS-BCNN architectures, and training hyperparameters to approximate the error-complexity Pareto frontier.
If this is right
- The framework supplies multiple models along the error-complexity frontier, allowing selection according to specific deployment constraints.
- Automatic choice of alignment operators handles multi-source asynchronous signals without manual preprocessing decisions.
- Co-design of preprocessing, architecture, and hyperparameters occurs systematically rather than through sequential trial-and-error.
- Performance gains appear on both controlled hierarchical synthetic data and real industrial sintering processes under identical budgets.
Where Pith is reading between the lines
- Practitioners could inspect the returned Pareto set after search and pick models for constraints that were not encoded in the original objectives.
- The same search structure might be applied to other multi-output prediction settings where configuration spaces are large and conditional.
- Varying the computational budget across runs would reveal how quickly the quality of the Pareto front saturates.
- Adding further alignment operators or alternative branch designs could be tested to see whether the frontier shifts measurably.
Load-bearing premise
The Player-based Hybrid Multi-Objective Evolutionary Algorithm can reliably locate superior models inside the hierarchical-conditional mixed configuration space when the computational budget is limited.
What would settle it
On the same hierarchical synthetic benchmarks and sintering dataset, a fixed standard configuration of the MS-BCNN or a random search baseline achieves equal or lower error at comparable complexity levels without the evolutionary search.
Figures






read the original abstract
Industrial forecasting often involves multi-source asynchronous signals and multi-output targets, while deployment requires explicit trade-offs between prediction error and model complexity. Current practices typically fix alignment strategies or network designs, making it difficult to systematically co-design preprocessing, architecture, and hyperparameters in budget-limited training-based evaluations. To address this issue, we propose an auto-configuration framework that outputs a deployable Pareto set of forecasting models balancing error and complexity. At the model level, a Multi-Scale Bi-Branch Convolutional Neural Network (MS--BCNN) is developed, where short- and long-kernel branches capture local fluctuations and long-term trends, respectively, for multi-output regression. At the search level, we unify alignment operators, architectural choices, and training hyperparameters into a hierarchical-conditional mixed configuration space, and apply Player-based Hybrid Multi-Objective Evolutionary Algorithm (PHMOEA) to approximate the error--complexity Pareto frontier within a limited computational budget. Experiments on hierarchical synthetic benchmarks and a real-world sintering dataset demonstrate that our framework outperforms competitive baselines under the same budget and offers flexible deployment choices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an auto-configuration framework for multi-scale multi-output time-series forecasting. It develops a Multi-Scale Bi-Branch Convolutional Neural Network (MS-BCNN) with short- and long-kernel branches and applies a Player-based Hybrid Multi-Objective Evolutionary Algorithm (PHMOEA) to search a hierarchical-conditional mixed configuration space of alignment operators, architectural choices, and training hyperparameters. The goal is to approximate the error-complexity Pareto frontier within a limited budget. Experiments on hierarchical synthetic benchmarks and a real-world sintering dataset are claimed to show outperformance over competitive baselines under the same budget, with flexible deployment options.
Significance. If the empirical claims are substantiated with rigorous validation, the work could offer a practical method for co-designing preprocessing, architecture, and hyperparameters in forecasting applications where explicit error-complexity trade-offs matter. The unification of alignment strategies and network design into a searchable conditional space addresses a real industrial need. However, the absence of detailed quantitative metrics, repeated trials, and search ablations in the current presentation limits the ability to gauge the result's robustness or generalizability.
major comments (2)
- [Experiments] The experimental section reports single-run Pareto fronts for the synthetic hierarchies and sintering dataset without repeated trials, seed variation, or statistical significance tests. This is insufficient to support the outperformance claim, as evolutionary search on hierarchical-conditional spaces is known to exhibit high variance; the gains could be artifacts of initialization rather than systematic superiority of PHMOEA under fixed budget.
- [Search Level / PHMOEA Description] No ablation studies or convergence analysis are provided for the PHMOEA components (e.g., player-based hybridization or handling of conditional dependencies among alignment operators, branch widths, and kernel sizes). This leaves the central assumption—that the algorithm reliably locates models near the true frontier within the limited evaluation budget—unverified and load-bearing for the headline result.
minor comments (2)
- [Abstract] The abstract asserts outperformance but supplies no quantitative metrics, baseline names, or error/complexity values, reducing immediate clarity for readers.
- [Model Level / Search Level] Notation for the hierarchical-conditional configuration space and the exact definition of model complexity (e.g., parameter count or FLOPs) should be formalized earlier to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental rigor and algorithmic validation that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Experiments] The experimental section reports single-run Pareto fronts for the synthetic hierarchies and sintering dataset without repeated trials, seed variation, or statistical significance tests. This is insufficient to support the outperformance claim, as evolutionary search on hierarchical-conditional spaces is known to exhibit high variance; the gains could be artifacts of initialization rather than systematic superiority of PHMOEA under fixed budget.
Authors: We agree that single-run results are insufficient to fully substantiate claims given the stochasticity of evolutionary search. In the revised manuscript we will report results from at least five independent runs with distinct random seeds for each method and dataset. We will include mean and standard deviation of key Pareto quality indicators (e.g., hypervolume) together with appropriate statistical tests to quantify variability and support the observed outperformance under the fixed evaluation budget. revision: yes
-
Referee: [Search Level / PHMOEA Description] No ablation studies or convergence analysis are provided for the PHMOEA components (e.g., player-based hybridization or handling of conditional dependencies among alignment operators, branch widths, and kernel sizes). This leaves the central assumption—that the algorithm reliably locates models near the true frontier within the limited evaluation budget—unverified and load-bearing for the headline result.
Authors: We concur that ablations and convergence analysis are necessary to validate the design choices in PHMOEA. The revised version will add a new experimental subsection containing: (i) an ablation comparing PHMOEA against a baseline MOEA without the player-based hybridization, (ii) targeted analysis of the conditional dependency encoding for alignment operators and architectural parameters, and (iii) convergence plots tracking Pareto-front quality across generations within the allotted budget. These additions will directly address the reliability of the search procedure. revision: yes
Circularity Check
No significant circularity; claims rest on external experimental comparisons
full rationale
The paper introduces an MS-BCNN architecture and PHMOEA search over a hierarchical configuration space, then reports empirical outperformance on synthetic hierarchies and a sintering dataset against baselines under fixed budget. No equations appear that define a target quantity in terms of itself or rename a fitted parameter as a prediction. The central result (Pareto-front approximation and deployment flexibility) is supported by direct comparisons rather than self-definition, self-citation chains, or ansatz smuggling. The search algorithm's reliability is an empirical premise, not a mathematical reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Drift-Aware Online Dynamic Learning for Nonstationary Multivariate Time Series: Application to Sintering Quality Prediction
DA-MSDL maintains predictive performance on drifting multivariate time series by detecting distribution shifts without labels and adapting via prioritized replay and hierarchical fine-tuning.
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.knosys.2020.106622. Hochreiter, S. and Schmidhuber, J. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997. doi: 10. 1162/neco.1997.9.8.1735. Huang, K., Wu, S., Li, Y ., Yang, C., and Gui, W. A multi- rate sampling data fusion method for fault diagnosis and its industrial applications.Journal of Process Control, 104:54–61, 2021...
-
[2]
doi: 10.1109/TEVC.2007.892759. Zhang, W., Yin, C., Liu, H., Zhou, X., and Xiong, H. Irreg- ular multivariate time series forecasting: A transformable patching graph neural networks approach. InProceedings of the 41st International Conference on Machine Learn- ing, volume 235 ofProceedings of Machine Learning Research, pp. 60179–60196, 2024. Zhou, T., Ma, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.