Recognition: 2 theorem links
· Lean TheoremDrift-Aware Online Dynamic Learning for Nonstationary Multivariate Time Series: Application to Sintering Quality Prediction
Pith reviewed 2026-05-10 17:06 UTC · model grok-4.3
The pith
The DA-MSDL framework maintains robust predictive performance on nonstationary multivariate time series by detecting drift unsupervisedly and adapting via hierarchical fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-scale bi-branch convolutional backbone combined with MMD-based unsupervised drift detection and drift-severity-guided hierarchical fine-tuning plus prioritized experience replay enables sustained multi-output accuracy on nonstationary streams, as demonstrated by superior long-horizon results on iron-ore sintering data and benchmark sets under pronounced concept drift.
What carries the argument
The Drift-Aware Multi-Scale Dynamic Learning (DA-MSDL) framework, whose backbone is a multi-scale bi-branch convolutional network that disentangles local fluctuations from long-term trends, with MMD used to quantify feature-distribution shifts for proactive adaptation and hierarchical fine-tuning supported by a dynamic memory queue to balance stability and plasticity.
If this is right
- Proactive updates triggered by feature-distribution shifts reduce the effect of label latency on prediction quality.
- Disentanglement of multi-scale patterns improves representation of complex nonstationary dynamics.
- Prioritized replay from a memory queue enables rapid alignment to new distributions while limiting catastrophic forgetting.
- Cross-domain results on sintering data and a public benchmark indicate the approach generalizes beyond a single industrial process.
Where Pith is reading between the lines
- The same unsupervised MMD trigger could be paired with other online learners facing delayed supervision.
- The hierarchical fine-tuning schedule may transfer to non-convolutional architectures for similar drift-handling tasks.
- Varying the memory queue size or replay priority rules would be a direct test of the stability-plasticity balance.
Load-bearing premise
That maximum mean discrepancy measured on the learned features reliably signals the start of performance degradation before the corresponding labels arrive.
What would settle it
A dataset with known drift injection points and deliberately delayed labels where model accuracy is tracked against the MMD threshold; if accuracy falls substantially before the threshold is crossed, the detection premise is falsified.
Figures








read the original abstract
Accurate prediction of nonstationary multivariate time series remains a critical challenge in complex industrial systems such as iron ore sintering. In practice, pronounced concept drift compounded by significant label verification latency rapidly degrades the performance of offline-trained models. Existing methods based on static architectures or passive update strategies struggle to simultaneously extract multi-scale spatiotemporal features and overcome the stability-plasticity dilemma without immediate supervision. To address these limitations, a Drift-Aware Multi-Scale Dynamic Learning (DA-MSDL) framework is proposed to maintain robust multi-output predictive performance via online adaptive mechanisms on nonstationary data streams. The framework employs a multi-scale bi-branch convolutional network as its backbone to disentangle local fluctuations from long-term trends, thereby enhancing representational capacity for complex dynamic patterns. To circumvent the label latency bottleneck, DA-MSDL leverages Maximum Mean Discrepancy (MMD) for unsupervised drift detection. By quantifying online statistical deviations in feature distributions, DA-MSDL proactively triggers model adaptation prior to inference. Furthermore, a drift-severity-guided hierarchical fine-tuning strategy is developed. Supported by prioritized experience replay from a dynamic memory queue, this approach achieves rapid distribution alignment while effectively mitigating catastrophic forgetting. Long-horizon experiments on real-world industrial sintering data and a public benchmark dataset demonstrate that DA-MSDL consistently outperforms representative baselines under severe concept drift. Exhibiting strong cross-domain generalization and predictive stability, the proposed framework provides an effective online dynamic learning paradigm for quality monitoring in nonstationary environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Drift-Aware Multi-Scale Dynamic Learning (DA-MSDL) framework for online prediction of nonstationary multivariate time series, with application to iron ore sintering quality. The method combines a multi-scale bi-branch convolutional backbone for disentangling local and long-term patterns, unsupervised MMD-based drift detection on learned features to trigger adaptation despite label latency, and a drift-severity-guided hierarchical fine-tuning strategy supported by prioritized replay from a dynamic memory queue to mitigate catastrophic forgetting. Long-horizon experiments on real industrial sintering streams and a public benchmark are reported to show consistent outperformance over baselines under severe concept drift.
Significance. If the central mechanisms prove reliable, the work supplies a concrete online adaptation paradigm for industrial quality monitoring under label delay and nonstationarity, directly addressing the stability-plasticity trade-off in multi-output regression settings. The emphasis on proactive, unsupervised triggering and hierarchical updates offers a practical template that could generalize beyond sintering to other delayed-label streaming applications.
major comments (3)
- [§3.3] §3.3 (Drift Detection): The claim that MMD computed on the multi-scale convolutional features reliably precedes and predicts subsequent degradation in the multi-output regression head is load-bearing for the proactive adaptation strategy, yet the manuscript supplies no correlation analysis, lead-time statistics, or ablation showing that detected MMD shifts align with actual increases in prediction error before labels arrive.
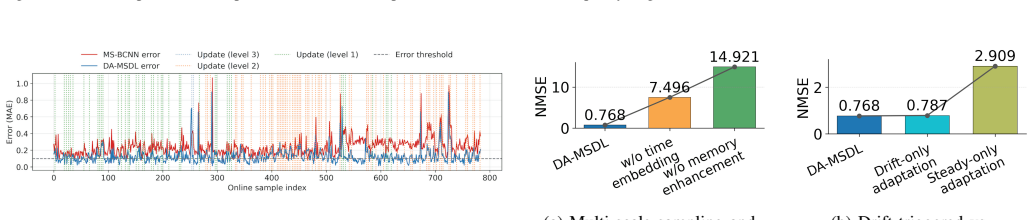
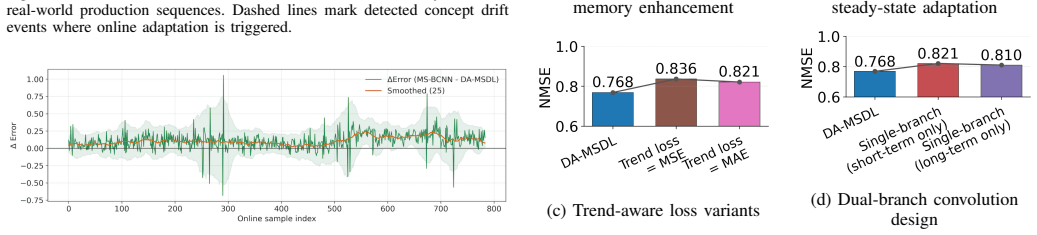
- [§4.1 and §5] §4.1 and §5 (Experimental Setup and Results): The long-horizon outperformance claims rest on the assertion that the dynamic memory queue and severity-guided updates prevent forgetting without introducing instability, but no ablation isolates the contribution of the prioritized replay buffer or quantifies how drift severity is measured and thresholded; without these, attribution of gains to the proposed mechanisms remains unclear.
- [Table 2] Table 2 (or equivalent performance table): Reported metrics under severe drift lack standard deviations across repeated runs, statistical significance tests, or sensitivity analysis to the MMD kernel bandwidth and memory queue hyperparameters, making it impossible to assess whether the observed improvements are robust or sensitive to implementation choices.
minor comments (3)
- [Abstract and §2] The abstract and §2 omit explicit equations for the multi-output loss and the exact form of the hierarchical fine-tuning objective, forcing the reader to infer the optimization details.
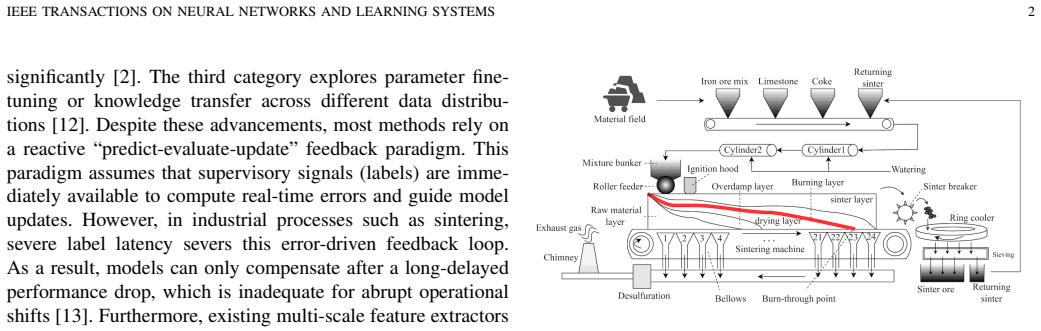
- [Figure 1] Figure 1 (architecture diagram) would benefit from clearer annotation of the bi-branch convolutional paths and the interface between the feature extractor and the MMD detector.
- [§3.4] Notation for the dynamic memory queue capacity and the severity threshold is introduced without a consolidated symbol table, complicating reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Drift Detection): The claim that MMD computed on the multi-scale convolutional features reliably precedes and predicts subsequent degradation in the multi-output regression head is load-bearing for the proactive adaptation strategy, yet the manuscript supplies no correlation analysis, lead-time statistics, or ablation showing that detected MMD shifts align with actual increases in prediction error before labels arrive.
Authors: We agree that explicit evidence linking MMD detections to subsequent error increases is important for validating the proactive strategy. The original manuscript presented overall performance gains under drift but did not include direct correlation or lead-time analysis. In the revision we will add a dedicated analysis (new figure and table) on the sintering dataset that reports Pearson correlation between MMD values and future prediction error, together with average lead-time statistics before labels become available. revision: yes
-
Referee: [§4.1 and §5] §4.1 and §5 (Experimental Setup and Results): The long-horizon outperformance claims rest on the assertion that the dynamic memory queue and severity-guided updates prevent forgetting without introducing instability, but no ablation isolates the contribution of the prioritized replay buffer or quantifies how drift severity is measured and thresholded; without these, attribution of gains to the proposed mechanisms remains unclear.
Authors: We acknowledge that clearer isolation of the replay buffer and severity-guided components is needed. We will expand Section 5 with new ablation experiments that disable prioritized replay and vary the severity thresholds, reporting the resulting performance changes. We will also add explicit description and pseudocode detailing how drift severity is computed from MMD magnitude and how the three-tier thresholds are selected. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent performance table): Reported metrics under severe drift lack standard deviations across repeated runs, statistical significance tests, or sensitivity analysis to the MMD kernel bandwidth and memory queue hyperparameters, making it impossible to assess whether the observed improvements are robust or sensitive to implementation choices.
Authors: We agree that statistical robustness and sensitivity information are essential. In the revised manuscript we will rerun all long-horizon experiments with five random seeds, report mean ± standard deviation for every metric, include paired t-test p-values against baselines, and add a sensitivity table (or supplementary figure) showing performance variation across a range of MMD kernel bandwidths and memory-queue sizes. revision: yes
Circularity Check
No circularity: framework relies on standard external techniques without self-referential derivations
full rationale
The paper presents DA-MSDL as a combination of a multi-scale convolutional backbone, MMD-based unsupervised drift detection, hierarchical fine-tuning, and prioritized replay. No equations, derivations, or first-principles results appear in the provided text that reduce any claimed prediction or performance gain to a quantity defined by the same inputs or fitted parameters. The approach invokes established methods (MMD, experience replay) whose validity is independent of the present work. Experimental claims rest on empirical comparison rather than any algebraic identity or self-citation chain that would force the outcome by construction. This is the normal case of a self-contained engineering framework.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DA-MSDL leverages Maximum Mean Discrepancy (MMD) for unsupervised drift detection... drift-severity-guided hierarchical fine-tuning strategy... prioritized experience replay from a dynamic memory queue
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-scale bi-branch convolutional network... short- and long-kernel convolution branches
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Learning under concept drift: A review,
J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, and G. Zhang, “Learning under concept drift: A review,”IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 9, pp. 2614–2635, 2018
2018
-
[2]
Evaluation of concept drift detection methods for imbalanced data streams,
A. Giełczyk and M. Wozniak, “Evaluation of concept drift detection methods for imbalanced data streams,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 4, pp. 4689–4703, 2024
2024
-
[3]
Dynamic modeling framework based on automatic identification of operating conditions for sintering carbon consumption prediction,
J. Hu, M. Wu, W. Cao, and W. Pedrycz, “Dynamic modeling framework based on automatic identification of operating conditions for sintering carbon consumption prediction,”IEEE Transactions on Industrial Elec- tronics, vol. 71, no. 3, pp. 3133–3141, 2024
2024
-
[4]
BTPNet: A probabilistic spatial-temporal aware network for burn-through point multistep prediction in sintering process,
F. Yan, C. Yang, X. Zhang, C. Yang, and Z. Ruan, “BTPNet: A probabilistic spatial-temporal aware network for burn-through point multistep prediction in sintering process,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 5, pp. 9032–9043, 2025
2025
-
[5]
Phase-field simulation of sintering process: A review,
M. Xue and M. Yi, “Phase-field simulation of sintering process: A review,”CMES-Computer Modeling in Engineering and Sciences, vol. 140, no. 2, pp. 1165–1204, 2024
2024
-
[6]
Multi-scale study of sintering: A review,
E. A. Olevsky, V . Tikare, and T. Garino, “Multi-scale study of sintering: A review,”Journal of the American Ceramic Society, vol. 89, no. 6, pp. 1914–1922, 2006
1914
-
[7]
A multiobjective evolutionary nonlinear ensemble learning with evolutionary feature selection for silicon pre- diction in blast furnace,
X. Wang, T. Hu, and L. Tang, “A multiobjective evolutionary nonlinear ensemble learning with evolutionary feature selection for silicon pre- diction in blast furnace,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 5, pp. 2080–2093, 2022
2080
-
[8]
Multiobjective ensemble learning with multiscale data for product quality prediction in iron and steel industry,
X. Wang, Y . Wang, L. Tang, and Q. Zhang, “Multiobjective ensemble learning with multiscale data for product quality prediction in iron and steel industry,”IEEE Transactions on Evolutionary Computation, vol. 28, no. 4, pp. 1099–1113, 2024
2024
-
[9]
Soft-sensing of burn-through point based on weighted kernel just-in-time learning and fuzzy broad- learning system in sintering process,
J. Hu, M. Wu, W. Cao, and W. Pedrycz, “Soft-sensing of burn-through point based on weighted kernel just-in-time learning and fuzzy broad- learning system in sintering process,”IEEE Transactions on Industrial Informatics, vol. 20, no. 5, pp. 7316–7324, 2024
2024
-
[10]
Temporal convolutional networks for time series forecasting: A review,
P. Lara-Ben ´ıtez, M. Carranza-Garc ´ıa, and J. C. Riquelme, “Temporal convolutional networks for time series forecasting: A review,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 5, pp. 2336–2356, 2021
2021
-
[11]
EnvFormer: A decomposition-based transformer for multistep burn-through point pre- diction in the sintering process,
Y . Xie, B. He, X. Zhang, Z. Song, and M. Kano, “EnvFormer: A decomposition-based transformer for multistep burn-through point pre- diction in the sintering process,”IEEE Transactions on Instrumentation and Measurement, vol. 73, pp. 1–10, 2024
2024
-
[12]
Multisource information fusion for autoformer: Soft sensor modeling of FeO content in iron ore sintering process,
C. Yang, C. Yang, X. Zhang, and J. Zhang, “Multisource information fusion for autoformer: Soft sensor modeling of FeO content in iron ore sintering process,”IEEE Transactions on Industrial Informatics, vol. 19, no. 12, pp. 11 584–11 595, 2023
2023
-
[13]
DSTED: A denoising spatial-temporal encoder-decoder framework for multistep prediction of burn-through point in sintering process,
F. Yan, C. Yang, and X. Zhang, “DSTED: A denoising spatial-temporal encoder-decoder framework for multistep prediction of burn-through point in sintering process,”IEEE Transactions on Industrial Electronics, vol. 69, no. 10, pp. 10 735–10 744, 2022
2022
-
[14]
Data-driven modeling of iron ore sintering process: A review and prospects,
W. Gui, C. Yang, Q. Xu, X. Yan, and H. Zhu, “Data-driven modeling of iron ore sintering process: A review and prospects,”Control Engineering Practice, vol. 89, pp. 1–18, 2019
2019
-
[15]
Modeling of sintering process using a selective support vector regression,
C. Gao, J. Li, X. Chen, and W. Gui, “Modeling of sintering process using a selective support vector regression,”Journal of Process Control, vol. 43, pp. 43–56, 2016
2016
-
[16]
Quality prediction of sintering process based on extreme learning machine,
X. Wanget al., “Quality prediction of sintering process based on extreme learning machine,”Chemometrics and Intelligent Laboratory Systems, vol. 146, pp. 234–241, 2015. IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 15
2015
-
[17]
Data-driven monitoring and diagnosis of modern industrial processes: A review,
S. Yin, S. X. Ding, X. Xie, and H. Luo, “Data-driven monitoring and diagnosis of modern industrial processes: A review,”IEEE Transactions on Industrial Electronics, vol. 61, no. 11, pp. 6390–6402, 2014
2014
-
[18]
Sintering burn-through point prediction based on deep LSTM networks,
S. Xie, F. Chu, Z. Wang, and H. Zhang, “Sintering burn-through point prediction based on deep LSTM networks,”IEEE Transactions on Industrial Informatics, vol. 17, no. 10, pp. 6845–6854, 2021
2021
-
[19]
A data-driven strategy for iron ore sintering process with label latency,
J. Liu, Z. Jiang, and W. Li, “A data-driven strategy for iron ore sintering process with label latency,”Journal of Manufacturing Systems, vol. 56, pp. 112–124, 2020
2020
-
[20]
Deep learning for multivariate time series: A survey from the perspective of architectures,
Y . Zhanget al., “Deep learning for multivariate time series: A survey from the perspective of architectures,”Information Fusion, vol. 88, pp. 12–28, 2022
2022
-
[21]
Novel multi-flow multi-scale convolutional neural network developed for quality prediction of batch processes to fuse data with different sampling frequencies,
Y . Dong and X. Yan, “Novel multi-flow multi-scale convolutional neural network developed for quality prediction of batch processes to fuse data with different sampling frequencies,”International Journal of Control, Automation and Systems, vol. 22, pp. 1–13, 2024
2024
-
[22]
Generalized domain adaptation with unknown classes for rotating machinery fault diagnosis under changing working conditions,
H. Shaoet al., “Generalized domain adaptation with unknown classes for rotating machinery fault diagnosis under changing working conditions,” IEEE Transactions on Industrial Informatics, vol. 18, no. 9, pp. 6043– 6052, 2022
2022
-
[23]
COMPOSE: A framework for class-incremental learning under extreme verification latency,
N. B. Dyer, R. Capo, and R. Polikar, “COMPOSE: A framework for class-incremental learning under extreme verification latency,”IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 12, pp. 2990–3003, 2014
2014
-
[24]
Self-labeled techniques for semi- supervised learning: A review,
I. Triguero, S. Garc ´ıa, and F. Herrera, “Self-labeled techniques for semi- supervised learning: A review,”Knowledge and Information Systems, vol. 42, no. 2, pp. 245–284, 2015
2015
-
[25]
SCARGC: A cluster-based active learning algorithm for data streams with extreme verification latency,
V . M. Souzaet al., “SCARGC: A cluster-based active learning algorithm for data streams with extreme verification latency,”Expert Systems with Applications, vol. 42, no. 17, pp. 6771–6781, 2015
2015
-
[26]
Online neural architecture search for data stream mod- eling,
T. Caldaset al., “Online neural architecture search for data stream mod- eling,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 1, pp. 1027–1041, 2024
2024
-
[27]
Neural architecture search: A survey,
T. Elskenet al., “Neural architecture search: A survey,”The Journal of Machine Learning Research, vol. 20, no. 1, pp. 1997–2017, 2019. [Online]. Available: https://jmlr.org/papers/v20/18-598.html
1997
-
[28]
Adaptive weighted broad echo state learning system-based dynamic modeling of carbon consumption in sintering process,
J. Hu, M. Wu, and W. Pedrycz, “Adaptive weighted broad echo state learning system-based dynamic modeling of carbon consumption in sintering process,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 7, pp. 12 066–12 075, 2025
2025
-
[29]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatricket al., “Overcoming catastrophic forgetting in neural networks,”Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017
2017
-
[30]
Continual lifelong learning with neural networks: A review,
G. I. Parisiet al., “Continual lifelong learning with neural networks: A review,”Neural Networks, vol. 113, pp. 54–71, 2019
2019
-
[31]
Moea/d with spatial–temporal topological tensor prediction for evolutionary dynamic multiobjective optimization,
X. Wang, Y . Zhao, L. Tang, and X. Yao, “Moea/d with spatial–temporal topological tensor prediction for evolutionary dynamic multiobjective optimization,”IEEE Transactions on Evolutionary Computation, vol. 29, no. 3, pp. 764–778, 2025
2025
-
[32]
Auto-Configured Networks for Multi-Scale Multi-Output Time-Series Forecasting
Y . Zhao, S. Yang, and X. Wang, “Auto-configured networks for multi-scale multi-output time-series forecasting,”arXiv preprint arXiv:2604.07610, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
A kernel two-sample test,
A. Gretton, K. M. Borgwardt, R. J. Rasch, B. Sch ¨olkopf, and A. Smola, “A kernel two-sample test,”Journal of Machine Learning Research, vol. 13, no. 25, pp. 723–773, 2012. [Online]. Available: http://jmlr.org/papers/v13/gretton12a.html
2012
-
[34]
Deep learning for time series forecasting: a survey,
X. Kong, Z. Chen, W. Liu, K. Ning, L. Zhang, S. M. Marier, Y . Liu, Y . Chen, and F. Xia, “Deep learning for time series forecasting: a survey,”International Journal of Machine Learning and Cybernetics, vol. 16, pp. 5079–5112, 2025
2025
-
[35]
Time-series forecasting with deep learning: a survey,
B. Lim and S. Zohren, “Time-series forecasting with deep learning: a survey,”Philosophical Transactions of the Royal Society A: Mathemati- cal, Physical and Engineering Sciences, vol. 379, no. 2194, p. 20200209, 2021
2021
-
[36]
A survey of deep learning for time series forecasting: Theories, datasets, and state-of-the-art techniques,
G. Lu, Y . Ou, Z. Wang, Y . Qu, Y . Xia, D. Tang, I. Kotenko, and W. Li, “A survey of deep learning for time series forecasting: Theories, datasets, and state-of-the-art techniques,”Computers, Materials and Continua, vol. 85, no. 2, pp. 2403–2441, 2025
2025
-
[37]
Facilitating ferrous oxide prediction: Enabling sintering forecasting with orthogonal basis-based implicit subspace identification,
S. Wang, C. Yang, and S. Lou, “Facilitating ferrous oxide prediction: Enabling sintering forecasting with orthogonal basis-based implicit subspace identification,”IEEE Transactions on Industrial Informatics, vol. 21, no. 1, 2025
2025
-
[38]
Hybrid self-learning model for the prediction and control of sintering furnace temperature,
Y . Dai, N. Chen, and Z. Shao, “Hybrid self-learning model for the prediction and control of sintering furnace temperature,”Control En- gineering Practice, vol. 154, p. 106159, 2025
2025
-
[39]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems, 2017
2017
-
[40]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[41]
Forecasting of iron ore sintering quality index: A latent variable method with deep inner structure,
C. Yang, C. Yang, J. Li, Y . Li, and F. Yan, “Forecasting of iron ore sintering quality index: A latent variable method with deep inner structure,”Computers in Industry, vol. 141, p. 103713, 2022
2022
-
[42]
M. Poch, “Water Treatment Plant,” UCI Machine Learning Repository, 1993, doi: 10.24432/C5FS4C
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.