Recognition: no theorem link
WUTDet: A 100K-Scale Ship Detection Dataset and Benchmarks with Dense Small Objects
Pith reviewed 2026-05-10 18:07 UTC · model grok-4.3
The pith
A 100k-image ship detection dataset with dense small objects shows Transformers outperforming CNNs and Mamba on accuracy in complex maritime scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WUTDet supplies 100,576 images and 381,378 annotated ship instances that cover diverse operational scenarios and imaging conditions. Benchmarks on 20 models reveal that Transformer architectures deliver the highest overall AP and APs scores and adapt best to complex maritime scenes, CNN architectures retain an edge in inference speed for real-time use, and Mamba architectures provide a balanced accuracy-efficiency trade-off. Models trained on WUTDet further demonstrate stronger generalization when tested on the unified Ship-GEN cross-dataset set.
What carries the argument
The WUTDet dataset itself, defined by its scale, high proportion of dense small ship instances, and coverage of varied maritime scenes and weather, which enables controlled comparison of CNN, Transformer, and Mamba detectors.
If this is right
- Transformer detectors become the default choice when maximum detection accuracy on small vessels is required.
- CNN detectors remain the practical option for real-time onboard navigation systems where speed matters most.
- Mamba detectors serve as a middle path for applications that need both reasonable accuracy and moderate compute.
- Training on WUTDet improves a model's ability to handle shifts in data distribution across different maritime sources.
- Future ship-detection papers can use WUTDet as a common benchmark to report comparable results.
Where Pith is reading between the lines
- The dataset's emphasis on dense small objects could be extended to create similar resources for other domains with crowded small targets, such as aerial vehicle or cell detection.
- Architectural comparisons performed here suggest that hybrid models combining Transformer attention with Mamba efficiency may further improve the accuracy-speed frontier on this data.
- Wider adoption of WUTDet would allow researchers to isolate the effect of scene diversity versus sheer scale when studying generalization failures in detection.
- The cross-dataset Ship-GEN protocol could be reused as a template for measuring domain shift in other perception tasks.
Load-bearing premise
The manual annotations of all 381k ship instances are accurate and consistent, and the 20 chosen baseline implementations plus evaluation protocols represent each architecture class without hidden biases.
What would settle it
A re-run of the 20 baselines on WUTDet with independently verified annotations that reverses the ranking between Transformer and other architectures, or a test on Ship-GEN where WUTDet-trained models no longer show superior generalization.
Figures










read the original abstract
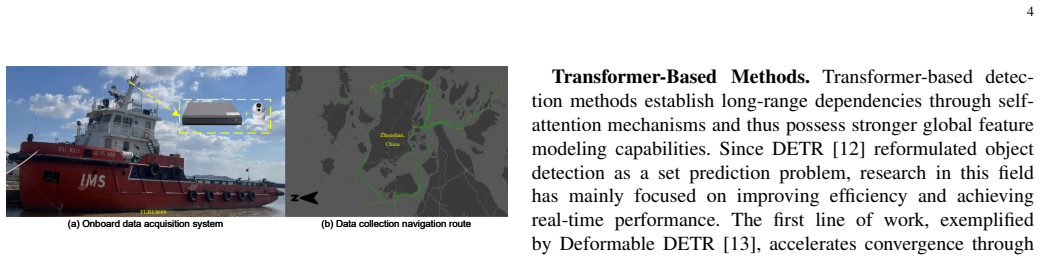
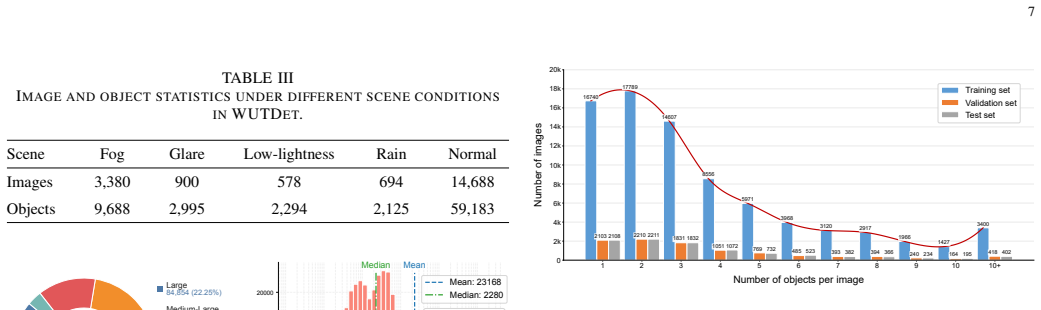
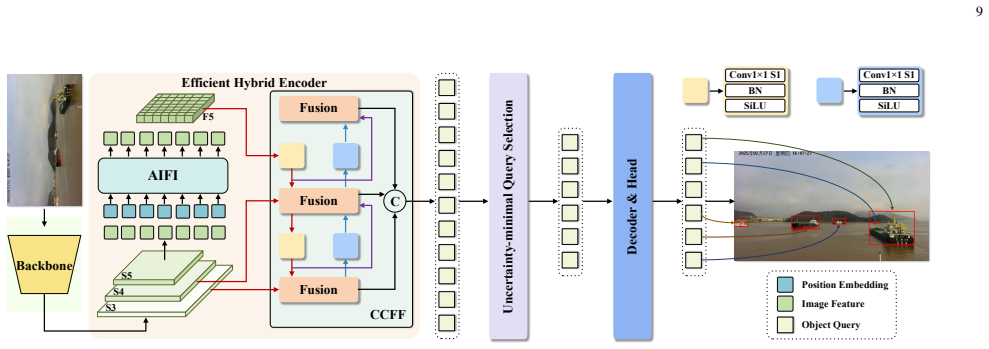
Ship detection for navigation is a fundamental perception task in intelligent waterway transportation systems. However, existing public ship detection datasets remain limited in terms of scale, the proportion of small-object instances, and scene diversity, which hinders the systematic evaluation and generalization study of detection algorithms in complex maritime environments. To this end, we construct WUTDet, a large-scale ship detection dataset. WUTDet contains 100,576 images and 381,378 annotated ship instances, covering diverse operational scenarios such as ports, anchorages, navigation, and berthing, as well as various imaging conditions including fog, glare, low-lightness, and rain, thereby exhibiting substantial diversity and challenge. Based on WUTDet, we systematically evaluate 20 baseline models from three mainstream detection architectures, namely CNN, Transformer, and Mamba. Experimental results show that the Transformer architecture achieves superior overall detection accuracy (AP) and small-object detection performance (APs), demonstrating stronger adaptability to complex maritime scenes; the CNN architecture maintains an advantage in inference efficiency, making it more suitable for real-time applications; and the Mamba architecture achieves a favorable balance between detection accuracy and computational efficiency. Furthermore, we construct a unified cross-dataset test set, Ship-GEN, to evaluate model generalization. Results on Ship-GEN show that models trained on WUTDet exhibit stronger generalization under different data distributions. These findings demonstrate that WUTDet provides effective data support for the research, evaluation, and generalization analysis of ship detection algorithms in complex maritime scenarios. The dataset is publicly available at: https://github.com/MAPGroup/WUTDet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WUTDet, a dataset of 100,576 images containing 381,378 annotated ship instances across diverse maritime scenarios (ports, anchorages, navigation, berthing) and imaging conditions (fog, glare, low-light, rain). It benchmarks 20 detection models spanning CNN, Transformer, and Mamba architectures, claiming Transformer superiority in overall AP and small-object APs, CNN advantage in inference speed, Mamba balance of accuracy and efficiency, and stronger generalization of WUTDet-trained models on the constructed Ship-GEN cross-dataset test set.
Significance. If the annotations are reliable and the benchmarks are free of hidden biases, WUTDet would provide a valuable large-scale resource for evaluating ship detectors under realistic maritime challenges, particularly dense small objects. The architectural comparisons and public release could inform model selection for real-time navigation systems and support further generalization studies.
major comments (2)
- [Dataset construction] Dataset construction section: No inter-annotator agreement metrics, multiple-reviewer protocol, or quality-control statistics are reported for the 381,378 manual labels. Given that small-object instances under adverse conditions form a core challenge, this omission directly affects the trustworthiness of all AP, APs, and Ship-GEN generalization claims.
- [Experimental evaluation] Experimental evaluation section: The paper evaluates 20 baselines but provides insufficient detail on data splits, small-object size thresholds, training hyperparameters, whether models were trained from scratch or fine-tuned, and whether any post-hoc selection occurred. These factors are load-bearing for the reported architecture rankings and cross-dataset results.
minor comments (2)
- [Implementation details] Clarify in the text whether the 20 baseline implementations follow identical training schedules and post-processing steps or if architecture-specific defaults were used.
- The GitHub release should include the precise annotation guidelines and any quality-assurance scripts to allow independent verification.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments below and will update the manuscript to incorporate additional details on dataset annotation and experimental setup.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: No inter-annotator agreement metrics, multiple-reviewer protocol, or quality-control statistics are reported for the 381,378 manual labels. Given that small-object instances under adverse conditions form a core challenge, this omission directly affects the trustworthiness of all AP, APs, and Ship-GEN generalization claims.
Authors: We agree that providing details on the annotation process is important for establishing the reliability of the dataset. In the revised manuscript, we will expand the 'Dataset Construction' section to include a description of the annotation protocol. This will cover the use of multiple annotators, the review process, and any quality control measures implemented. While we did not originally compute inter-annotator agreement statistics, we will report the procedures used to ensure label quality. We believe this will strengthen the trustworthiness of our claims. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: The paper evaluates 20 baselines but provides insufficient detail on data splits, small-object size thresholds, training hyperparameters, whether models were trained from scratch or fine-tuned, and whether any post-hoc selection occurred. These factors are load-bearing for the reported architecture rankings and cross-dataset results.
Authors: We acknowledge the need for more transparency in the experimental setup. In the revised version, we will add a dedicated subsection detailing the data splits (training, validation, and test sets), the definition of small objects (e.g., based on pixel area thresholds), the full list of training hyperparameters for each model, confirmation that models were fine-tuned from pre-trained weights, and assurance that no post-hoc model selection was performed beyond the standard evaluation protocol. This will allow readers to better interpret the architectural comparisons and generalization results. revision: yes
Circularity Check
No circularity: empirical dataset paper with direct benchmarking
full rationale
This is a dataset-construction and empirical-benchmarking paper. It introduces WUTDet (100k images, 381k instances), evaluates 20 off-the-shelf detectors from three families on it, and reports cross-dataset generalization on Ship-GEN. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. All central claims are direct experimental outcomes (AP, APs, inference speed, generalization gaps) rather than reductions to self-defined quantities or self-citation chains. Standard annotation and evaluation protocols are assumed; any quality issues would affect correctness, not create circular logic. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Maritime environment perception based on deep learning,
J. Lin, P. Diekmann, C.-E. Framing, R. Zweigel, and D. Abel, “Maritime environment perception based on deep learning,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 9, pp. 15 487–15 497, 2022
2022
-
[2]
A guide to image-and video-based small object detection using deep learning: Case study of maritime surveillance,
A. M. Rekavandi, L. Xu, F. Boussaid, A.-K. Seghouane, S. Hoefs, and M. Bennamoun, “A guide to image-and video-based small object detection using deep learning: Case study of maritime surveillance,” IEEE Trans. Intell. Transp. Syst., 2025
2025
-
[3]
Mdd-shipnet: Math-data integrated defogging for fog-occlusion ship detection,
N. Wang, Y . Wang, Y . Feng, and Y . Wei, “Mdd-shipnet: Math-data integrated defogging for fog-occlusion ship detection,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 10, pp. 15 040–15 052, 2024
2024
-
[4]
Deep-learning-empowered visual ship detection and tracking: Literature review and future direc- tion,
B. Zhang, J. Liu, R. W. Liu, and Y . Huang, “Deep-learning-empowered visual ship detection and tracking: Literature review and future direc- tion,”Eng. Appl. Artif. Intell., vol. 141, p. 109754, 2025
2025
-
[5]
Aodemar: Attention-aware occlusion detection of vessels for maritime autonomous surface ships,
N. Wang, Y . Wang, Y . Feng, and Y . Wei, “Aodemar: Attention-aware occlusion detection of vessels for maritime autonomous surface ships,” IEEE Trans. Intell. Transp. Syst., vol. 25, no. 10, pp. 13 584–13 597, 2024
2024
-
[6]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”Adv. Neural Inform. Process. Syst., vol. 28, 2015
2015
-
[7]
YOLOv3: An Incremental Improvement
J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018
work page internal anchor Pith review arXiv 2018
-
[8]
YOLOv4: Optimal Speed and Accuracy of Object Detection
A. Bochkovskiy, C.-Y . Wang, and H.-Y . M. Liao, “Yolov4: Op- timal speed and accuracy of object detection,”arXiv preprint arXiv:2004.10934, 2020
work page internal anchor Pith review arXiv 2004
-
[9]
Ssd: Single shot multibox detector,
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y . Fu, and A. C. Berg, “Ssd: Single shot multibox detector,” inproc. ECCV. Springer, 2016, pp. 21–37
2016
-
[10]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Adv. Neural Inform. Process. Syst., vol. 30, 2017
2017
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” inproc. ECCV. Springer, 2020, pp. 213–229
2020
-
[13]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,”arXiv preprint arXiv:2010.04159, 2020. 20
work page internal anchor Pith review arXiv 2010
-
[14]
Detrs beat yolos on real-time object detection,
Y . Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y . Liu, and J. Chen, “Detrs beat yolos on real-time object detection,” inproc. IEEE CVPR, 2024, pp. 16 965–16 974
2024
-
[15]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inproc. COLM, 2024
2024
-
[16]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: Efficient visual representation learning with bidirectional state space model,”arXiv preprint arXiv:2401.09417, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
Seaships: A large-scale precisely annotated dataset for ship detection,
Z. Shao, W. Wu, Z. Wang, W. Du, and C. Li, “Seaships: A large-scale precisely annotated dataset for ship detection,”IEEE Trans. Multimedia, vol. 20, no. 10, pp. 2593–2604, 2018
2018
-
[18]
An image-based benchmark dataset and a novel object detector for water surface object detection,
Z. Zhou, J. Sun, J. Yu, K. Liu, J. Duan, L. Chen, and C. P. Chen, “An image-based benchmark dataset and a novel object detector for water surface object detection,”Front. Neurorob., vol. 15, p. 723336, 2021
2021
-
[19]
Waterscenes: A multi-task 4d radar- camera fusion dataset and benchmarks for autonomous driving on water surfaces,
S. Yao, R. Guan, Z. Wu, Y . Ni, Z. Huang, R. W. Liu, Y . Yue, W. Ding, E. G. Lim, H. Seoet al., “Waterscenes: A multi-task 4d radar- camera fusion dataset and benchmarks for autonomous driving on water surfaces,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 11, pp. 16 584– 16 598, 2024
2024
-
[20]
Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey,
D. K. Prasad, D. Rajan, L. Rachmawati, E. Rajabally, and C. Quek, “Video processing from electro-optical sensors for object detection and tracking in a maritime environment: A survey,”IEEE Trans. Intell. Transp. Syst., vol. 18, no. 8, pp. 1993–2016, 2017
1993
-
[21]
Mcships: A large-scale ship dataset for detection and fine-grained categorization in the wild,
Y . Zheng and S. Zhang, “Mcships: A large-scale ship dataset for detection and fine-grained categorization in the wild,” inproc. IEEE ICME. IEEE, 2020, pp. 1–6
2020
-
[22]
Simuships-a high resolution simulation dataset for ship detection with precise annotations,
M. Raza, H. Prokopova, S. Huseynzade, S. Azimi, and S. Lafond, “Simuships-a high resolution simulation dataset for ship detection with precise annotations,” inproc. OCEANS. IEEE, 2022, pp. 1–5
2022
-
[23]
Asynchronous trajectory matching-based multimodal maritime data fusion for vessel traffic surveillance in inland waterways,
Y . Guo, R. W. Liu, J. Qu, Y . Lu, F. Zhu, and Y . Lv, “Asynchronous trajectory matching-based multimodal maritime data fusion for vessel traffic surveillance in inland waterways,”IEEE Trans. Intell. Transp. Syst., vol. 24, no. 11, pp. 12 779–12 792, 2023
2023
-
[24]
Marine vessel detection dataset and benchmark for unmanned surface vehicles,
N. Wang, Y . Wang, Y . Wei, B. Han, and Y . Feng, “Marine vessel detection dataset and benchmark for unmanned surface vehicles,”Appl. Ocean Res., vol. 142, p. 103835, 2024
2024
-
[25]
The pascal visual object classes (voc) challenge,
M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisser- man, “The pascal visual object classes (voc) challenge,”Int. J. Comput. Vision, vol. 88, no. 2, pp. 303–338, 2010
2010
-
[26]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inproc. IEEE CVPR. Ieee, 2009, pp. 248–255
2009
-
[27]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”Int. J. Comput. Vision, vol. 115, no. 3, pp. 211–252, 2015
2015
-
[28]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inproc. ECCV. Springer, 2014, pp. 740–755
2014
-
[29]
The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont- Tuset, S. Kamali, S. Popov, M. Malloci, A. Kolesnikovet al., “The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale,”Int. J. Comput. Vision, vol. 128, no. 7, pp. 1956–1981, 2020
1956
-
[30]
Objects365: A large-scale, high-quality dataset for object detection,
S. Shao, Z. Li, T. Zhang, C. Peng, G. Yu, X. Zhang, J. Li, and J. Sun, “Objects365: A large-scale, high-quality dataset for object detection,” in proc. IEEE ICCV, 2019, pp. 8430–8439
2019
-
[31]
Fast image-based ob- stacle detection from unmanned surface vehicles,
M. Kristan, V . S. Kenk, S. Kova ˇciˇc, and J. Per ˇs, “Fast image-based ob- stacle detection from unmanned surface vehicles,”IEEE Trans. Cybern., vol. 46, no. 3, pp. 641–654, 2015
2015
-
[32]
Cascade r-cnn: Delving into high quality object detection,
Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” inproc. IEEE CVPR, 2018, pp. 6154–6162
2018
-
[33]
YOLOX: Exceeding YOLO Series in 2021
Z. Ge, S. Liu, F. Wang, Z. Li, and J. Sun, “Yolox: Exceeding yolo series in 2021,”arXiv preprint arXiv:2107.08430, 2021
work page internal anchor Pith review arXiv 2021
-
[34]
YOLOv12: Attention-Centric Real-Time Object Detectors
Y . Tian, Q. Ye, and D. Doermann, “Yolov12: Attention-centric real-time object detectors,”arXiv preprint arXiv:2502.12524, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
arXiv preprint arXiv:2506.17733 (2025)
M. Lei, S. Li, Y . Wu, H. Hu, Y . Zhou, X. Zheng, G. Ding, S. Du, Z. Wu, and Y . Gao, “Yolov13: Real-time object detection with hypergraph- enhanced adaptive visual perception,”arXiv preprint arXiv:2506.17733, 2025
-
[36]
Dab-detr: Dynamic anchor boxes are better queries for detr,
S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, and L. Zhang, “Dab-detr: Dynamic anchor boxes are better queries for detr,”arXiv preprint arXiv:2201.12329, 2022
-
[37]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, and H.-Y . Shum, “Dino: Detr with improved denoising anchor boxes for end-to- end object detection,”arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review arXiv 2022
-
[38]
Y . Peng, H. Li, P. Wu, Y . Zhang, X. Sun, and F. Wu, “D-fine: Redefine regression task in detrs as fine-grained distribution refinement,”arXiv preprint arXiv:2410.13842, 2024
-
[39]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,”Adv. Neural Inform. Process. Syst., vol. 37, pp. 103 031–103 063, 2024
2024
-
[40]
Mamba yolo: A simple baseline for object detection with state space model,
Z. Wang, C. Li, H. Xu, X. Zhu, and H. Li, “Mamba yolo: A simple baseline for object detection with state space model,” inproc. AAAI, vol. 39, no. 8, 2025, pp. 8205–8213
2025
-
[41]
Ultralytics YOLO,
G. Jocher, J. Qiu, and A. Chaurasia, “Ultralytics YOLO,” 2023. [Online]. Available: https://github.com/ultralytics/ultralytics
2023
-
[42]
Yolov6: A single-stage object detection framework for industrial applications
C. Li, L. Li, H. Jiang, K. Weng, Y . Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nieet al., “Yolov6: A single-stage object detection framework for industrial applications,”arXiv preprint arXiv:2209.02976, 2022
-
[43]
Hyper-yolo: When visual object detection meets hypergraph computation,
Y . Feng, J. Huang, S. Du, S. Ying, J.-H. Yong, Y . Li, G. Ding, R. Ji, and Y . Gao, “Hyper-yolo: When visual object detection meets hypergraph computation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 4, pp. 2388–2401, 2024
2024
-
[44]
Fbrt-yolo: Faster and better for real- time aerial image detection,
Y . Xiao, T. Xu, Y . Xin, and J. Li, “Fbrt-yolo: Faster and better for real- time aerial image detection,” inproc. AAAI, vol. 39, no. 8, 2025, pp. 8673–8681
2025
-
[45]
Yolo-ms: Rethinking multi-scale representation learning for real-time object detection,
Y . Chen, X. Yuan, J. Wang, R. Wu, X. Li, Q. Hou, and M.-M. Cheng, “Yolo-ms: Rethinking multi-scale representation learning for real-time object detection,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 47, no. 6, pp. 4240–4252, 2025
2025
-
[46]
Lw-detr: A transformer replacement to yolo for real-time detection,
Q. Chen, X. Su, X. Zhang, J. Wang, J. Chen, Y . Shen, C. Han, Z. Chen, W. Xu, F. Liet al., “Lw-detr: A transformer replacement to yolo for real-time detection,”arXiv preprint arXiv:2406.03459, 2024
-
[47]
Deim: Detr with improved matching for fast convergence,
S. Huang, Z. Lu, X. Cun, Y . Yu, X. Zhou, and X. Shen, “Deim: Detr with improved matching for fast convergence,” inproc. CVPR, 2025, pp. 15 162–15 171
2025
-
[48]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1137–1149, 2016
2016
-
[49]
Mobilemamba: Lightweight multi-receptive visual mamba network,
H. He, J. Zhang, Y . Cai, H. Chen, X. Hu, Z. Gan, Y . Wang, C. Wang, Y . Wu, and L. Xie, “Mobilemamba: Lightweight multi-receptive visual mamba network,” inproc. CVPR, 2025, pp. 4497–4507
2025
-
[50]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inproc. ICCV, 2017, pp. 2980–2988
2017
-
[51]
X. Zhou, D. Wang, and P. Kr ¨ahenb¨uhl, “Objects as points,”arXiv preprint arXiv:1904.07850, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.