Recognition: no theorem link
PeReGrINE: Evaluating Personalized Review Fidelity with User Item Graph Context
Pith reviewed 2026-05-10 17:49 UTC · model grok-4.3
The pith
Restructuring Amazon reviews into a time-ordered user-item graph lets researchers measure how different evidence slices affect the fidelity of generated personalized reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
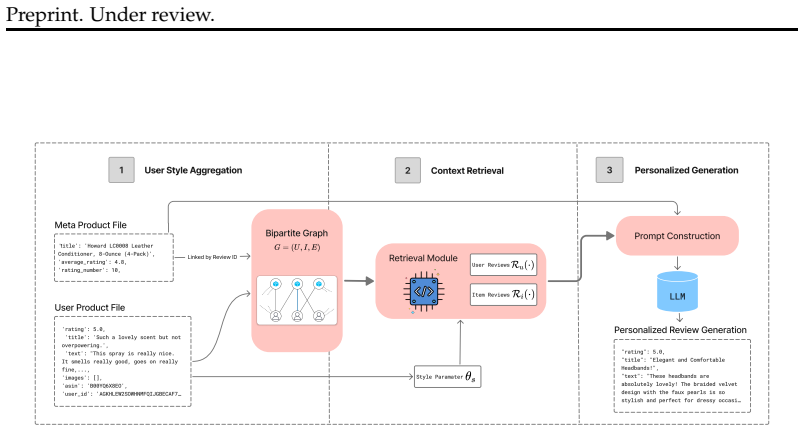
Converting the review collection into a temporally consistent bipartite graph and deriving a User Style Parameter from prior reviews allows systematic comparison of four evidence-retrieval conditions; dissonance from user style and product consensus is lowest when models draw on the full set of graph-derived contexts rather than any isolated source.
What carries the argument
The User Style Parameter, a compact summary of a user's linguistic and affective patterns extracted from earlier reviews, that stands in for raw history while the temporally bounded bipartite graph supplies product, user, and neighbor evidence windows.
If this is right
- Combined graph evidence produces reviews whose style and content align more closely with both the individual user and the product's established consensus than any single evidence type.
- Visual context can raise surface quality in some cases yet does not displace graph-derived textual evidence as the primary driver of personalization.
- The same controlled comparison of evidence composition can be repeated across product categories to reveal category-specific differences in how context affects fidelity.
- Dissonance Analysis supplies a macro-level signal that complements token-level generation metrics when judging review realism.
Where Pith is reading between the lines
- The same graph-restructuring approach could be applied to other user-generated text tasks such as personalized product descriptions or recommendation justifications.
- Varying the size of the evidence windows or the temporal cutoffs would test whether recency weighting changes the observed advantage of combined evidence.
- If the User Style Parameter proves stable, it could serve as a lightweight user embedding for downstream tasks beyond review generation.
- Extending dissonance measurement to track consistency with item metadata or cross-category user behavior would broaden the evaluation.
Load-bearing premise
A compact summary of prior reviews can reliably capture a user's enduring style and that the chosen time windows do not create artificial patterns in the evidence.
What would settle it
Generating reviews with the same models but supplying no graph evidence or random evidence and observing that the resulting dissonance scores are equal to or lower than those obtained with the structured graph contexts.
Figures



read the original abstract
We introduce PeReGrINE, a benchmark and evaluation framework for personalized review generation grounded in graph-structured user--item evidence. PeReGrINE restructures Amazon Reviews 2023 into a temporally consistent bipartite graph, where each target review is conditioned on bounded evidence from user history, item context, and neighborhood interactions under explicit temporal cutoffs. To represent persistent user preferences without conditioning directly on sparse raw histories, we compute a User Style Parameter that summarizes each user's linguistic and affective tendencies over prior reviews. This setup supports controlled comparison of four graph-derived retrieval settings: product-only, user-only, neighbor-only, and combined evidence. Beyond standard generation metrics, we introduce Dissonance Analysis, a macro-level evaluation framework that measures deviation from expected user style and product-level consensus. We also study visual evidence as an auxiliary context source and find that it can improve textual quality in some settings, while graph-derived evidence remains the main driver of personalization and consistency. Across product categories, PeReGrINE offers a reproducible way to study how evidence composition affects review fidelity, personalization, and grounding in retrieval-conditioned language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PeReGrINE, a benchmark and evaluation framework for personalized review generation grounded in graph-structured user-item evidence. It restructures Amazon Reviews 2023 into a temporally consistent bipartite graph with bounded evidence windows and explicit temporal cutoffs. A User Style Parameter summarizes each user's linguistic and affective tendencies from prior reviews to avoid direct conditioning on sparse histories. This enables controlled comparisons of four retrieval settings (product-only, user-only, neighbor-only, and combined evidence). The paper introduces Dissonance Analysis to measure macro-level deviations from expected user style and product consensus, examines visual evidence as auxiliary context, and concludes that graph-derived evidence is the main driver of personalization and consistency across product categories.
Significance. If the core assumptions are validated, PeReGrINE supplies a reproducible, temporally grounded benchmark for studying evidence composition in retrieval-augmented review generation. This is significant for the IR and NLG communities because it offers controlled settings to isolate the contributions of user, item, and neighborhood context, along with a new macro-level tool (Dissonance Analysis) beyond standard generation metrics. The explicit graph restructuring and multi-setting comparison provide a foundation for future work on personalized language models; the reproducible structure and focus on fidelity are clear strengths.
major comments (2)
- [§4.2] §4.2 (User Style Parameter definition): The claim that graph-derived evidence is the main driver of personalization and consistency rests on this parameter accurately proxying persistent linguistic and affective tendencies without the full sparse history. If the parameter is a coarse aggregate (e.g., averaged embeddings or simple statistics), it risks erasing user-specific variability or temporal drift, rendering the four retrieval settings' comparisons against an incomplete baseline and potentially attributing summarization artifacts to genuine graph context gains. A concrete validation (correlation with held-out reviews or ablation on the aggregation method) is required.
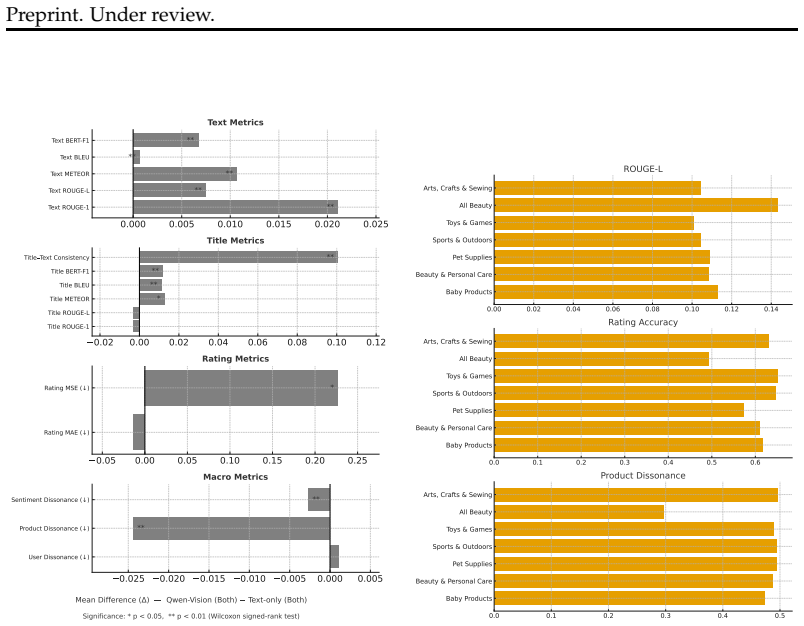
- [Section 5] Section 5 (Experimental results and Dissonance Analysis): The abstract states that visual evidence improves textual quality in some settings while graph evidence remains the main driver, yet no quantitative results, error analysis, statistical significance tests, or per-setting differences are described. Without these, the measurable impact of the four retrieval settings and the consistency gains across categories cannot be assessed, and post-hoc category selection on Amazon products may confound the reported effects.
minor comments (2)
- [Abstract] Abstract: The summary of findings ('we find that...') would be strengthened by including one or two key quantitative highlights or metric values to convey the scale of the reported improvements.
- [Section 3] Notation and reproducibility: Provide explicit equations or pseudocode for the User Style Parameter computation and the exact temporal cutoff / bounded-window selection rules to facilitate exact replication of the graph construction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (User Style Parameter definition): The claim that graph-derived evidence is the main driver of personalization and consistency rests on this parameter accurately proxying persistent linguistic and affective tendencies without the full sparse history. If the parameter is a coarse aggregate (e.g., averaged embeddings or simple statistics), it risks erasing user-specific variability or temporal drift, rendering the four retrieval settings' comparisons against an incomplete baseline and potentially attributing summarization artifacts to genuine graph context gains. A concrete validation (correlation with held-out reviews or ablation on the aggregation method) is required.
Authors: We agree that additional validation of the User Style Parameter is warranted to ensure it does not introduce summarization artifacts. The parameter is intentionally computed as an aggregate summary of prior reviews to capture persistent linguistic and affective tendencies while respecting data sparsity and temporal cutoffs. In the revised manuscript, we will add a dedicated validation subsection that reports Pearson correlations between the parameter and held-out review embeddings, along with an ablation comparing mean aggregation against alternative methods (e.g., weighted or clustering-based summaries). These additions will directly support the claim that graph-derived evidence drives the observed personalization gains beyond any baseline summarization effects. revision: yes
-
Referee: [Section 5] Section 5 (Experimental results and Dissonance Analysis): The abstract states that visual evidence improves textual quality in some settings while graph evidence remains the main driver, yet no quantitative results, error analysis, statistical significance tests, or per-setting differences are described. Without these, the measurable impact of the four retrieval settings and the consistency gains across categories cannot be assessed, and post-hoc category selection on Amazon products may confound the reported effects.
Authors: Section 5 already presents quantitative results for all four retrieval settings, including per-setting metric tables, Dissonance Analysis scores, and category-level consistency breakdowns with accompanying figures. We acknowledge, however, that explicit statistical significance tests and a more granular error analysis would improve interpretability. In the revision we will add paired t-tests (or appropriate non-parametric equivalents) for key comparisons across settings and a new error-analysis subsection examining failure cases by evidence type. Regarding category selection, we will explicitly state that the ten categories were chosen a priori based on having sufficient review volume to support temporal graph construction and bounded evidence windows; this criterion was applied uniformly before any experiments and is not post-hoc. These clarifications will allow readers to better assess the impact of evidence composition. revision: partial
Circularity Check
No circularity: benchmark definition with independent parameter computation
full rationale
The paper presents PeReGrINE as an evaluation benchmark that restructures Amazon Reviews 2023 into a temporally consistent bipartite graph and computes a User Style Parameter as a summary of linguistic and affective tendencies from each user's prior reviews (explicitly excluding the target review). This parameter feeds into Dissonance Analysis to quantify deviation in generated outputs, but the computation is performed on historical data independent of the evaluation target. No equations, derivations, or self-citations are present that reduce any metric or comparison (product-only, user-only, neighbor-only, combined) to the inputs by construction. The four retrieval settings are controlled experimental conditions on the restructured graph, not fitted predictions. The framework is self-contained against external data splits and does not rely on load-bearing self-citations or ansatzes.
Axiom & Free-Parameter Ledger
free parameters (1)
- User Style Parameter
axioms (1)
- domain assumption Amazon Reviews 2023 admits a temporally consistent bipartite graph representation under explicit cutoffs without introducing selection bias
invented entities (1)
-
Dissonance Analysis
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Personalized text gen- eration with fine-grained linguistic control
Bashar Alhafni, Vivek Kulkarni, Dhruv Kumar, and Vipul Raheja. Personalized text gen- eration with fine-grained linguistic control. In Ameet Deshpande, EunJeong Hwang, Vishvak Murahari, Joon Sung Park, Diyi Yang, Ashish Sabharwal, Karthik Narasimhan, and Ashwin Kalyan (eds.),Proceedings of the 1st Workshop on Personalization of Generative AI Systems (PERS...
2024
-
[2]
URLhttps://aclanthology.org/2024.personalize-1.8/
Association for Computational Linguistics. URLhttps://aclanthology.org/2024.personalize-1.8/. Steven Au, Cameron J Dimacali, Ojasmitha Pedirappagari, Namyong Park, Franck Dernon- court, Yu Wang, Nikos Kanakaris, Hanieh Deilamsalehy, Ryan A Rossi, and Nesreen K Ahmed. Personalized graph-based retrieval for large language models.arXiv preprint arXiv:2501.02157,
-
[3]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Person- aLLM: Investigating the ability of large language models to express personality traits
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. Person- aLLM: Investigating the ability of large language models to express personality traits. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Findings of the Association for Computational Linguistics: NAACL 2024, pp. 3605–3627, Mexico City, Mexico, June
2024
-
[5]
Association for Computational Linguistics. doi: 10.18653/v1/2024.findings-naacl.229. URLhttps://aclanthology.org/2024.findings-naacl.229/. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K ¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval- augmented generation for knowledge-intens...
-
[6]
doi: 10.18653/v1/2024.customnlp4u-1.16
Association for Computational Linguistics. doi: 10.18653/v1/2024.customnlp4u-1.16. URL https:// aclanthology.org/2024.customnlp4u-1.16/. Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. LaMP: When large language models meet personalization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pp. ...
-
[7]
L a MP : When Large Language Models Meet Personalization
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.399. URL https://aclanthology.org/2024.acl-long.399. Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. Kgat: Knowledge graph attention network for recommendation. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 9...
-
[8]
An Yan, Yuhan Liu, Shuo Zhang, Ee-Peng Lim, and Jing Han
URL https://arxiv.org/abs/1901.08149. An Yan, Yuhan Liu, Shuo Zhang, Ee-Peng Lim, and Jing Han. Personalized showcases: Generating multi-modal explanations for recommendations. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1027–1036,
-
[9]
Association for Computational Linguistics. doi: 10.18653/v1/P18-1205. URL https://aclanthology.org/P18-1205/. A Data Processing Pipeline To construct PeReGrINE, we processed Amazon Reviews 2023 (Hou et al.,
-
[10]
A.1 Pre-Processing and Graph Construction The raw dataset is sparse and noisy
with a filtering and indexing pipeline designed to preserve temporal integrity while remaining practical for large product categories. A.1 Pre-Processing and Graph Construction The raw dataset is sparse and noisy. We retained only reviews posted after January 1, 2016, removed duplicates, and enforced minimum interaction counts for both items and users. In...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.