Recognition: no theorem link
TEMPER: Testing Emotional Perturbation in Quantitative Reasoning
Pith reviewed 2026-05-10 18:04 UTC · model grok-4.3
The pith
Emotional framing reduces LLM accuracy on quantitative tasks by 2-10 percentage points even when all numbers and logic remain identical.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Emotional variants of quantitative reasoning problems cause a consistent drop in model accuracy compared to neutral versions, and neutralizing the emotion restores performance, demonstrating that stylistic emotional content specifically impairs reasoning.
What carries the argument
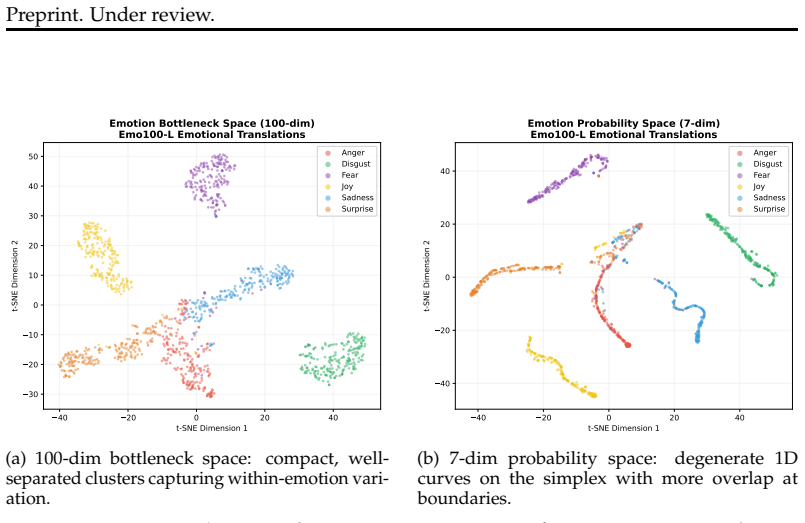
The emotion translation framework that rewrites neutral problems into emotional variants while preserving all quantities and relationships exactly, supported by semantic verification to create the Temper-5400 benchmark of 5,400 pairs.
If this is right
- Emotional framing produces measurable accuracy drops of 2-10 points on GSM8K, MultiArith, and ARC-Challenge across model sizes from 1B to frontier scale.
- Neutralizing emotional language at inference time recovers most of the performance lost to emotional framing.
- Non-emotional paraphrases cause no accuracy degradation, isolating the effect to emotional content rather than surface changes.
- The translation procedure provides a general method for constructing controlled stylistic variants to test model robustness on other attributes.
Where Pith is reading between the lines
- Models could gain robustness by training on datasets that include controlled emotional variants of the same underlying problems.
- The same translation technique might reveal similar sensitivities in non-quantitative tasks where emotional language appears in prompts.
- Inference pipelines could routinely apply neutralization steps before reasoning tasks to improve reliability on real-world queries.
Load-bearing premise
The emotion translation framework preserves all quantities and relationships exactly, with semantic verification ensuring no content corruption.
What would settle it
Finding no accuracy difference between emotional and neutral versions of the same problems on the evaluated models, or observing that neutralization fails to recover the lost performance.
Figures



read the original abstract
Large language models are trained and evaluated on quantitative reasoning tasks written in clean, emotionally neutral language. However, real-world queries are often wrapped in frustration, urgency or enthusiasm. Does emotional framing alone degrade reasoning when all numerical content is preserved? To investigate this, a controlled emotion translation framework is developed that rewrites problems into emotional variants while preserving all quantities and relationships. Using this framework, Temper-5400 (5,400 semantically verified emotion--neutral pairs) is constructed across GSM8K, MultiArith, and ARC-Challenge, and evaluated on eighteen models (1B to frontier scale). Two core results emerge: First, emotional framing reduces accuracy by 2-10 percentage points even though all numerical content is preserved. Second, neutralizing emotional variants recovers most of the lost performance, showing both that the degradation is tied to emotional style rather than content corruption and that neutralization can serve as a lightweight inference-time mitigation. Non-emotional paraphrases cause no such degradation, implicating emotional content rather than surface-level changes. Beyond emotion specifically, the benchmark construction procedure provides a general framework for controlled stylistic translation and robustness evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a controlled emotion translation framework that rewrites quantitative reasoning problems into emotional variants while preserving all quantities and relationships. It constructs the Temper-5400 dataset of 5,400 semantically verified emotion-neutral pairs from GSM8K, MultiArith, and ARC-Challenge. Evaluation on 18 models shows emotional framing reduces accuracy by 2-10 percentage points, with neutralization recovering most lost performance, and non-emotional paraphrases causing no degradation.
Significance. If the preservation of content is confirmed, the results indicate that emotional style in problem statements can significantly impact LLM performance on quantitative tasks, even when numbers and operations are identical. This has implications for the robustness of LLMs in real-world applications where emotional language is prevalent. The neutralization technique provides a potential lightweight fix, and the framework offers a template for testing other stylistic factors. The scale of the evaluation across multiple models and datasets adds to its potential impact.
major comments (1)
- The abstract states that the framework 'preserves all quantities and relationships' and that pairs are 'semantically verified,' yet no description of the verification procedure is provided (human review, automated checks for numerical equality and operator identity, inter-annotator agreement?). This is load-bearing for the headline result, as subtle changes could produce the observed degradation without emotional effect.
minor comments (2)
- The range of accuracy reduction (2-10 percentage points) is broad; providing more granular results per model size or dataset would strengthen the presentation.
- No details on statistical significance tests or error analysis are mentioned, which would help assess the reliability of the reported drops.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for highlighting the importance of transparency in our verification procedure. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The abstract states that the framework 'preserves all quantities and relationships' and that pairs are 'semantically verified,' yet no description of the verification procedure is provided (human review, automated checks for numerical equality and operator identity, inter-annotator agreement?). This is load-bearing for the headline result, as subtle changes could produce the observed degradation without emotional effect.
Authors: We agree that a detailed account of the verification procedure is essential to substantiate the claim that emotional framing, rather than content alteration, drives the observed accuracy drops. The current manuscript describes the overall construction pipeline in Section 3 but does not provide a dedicated, explicit subsection on verification steps. We will revise the paper to add a new subsection (3.3) that specifies: (1) automated checks confirming exact numerical equality and operator/relationship identity across each emotion-neutral pair, (2) the human review protocol (three independent annotators per pair, with instructions to flag any semantic drift or quantity change), and (3) the resulting inter-annotator agreement (Cohen's kappa). We will also reference this procedure from the abstract and introduction for visibility. These additions directly address the load-bearing concern and will be included in the revised version. revision: yes
Circularity Check
No circularity: empirical dataset construction and evaluation
full rationale
The paper's core contribution is the construction of the Temper-5400 benchmark via an emotion translation framework that produces semantically verified pairs, followed by direct accuracy measurements across 18 models on GSM8K, MultiArith, and ARC-Challenge. No derivations, first-principles predictions, fitted parameters, or self-referential equations are present. Results (2-10 pp accuracy drop from emotional framing, recovery via neutralization) are reported as empirical observations rather than outputs that reduce to the inputs by construction. Non-emotional paraphrases are used as a control, but this remains a comparative measurement without definitional loops or load-bearing self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Emotional variants can be created while exactly preserving numerical content and relationships
Reference graph
Works this paper leans on
-
[1]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Han- naneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms.arXiv preprint arXiv:1905.13319,
work page Pith review arXiv 1905
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Dhariwal Prafulla, Timo Pohl, Alec Radford, Ilya Sutskever, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cheng Li, Jindong Wang, Yixuan Zhang, Kaijie Zhu, Wenxin Hou, Jianxun Lian, Fang Luo, Qiang Yang, and Xing Xie. Large language models understand and can be enhanced by emotional stimuli.arXiv preprint arXiv:2307.11760, 2024a. Qintong Li, Leyang Cui, Xueliang Zhao, Lingpeng Kong, and Wei Bi. GSM-Plus: A com- prehensive benchmark for evaluating the robustne...
-
[7]
Dear sir or madam, may I introduce the GYAFC dataset: Quantifying formality of text through crowdsourcing
Sudha Rao and Joel Tetreault. Dear sir or madam, may I introduce the GYAFC dataset: Quantifying formality of text through crowdsourcing. InProceedings of the 2018 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 129–140,
2018
-
[8]
10 Preprint. Under review. Benjamin Reichman, Adar Avsian, Kartik Talamadupula, Toshish Jawale, and Larry Heck. Emotional RAG LLMs: Reading comprehension for the open internet.arXiv preprint arXiv:2408.11189,
-
[9]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pp. 1743–1752,
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.