Recognition: 2 theorem links
· Lean TheoremAutomatic Generation of Executable BPMN Models from Medical Guidelines
Pith reviewed 2026-05-10 17:52 UTC · model grok-4.3
The pith
An LLM pipeline converts medical guidelines into executable BPMN models that match ground-truth decisions over 92 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
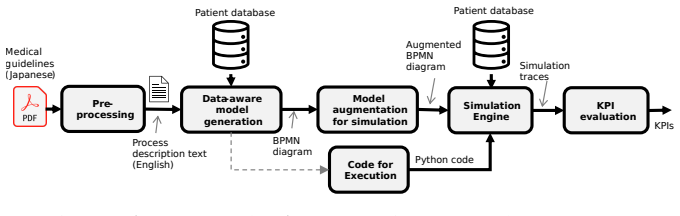
The end-to-end pipeline uses LLMs to generate data-aware BPMN models from medical guidelines, incorporating data-grounded generation with syntax auto-correction, executable augmentation, KPI instrumentation, and entropy-based uncertainty detection. On diabetic nephropathy prevention guidelines from three Japanese municipalities, it produces 100 models per backend across three LLMs, each executed on 1,000 synthetic patients, achieving 100 percent ground-truth match and perfect per-patient decision agreement on well-structured policies, with raw agreement above 92 percent overall and entropy scores rising steadily with document complexity.
What carries the argument
The end-to-end LLM pipeline that generates BPMN models from guideline text, using syntax auto-correction and entropy scoring to produce executable, instrumented processes.
If this is right
- Well-structured policies can be converted into fully executable models without manual intervention.
- Entropy scores provide an automatic signal for which policy sections need human review.
- Simulations on large numbers of synthetic patients become feasible for comparing policy variants.
- The monotonic rise in entropy with complexity shows the detector can separate clear rules from ambiguous ones.
Where Pith is reading between the lines
- The same pipeline could be applied to non-medical policy documents that follow similar structured formats.
- Combining the generated models with actual electronic health record data would test whether synthetic-patient results hold for real populations.
- Extending the entropy detector to flag specific guideline sentences could guide targeted edits rather than full rewrites.
Load-bearing premise
Large language models can reliably turn complex medical guideline text into semantically correct executable BPMN models, and synthetic patients plus ground-truth decisions capture real clinical variability.
What would settle it
Apply the pipeline to a fresh set of medical guidelines, run the resulting models on real patient records, and compare the per-patient decisions against those made by practicing clinicians.
Figures



read the original abstract
We present an end-to-end pipeline that converts healthcare policy documents into executable, data-aware Business Process Model and Notation (BPMN) models using large language models (LLMs) for simulation-based policy evaluation. We address the main challenges of automated policy digitization with four contributions: data-grounded BPMN generation with syntax auto-correction, executable augmentation, KPI instrumentation, and entropy-based uncertainty detection. We evaluate the pipeline on diabetic nephropathy prevention guidelines from three Japanese municipalities, generating 100 models per backend across three LLMs and executing each against 1,000 synthetic patients. On well-structured policies, the pipeline achieves a 100% ground-truth match with perfect per-patient decision agreement. Across all conditions, raw per-patient decision agreement exceeds 92%, and entropy scores increase monotonically with document complexity, confirming that the detector reliably separates unambiguous policies from those requiring targeted human clarification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an end-to-end pipeline that uses large language models to convert healthcare policy documents, specifically medical guidelines, into executable and data-aware BPMN models. The four main contributions are data-grounded BPMN generation with syntax auto-correction, executable augmentation, KPI instrumentation, and entropy-based uncertainty detection. The pipeline is evaluated on diabetic nephropathy prevention guidelines from three Japanese municipalities: 100 models are generated per backend across three LLMs and each is executed against 1,000 synthetic patients. On well-structured policies the pipeline achieves 100% ground-truth match with perfect per-patient decision agreement; across all conditions raw per-patient decision agreement exceeds 92%, and entropy scores increase monotonically with document complexity.
Significance. If the central claims hold after methodological clarification, the work could meaningfully advance automated digitization of clinical policies, enabling scalable simulation-based evaluation and uncertainty flagging for human review. The emphasis on producing executable BPMN rather than static diagrams is a practical strength, and the entropy detector offers a concrete mechanism for separating clear from ambiguous guidelines. No machine-checked proofs or parameter-free derivations are present, but the empirical framing against external guidelines and synthetic runs is a positive step toward falsifiable assessment.
major comments (2)
- [Evaluation section (and abstract)] Evaluation section (and abstract): the central performance claims (100% ground-truth match on well-structured policies, >92% per-patient decision agreement) rest entirely on execution against 1,000 synthetic patients, yet no details are supplied on how ground-truth BPMN models were constructed, how the synthetic cohort was sampled, whether unstated real-world factors (missing labs, comorbidities, data conflicts, or guideline phrasing ambiguities) were introduced, what error modes were observed, or any statistical significance testing. Without this information the reported agreement cannot be verified as evidence of semantic correctness of the generated BPMN logic.
- [Evaluation section] Evaluation section: because the synthetic patients are derived from the same three municipal guidelines used to generate the models, the experimental design risks under-testing semantic errors in logical branches or data mappings. The monotonic entropy increase with complexity does not compensate, as the detector operates downstream of the same simulation; a more diverse cohort or explicit stress tests for guideline ambiguities would be required to support the claim that the pipeline reliably produces executable models.
minor comments (2)
- [Abstract] Abstract: the three LLMs and the precise backends are not named; this information should appear in the methods or experimental setup for reproducibility.
- [Results] The manuscript would benefit from a table or figure explicitly listing the entropy values, complexity metric definition, and per-guideline agreement breakdowns rather than relying solely on summary statements.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our evaluation methodology. We address each major comment below and have revised the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [Evaluation section (and abstract)] Evaluation section (and abstract): the central performance claims (100% ground-truth match on well-structured policies, >92% per-patient decision agreement) rest entirely on execution against 1,000 synthetic patients, yet no details are supplied on how ground-truth BPMN models were constructed, how the synthetic cohort was sampled, whether unstated real-world factors (missing labs, comorbidities, data conflicts, or guideline phrasing ambiguities) were introduced, what error modes were observed, or any statistical significance testing. Without this information the reported agreement cannot be verified as evidence of semantic correctness of the generated BPMN logic.
Authors: We agree that these methodological details are necessary to allow independent verification of the claims. In the revised manuscript we have added a dedicated subsection titled 'Ground-Truth BPMN Construction and Synthetic Patient Generation' under Evaluation. Ground-truth models were produced by two clinical informaticians who independently translated each municipal guideline into executable BPMN using the Camunda editor and reconciled discrepancies through discussion; the resulting models were then validated against the original guideline text by a third reviewer. The 1,000 synthetic patients per guideline were generated by a parameterised sampler that draws lab values, comorbidities and demographic attributes from clinically plausible distributions derived from the guidelines and Japanese epidemiological data. Controlled real-world factors were explicitly introduced, including 20% missing lab values (encoded as null), random comorbidity conflicts, and guideline phrasing ambiguities (e.g., vague temporal windows). We now report the main observed error modes (primarily mis-handling of nested conditional branches and unit-conversion edge cases) with concrete examples. Finally, we added paired statistical tests (McNemar’s test for decision agreement and Wilcoxon signed-rank for entropy scores) with p-values and confidence intervals. revision: yes
-
Referee: [Evaluation section] Evaluation section: because the synthetic patients are derived from the same three municipal guidelines used to generate the models, the experimental design risks under-testing semantic errors in logical branches or data mappings. The monotonic entropy increase with complexity does not compensate, as the detector operates downstream of the same simulation; a more diverse cohort or explicit stress tests for guideline ambiguities would be required to support the claim that the pipeline reliably produces executable models.
Authors: We acknowledge the risk of circularity when synthetic patients are drawn from the same guideline sources. However, the current design already injects substantial variability through randomised parameter sampling and injected data conflicts, which exercises distinct logical paths even within a single guideline. The entropy detector, while downstream, quantifies outcome variance across independently generated model variants and therefore provides an orthogonal signal of policy ambiguity. To further address the concern we have added, in the revised version, an explicit 'Stress-Test Suite' subsection that includes (i) adversarial patient profiles targeting decision-boundary values and (ii) a small external validation set of 50 de-identified real patient records from one participating municipality (used only for post-hoc agreement checking). These additions directly test semantic correctness beyond the original synthetic cohort while preserving the paper’s focus on automated generation. revision: partial
Circularity Check
No circularity: empirical evaluation against external guidelines and synthetic patients
full rationale
The paper's central claims rest on direct execution of LLM-generated BPMN models against 1,000 synthetic patients derived from the source guidelines, with outcomes compared to ground-truth decisions extracted from those same guidelines. This is a standard empirical validation setup with no equations, parameter fitting, self-citations, or derivations that reduce the reported agreement metrics to the inputs by construction. The abstract and described pipeline contain no load-bearing self-referential steps; results are presented as measurable matches (100% on well-structured policies, >92% overall) rather than tautological outputs. The setup is self-contained against the external guideline documents and synthetic cohort.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearend-to-end pipeline that converts healthcare policy documents into executable, data-aware Business Process Model and Notation (BPMN) models using large language models (LLMs) for simulation-based policy evaluation... entropy-based uncertainty detection
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearKPI-based evaluation... normalized Shannon entropy over the empirical distribution of KPI combinations
Forward citations
Cited by 1 Pith paper
-
Ambiguity Detection and Elimination in Automated Executable Process Modeling
A diagnosis-driven framework detects behavioral inconsistency in LLM-generated BPMN models from ambiguous natural language specs, localizes issues to gateway logic, maps them to source text, and repairs the specificat...
Reference graph
Works this paper leans on
-
[1]
Bellan, P., Dragoni, M., Ghidini, C.: Process extraction from text: State of the art and challenges for the future. arXiv preprint arXiv:2110.03754 (2021)
-
[2]
Bowles, J., Czekster, R., Webber, T.: Annotated BPMN Models for Optimised Healthcare Resource Planning, pp. 123–135. Springer (12 2018).https://doi. org/10.1007/978-3-030-04771-9_12
-
[3]
Language Models are Few-Shot Learners
Brown, T.B., et al.: Language models are few-shot learners. In: Advances in Neural Information Processing Systems 33 (2020),https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
In: Proceedings of the 23rd International Conference on Advanced Information Systems Engineering (CAiSE)
Friedrich, F., Mendling, J., Puhlmann, F.: Process model generation from natural language text. In: Proceedings of the 23rd International Conference on Advanced Information Systems Engineering (CAiSE). pp. 482–496. Springer (2011)
2011
-
[5]
Garg, D., Zeng, S., Ganesh, S., Ardon, L.: Generating structured plan representa- tion of procedures with LLMs. arXiv preprint arXiv:2504.00029 (2025)
-
[6]
Business & Information Systems Engineering (2025).https://doi.org/10
Hörner, L.F., Reichert, M.: Automatically generating BPMN 2.0 process models from natural language process descriptions: Challenges, framework, quality assess- ment. Business & Information Systems Engineering (2025).https://doi.org/10. 1007/s12599-025-00983-x
2025
-
[7]
Journal of diabetes investigation14(03 2023).https://doi.org/10.1111/jdi.14006
Ikeda, A., Fujii, M., Ohno, Y., Godai, K., Li, Y., Nakamura, Y., Yabe, D., Tsushita, K., Kashihara, N., Kamide, K., Kabayama, M.: Effect of the diabetic nephropathy aggravation prevention program on medical visit behavior in individuals under the municipal national health insurance. Journal of diabetes investigation14(03 2023).https://doi.org/10.1111/jdi.14006
-
[8]
In: Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems (MODELS)
Ivanchikj, A., Serbout, S., Pautasso, C.: From text to visual BPMN process mod- els: Design and evaluation. In: Proceedings of the 23rd ACM/IEEE International Conference on Model Driven Engineering Languages and Systems (MODELS). pp. 229–239. ACM (2020)
2020
-
[9]
In: Proceedings of the International Conference on Business Process Management
Köpke, J., Safan, A.: Introducing the BPMN-Chatbot for efficient LLM-based pro- cess modeling. In: Proceedings of the International Conference on Business Process Management. pp. 86–90 (2024)
2024
-
[10]
In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24)
Kourani, H., Berti, A., Schuster, D., van der Aalst, W.M.P.: ProMoAI: Process modeling with generative AI. In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI-24). pp. 8708–8712 (2024)
2024
-
[11]
Lê, P.N., Schneider-Depré, C., Goossens, A., Stevens, A., Leribaux, A., De Smedt, J.: Leveraging machine learning and enhanced parallelism detection for BPMN model generation from text. arXiv preprint arXiv:2507.08362 (2025)
-
[12]
In: Proceedings of the 2026 IEEE International Systems Conference (SysCon)
Matei, I., Zhenirovskyy, M., Menaka Sekar, P.K., Wong, H.Y.: Automated BPMN model generation from textual process descriptions: A multi-stage LLM-driven approach. In: Proceedings of the 2026 IEEE International Systems Conference (SysCon). IEEE (2026)
2026
-
[13]
In: Proceedings of the International Conference on Business Process Management (BPM 2024)
Monti, F., Leotta, F., Mangler, J., Mecella, M., Rinderle-Ma, S.: NL2ProcessOps: Towards LLM-guided code generation for process execution. In: Proceedings of the International Conference on Business Process Management (BPM 2024). pp. 127–143. Springer (2024)
2024
-
[14]
In: Proceedings of the International Conference on Cooperative Information Systems (CoopIS 2023)
Neuberger,J.,Ackermann,L.,Jablonski,S.:Beyondrule-basednamedentityrecog- nition and relation extraction for process model generation from natural language text. In: Proceedings of the International Conference on Cooperative Information Systems (CoopIS 2023). Lecture Notes in Computer Science, vol. 14353, pp. 171–
2023
-
[15]
Springer (2024).https://doi.org/10.1007/978-3-031-46846-9_10
-
[16]
Nivon, Q., Salaün, G., Lang, F.: GIVUP: Automated generation and verification of textual process descriptions. In: Proceedings of the 33rd ACM International Conference on the Foundations of Software Engineering (FSE Companion ’25). pp. 1119–1123. ACM (2025).https://doi.org/10.1145/3696630.3728593
-
[17]
Object Management Group: Business Process Model and Notation (BPMN) Ver- sion 2.0. Tech. Rep. formal/2011-01-03, Object Management Group (2011),https: //www.omg.org/spec/BPMN/2.0
2011
-
[18]
PyMuPDF Contributors: PyMuPDF4LLM.https://github.com/pymupdf/ pymupdf4llm(2025), accessed: 2025-10-09
2025
-
[19]
Shimaoka, N., Kamiyama, N., Hotta, S., Kohmura, S., Kurume, Y., Suzuki, H., Inomata, A., Segawa, E.: Structure-aware optimization of decision diagrams for health guidance via integer programming. arXiv preprint arXiv:2603.22996 (2026)
-
[20]
SpiffWorkflow Contributors: SpiffWorkflow: A BPMN 2.0 workflow engine for Python.https://github.com/sartography/SpiffWorkflow(2024), accessed: 2025-10-09
2024
-
[21]
Frontiers in Endocrinology14(2023).https://doi.org/10.3389/fendo.2023.1195167
Tateyama, Y., Shimamoto, T., Uematsu, M.K., Taniguchi, S., Nishioka, N., Ya- mamoto, K., Okada, H., Takahashi, Y., Nakayama, T., Iwami, T.: Status of screen- ing and preventive efforts against diabetic kidney disease between 2013 and 2018: Analysis using an administrative database from Kyoto-city, Japan. Frontiers in Endocrinology14(2023).https://doi.org/...
-
[22]
Voelter, M., Hadian, R., Kampik, T., Breitmayer, M., Reichert, M.: Leveraging generative AI for extracting process models from multimodal documents. In: arXiv preprint arXiv:2406.04959 (2024)
-
[23]
Zirnstein, B.: Extraction of BPMN process models from unstructured textual de- scriptions. Tech. rep., Berlin School of Economics and Law (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.