Recognition: 1 theorem link
· Lean TheoremHarnessing Embodied Agents: Runtime Governance for Policy-Constrained Execution
Pith reviewed 2026-05-10 18:00 UTC · model grok-4.3
The pith
Embodied agents achieve reliable policy compliance when cognition is separated from an external runtime governance layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
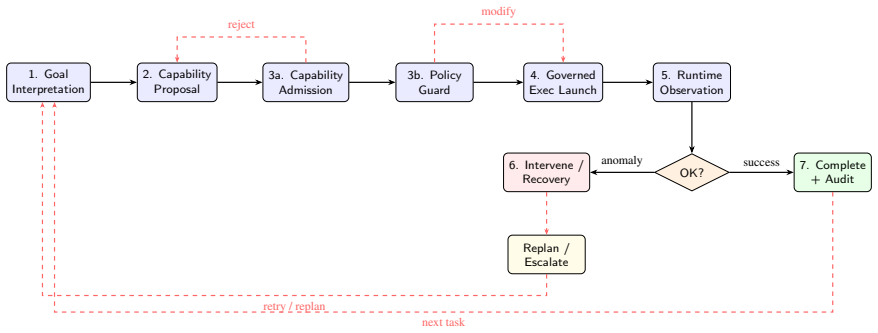
Embodied intelligence demands not only capable agents but also robust external oversight at runtime. The proposed framework externalizes safety and control functions into a dedicated governance layer, formalizing the boundaries with the agent and Embodied Capability Modules to enable standardized policy enforcement. Validation across 1000 randomized trials confirms high rates of unauthorized action interception, reduced unsafe continuations under drift, and successful recovery to compliance.
What carries the argument
The runtime governance layer, external to the agent, that executes policy checking, capability admission, execution monitoring, rollback handling, and human override while maintaining formalized control boundaries with the embodied agent and Embodied Capability Modules (ECMs).
Load-bearing premise
The randomized simulation trials accurately reflect real-world conditions for policy violations, runtime drift, and recovery in embodied agents, and the governance layer can be added without creating new vulnerabilities or inefficiencies.
What would settle it
Deploying the governance layer on physical robots in a real environment and measuring whether unauthorized actions are intercepted at rates close to 96% without introducing delays or security risks.
Figures


read the original abstract
Embodied agents are evolving from passive reasoning systems into active executors that interact with tools, robots, and physical environments. Once granted execution authority, the central challenge becomes how to keep actions governable at runtime. Existing approaches embed safety and recovery logic inside the agent loop, making execution control difficult to standardize, audit, and adapt. This paper argues that embodied intelligence requires not only stronger agents, but stronger runtime governance. We propose a framework for policy-constrained execution that separates agent cognition from execution oversight. Governance is externalized into a dedicated runtime layer performing policy checking, capability admission, execution monitoring, rollback handling, and human override. We formalize the control boundary among the embodied agent, Embodied Capability Modules (ECMs), and runtime governance layer, and validate through 1000 randomized simulation trials across three governance dimensions. Results show 96.2% interception of unauthorized actions, reduction of unsafe continuation from 100% to 22.2% under runtime drift, and 91.4% recovery success with full policy compliance, substantially outperforming all baselines (p<0.001). By reframing runtime governance as a first-class systems problem, this paper positions policy-constrained execution as a key design principle for embodied agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes separating agent cognition from execution oversight in embodied agents via a dedicated runtime governance layer that handles policy checking, capability admission, monitoring, rollback, and human overrides. It formalizes the control boundary between the embodied agent, Embodied Capability Modules (ECMs), and this governance layer, then validates the approach with 1000 randomized simulation trials across three governance dimensions, claiming 96.2% interception of unauthorized actions, reduction of unsafe continuation from 100% to 22.2% under runtime drift, 91.4% recovery success with full compliance, and statistically significant outperformance of baselines (p<0.001).
Significance. If the reported simulation results prove robust and transferable, the work could meaningfully advance safety engineering for embodied systems by reframing runtime governance as an external, auditable systems layer rather than an agent-internal concern. The quantitative deltas versus baselines and the emphasis on policy-constrained execution provide a concrete design principle that could influence standards for tool-using and robotic agents. The absence of disclosed generative models for the simulations, however, currently caps the significance at the level of a promising but unverified framework.
major comments (3)
- Simulation experiments section: The 1000 randomized trials are the sole empirical support for the headline metrics (96.2% interception, 22.2% unsafe continuation, 91.4% recovery). No state-transition rules, parameter distributions, or generative models for policy violations, runtime drift, or rollback are supplied, preventing assessment of whether the results remain valid under sensor noise, actuator latency, or partial observability that occur on real hardware.
- Formalization of control boundary: The separation among agent, ECMs, and runtime governance layer is presented as a central contribution, yet the manuscript supplies no interface definitions, state-machine diagrams, or interface contracts that would allow independent implementation or auditing. This omission directly affects the claim that governance can be standardized and adapted independently of the agent.
- Baseline comparison: The paper states that the governance layer “substantially outperforming all baselines (p<0.001),” but neither the identity of the baselines nor their implementation details (e.g., whether they embed safety logic inside the agent loop) are described, rendering the statistical claim impossible to reproduce or contextualize.
minor comments (2)
- The abstract refers to “three governance dimensions” without enumerating them; the experimental section should list these dimensions explicitly.
- Terminology: “Embodied Capability Modules (ECMs)” is introduced without a clear mapping to existing concepts such as skill libraries or tool-use APIs in the robotics literature; a short related-work paragraph would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will incorporate the requested clarifications and additions into the revised manuscript.
read point-by-point responses
-
Referee: Simulation experiments section: The 1000 randomized trials are the sole empirical support for the headline metrics (96.2% interception, 22.2% unsafe continuation, 91.4% recovery). No state-transition rules, parameter distributions, or generative models for policy violations, runtime drift, or rollback are supplied, preventing assessment of whether the results remain valid under sensor noise, actuator latency, or partial observability that occur on real hardware.
Authors: We agree that the current description of the simulation experiments is insufficient for full reproducibility and robustness assessment. In the revised manuscript we will add explicit state-transition rules, the parameter distributions governing policy violations and runtime drift, the generative models used to produce the 1000 trials, and a dedicated subsection analyzing sensitivity to sensor noise, actuator latency, and partial observability within the simulation environment. revision: yes
-
Referee: Formalization of control boundary: The separation among agent, ECMs, and runtime governance layer is presented as a central contribution, yet the manuscript supplies no interface definitions, state-machine diagrams, or interface contracts that would allow independent implementation or auditing. This omission directly affects the claim that governance can be standardized and adapted independently of the agent.
Authors: We concur that the control-boundary formalization requires more concrete artifacts. The revised manuscript will include explicit interface definitions, state-machine diagrams for the interactions among the embodied agent, ECMs, and governance layer, and pseudocode specifying the contracts for capability admission, monitoring, and rollback. revision: yes
-
Referee: Baseline comparison: The paper states that the governance layer “substantially outperforming all baselines (p<0.001),” but neither the identity of the baselines nor their implementation details (e.g., whether they embed safety logic inside the agent loop) are described, rendering the statistical claim impossible to reproduce or contextualize.
Authors: We will expand the experimental section to name each baseline, describe whether safety logic is embedded inside the agent loop or handled externally, and supply the exact statistical procedures and p-value calculations used for the reported comparisons. revision: yes
Circularity Check
No circularity; framework and simulation results are independent of inputs
full rationale
The paper introduces a new runtime governance framework separating agent cognition from oversight, formalizes the agent/ECM/governance boundary as a conceptual contribution, and reports empirical performance from 1000 randomized simulation trials. No equations, parameters, or predictions reduce by construction to prior fits, self-citations, or ansatzes. The reported metrics (96.2% interception, 22.2% unsafe continuation, 91.4% recovery) are simulation outputs rather than tautological renamings or self-defined quantities. The derivation chain is self-contained against external benchmarks with no load-bearing self-citation or definitional loops.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embodied agents can have their execution separated from a governance layer without loss of functionality.
- domain assumption Simulation trials with randomized scenarios sufficiently represent real-world execution risks.
invented entities (2)
-
Embodied Capability Modules (ECMs)
no independent evidence
-
Runtime governance layer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize the control boundary among the embodied agent, Embodied Capability Modules (ECMs), and runtime governance layer... Et = GOV(Pt, Ci, Πt, Γt, Ωt)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
EmbodiedGovBench: A Benchmark for Governance, Recovery, and Upgrade Safety in Embodied Agent Systems
EmbodiedGovBench is a new benchmark framework that measures embodied agent systems on seven governance dimensions including policy adherence, recovery success, and upgrade safety.
-
Federated Single-Agent Robotics: Multi-Robot Coordination Without Intra-Robot Multi-Agent Fragmentation
Multi-robot coordination is achieved by federating single-agent robot runtimes at the fleet level instead of fragmenting each robot into multiple internal agents.
-
ECM Contracts: Contract-Aware, Versioned, and Governable Capability Interfaces for Embodied Agents
ECM Contracts define a six-dimensional contract model for embodied capability modules that enables static checks for safe composition, installation, and versioned upgrades in robotics systems.
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding,et al., “RT-1: Robotics Transformer for real-world control at scale,” inRobotics: Science and Systems (RSS), 2023
2023
-
[2]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Hausman,et al., “RT-2: Vision- language-action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
PaLM-E: An embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu,et al., “PaLM-E: An embodied multimodal language model,” inProc. ICML, 2023
2023
-
[4]
Toolformer: Language Models Can Teach Themselves to Use Tools
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”arXiv preprint arXiv:2302.04761, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. Int. Conf. Learning Representations (ICLR), 2023
2023
-
[6]
ChatGPT for Robotics: Design principles and model abilities,
S. Vemprala, R. Bonatti, A. Bucker, and A. Kapoor, “ChatGPT for Robotics: Design principles and model abilities,”IEEE Access, vol. 12, pp. 36857–36872, 2024
2024
-
[7]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn,et al., “Do as I can, not as I say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review arXiv 2022
-
[8]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” inProc. IEEE ICRA, 2023
2023
-
[9]
RoboClaw: Agentic robotic framework for scalable and long-horizon task execution with VLMs,
Y . Yang, Z. Jiang, Y . Zhang, J. Xu, and J. Zhu, “RoboClaw: Agentic robotic framework for scalable and long-horizon task execution with VLMs,”arXiv preprint arXiv:2503.07833, 2025
-
[10]
Inner Monologue: Embodied Reasoning through Planning with Language Models
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Cheb- otar,et al., “Inner monologue: Embodied reasoning through planning with language models,”arXiv preprint arXiv:2207.05608, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxPoser: Composable 3D value maps for robotic manipulation with language models,”arXiv preprint arXiv:2307.05973, 2023. 32
work page internal anchor Pith review arXiv 2023
-
[12]
arXiv preprint arXiv:2603.16952 , year=
U. Grover, R. Ranjan, M. Mao, T. T. Dong, S. Praveen, Z. Wu, J. M. Chang, T. Mohsenin, Y . Sheng, A. Polyzou, E. Kanjo, and X. Lin, “Embodied foundation models at the edge: A survey of deployment constraints and mitigation strategies,”arXiv preprint arXiv:2603.16952, 2026
-
[13]
AEROS: A Single-Agent Operating Architecture with Embodied Capability Modules
Qin, X., Luan, S., See, J., Yang, C., Li, Z.: AEROS: Agent execution runtime operating system for embodied robots. arXiv preprint arXiv:2604.07039 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Harness Engineering,
M. Fowler, “Harness Engineering,” martinfowler.com, 2025. [Online]. Available:https:// martinfowler.com/articles/exploring-gen-ai/harness-engineering.html
2025
-
[15]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Lin, W. X. Zhao, Z. Wei, and J. Wen, “A survey on large language model based autonomous agents,”Frontiers of Com- puter Science, vol. 18, no. 6, 2024
2024
-
[16]
Chameleon: Plug-and-play compositional reasoning with large language models
P. Lu, B. Peng, H. Cheng, M. Galley, K.-W. Chang, Y . N. Wu, S.-C. Zhu, and J. Gao, “Chameleon: Plug-and-play compositional reasoning with large language models,”arXiv preprint arXiv:2304.09842, 2023
-
[17]
Y . Wang, F. Xu, Z. Lin, G. He, Y . Huang, H. Gao, Z. Niu, S. Lian, and Z. Liu, “From assistant to double agent: Formalizing and benchmarking attacks on OpenClaw for personalized local AI agent,” arXiv preprint arXiv:2602.08412, 2026
-
[18]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProc. ACM UIST, 2023
2023
-
[19]
ProgPrompt: Generating situated robot task plans using large language models,
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg, “ProgPrompt: Generating situated robot task plans using large language models,” inProc. IEEE ICRA, 2023
2023
-
[20]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Aligning cyber space with physical world: A comprehensive survey on embodied AI,
Y . Liu, Q. Guo, H. Yang, L. Li, H. Wang, J. Feng, G. Yin, and D. Shen, “Aligning cyber space with physical world: A comprehensive survey on embodied AI,”arXiv preprint arXiv:2407.06886, 2024
-
[22]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inConf. Robot Learning (CoRL), 2017
2017
-
[23]
Design and use paradigms for Gazebo, an open-source multi-robot simu- lator,
N. Koenig and A. Howard, “Design and use paradigms for Gazebo, an open-source multi-robot simu- lator,” inProc. IEEE/RSJ IROS, 2004
2004
-
[24]
Z. Zhu, R. Zhao, Q. Zhao, Z. Wang, and H. Zhao, “EARBench: Towards evaluating physical risk awareness for task planning of foundation model-based embodied AI agents,”arXiv preprint arXiv:2408.04449, 2024. 33
-
[25]
SafeAgentBench: A benchmark for safe task planning of embodied LLM agents
S. Yin, Z. Pang, and others, “SafeAgentBench: A benchmark for safe task planning of embodied LLM agents,”arXiv preprint arXiv:2412.13178, 2024
-
[26]
FDIR methods for space robots: A comprehensive survey and prospects,
Q. Li, R. Gross, and S. Yin, “FDIR methods for space robots: A comprehensive survey and prospects,” Acta Astronautica, vol. 209, pp. 243–262, 2023
2023
-
[27]
Safe reinforcement learning via shielding,
M. Alshiekh, R. Bloem, R. Ehlers, B. Könighofer, S. Niekum, and U. Topcu, “Safe reinforcement learning via shielding,” inProc. AAAI Conf. Artificial Intelligence, 2018
2018
-
[28]
Shield synthesis for reinforcement learning,
B. Könighofer, F. Lorber, N. Jansen, and R. Bloem, “Shield synthesis for reinforcement learning,” in Proc. Int. Symp. Leveraging Applications of Formal Methods (ISoLA), 2020
2020
-
[29]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” inEuropean Control Conference (ECC), 2019
2019
-
[30]
A general safety framework for learning-based control in uncertain robotic systems,
J. F. Fisac, A. K. Akametalu, M. N. Zeilinger, S. Kaynama, J. Gillula, and C. J. Tomlin, “A general safety framework for learning-based control in uncertain robotic systems,”IEEE Transactions on Au- tomatic Control, vol. 64, no. 7, pp. 2737–2752, 2019
2019
-
[31]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inProc. Int. Conf. Machine Learning (ICML), 2017
2017
-
[32]
Safe exploration in continuous action spaces,
G. Dalal, K. Dvijotham, M. Vecerik, T. Hester, C. Paduraru, and Y . Tassa, “Safe exploration in contin- uous action spaces,”arXiv preprint arXiv:1801.08757, 2018
-
[33]
Combining model checking and runtime verification for safe robotics,
A. Desai, T. Dreossi, and S. A. Seshia, “Combining model checking and runtime verification for safe robotics,” inProc. Int. Conf. Runtime Verification (RV), 2017
2017
-
[34]
A comprehensive survey on safe reinforcement learning,
J. García and F. Fernández, “A comprehensive survey on safe reinforcement learning,”Journal of Ma- chine Learning Research, vol. 16, no. 42, pp. 1437–1480, 2015
2015
-
[35]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 5, pp. 411–444, 2022
2022
-
[36]
A tour of reinforcement learning: The view from continuous control,
B. Recht, “A tour of reinforcement learning: The view from continuous control,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 2, pp. 253–279, 2019
2019
-
[37]
Using simplicity to control complexity,
L. Sha, “Using simplicity to control complexity,”IEEE Software, vol. 18, no. 4, pp. 20–28, 2001
2001
-
[38]
Preventing undesirable behavior of intelligent machines,
P. S. Thomas, B. C. da Silva, A. G. Barto, S. Giguere, Y . Brun, and E. Brunskill, “Preventing undesirable behavior of intelligent machines,”Science, vol. 366, no. 6468, pp. 999–1004, 2019
2019
-
[39]
Robots and robotic devices — Safety requirements for industrial robots,
ISO 10218-1:2011, “Robots and robotic devices — Safety requirements for industrial robots,” Interna- tional Organization for Standardization, 2011. 34
2011
-
[40]
Robots and robotic devices — Safety requirements for personal care robots,
ISO 13482:2014, “Robots and robotic devices — Safety requirements for personal care robots,” Inter- national Organization for Standardization, 2014
2014
-
[41]
N. G. Leveson,Engineering a Safer World: Systems Thinking Applied to Safety. MIT Press, 2011
2011
-
[42]
Autonomous vehicle safety: An interdisciplinary challenge,
P. Koopman and M. Wagner, “Autonomous vehicle safety: An interdisciplinary challenge,”IEEE Intel- ligent Transportation Systems Magazine, vol. 9, no. 1, pp. 90–96, 2017
2017
-
[43]
Real-time anomaly detection and reactive planning with large language models,
R. Sinha, A. Elhafsi, C. Agia, M. Foutter, E. Schmerling, and M. Pavone, “Real-time anomaly detection and reactive planning with large language models,” inRobotics: Science and Systems (RSS), 2024
2024
-
[44]
Alshiekh, M., Bloem, R., Ehlers, R., Könighofer, B., Niekum, S., Topcu, U.,
M. Ahn, D. Dwibedi, C. Finn, M. G. Arenas, K. Gopalakrishnan, K. Hausman, B. Ichter, A. Irpan, N. Joshi, R. Julian,et al., “AutoRT: Embodied foundation models for large scale orchestration of robotic agents,”arXiv preprint arXiv:2401.12963, 2024
-
[45]
W. Zhang, X. Kong, T. Braunl, and J. B. Hong, “SafeEmbodAI: A safety framework for mobile robots in embodied AI systems,”arXiv preprint arXiv:2409.01630, 2024
-
[46]
Z. Xiang, Z. Liu, P. Bian, P. Mittal, and W. Xu, “GuardAgent: Safeguard LLM agents by a guard agent via knowledge-enabled reasoning,”arXiv preprint arXiv:2406.09187, 2024
-
[47]
Rebedea, T., Dinu, R., Sreedhar, M., Parisien, C., Cohen, J.,
Z. Ravichandran, A. Robey, V . Kumar, G. J. Pappas, and H. Hassani, “RoboGuard: Safety guardrails for LLM-enabled robots,”arXiv preprint arXiv:2503.07885, 2025
-
[48]
AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents,
H. Wang, C. M. Poskitt, and J. Sun, “AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents,” inProc. IEEE/ACM Int. Conf. Software Engineering (ICSE), 2026
2026
-
[49]
NeMo Guardrails: A toolkit for control- lable and safe LLM applications with programmable rails,
T. Rebedea, R. Dinu, M. Sreedhar, C. Parisien, and J. Cohen, “NeMo Guardrails: A toolkit for control- lable and safe LLM applications with programmable rails,” inProc. EMNLP System Demonstrations, 2023
2023
-
[50]
Safety guardrails for LLM-enabled robots,
A. Ravichandran, A. Robey, Z. Sun, and H. Hassani, “Safety guardrails for LLM-enabled robots,”IEEE Robotics and Automation Letters, 2026
2026
-
[51]
TrustAgent: Towards safe and trustworthy LLM-based agents,
W. Hua, X. Yang, M. Jin, Z. Li, W. Cheng, R. Tang, and Y . Zhang, “TrustAgent: Towards safe and trustworthy LLM-based agents,” inFindings of EMNLP, 2024
2024
-
[52]
Pro2guard: Proactive runtime enforcement of llm agent safety via probabilistic model checking
H. Wang, C. M. Poskitt, J. Sun, and J. Wei, “Pro2Guard: Proactive runtime enforcement of LLM agent safety via probabilistic model checking,”arXiv preprint arXiv:2508.00500, 2025
-
[53]
A brief account of runtime verification,
M. Leucker and C. Schallhart, “A brief account of runtime verification,”J. Logic and Algebraic Pro- gramming, vol. 78, no. 5, pp. 293–303, 2009
2009
-
[54]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” inRobotics: Science and Systems (RSS), 2023. 35
2023
-
[55]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” inProc. IEEE/RSJ IROS, 2017
2017
-
[56]
A model for types and levels of human interaction with automation,
R. Parasuraman, T. B. Sheridan, and C. D. Wickens, “A model for types and levels of human interaction with automation,”IEEE Trans. Systems, Man, and Cybernetics—Part A, vol. 30, no. 3, pp. 286–297, 2000
2000
-
[57]
Human-robot interaction: A survey,
M. A. Goodrich and A. C. Schultz, “Human-robot interaction: A survey,”Foundations and Trends in Human-Computer Interaction, vol. 1, no. 3, pp. 203–275, 2007
2007
-
[58]
The challenge of crafting intelligible explanations,
D. S. Weld and G. Bansal, “The challenge of crafting intelligible explanations,”Communications of the ACM, vol. 62, no. 7, pp. 70–79, 2019
2019
-
[59]
Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (AI Act),
European Parliament and Council of the European Union, “Regulation (EU) 2024/1689 laying down harmonised rules on artificial intelligence (AI Act),”Official Journal of the European Union, L series, 2024
2024
-
[60]
Learning Without Losing Identity: Capability Evolution for Embodied Agents
Qin, X., Luan, S., See, J., Yang, C., Li, Z.: Learning without losing identity: Capability evolution for embodied agents. arXiv preprint arXiv:2604.07799 (2026) 36
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.