Recognition: unknown
FlowGuard: Towards Lightweight In-Generation Safety Detection for Diffusion Models via Linear Latent Decoding
Pith reviewed 2026-05-10 16:58 UTC · model grok-4.3
The pith
A linear approximation to the VAE decoder lets diffusion models detect NSFW content in the middle of generation steps rather than before or after.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowGuard is a cross-model in-generation detection framework that inspects intermediate denoising steps in latent diffusion models by applying a linear approximation for latent decoding together with curriculum learning, enabling early identification of NSFW content that outperforms pre-generation prompt checks and post-generation classifiers on both in-distribution and out-of-distribution cases.
What carries the argument
The linear approximation for latent decoding, which maps noisy latents directly to an approximate image space to extract safety signals without running full VAE decoding at every step.
If this is right
- Generation of unsafe images can be halted after only a few denoising steps instead of running to completion.
- The detector works without retraining when the underlying diffusion backbone changes.
- Peak GPU memory for the safety check drops by over 97 percent and each projection takes 0.2 seconds instead of 8.1 seconds.
- Overall F1 score for NSFW detection rises by more than 30 percent compared with prior methods.
Where Pith is reading between the lines
- The same linear shortcut could be tested on safety signals other than NSFW, such as bias or copyright indicators in the latent trajectory.
- Real-time generation pipelines could embed this check as a lightweight monitor that aborts or redirects the process on the fly.
Load-bearing premise
The linear approximation keeps enough safety-relevant information from the noisy early latents so that a detector trained on it still works reliably across different diffusion backbones.
What would settle it
A new diffusion backbone where the linear decoder approximation produces early-step detections whose F1 score falls to the level of a prompt-only classifier.
Figures






read the original abstract
Diffusion-based image generation models have advanced rapidly but pose a safety risk due to their potential to generate Not-Safe-For-Work (NSFW) content. Existing NSFW detection methods mainly operate either before or after image generation. Pre-generation methods rely on text prompts and struggle with the gap between prompt safety and image safety. Post-generation methods apply classifiers to final outputs, but they are poorly suited to intermediate noisy images. To address this, we introduce FlowGuard, a cross-model in-generation detection framework that inspects intermediate denoising steps. This is particularly challenging in latent diffusion, where early-stage noise obscures visual signals. FlowGuard employs a novel linear approximation for latent decoding and leverages a curriculum learning approach to stabilize training. By detecting unsafe content early, FlowGuard reduces unnecessary diffusion steps to cut computational costs. Our cross-model benchmark spanning nine diffusion-based backbones shows the effectiveness of FlowGuard for in-generation NSFW detection in both in-distribution and out-of-distribution settings, outperforming existing methods by over 30% in F1 score while delivering transformative efficiency gains, including slashing peak GPU memory demand by over 97% and projection time from 8.1 seconds to 0.2 seconds compared to standard VAE decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlowGuard, a cross-model framework for in-generation NSFW detection in latent diffusion models. It replaces standard VAE decoding of intermediate noisy latents with a linear approximation, trains a detector via curriculum learning, and claims this enables early unsafe-content detection, early stopping, and large efficiency gains. The central empirical result is a >30% F1 improvement over prior methods together with a 97% reduction in peak GPU memory and a reduction in projection time from 8.1 s to 0.2 s, demonstrated across nine diffusion backbones in both in-distribution and out-of-distribution regimes.
Significance. If the linear approximation is shown to preserve safety-relevant visual features at high noise levels, the method would constitute a practical advance for real-time safety filtering in generative pipelines. The reported memory and latency reductions are large enough to be deployment-relevant, and the cross-model scope is a positive feature. The absence of any reported fidelity metric for the linear decoder on noisy latents, however, leaves the generalization claims unanchored.
major comments (3)
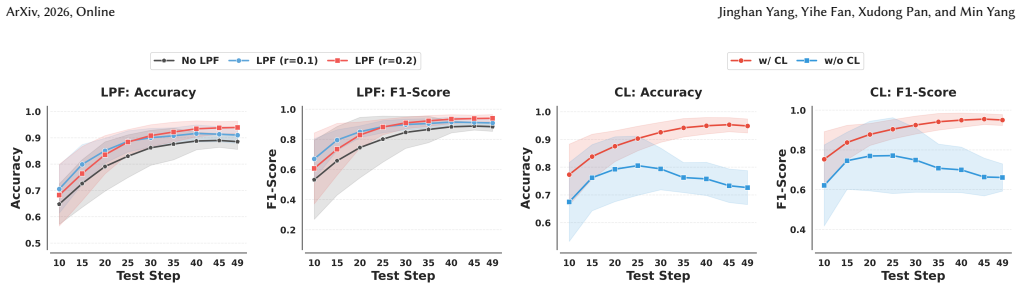
- [§3] §3 (Linear Latent Decoding): the central claim that the linear map preserves NSFW signals sufficiently for reliable detection at early timesteps (t > 0.6T) is unsupported by any quantitative fidelity measure (e.g., CLIP cosine similarity, classification accuracy gap, or reconstruction error) between the linear decode and true VAE decode on the same noisy latents. Without this, the reported F1 gains and cross-model generalization cannot be distinguished from training-distribution artifacts.
- [§4] §4 (Curriculum Learning) and experimental protocol: no description is given of the curriculum schedule, stage boundaries, loss weighting, or hyper-parameters. The absence of these details, together with the lack of an ablation that isolates the linear decoder from the curriculum, makes it impossible to assess whether the claimed stabilization and >30% F1 lift are reproducible or method-specific.
- [Table 1] Table 1 / cross-model benchmark: the results table reports aggregate F1 but contains no per-timestep or per-noise-level breakdown, nor any comparison of detector performance on linearly decoded versus VAE-decoded latents at the same early steps. This omission directly undermines the claim that the linear approximation is the enabling factor for both accuracy and efficiency.
minor comments (2)
- [Abstract] The abstract states quantitative gains without naming the exact baselines or providing confidence intervals; this should be corrected for clarity.
- [§3] Notation for the linear map (e.g., definition of the projection matrix and its dependence on timestep) is introduced without an explicit equation; adding one would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments identify important areas where additional evidence and clarity will strengthen the manuscript. We address each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [§3] §3 (Linear Latent Decoding): the central claim that the linear map preserves NSFW signals sufficiently for reliable detection at early timesteps (t > 0.6T) is unsupported by any quantitative fidelity measure (e.g., CLIP cosine similarity, classification accuracy gap, or reconstruction error) between the linear decode and true VAE decode on the same noisy latents. Without this, the reported F1 gains and cross-model generalization cannot be distinguished from training-distribution artifacts.
Authors: We agree that a direct quantitative fidelity analysis between the linear decoder and the true VAE decoder on noisy latents would provide stronger anchoring for the claims. While the reported cross-model F1 improvements and out-of-distribution generalization offer indirect support, they do not fully isolate the contribution of the linear approximation. In the revised manuscript we will add a new subsection (or appendix table) reporting CLIP cosine similarity, pixel-level reconstruction error, and detection accuracy gap between linear and VAE decodes across a range of noise levels, with particular emphasis on early timesteps (t > 0.6T). revision: yes
-
Referee: [§4] §4 (Curriculum Learning) and experimental protocol: no description is given of the curriculum schedule, stage boundaries, loss weighting, or hyper-parameters. The absence of these details, together with the lack of an ablation that isolates the linear decoder from the curriculum, makes it impossible to assess whether the claimed stabilization and >30% F1 lift are reproducible or method-specific.
Authors: We apologize for the omission of the full curriculum-learning protocol in the main text. The schedule, stage boundaries, loss weighting, and hyper-parameters are described in the supplementary material; we will move this description into §4 for completeness. In addition, we will include a new ablation study that isolates the linear latent decoder from the curriculum learning strategy, reporting performance with and without each component to demonstrate their individual contributions to training stability and the observed F1 gains. revision: yes
-
Referee: [Table 1] Table 1 / cross-model benchmark: the results table reports aggregate F1 but contains no per-timestep or per-noise-level breakdown, nor any comparison of detector performance on linearly decoded versus VAE-decoded latents at the same early steps. This omission directly undermines the claim that the linear approximation is the enabling factor for both accuracy and efficiency.
Authors: We concur that aggregate F1 scores alone do not fully illustrate the benefits at early timesteps. We will expand Table 1 (or add a companion table) with per-timestep and per-noise-level F1 breakdowns. We will also add a direct side-by-side comparison of detector performance using the linear decoder versus the standard VAE decoder on identical early-stage latents, thereby clarifying the accuracy-efficiency trade-off enabled by the linear approximation. revision: yes
Circularity Check
No significant circularity: novel linear decoding and curriculum components are independent of evaluation data fits.
full rationale
The paper introduces a new linear approximation for latent decoding in early noisy steps plus curriculum learning for detector training. These are presented as methodological contributions rather than reparameterizations of existing quantities. Central performance claims ( >30% F1 gains, 97% memory reduction) rest on empirical cross-model benchmarks across nine backbones in both in- and out-of-distribution regimes, not on any fitted parameter that is then renamed as a prediction on the same data. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to force the results. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. 2025. FLUX.1 Kontext: Flow Matching for In-Context Image Generation an...
2025
-
[3]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. InProceedings of the 26th annual international conference on machine learning. 41–48
2009
-
[4]
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhong- dao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. 2024. PixArt- Σ: Weak- to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation. arXiv:2403.04692 [cs.CV] https://arxiv.org/abs/2403.04692
- [5]
-
[6]
P Kingma Diederik and Welling Max. 2019. An introduction to variational autoencoders.Foundations and Trends®in Machine Learning12, 4 (2019), 307– 392
2019
-
[7]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al . 2021. An Image is Worth 16x16 Words: Trans- formers for Image Recognition at Scale. InInternational Conference on Learning Representations (ICLR). https://openreview.net/for...
2021
-
[8]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis.arXiv preprint arXiv:2403.03206(2024)
work page internal anchor Pith review arXiv 2024
-
[9]
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau
-
[10]
arXiv:2303.07345 [cs.CV] https: //arxiv.org/abs/2303.07345
Erasing Concepts from Diffusion Models. arXiv:2303.07345 [cs.CV] https: //arxiv.org/abs/2303.07345
-
[11]
Gonzalez and Richard E
Rafael C. Gonzalez and Richard E. Woods. 2018.Digital Image Processing(4th ed.). Pearson
2018
-
[12]
Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Networks. arXiv:1406.2661 [stat.ML] https://arxiv.org/abs/1406.2661
work page internal anchor Pith review arXiv 2014
- [13]
- [14]
-
[15]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. InAdvances in Neural Information Processing Systems, Vol. 33. 6840–6851. https://proceedings.neurips.cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b-Paper.pdf
2020
-
[16]
Diederik P Kingma and Max Welling. 2013. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [17]
-
[18]
Black Forest Labs. 2026. FLUX.2-dev: Open-Weights Scalable Transformer. https: //huggingface.co/black-forest-labs/FLUX.2-dev
2026
-
[19]
Feifei Li, Mi Zhang, Yiming Sun, and Min Yang. 2025. Detect-and-guide: Self- regulation of diffusion models for safe text-to-image generation via guideline token optimization. InProceedings of the Computer Vision and Pattern Recognition Conference. 13252–13262
2025
-
[20]
Lijun Li, Zhelun Shi, Xuhao Hu, Bowen Dong, Yiran Qin, Xihui Liu, Lu Sheng, and Jing Shao. 2025. T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13381–13392
2025
- [21]
-
[22]
Runtao Liu, Ashkan Khakzar, Jindong Gu, Qifeng Chen, Philip Torr, and Fabio Pizzati. 2024. Latent guard: a safety framework for text-to-image generation. In European Conference on Computer Vision. Springer, 93–109
2024
-
[23]
Ilya Loshchilov and Frank Hutter. 2017. SGDR: Stochastic Gradient Descent with Warm Restarts. InInternational Conference on Learning Representations (ICLR). https://openreview.net/forum?id=Skq89Scxx
2017
-
[24]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regular- ization. InInternational Conference on Learning Representations (ICLR). https: //openreview.net/forum?id=Bkg6RiCqY7
2019
-
[25]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. 2024. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. 16683–16694. https://openaccess.thecvf.com/content/CVPR2024/ html/P...
2024
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning, Vol. 139. 8748–8763. h...
2021
-
[27]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis with La- tent Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10684–10695. https: //openaccess.thecvf.com/content/CVPR2022/html/Rombach_High-Resolution_ Image_Synthesis_With_Latent_D...
2022
-
[28]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-Resolution Image Synthesis With Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[29]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Den- ton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. 2023. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. InProceedings of the IEEE/CVF Conf...
2023
- [31]
-
[32]
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting
-
[33]
Available: https://arxiv.org/abs/2211.05105
Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models. arXiv:2211.05105 [cs.CV] https://arxiv.org/abs/2211.05105
-
[34]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2021. Score-Based Generative Modeling through Stochas- tic Differential Equations. InInternational Conference on Learning Representations. https://openreview.net/forum?id=PxTIG12RRHS
2021
-
[35]
Z-Image Team. 2025. Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.arXiv preprint arXiv:2511.22699(2025)
work page internal anchor Pith review arXiv 2025
- [36]
-
[37]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [38]
- [39]
-
[40]
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao
-
[41]
arXiv:2305.12082 [cs.LG] https://arxiv.org/abs/2305.12082
SneakyPrompt: Jailbreaking Text-to-image Generative Models. arXiv:2305.12082 [cs.LG] https://arxiv.org/abs/2305.12082
-
[42]
Yijun Yang, Pan Zhou, Yuancheng Xu, Kai Wang, Jianshu Ji, Zeyi Huang, Zhen- huan Liu, Jiashi Feng, and Xinchao Wang. 2023. Learning to prompt safely with image-language models. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 13117–13126
2023
- [43]
-
[44]
Ruiyang Zhang, Jiahao Luo, Xiaoru Feng, Qiufan Pang, Yaodong Yang, and Juntao Dai. 2025. SafeEditor: Unified MLLM for Efficient Post-hoc T2I Safety Editing. arXiv:2510.24820 [cs.CV] https://arxiv.org/abs/2510.24820 A Linear Decoder Examples The linear decoder is trained on latent-image pairs, with the images synthesized by the VAE decoder. While the origi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.