Recognition: no theorem link
Same Outcomes, Different Journeys: A Trace-Level Framework for Comparing Human and GUI-Agent Behavior in Production Search Systems
Pith reviewed 2026-05-10 18:17 UTC · model grok-4.3
The pith
GUI agents match human task success and queries in search systems but navigate interfaces differently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show through their trace-level framework that in a production audio-streaming search application, a state-of-the-art GUI agent achieves task success comparable to 39 human participants across ten multi-hop search tasks and generates broadly aligned queries, but follows systematically different navigation strategies where participants exhibit content-centric, exploratory behavior while the agent is more search-centric and low-branching. Outcome and query alignment therefore do not imply behavioral alignment.
What carries the argument
The trace-level evaluation framework that compares behavior across task outcome and effort, query formulation, and navigation across interface states.
If this is right
- Task success rates alone cannot validate GUI agents as reliable proxies for human users in search systems.
- Query alignment is also insufficient to confirm that agents interact with interfaces in human-like ways.
- Production systems deploying agents for evaluation need trace-level diagnostics to detect navigation mismatches.
- Optimizations derived from agent simulations may not improve experience for actual users when paths differ.
Where Pith is reading between the lines
- The same framework could be used in other GUI domains such as e-commerce or productivity tools to test for parallel mismatches between agent and human traces.
- Agent training or prompting methods might be adjusted to encourage more exploratory navigation without losing efficiency on task completion.
- If navigation gaps persist across agents, relying on them for A/B testing or ranking experiments could systematically bias results away from human preferences.
Load-bearing premise
The behavioral differences observed with one state-of-the-art agent and ten tasks in a single audio-streaming application will generalize to other agents and other production search systems.
What would settle it
A study in another production search system or with a different GUI agent that finds identical navigation patterns between the agent and humans.
Figures



read the original abstract
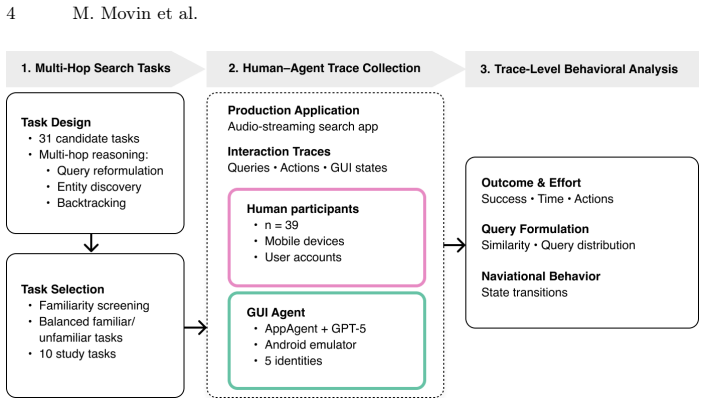
LLM-driven GUI agents are increasingly used in production systems to automate workflows and simulate users for evaluation and optimization. Yet most GUI-agent evaluations emphasize task success and provide limited evidence on whether agents interact in human-like ways. We present a trace-level evaluation framework that compares human and agent behavior across (i) task outcome and effort, (ii) query formulation, and (iii) navigation across interface states. We instantiate the framework in a controlled study in a production audio-streaming search application, where 39 participants and a state-of-the-art GUI agent perform ten multi-hop search tasks. The agent achieves task success comparable to participants and generates broadly aligned queries, but follows systematically different navigation strategies: participants exhibit content-centric, exploratory behavior, while the agent is more search-centric and low-branching. These results show that outcome and query alignment do not imply behavioral alignment, motivating trace-level diagnostics when deploying GUI agents as proxies for users in production search systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a trace-level framework for comparing human and GUI-agent behavior in production search systems along three dimensions: task outcome and effort, query formulation, and navigation across interface states. It reports a controlled study in which 39 human participants and one state-of-the-art GUI agent each completed ten multi-hop search tasks in a production audio-streaming application. The agent matched human task success rates and produced broadly aligned queries, yet exhibited systematically different navigation patterns (humans were more content-centric and exploratory; the agent was more search-centric and low-branching). The authors conclude that outcome and query alignment do not guarantee behavioral alignment and therefore advocate trace-level diagnostics when using GUI agents as user proxies.
Significance. If the empirical findings are robust, the work usefully demonstrates that conventional success metrics are insufficient for validating GUI agents as human proxies in search interfaces. The trace-level lens could inform more realistic agent evaluation and optimization pipelines in production systems, particularly where behavioral fidelity affects downstream metrics such as user satisfaction or system load.
major comments (3)
- [Results] Results section (navigation analysis): the manuscript reports systematic differences in navigation strategies but supplies no statistical tests, confidence intervals, or inter-rater reliability measures for the trace coding; without these, the strength of the central behavioral-alignment claim cannot be assessed.
- [Discussion] Study design and Discussion: the recommendation to adopt trace-level diagnostics for production search systems rests on data from a single audio-streaming app, one GUI agent, and ten tasks; this single-instance design supplies a counter-example but provides limited warrant for the general claim that outcome/query alignment never implies behavioral alignment across agents and domains.
- [Framework and Study] Framework instantiation: the operational definitions and coding scheme used to classify navigation traces as 'content-centric/exploratory' versus 'search-centric/low-branching' are not fully specified (e.g., no decision rules, examples, or inter-coder protocol), which is load-bearing for reproducibility of the reported differences.
minor comments (2)
- [Abstract] Abstract and Introduction: the exact version or training details of the 'state-of-the-art GUI agent' are not stated; adding this information would help readers interpret the navigation divergence.
- [Related Work] Related work: a brief comparison table or paragraph situating the proposed framework against existing GUI-agent benchmarks (e.g., those focused solely on success rate) would clarify the incremental contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [Results] Results section (navigation analysis): the manuscript reports systematic differences in navigation strategies but supplies no statistical tests, confidence intervals, or inter-rater reliability measures for the trace coding; without these, the strength of the central behavioral-alignment claim cannot be assessed.
Authors: We agree that incorporating statistical tests and confidence intervals would strengthen the presentation of the navigation differences. In the revised version, we will include appropriate non-parametric tests (such as Fisher's exact test for categorical navigation patterns) and report confidence intervals for key proportions. For the trace coding, the analysis was conducted by the research team using a shared coding scheme; we will add details on the coding process and, if feasible, compute inter-rater reliability by having a second coder review a subset of traces. These additions will be placed in the Results section and an appendix. revision: yes
-
Referee: [Discussion] Study design and Discussion: the recommendation to adopt trace-level diagnostics for production search systems rests on data from a single audio-streaming app, one GUI agent, and ten tasks; this single-instance design supplies a counter-example but provides limited warrant for the general claim that outcome/query alignment never implies behavioral alignment across agents and domains.
Authors: The study is indeed limited to one production application, a single GUI agent, and ten tasks, and we present it as an illustrative counter-example demonstrating that outcome and query alignment do not necessarily entail behavioral alignment. We do not claim this holds universally across all agents and domains. In the revised Discussion, we will more explicitly qualify the generalizability of our findings, highlight the need for broader validation in future work, and adjust the language to emphasize the motivational aspect of the results rather than a strong general claim. revision: partial
-
Referee: [Framework and Study] Framework instantiation: the operational definitions and coding scheme used to classify navigation traces as 'content-centric/exploratory' versus 'search-centric/low-branching' are not fully specified (e.g., no decision rules, examples, or inter-coder protocol), which is load-bearing for reproducibility of the reported differences.
Authors: We recognize the importance of fully specifying the coding scheme for reproducibility. The manuscript currently describes the categories at a high level. We will revise the Framework section to include precise operational definitions, decision rules for classifying each trace (with examples), and a description of the inter-coder protocol. These details will be added to the main text or as a supplementary appendix to ensure the classification process can be replicated. revision: yes
Circularity Check
No circularity: empirical study grounded in new data
full rationale
The paper reports results from a controlled empirical study with 39 human participants and one GUI agent performing ten tasks in a single audio-streaming application. All claims about outcome alignment, query formulation, and navigation differences are derived directly from the collected trace data rather than from equations, fitted parameters, or prior self-citations. No load-bearing steps reduce to inputs by construction, and the framework is presented as a new instantiation without self-referential derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trace logs from interface interactions reliably reflect underlying user and agent strategies.
Reference graph
Works this paper leans on
-
[1]
Foundations and Trends in Information Retrieval18(1-2), 1–261 (2024) 16 M
Balog, K., Zhai, C.: User simulation for evaluating information access systems. Foundations and Trends in Information Retrieval18(1-2), 1–261 (2024) 16 M. Movin et al
2024
-
[2]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Cheng, K., Sun, Q., Chu, Y., Xu, F., Li, Y., Zhang, J., Wu, Z.: SeeClick: Harnessing GUI Grounding for Advanced Visual GUI Agents. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9313–9332 (2024)
2024
-
[3]
Advances in Neural Informa- tion Processing Systems36, 28091–28114 (2023)
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2Web: Towards a generalist agent for the web. Advances in Neural Informa- tion Processing Systems36, 28091–28114 (2023)
2023
-
[4]
Information Retrieval11(3), 209–228 (2008)
Keskustalo, H., Järvelin, K., Pirkola, A.: Evaluating the effectiveness of relevance feedback based on a user simulation model: effects of a user scenario on cumulated gain value. Information Retrieval11(3), 209–228 (2008)
2008
-
[5]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
Koh, J.Y., Lo, R., Jang, L., Duvvur, V., Lim, M., Huang, P.Y., Neubig, G., Zhou, S., Salakhutdinov, R., Fried, D.: VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
2024
- [6]
-
[7]
In: Proceedings of the Extended Abstracts of the CHI Conference on Hu- man Factors in Computing Systems
Lu, Y., Yao, B., Gu, H., Huang, J., Wang, Z.J., Li, Y., Gesi, J., He, Q., Li, T.J.J., Wang, D.: UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design. In: Proceedings of the Extended Abstracts of the CHI Conference on Hu- man Factors in Computing Systems. pp. 1–12 (2025)
2025
-
[8]
Foundations and Trends®in Information Retrieval17(4), 457–586 (2024)
Mavi, V., Jangra, A., Jatowt, A.: Multi-hop question answering. Foundations and Trends®in Information Retrieval17(4), 457–586 (2024)
2024
-
[9]
In: Proceedings of the 39th Inter- national ACM SIGIR conference on Research and Development in Information Retrieval
Maxwell, D., Azzopardi, L.: Simulating interactive information retrieval: SimIIR: A framework for the simulation of interaction. In: Proceedings of the 39th Inter- national ACM SIGIR conference on Research and Development in Information Retrieval. pp. 1141–1144 (2016)
2016
-
[10]
Gui agents: A survey.arXiv preprint arXiv:2412.13501, 2024
Nguyen, D., Chen, J., Wang, Y., Wu, G., Park, N., Hu, Z., Lyu, H., Wu, J., Aponte, R., Xia, Y., et al.: GUI agents: A survey. arXiv preprint arXiv:2412.13501 (2024)
-
[11]
https://openai.com/index/introducing-gpt-5/ (2025)
OpenAI: GPT-5. https://openai.com/index/introducing-gpt-5/ (2025)
2025
-
[12]
In: Proceedings of the 5th information interaction in context sym- posium
Thomas, P., Moffat, A., Bailey, P., Scholer, F.: Modeling decision points in user search behavior. In: Proceedings of the 5th information interaction in context sym- posium. pp. 239–242 (2014)
2014
-
[13]
How do AI agents do human work? comparing AI and human workflows across diverse occupations
Wang, Z.Z., Shao, Y., Shaikh, O., Fried, D., Neubig, G., Yang, D.: How Do AI Agents Do Human Work? Comparing AI and Human Workflows Across Diverse Occupations. arXiv preprint arXiv:2510.22780 (2025)
-
[14]
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments (2024), https://arxiv.org/abs/2404.07972
work page internal anchor Pith review arXiv 2024
-
[15]
In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems
Zhang, C., Yang, Z., Liu, J., Li, Y., Han, Y., Chen, X., Huang, Z., Fu, B., Yu, G.: AppAgent: Multimodal Agents as Smartphone Users. In: Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. CHI ’25 (2025)
2025
-
[16]
In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval
Zhang, E., Wang, X., Gong, P., Lin, Y., Mao, J.: USimAgent: Large Language Models for Simulating Search Users. In: Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2687–2692 (2024)
2024
-
[17]
In: Proceedings of the 48th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval
Zhang, E., Wang, X., Gong, P., Yang, Z., Mao, J.: Exploring human-like thinking in search simulations with large language models. In: Proceedings of the 48th In- ternational ACM SIGIR Conference on Research and Development in Information Retrieval. pp. 2669–2673 (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.