Recognition: unknown
SceneScribe-1M: A Large-Scale Video Dataset with Comprehensive Geometric and Semantic Annotations
Pith reviewed 2026-05-10 17:12 UTC · model grok-4.3
The pith
SceneScribe-1M supplies one million videos with text descriptions, camera parameters, dense depth maps, and consistent 3D point tracks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
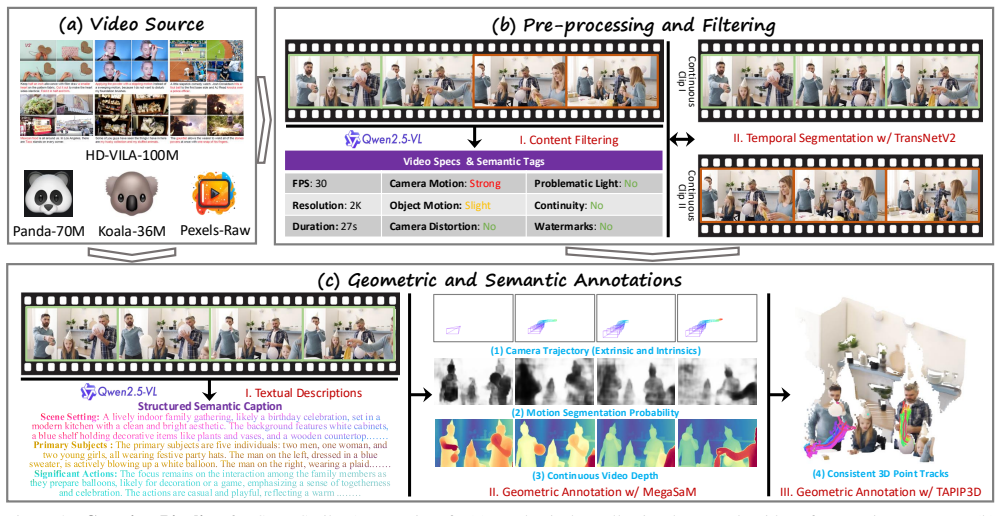
We introduce SceneScribe-1M, a new large-scale, multi-modal video dataset. It comprises one million in-the-wild videos, each meticulously annotated with detailed textual descriptions, precise camera parameters, dense depth maps, and consistent 3D point tracks. We demonstrate the versatility and value of SceneScribe-1M by establishing benchmarks across a wide array of downstream tasks, including monocular depth estimation, scene reconstruction, and dynamic point tracking, as well as generative tasks such as text-to-video synthesis, with or without camera control.
What carries the argument
The SceneScribe-1M dataset itself, which pairs each of one million videos with a complete set of semantic text descriptions and geometric annotations consisting of camera parameters, dense depth maps, and temporally consistent 3D point tracks.
If this is right
- Monocular depth estimation models can be trained and tested on a much larger and more diverse collection of real video sequences than before.
- Scene reconstruction methods gain direct access to dense per-frame depth and long-term 3D point correspondences for improved accuracy.
- Dynamic point tracking algorithms receive consistent 3D tracks that span entire videos rather than short clips.
- Text-to-video generators can be conditioned on explicit camera trajectories derived from the provided parameters.
- Perception and generation research can share the same data source and therefore compare results on identical video content.
Where Pith is reading between the lines
- The joint availability of semantic and geometric labels may encourage training regimes that enforce geometric consistency inside video generation networks.
- Researchers could derive additional self-supervision signals by checking that generated videos respect the same camera and depth constraints present in the dataset.
- The scale of consistent 3D tracks could support new forms of long-range video understanding that current short-clip datasets cannot address.
- Similar annotation pipelines might later be applied to other large video collections to expand coverage beyond the current one million sequences.
Load-bearing premise
The camera parameters, depth maps, and 3D point tracks supplied for every video are accurate and consistent enough to serve as reliable supervision and evaluation targets.
What would settle it
A measurement showing that the supplied depth maps or camera parameters deviate substantially from independent ground-truth sensors on a held-out set of videos, or a finding that models trained on these annotations show no improvement over models trained on existing smaller datasets.
Figures






read the original abstract
The convergence of 3D geometric perception and video synthesis has created an unprecedented demand for large-scale video data that is rich in both semantic and spatio-temporal information. While existing datasets have advanced either 3D understanding or video generation, a significant gap remains in providing a unified resource that supports both domains at scale. To bridge this chasm, we introduce SceneScribe-1M, a new large-scale, multi-modal video dataset. It comprises one million in-the-wild videos, each meticulously annotated with detailed textual descriptions, precise camera parameters, dense depth maps, and consistent 3D point tracks. We demonstrate the versatility and value of SceneScribe-1M by establishing benchmarks across a wide array of downstream tasks, including monocular depth estimation, scene reconstruction, and dynamic point tracking, as well as generative tasks such as text-to-video synthesis, with or without camera control. By open-sourcing SceneScribe-1M, we aim to provide a comprehensive benchmark and a catalyst for research, fostering the development of models that can both perceive the dynamic 3D world and generate controllable, realistic video content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SceneScribe-1M, a new large-scale dataset of one million in-the-wild videos, each annotated with detailed textual descriptions, precise camera parameters, dense depth maps, and consistent 3D point tracks. It establishes benchmarks for downstream tasks including monocular depth estimation, scene reconstruction, dynamic point tracking, and text-to-video synthesis with or without camera control, and releases the dataset openly.
Significance. If the geometric annotations prove sufficiently accurate and consistent, the dataset would be a significant contribution by providing a unified, large-scale resource that bridges semantic video understanding and 3D geometric perception, enabling new work on controllable video generation and dynamic scene modeling. The open release of the full dataset and annotations is a clear strength that supports reproducibility.
major comments (2)
- [§3] §3 (Dataset Construction): The automated pipelines used to derive camera parameters, dense depth maps, and 3D point tracks from in-the-wild videos are described at a high level, but no quantitative validation protocol, error distributions, or comparison against independent ground-truth references on a held-out diverse subset is reported. This directly affects the load-bearing claim that the annotations are 'precise' and 'consistent' enough to support the listed benchmarks.
- [§4] §4 (Benchmarks): The reported results for monocular depth estimation, scene reconstruction, and dynamic point tracking assume the provided annotations serve as reliable supervision or evaluation targets, yet no ablation or sensitivity analysis quantifies how annotation noise (from SfM, monocular depth models, or trackers) affects the observed performance gaps versus prior datasets.
minor comments (2)
- [Abstract] Abstract: The phrasing 'precise camera parameters' and 'meticulously annotated' should be qualified to reflect that these quantities are estimated rather than directly measured, to avoid overstating annotation fidelity.
- [§2] §2 (Related Work): A more explicit comparison table contrasting SceneScribe-1M against existing video datasets (e.g., in scale, annotation types, and validation) would help readers assess the claimed gap.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the presentation of the dataset construction and benchmark evaluations.
read point-by-point responses
-
Referee: [§3] §3 (Dataset Construction): The automated pipelines used to derive camera parameters, dense depth maps, and 3D point tracks from in-the-wild videos are described at a high level, but no quantitative validation protocol, error distributions, or comparison against independent ground-truth references on a held-out diverse subset is reported. This directly affects the load-bearing claim that the annotations are 'precise' and 'consistent' enough to support the listed benchmarks.
Authors: We agree that the current description in §3 is high-level and that explicit quantitative validation would better support the claims of precision and consistency. The pipelines rely on established components (COLMAP for SfM, recent monocular depth models, and multi-view consistent trackers), each of which has been validated in the literature. To address the referee's concern directly, the revised manuscript will add a new subsection in §3 that reports (1) a quantitative validation protocol, (2) error distributions (e.g., camera pose error, depth MAE, track consistency) on a held-out diverse subset of 5,000 videos, and (3) cross-validation against alternative pipelines and publicly available datasets that contain partial ground-truth geometry. We note that fully independent 3D ground truth does not exist for the majority of in-the-wild videos; therefore the added analysis will emphasize consistency metrics and proxy evaluations rather than claiming absolute ground-truth accuracy. revision: yes
-
Referee: [§4] §4 (Benchmarks): The reported results for monocular depth estimation, scene reconstruction, and dynamic point tracking assume the provided annotations serve as reliable supervision or evaluation targets, yet no ablation or sensitivity analysis quantifies how annotation noise (from SfM, monocular depth models, or trackers) affects the observed performance gaps versus prior datasets.
Authors: We concur that a sensitivity analysis would improve the interpretability of the benchmark results. In the revised §4 we will add an ablation study that (1) varies annotation confidence thresholds and noise injection levels, (2) measures the resulting changes in downstream task performance, and (3) compares the magnitude of these effects against the performance gaps reported versus prior datasets. This analysis will be presented alongside the existing benchmark tables to clarify the robustness of the observed improvements. revision: yes
Circularity Check
Dataset release paper exhibits no circularity in claims
full rationale
The paper introduces SceneScribe-1M as a new annotated video dataset without any mathematical derivations, model predictions, or first-principles results. Its claims center on the dataset's scale, annotation types (text, cameras, depth, tracks), and downstream benchmarks, none of which reduce by construction to fitted parameters or self-citations. Annotation pipelines are external tools applied to data; the paper does not claim to derive or predict the annotations from the dataset itself. Concerns about annotation accuracy are validation issues, not circularity. The work is self-contained as a data contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-quality, consistent annotations for camera parameters, dense depth maps, and 3D point tracks can be reliably produced for one million in-the-wild videos
Reference graph
Works this paper leans on
-
[1]
com / UmiMarch / OpenVideo, 2023
Openvideo.https : / / github . com / UmiMarch / OpenVideo, 2023. 4
2023
-
[2]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Eliza- beth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025. 1, 3
work page internal anchor Pith review arXiv 2025
-
[3]
Ac3d: Analyzing and improving 3d camera control in video diffusion transform- ers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Ali- aksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transform- ers. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 22875– 22889, 2025. 3, 6, 7, 8
2025
-
[4]
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Di Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints.arXiv preprint arXiv:2412.07760, 2024. 3
-
[5]
Recammaster: Camera-controlled generative rendering from a single video, 2025
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lian- rui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video.arXiv preprint arXiv:2503.11647, 2025. 2, 3
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2, 3, 4, 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[8]
Video generation models as world simulators.OpenAI Blog, 1:1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luh- man, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1:1, 2024. 3
2024
-
[9]
A naturalistic open source movie for optical flow evaluation
Daniel J Butler, Jonas Wulff, Garrett B Stanley, and Michael J Black. A naturalistic open source movie for optical flow evaluation. InProceedings of the European Conference on Computer Vision (ECCV), pages 611–625, 2012. 8
2012
-
[10]
Yohann Cabon, Naila Murray, and Martin Humenberger. Vir- tual kitti 2.arXiv preprint arXiv:2001.10773, 2020. 2, 3
work page internal anchor Pith review arXiv 2001
-
[11]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[12]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, et al. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13320–13331, 2024. 2, 3, 4
2024
-
[13]
Genie 3: A new frontier for world models
DeepMind. Genie 3: A new frontier for world models. https://deepmind.google/blog/genie-3-a- new-frontier-for-world-models, 2024. 1, 3
2024
-
[14]
Gemini 2.0 flash.https : / / deepmind
Google DeepMind. Gemini 2.0 flash.https : / / deepmind . google / technologies / gemini / flash/, 2024. 5
2024
-
[15]
Tap-vid: A benchmark for track- ing any point in a video.Advances in Neural Information Processing Systems (NeurIPS), pages 13610–13626, 2022
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Re- casens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. Tap-vid: A benchmark for track- ing any point in a video.Advances in Neural Information Processing Systems (NeurIPS), pages 13610–13626, 2022. 8
2022
-
[16]
Google scanned objects: A high- quality dataset of 3d scanned household items
Laura Downs, Anthony Francis, Nate Koenig, Brandon Kin- man, Ryan Hickman, Krista Reymann, Thomas B McHugh, and Vincent Vanhoucke. Google scanned objects: A high- quality dataset of 3d scanned household items. InProceed- ings of the International Conference on Robotics and Au- tomation (ICRA), pages 2553–2560, 2022. 8
2022
-
[17]
arXiv preprint arXiv:2506.01943 , year=
Xiao Fu, Xintao Wang, Xian Liu, Jianhong Bai, Runsen Xu, Pengfei Wan, Di Zhang, and Dahua Lin. Learning video gen- eration for robotic manipulation with collaborative trajectory control.arXiv preprint arXiv:2506.01943, 2025. 2
-
[18]
Kubric: A scalable dataset generator
Klaus Greff, Francois Belletti, Lucas Beyer, Carl Doersch, Yilun Du, Daniel Duckworth, David J Fleet, Dan Gnanapra- gasam, Florian Golemo, Charles Herrmann, et al. Kubric: A scalable dataset generator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3749–3761, 2022. 8
2022
-
[19]
3d packing for self-supervised monocular depth estimation
Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raven- tos, and Adrien Gaidon. 3d packing for self-supervised monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2485–2494, 2020. 8
2020
-
[20]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[21]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[22]
Tianyu Huang, Wangguandong Zheng, Tengfei Wang, Yuhao Liu, Zhenwei Wang, Junta Wu, Jie Jiang, Hui Li, Rynson WH Lau, Wangmeng Zuo, and Chunchao Guo. V oyager: Long-range and world-consistent video diffu- sion for explorable 3d scene generation.arXiv preprint arXiv:2506.04225, 2025. 2
-
[23]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. arXiv preprint arXiv:2411.02385, 2024. 3
-
[25]
Dy- namicstereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Dy- namicstereo: Consistent dynamic depth from stereo videos. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 13229– 13239, 2023. 8
2023
-
[26]
Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos
Nikita Karaev, Yuri Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6013–6022, 2025. 3, 6, 7, 8
2025
-
[27]
Comparison of monocular depth estimation methods using geometrically relevant metrics on the ibims-1 dataset.Computer Vision and Image Understanding (CVIU), 191:102877, 2020
Tobias Koch, Lukas Liebel, Marco K ¨orner, and Friedrich Fraundorfer. Comparison of monocular depth estimation methods using geometrically relevant metrics on the ibims-1 dataset.Computer Vision and Image Understanding (CVIU), 191:102877, 2020. 8
2020
-
[28]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Tapvid-3d: A benchmark for tracking any point in 3d.Advances in Neural Information Processing Systems (NeurIPS), 37:82149–82165, 2024
Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, Joao Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch. Tapvid-3d: A benchmark for tracking any point in 3d.Advances in Neural Information Processing Systems (NeurIPS), 37:82149–82165, 2024. 8
2024
-
[30]
arXiv preprint arXiv:2510.18313 (2025)
Bohan Li, Zhuang Ma, Dalong Du, Baorui Peng, Zhujin Liang, Zhenqiang Liu, Chao Ma, Yueming Jin, Hao Zhao, Wenjun Zeng, et al. Omninwm: Omniscient driving naviga- tion world models.arXiv preprint arXiv:2510.18313, 2025. 2
-
[31]
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World mod- els amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025. 2
-
[32]
arXiv preprint arXiv:2506.15675 (2025)
Zhen Li, Chuanhao Li, Xiaofeng Mao, Shaoheng Lin, Ming Li, Shitian Zhao, Zhaopan Xu, Xinyue Li, Yukang Feng, Jianwen Sun, et al. Sekai: A video dataset towards world exploration.arXiv preprint arXiv:2506.15675, 2025. 1, 2, 3
-
[33]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holyn- ski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10486–10496, 2025. 2, 3, 4, 5, 8
2025
-
[34]
Towards world simulator: Crafting physical commonsense-based benchmark for video generation,
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quan- feng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024. 3
-
[35]
Orb-slam: A versatile and accurate monocular slam system.IEEE Transactions on Robotics (TRO), 31:1147– 1163, 2015
Raul Mur-Artal, Jose Maria Martinez Montiel, and Juan D Tardos. Orb-slam: A versatile and accurate monocular slam system.IEEE Transactions on Robotics (TRO), 31:1147– 1163, 2015. 2
2015
-
[36]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 2, 3
work page internal anchor Pith review arXiv 2024
-
[37]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10106–10116, 2024. 3, 5
2024
-
[38]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10901–10911, 2021. 2, 8
2021
-
[39]
Dynamic cam- era poses and where to find them
Chris Rockwell, Joseph Tung, Tsung-Yi Lin, Ming-Yu Liu, David F Fouhey, and Chen-Hsuan Lin. Dynamic cam- era poses and where to find them. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12444–12455, 2025. 2, 3
2025
-
[40]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4104–4113, 2016. 2
2016
-
[41]
Bad slam: Bundle adjusted direct rgb-d slam
Thomas Schops, Torsten Sattler, and Marc Pollefeys. Bad slam: Bundle adjusted direct rgb-d slam. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 134–144, 2019. 8
2019
-
[42]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InProceedings of the European Conference on Computer Vision (ECCV), pages 746–760, 2012. 8
2012
-
[43]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012. 2, 3
work page internal anchor Pith review arXiv 2012
-
[44]
Transnet v2: An effec- tive deep network architecture for fast shot transition detec- tion
Tom ´as Soucek and Jakub Lokoc. Transnet v2: An effec- tive deep network architecture for fast shot transition detec- tion. InProceedings of the ACM International Conference on Multimedia (ACM MM), pages 11218–11221, 2024. 4
2024
-
[45]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in Neural Information Processing Systems (NeurIPS), pages 16558–16569, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in Neural Information Processing Systems (NeurIPS), pages 16558–16569, 2021. 5
2021
-
[46]
Deep patch vi- sual odometry.Advances in Neural Information Processing Systems (NeurIPS), pages 39033–39051, 2023
Zachary Teed, Lahav Lipson, and Jia Deng. Deep patch vi- sual odometry.Advances in Neural Information Processing Systems (NeurIPS), pages 39033–39051, 2023. 5
2023
-
[47]
Sparsity invariant cnns
Jonas Uhrig, Nick Schneider, Lukas Schneider, Uwe Franke, Thomas Brox, and Andreas Geiger. Sparsity invariant cnns. InProceedings of the International Conference on 3D Vision (3DV), pages 11–20, 2017. 8
2017
-
[48]
Igor Vasiljevic, Nick Kolkin, Shanyi Zhang, Ruotian Luo, Haochen Wang, Falcon Z Dai, Andrea F Daniele, Moham- madreza Mostajabi, Steven Basart, Matthew R Walter, et al. Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463, 2019. 8
-
[49]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. 3, 5, 6, 7, 8
2025
-
[51]
Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676,
-
[52]
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content
Qiuheng Wang, Yukai Shi, Jiarong Ou, Rui Chen, Ke Lin, Jiahao Wang, Boyuan Jiang, Haotian Yang, Mingwu Zheng, Xin Tao, et al. Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8428–8437, 2025. 2, 3, 4
2025
-
[53]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10510–10522, 2025. 3
2025
-
[54]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5261–5271, 2025. 3, 6, 7
2025
-
[55]
Dust3r: Geometric 3d vi- sion made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vi- sion made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20697–20709, 2024. 5
2024
-
[56]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Se- bastian Scherer. Tartanair: A dataset to push the limits of visual slam. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916, 2020. 7
2020
-
[57]
Scene graph disentanglement and composition for generalizable complex image generation.Advances in Neural Information Process- ing Systems (NeurIPS), 37:98478–98504, 2024
Yunnan Wang, Ziqiang Li, Wenyao Zhang, Zequn Zhang, Baao Xie, Xihui Liu, Wenjun Zeng, and Xin Jin. Scene graph disentanglement and composition for generalizable complex image generation.Advances in Neural Information Process- ing Systems (NeurIPS), 37:98478–98504, 2024. 3
2024
-
[58]
Spatialtracker: Tracking any 2d pixels in 3d space
Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, and Xiaowei Zhou. Spatialtracker: Tracking any 2d pixels in 3d space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20406–20417, 2024. 3
2024
-
[59]
Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025. 3, 6, 7, 8
-
[60]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 399–417, 2024. 3
2024
-
[61]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5288–5296,
-
[62]
Jiaqi Xu, Xinyi Zou, Kunzhe Huang, Yunkuo Chen, Bo Liu, MengLi Cheng, Xing Shi, and Jun Huang. Easyanimate: A high-performance long video generation method based on transformer architecture.arXiv preprint arXiv:2405.18991,
-
[63]
Ad- vancing high-resolution video-language representation with large-scale video transcriptions
Hongwei Xue, Tiankai Hang, Yanhong Zeng, Yuchong Sun, Bei Liu, Huan Yang, Jianlong Fu, and Baining Guo. Ad- vancing high-resolution video-language representation with large-scale video transcriptions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5036–5045, 2022. 2, 3, 4
2022
-
[64]
Fast3r: Towards 3d reconstruction of 1000+ im- ages in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ im- ages in one forward pass. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21924–21935, 2025. 5
2025
-
[65]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10371–10381, 2024. 3, 5
2024
-
[66]
Blendedmvs: A large- scale dataset for generalized multi-view stereo networks
Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large- scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 1790–1799,
-
[67]
Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Rui-Jie Zhu, Xinhua Cheng, Jiebo Luo, and Li Yuan. Chronomagic-bench: A benchmark for metamorphic evaluation of text-to-time-lapse video gen- eration.Advances in Neural Information Processing Systems (NeurIPS), pages 21236–21270, 2024. 2, 3
2024
-
[68]
Bowei Zhang, Lei Ke, Adam W Harley, and Katerina Fragki- adaki. Tapip3d: Tracking any point in persistent 3d geome- try.arXiv preprint arXiv:2504.14717, 2025. 2, 3, 4, 5, 8
-
[69]
arXiv preprint arXiv:2410.03825 (2024)
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimat- ing geometry in the presence of motion.arXiv preprint arXiv:2410.03825, 2024. 3, 5, 6, 7, 8
-
[70]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gor- don Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), pages 21936–21947,
-
[71]
Genxd: Generating any 3d and 4d scenes.arXiv preprint arXiv:2411.02319, 2024
Yuyang Zhao, Chung-Ching Lin, Kevin Lin, Zhiwen Yan, Linjie Li, Zhengyuan Yang, Jianfeng Wang, Gim Hee Lee, and Lijuan Wang. Genxd: Generating any 3d and 4d scenes. arXiv preprint arXiv:2411.02319, 2024. 2, 3
-
[72]
Pointodyssey: A large-scale synthetic dataset for long-term point tracking
Yang Zheng, Adam W Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J Guibas. Pointodyssey: A large-scale synthetic dataset for long-term point tracking. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (CVPR), pages 19855–19865, 2023. 2, 8
2023
-
[73]
Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37:1–12, 2018
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37:1–12, 2018. 2, 3, 8
2018
-
[74]
Celebv- hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv- hq: A large-scale video facial attributes dataset. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 650–667, 2022. 2, 3
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.