Recognition: 2 theorem links
· Lean TheoremMotionScape: A Large-Scale Real-World Highly Dynamic UAV Video Dataset for World Models
Pith reviewed 2026-05-10 17:07 UTC · model grok-4.3
The pith
A new dataset of highly dynamic UAV videos with 6-DoF trajectories and language annotations improves world models' simulation of complex 3D aerial dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
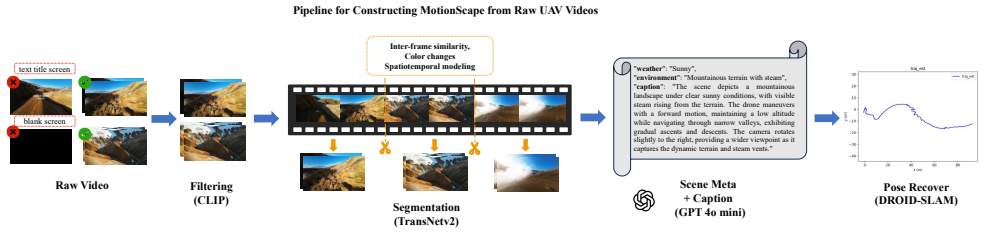
MotionScape supplies over 30 hours of 4K UAV-view videos with more than 4.5 million frames, each tightly coupled to accurate 6-DoF camera trajectories and fine-grained natural language descriptions. An automated multi-stage pipeline performs CLIP-based filtering, robust visual SLAM for trajectory recovery, temporal segmentation, and large-language-model semantic annotation to produce the aligned samples. When existing world models incorporate this data, they gain improved ability to simulate complex 3D dynamics and handle large viewpoint shifts, supporting better decision-making for UAV agents.
What carries the argument
The MotionScape dataset, built through an automated pipeline that couples raw UAV videos with 6-DoF trajectories recovered via visual SLAM and semantic annotations from language models.
Load-bearing premise
That the main barrier for world models on UAV tasks is the absence of high-dynamic 6-DoF motion patterns in prior training data, and that the automatically generated trajectories and annotations are accurate enough to close the gap without adding new errors.
What would settle it
Retrain a baseline world model on MotionScape versus standard datasets alone, then evaluate prediction error on held-out UAV sequences using metrics for 3D spatiotemporal consistency under rapid viewpoint changes; absence of measurable gains would falsify the improvement claim.
Figures



read the original abstract
Recent advances in world models have demonstrated strong capabilities in simulating physical reality, making them an increasingly important foundation for embodied intelligence. For UAV agents in particular, accurate prediction of complex 3D dynamics is essential for autonomous navigation and robust decision-making in unconstrained environments. However, under the highly dynamic camera trajectories typical of UAV views, existing world models often struggle to maintain spatiotemporal physical consistency. A key reason lies in the distribution bias of current training data: most existing datasets exhibit restricted 2.5D motion patterns, such as ground-constrained autonomous driving scenes or relatively smooth human-centric egocentric videos, and therefore lack realistic high-dynamic 6-DoF UAV motion priors. To address this gap, we present MotionScape, a large-scale real-world UAV-view video dataset with highly dynamic motion for world modeling. MotionScape contains over 30 hours of 4K UAV-view videos, totaling more than 4.5M frames. This novel dataset features semantically and geometrically aligned training samples, where diverse real-world UAV videos are tightly coupled with accurate 6-DoF camera trajectories and fine-grained natural language descriptions. To build the dataset, we develop an automated multi-stage processing pipeline that integrates CLIP-based relevance filtering, temporal segmentation, robust visual SLAM for trajectory recovery, and large-language-model-driven semantic annotation. Extensive experiments show that incorporating such semantically and geometrically aligned annotations effectively improves the ability of existing world models to simulate complex 3D dynamics and handle large viewpoint shifts, thereby benefiting decision-making and planning for UAV agents in complex environments. The dataset is publicly available at https://github.com/Thelegendzz/MotionScape
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MotionScape, a dataset comprising over 30 hours of 4K UAV-view videos (more than 4.5M frames) with semantically and geometrically aligned annotations, including 6-DoF camera trajectories recovered via visual SLAM and fine-grained natural language descriptions generated by LLMs. The automated pipeline combines CLIP-based filtering, temporal segmentation, SLAM trajectory recovery, and LLM annotation. The central claim is that training world models on these aligned samples improves simulation of complex 3D dynamics and handling of large viewpoint shifts for UAV agents.
Significance. If the trajectories prove accurate and the claimed improvements hold under rigorous evaluation, the dataset would address a clear gap in high-dynamic 6-DoF training data for world models, potentially aiding UAV planning and decision-making. The public release of the dataset and processing pipeline constitutes a concrete, reusable contribution.
major comments (2)
- [Abstract] Abstract: the statement that 'extensive experiments show that incorporating such semantically and geometrically aligned annotations effectively improves...' is unsupported by any reported quantitative metrics, baselines, ablations, or error analysis, leaving the central empirical claim unverified.
- [Dataset construction pipeline] Dataset construction pipeline: the 'robust visual SLAM' step for 6-DoF trajectory recovery reports no quantitative validation (e.g., ATE, RPE, scale consistency, or comparison against GPS/IMU logs), which is load-bearing because monocular SLAM in high-dynamic UAV footage is prone to drift, tracking loss, and scale ambiguity; without these checks the geometric alignment cannot be assumed sufficient to teach genuine 3D dynamics rather than artifacts.
minor comments (2)
- [Abstract] Abstract: the total number of distinct trajectories or annotated segments is not stated, which would help readers gauge dataset diversity.
- [Dataset availability] Ensure the public GitHub repository includes the full processing code and any filtering thresholds so that the automated pipeline is fully reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments show that incorporating such semantically and geometrically aligned annotations effectively improves...' is unsupported by any reported quantitative metrics, baselines, ablations, or error analysis, leaving the central empirical claim unverified.
Authors: We agree that the abstract's empirical claim would be stronger with explicit references to quantitative results. The current manuscript presents experimental results on world model training, but we acknowledge these could be expanded with clearer metrics and ablations. In the revised version we will update the abstract to reference specific findings and augment the experiments section with additional quantitative metrics, baselines, ablations, and error analysis to fully support the claim. revision: yes
-
Referee: [Dataset construction pipeline] Dataset construction pipeline: the 'robust visual SLAM' step for 6-DoF trajectory recovery reports no quantitative validation (e.g., ATE, RPE, scale consistency, or comparison against GPS/IMU logs), which is load-bearing because monocular SLAM in high-dynamic UAV footage is prone to drift, tracking loss, and scale ambiguity; without these checks the geometric alignment cannot be assumed sufficient to teach genuine 3D dynamics rather than artifacts.
Authors: We concur that quantitative validation of the recovered 6-DoF trajectories is essential. The manuscript describes the use of a robust visual SLAM pipeline but does not report ATE, RPE, scale consistency checks, or comparisons to GPS/IMU. Because synchronized ground-truth sensor logs were not collected for the majority of sequences, direct quantitative comparison is not possible across the full dataset. In the revision we will add a dedicated subsection on trajectory quality, including qualitative validation (visual inspection, smoothness, and cross-sequence consistency), and an explicit limitations discussion covering potential drift, tracking loss, and scale ambiguity in monocular SLAM under high-dynamic UAV motion. revision: partial
Circularity Check
No circularity: dataset release with external empirical validation
full rationale
The paper's core contribution is the release of MotionScape, a new UAV video dataset constructed via an automated pipeline (CLIP filtering, visual SLAM trajectory recovery, LLM semantic annotation). The central claim—that the dataset improves world models on 3D dynamics and viewpoint shifts—is supported by reported experiments measuring performance gains on held-out tasks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The derivation chain is the pipeline itself, which produces new data rather than reducing any result to its own inputs by construction. This is a standard non-circular dataset paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearMotionScape contains over 30 hours of 4K UAV-view videos... automated multi-stage processing pipeline that integrates CLIP-based relevance filtering, temporal segmentation, robust visual SLAM for trajectory recovery, and large-language-model-driven semantic annotation.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMean optical flow magnitude... 36.630 (Ours) vs. TartanAir 41.856
Reference graph
Works this paper leans on
-
[1]
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. 2025. World Simulation with Video Foundation Models for Physical AI. arXiv:2511.00062 [cs.CV] https: //arxiv.org/abs/2511.00062
work page internal anchor Pith review arXiv 2025
-
[2]
Amado Antonini, Winter Guerra, Varun Murali, Thomas Sayre-McCord, and Sertac Karaman. 2018. The blackbird dataset: A large-scale dataset for uav perception in aggressive flight. InInternational Symposium on Experimental Robotics. Springer, 130–139
2018
-
[3]
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. 2020. nuscenes: A multimodal dataset for autonomous driving. 11621–11631 pages
2020
-
[4]
Carlos Campos, Richard Elvira, Juan J Gómez Rodríguez, José MM Montiel, and Juan D Tardós. 2021. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam.IEEE transactions on robotics37, 6 (2021), 1874–1890
2021
-
[5]
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. 2024. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. 7310–7320 pages
2024
-
[6]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming- Hsuan Yang, et al . 2024. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. 13320–13331 pages
2024
-
[7]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al . 2020. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020). https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
Michael Fonder and Marc Van Droogenbroeck. 2019. Mid-air: A multi-modal dataset for extremely low altitude drone flights. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 0–0
2019
-
[9]
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. 2022. Ego4d: Around the world in 3,000 hours of egocentric video. 18995– 19012 pages
2022
-
[10]
David Ha and Jürgen Schmidhuber. 2018. World models.arXiv preprint arXiv:1803.101222, 3 (2018), 440
work page internal anchor Pith review arXiv 2018
-
[11]
2003.Multiple view geometry in computer vision
Richard Hartley and Andrew Zisserman. 2003.Multiple view geometry in computer vision. Cambridge university press
2003
-
[12]
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. 2024. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101(2024). https://arxiv.org/abs/2404. 02101
work page internal anchor Pith review arXiv 2024
-
[13]
Will Kay, Joao Carreira, Karen Simonyan, et al. 2017. The Kinetics Human Action Video Dataset. arXiv:1705.06950 [cs.CV] https://arxiv.org/abs/1705.06950
work page internal anchor Pith review arXiv 2017
-
[14]
Chen-Hsuan Lin, Wei-Chiu Ma, Antonio Torralba, and Simon Lucey. 2021. Barf: Bundle-adjusting neural radiance fields. InProceedings of the IEEE/CVF interna- tional conference on computer vision. 5741–5751
2021
-
[15]
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. 2021. Infinite nature: Perpetual view generation of natural scenes from a single image. InProceedings of the IEEE/CVF International Conference on Computer Vision. 14458–14467
2021
-
[16]
Yixin Liu, Kai Zhang, Yuan Li, et al . 2024. Sora: A Review on Back- ground, Technology, Limitations, and Opportunities of Large Vision Models. arXiv:2402.17177 [cs.CV] https://arxiv.org/abs/2402.17177
work page internal anchor Pith review arXiv 2024
-
[17]
Antonio Loquercio, Elia Kaufmann, René Ranftl, Matthias Müller, Vladlen Koltun, and Davide Scaramuzza. 2021. Learning high-speed flight in the wild.Science Robotics6, 59 (2021), eabg5810
2021
-
[18]
Ye Lyu, George Vosselman, Gui-Song Xia, Alper Yilmaz, and Michael Ying Yang
-
[19]
UAVid: A semantic segmentation dataset for UAV imagery.ISPRS journal of photogrammetry and remote sensing165 (2020), 108–119
2020
-
[20]
András L Majdik, Charles Till, and Davide Scaramuzza. 2017. The Zurich urban micro aerial vehicle dataset.The International Journal of Robotics Research36, 3 (2017), 269–273
2017
-
[21]
Kepan Nan, Rui Xie, Penghao Zhou, et al . 2024. OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation. arXiv:2407.02371 [cs.CV] https://arxiv.org/abs/2407.02371
work page internal anchor Pith review arXiv 2024
-
[22]
OpenAI, :, Aaron Hurst, Adam Lerer, et al . 2024. GPT-4o System Card. arXiv:2410.21276 [cs.CL] https://arxiv.org/abs/2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. 2024. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. (2024), 6892–6903
2024
-
[24]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 4195–4205
2023
-
[25]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. 8748–8763 pages
2021
-
[26]
Johannes L Schonberger and Jan-Michael Frahm. 2016. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition. 4104–4113
2016
- [27]
-
[28]
Tomás Soucek and Jakub Lokoc. 2024. Transnet v2: An effective deep network architecture for fast shot transition detection. 11218–11221 pages
2024
-
[29]
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al
-
[30]
2446–2454 pages
Scalability in perception for autonomous driving: Waymo open dataset. 2446–2454 pages
-
[31]
Zachary Teed and Jia Deng. 2021. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. 16558–16569 pages
2021
-
[32]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. 2023. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942(2023). https://arxiv.org/abs/2307.06942
-
[33]
Zirui Wang, Shangzhe Wu, Weidi Xie, Min Chen, and Victor Adrian Prisacariu
-
[34]
NeRF–: Neural radiance fields without known camera parameters. (2021)
2021
-
[35]
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. 2024. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers. 1–11
2024
-
[36]
Pengfei Zhu, Longyin Wen, Xiao Bian, Haibin Ling, and Qinghua Hu. 2018. Vision meets drones: A challenge.arXiv preprint arXiv:1804.07437(2018). https: //arxiv.org/abs/1804.07437
work page Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.