Recognition: no theorem link
Bridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding
Pith reviewed 2026-05-10 18:35 UTC · model grok-4.3
The pith
Decoupling temporal and spatial localization in video grounding resolves entanglement and token redundancy for MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce Bridge-STG, an end-to-end framework that decouples temporal and spatial localization for spatio-temporal video grounding. It uses the Spatio-Temporal Semantic Bridging mechanism with Explicit Temporal Alignment to distill the MLLM's temporal reasoning context into enriched bridging queries that serve as a semantic interface, paired with Query-Guided Spatial Localization that drives a spatial decoder using multi-layer interactive queries and positive/negative frame sampling to remove dual-domain visual token redundancy. This yields state-of-the-art results among MLLM-based methods, raising average m_vIoU from 26.4 to 34.3 on VidSTG while enabling cross-task transfer in a
What carries the argument
Spatio-Temporal Semantic Bridging (STSB) with Explicit Temporal Alignment (ETA), which distills MLLM temporal reasoning into bridging queries as the semantic interface for the spatial decoder.
If this is right
- Achieves state-of-the-art performance among MLLM-based methods on video grounding benchmarks.
- Raises average m_vIoU from 26.4 to 34.3 on the VidSTG dataset.
- Enables strong cross-task transfer across fine-grained video understanding tasks via unified multi-task training.
- Removes dual-domain visual token redundancy through positive and negative frame sampling in the spatial decoder.
Where Pith is reading between the lines
- The same bridging idea could extend to other tasks that combine sequence reasoning with spatial output, such as dense video captioning.
- Positive and negative frame sampling might generalize to reduce token counts in longer untrimmed videos without retraining the full MLLM.
- Unified multi-task training suggests the framework could serve as a backbone for joint optimization of grounding, action recognition, and moment retrieval.
Load-bearing premise
That the bridging queries can transfer the MLLM's temporal context to the spatial decoder without creating misalignment or losing critical information.
What would settle it
Running the model on VidSTG after ablating Explicit Temporal Alignment and checking whether m_vIoU falls back to or below the 26.4 baseline.
Figures






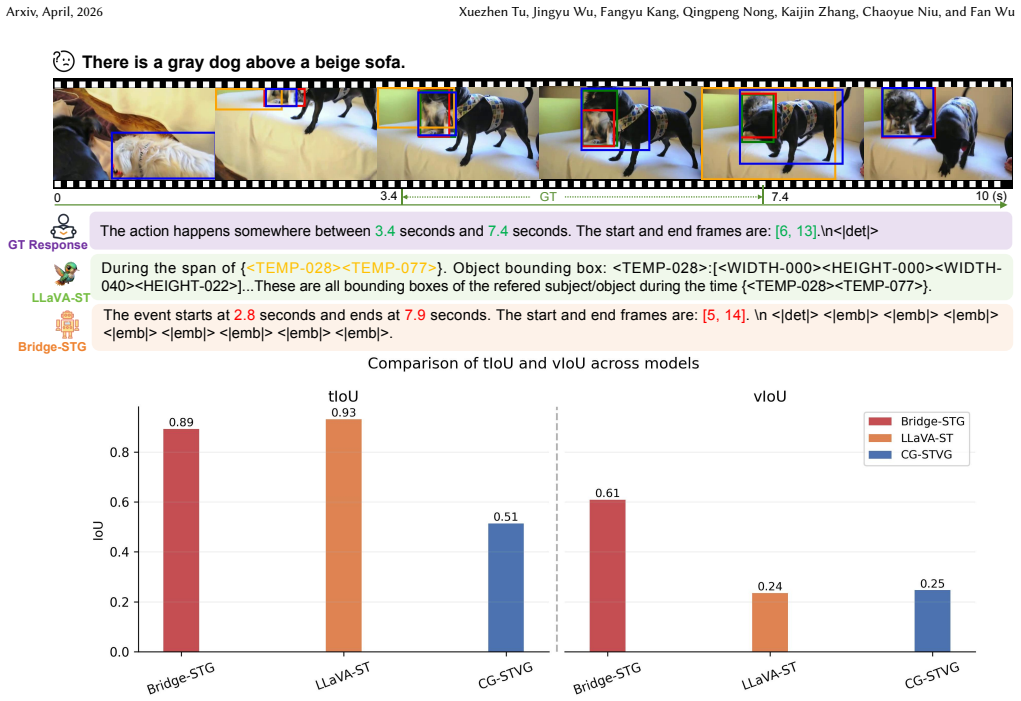

read the original abstract
Spatio-Temporal Video Grounding requires jointly localizing target objects across both temporal and spatial dimensions based on natural language queries, posing fundamental challenges for existing Multimodal Large Language Models (MLLMs). We identify two core challenges: \textit{entangled spatio-temporal alignment}, arising from coupling two heterogeneous sub-tasks within the same autoregressive output space, and \textit{dual-domain visual token redundancy}, where target objects exhibit simultaneous temporal and spatial sparsity, rendering the overwhelming majority of visual tokens irrelevant to the grounding query. To address these, we propose \textbf{Bridge-STG}, an end-to-end framework that decouples temporal and spatial localization while maintaining semantic coherence. While decoupling is the natural solution to this entanglement, it risks creating a semantic gap between the temporal MLLM and the spatial decoder. Bridge-STG resolves this through two pivotal designs: the \textbf{Spatio-Temporal Semantic Bridging (STSB)} mechanism with Explicit Temporal Alignment (ETA) distills the MLLM's temporal reasoning context into enriched bridging queries as a robust semantic interface; and the \textbf{Query-Guided Spatial Localization (QGSL)} module leverages these queries to drive a purpose-built spatial decoder with multi-layer interactive queries and positive/negative frame sampling, jointly eliminating dual-domain visual token redundancy. Extensive experiments across multiple benchmarks demonstrate that Bridge-STG achieves state-of-the-art performance among MLLM-based methods. Bridge-STG improves average m\_vIoU from $26.4$ to $34.3$ on VidSTG and demonstrates strong cross-task transfer across various fine-grained video understanding tasks under a unified multi-task training regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Bridge-STG, an end-to-end MLLM-based framework for spatio-temporal video grounding that decouples temporal localization (handled by the MLLM) from spatial localization (handled by a dedicated decoder). It introduces the Spatio-Temporal Semantic Bridging (STSB) mechanism with Explicit Temporal Alignment (ETA) to distill temporal reasoning context into enriched bridging queries, and the Query-Guided Spatial Localization (QGSL) module that uses these queries with multi-layer interactive queries and positive/negative frame sampling to address dual-domain visual token redundancy. The work claims state-of-the-art results among MLLM-based methods, including an improvement in average m_vIoU from 26.4 to 34.3 on VidSTG, plus strong cross-task transfer under unified multi-task training.
Significance. If the decoupling succeeds in creating a robust semantic interface without information loss or misalignment, the approach could offer a practical template for combining autoregressive MLLMs with specialized spatial decoders in video tasks, improving both accuracy and efficiency while enabling multi-task transfer. The reported VidSTG gains and cross-task results would then represent a meaningful advance over entangled end-to-end MLLM baselines.
major comments (2)
- [Abstract] Abstract: The central quantitative claim (average m_vIoU rising from 26.4 to 34.3 on VidSTG) is presented without any description of the baselines, ablation controls, error bars, data splits, or statistical significance tests. This prevents assessment of whether the reported improvement is attributable to STSB+ETA or to confounding factors such as multi-task training and positive/negative sampling.
- [Abstract] Abstract (STSB with ETA description): The load-bearing assumption that STSB+ETA distills MLLM temporal reasoning context into bridging queries 'without introducing misalignment or loss of critical information' is not supported by any intermediate diagnostics (alignment loss curves, query reconstruction fidelity, temporal-to-spatial attention visualizations, or ablation on ETA). If this interface fails to preserve temporal details, the subsequent QGSL decoder cannot reliably localize and the decoupling benefit collapses.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments across multiple benchmarks' and 'various fine-grained video understanding tasks' but names only VidSTG explicitly; a table or list of all evaluated datasets and tasks would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications from the full paper and indicate revisions where appropriate to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central quantitative claim (average m_vIoU rising from 26.4 to 34.3 on VidSTG) is presented without any description of the baselines, ablation controls, error bars, data splits, or statistical significance tests. This prevents assessment of whether the reported improvement is attributable to STSB+ETA or to confounding factors such as multi-task training and positive/negative sampling.
Authors: We acknowledge that the abstract is concise by nature and omits full experimental details. The full manuscript (Section 4) provides these: comparisons against prior MLLM baselines achieving 26.4 m_vIoU, controlled ablations isolating STSB+ETA and QGSL contributions (showing gains persist under single-task training), VidSTG data splits, and multi-task vs. single-task results demonstrating that positive/negative sampling and bridging are not the sole drivers. No error bars or significance tests are included, following common practice in video grounding literature for m_vIoU; we can add them in revision if needed. The reported gains are attributable to the proposed decoupling, as ablations confirm. revision: partial
-
Referee: [Abstract] Abstract (STSB with ETA description): The load-bearing assumption that STSB+ETA distills MLLM temporal reasoning context into bridging queries 'without introducing misalignment or loss of critical information' is not supported by any intermediate diagnostics (alignment loss curves, query reconstruction fidelity, temporal-to-spatial attention visualizations, or ablation on ETA). If this interface fails to preserve temporal details, the subsequent QGSL decoder cannot reliably localize and the decoupling benefit collapses.
Authors: The paper supports the assumption through explicit design of ETA for temporal alignment and end-to-end results: ablations in Section 4.3 show clear performance drops (e.g., m_vIoU degradation) when ETA is removed, and cross-task transfer under unified training indicates preserved semantic coherence. However, we agree that intermediate diagnostics like alignment curves, reconstruction fidelity, or attention visualizations are absent from the current version. We will incorporate these (e.g., ETA ablation details and bridging query visualizations) in the revised manuscript to directly validate information preservation. revision: yes
Circularity Check
No circularity: empirical architecture with benchmark results, no derivations or self-referential reductions.
full rationale
The paper describes an engineering framework (Bridge-STG with STSB+ETA and QGSL) to address entanglement and token redundancy in video grounding. No equations, derivations, or first-principles results are presented that reduce any claim to its own inputs by construction. Performance gains (e.g., m_vIoU 26.4 to 34.3) are reported from experiments under multi-task training, not derived from fitted parameters renamed as predictions or self-citations that bear the central load. The decoupling and bridging mechanisms are presented as design choices with empirical validation, not tautological redefinitions. This is a standard non-circular empirical CV paper.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Spatio-Temporal Semantic Bridging (STSB) mechanism with Explicit Temporal Alignment (ETA)
no independent evidence
-
Query-Guided Spatial Localization (QGSL) module
no independent evidence
Forward citations
Cited by 1 Pith paper
-
CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
CaC is a hierarchical spatiotemporal concentrating reward model for video anomalies that reports 25.7% accuracy gains on fine-grained benchmarks and 11.7% anomaly reduction in generated videos via a new dataset and GR...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [2]
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al . 2025. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al . 2025. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Wayner Barrios, Mattia Soldan, Alberto Mario Ceballos-Arroyo, Fabian Caba Heilbron, and Bernard Ghanem. 2023. Localizing moments in long video via multimodal guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision. 13667–13678
2023
-
[6]
Jun Chen, Deyao Zhu, Xiaoqian Shen, Xiang Li, Zechun Liu, Pengchuan Zhang, Raghuraman Krishnamoorthi, Vikas Chandra, Yunyang Xiong, and Mohamed Elhoseiny. 2023. MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning (2023).URL https://arxiv. org/abs/2310.09478 18 (2023)
-
[7]
Yi-Wen Chen, Yi-Hsuan Tsai, and Ming-Hsuan Yang. 2021. End-to-end multi- modal video temporal grounding.Advances in Neural Information Processing Systems34 (2021), 28442–28453
2021
-
[8]
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. 2024. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476(2024)
work page internal anchor Pith review arXiv 2024
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24108–24118
2025
-
[11]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. Tall: Temporal activity localization via language query. InProceedings of the IEEE international conference on computer vision. 5267–5275
2017
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Xin Gu, Heng Fan, Yan Huang, Tiejian Luo, and Libo Zhang. 2024. Context-guided spatio-temporal video grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18330–18339
2024
- [14]
- [15]
-
[16]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al . 2025. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062(2025)
work page internal anchor Pith review arXiv 2025
-
[17]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al . 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Yongxin Guo, Jingyu Liu, Mingda Li, Dingxin Cheng, Xiaoying Tang, Dianbo Sui, Qingbin Liu, Xi Chen, and Kevin Zhao. 2025. Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 3302–3310
2025
-
[19]
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang
- [20]
-
[21]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.Iclr1, 2 (2022), 3
2022
-
[22]
Lianghua Huang, Xin Zhao, and Kaiqi Huang. 2019. Got-10k: A large high- diversity benchmark for generic object tracking in the wild.IEEE transactions on pattern analysis and machine intelligence43, 5 (2019), 1562–1577
2019
-
[23]
Jinhyun Jang, Jungin Park, Jin Kim, Hyeongjun Kwon, and Kwanghoon Sohn
-
[24]
In Proceedings of the IEEE/CVF International Conference on Computer Vision
Knowing where to focus: Event-aware transformer for video grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 13846– 13856
-
[25]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. 2024. Chat-univi: Unified visual representation empowers large language models with image and video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13700–13710
2024
-
[26]
Yang Jin, Zehuan Yuan, Yadong Mu, et al . 2022. Embracing consistency: A one-stage approach for spatio-temporal video grounding.Advances in Neural Information Processing Systems35 (2022), 29192–29204
2022
-
[27]
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. 2014. Referitgame: Referring to objects in photographs of natural scenes. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 787–798
2014
-
[28]
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. 2024. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9579–9589
2024
-
[29]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. 2024. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xi- aoming Wei, and Si Liu. 2025. Llava-st: A multimodal large language model for fine-grained spatial-temporal understanding. InProceedings of the Computer Vision and Pattern Recognition Conference. 8592–8603
2025
-
[31]
Xiaohai Li, Bineng Zhong, Qihua Liang, Zhiyi Mo, Jian Nong, and Shuxiang Song
-
[32]
InProceedings of the Computer Vision and Pattern Recognition Conference
Dynamic Updates for Language Adaptation in Visual-Language Tracking. InProceedings of the Computer Vision and Pattern Recognition Conference. 19165– 19174. Arxiv, April, 2026 Xuezhen Tu, Jingyu Wu, Fangyu Kang, Qingpeng Nong, Kaijin Zhang, Chaoyue Niu, and Fan Wu
2026
-
[33]
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. 2024. Video-LLaVA: Learning United Visual Representation by Alignment Before Pro- jection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 5971–5984
2024
-
[34]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[35]
Zihang Lin, Chaolei Tan, Jian-Fang Hu, Zhi Jin, Tiancai Ye, and Wei-Shi Zheng
-
[36]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Collaborative static and dynamic vision-language streams for spatio- temporal video grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23100–23109
-
[37]
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. 2024. Grounding dino: Marry- ing dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision. Springer, 38–55
2024
-
[38]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Chuofan Ma, Yi Jiang, Jiannan Wu, Zehuan Yuan, and Xiaojuan Qi. 2024. Groma: Localized visual tokenization for grounding multimodal large language models. InEuropean Conference on Computer Vision. Springer, 417–435
2024
-
[40]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. 2024. Video-chatgpt: Towards detailed video understanding via large vision and lan- guage models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 12585–12602
2024
-
[41]
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. 2016. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition. 11–20
2016
-
[42]
WonJun Moon, Sangeek Hyun, SangUk Park, Dongchan Park, and Jae-Pil Heo
-
[43]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition
Query-dependent video representation for moment retrieval and highlight detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 23023–23033
-
[44]
Shuhuai Ren, Linli Yao, Shicheng Li, Xu Sun, and Lu Hou. 2024. Timechat: A time-sensitive multimodal large language model for long video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14313–14323
2024
-
[45]
Rui Su, Qian Yu, and Dong Xu. 2021. Stvgbert: A visual-linguistic transformer based framework for spatio-temporal video grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1533–1542
2021
-
[46]
Zongheng Tang, Yue Liao, Si Liu, Guanbin Li, Xiaojie Jin, Hongxu Jiang, Qian Yu, and Dong Xu. 2021. Human-centric spatio-temporal video grounding with visual transformers.IEEE Transactions on Circuits and Systems for Video Technology32, 12 (2021), 8238–8249
2021
-
[47]
Joseph Raj Vishal, Divesh Basina, Aarya Choudhary, and Bharatesh Chakravarthi
- [48]
- [49]
- [50]
-
[51]
Han Wang, Yongjie Ye, Yanjie Wang, Yuxiang Nie, and Can Huang. 2024. Elysium: Exploring object-level perception in videos via mllm. InEuropean Conference on Computer Vision. Springer, 166–185
2024
- [52]
-
[53]
Lan Wang, Gaurav Mittal, Sandra Sajeev, Ye Yu, Matthew Hall, Vishnu Naresh Boddeti, and Mei Chen. 2023. Protege: Untrimmed pretraining for video temporal grounding by video temporal grounding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 6575–6585
2023
-
[54]
Shansong Wang, Mingzhe Hu, Qiang Li, Mojtaba Safari, and Xiaofeng Yang
- [55]
- [56]
- [57]
-
[58]
Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. 2024. Videogrounding-dino: Towards open-vocabulary spatio-temporal video grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18909–18918
2024
-
[59]
Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, and Song Bai. 2024. General object foundation model for images and videos at scale. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3783–3795
2024
-
[60]
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. 2021. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9777–9786
2021
-
[61]
Jinxia Xie, Bineng Zhong, Zhiyi Mo, Shengping Zhang, Liangtao Shi, Shuxi- ang Song, and Rongrong Ji. 2024. Autoregressive queries for adaptive tracking with spatio-temporal transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 19300–19309
2024
-
[62]
Cilin Yan, Haochen Wang, Shilin Yan, Xiaolong Jiang, Yao Hu, Guoliang Kang, Weidi Xie, and Efstratios Gavves. 2024. Visa: Reasoning video object segmentation via large language models. InEuropean Conference on Computer Vision. Springer, 98–115
2024
-
[63]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. 2022. Tubedetr: Spatio-temporal video grounding with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16442– 16453
2022
-
[65]
Chenyu Yang, Xuan Dong, Xizhou Zhu, Weijie Su, Jiahao Wang, Hao Tian, Zhe Chen, Wenhai Wang, Lewei Lu, and Jifeng Dai. 2025. PVC: Progressive Visual Token Compression for Unified Image and Video Processing in Large Vision- Language Models. InProceedings of the Computer Vision and Pattern Recognition Conference. 24939–24949
2025
- [66]
- [67]
- [68]
- [69]
-
[70]
Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, et al. 2025. Glm-4.5: Agentic, reasoning, and coding (arc) foundation models.arXiv preprint arXiv:2508.06471 (2025)
work page internal anchor Pith review arXiv 2025
- [71]
-
[72]
Hao Zhang, Hongyang Li, Feng Li, Tianhe Ren, Xueyan Zou, Shilong Liu, Shijia Huang, Jianfeng Gao, Leizhang, Chunyuan Li, et al . 2024. Llava-grounding: Grounded visual chat with large multimodal models. InEuropean Conference on Computer Vision. Springer, 19–35
2024
- [73]
-
[74]
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao
-
[75]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Where does it exist: Spatio-temporal video grounding for multi-form sentences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10668–10677
- [76]
-
[77]
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. 2025. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2020. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159(2020). Bridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding Arxiv, April, 2026 A Self-Collected Data Details The self-collected data is synthesize...
work page internal anchor Pith review arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.