Recognition: 2 theorem links
· Lean TheoremNeural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling
Pith reviewed 2026-05-10 18:31 UTC · model grok-4.3
The pith
Responsible-DKT injects symbolic mastery and non-mastery rules into neural knowledge tracing to raise accuracy and add interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
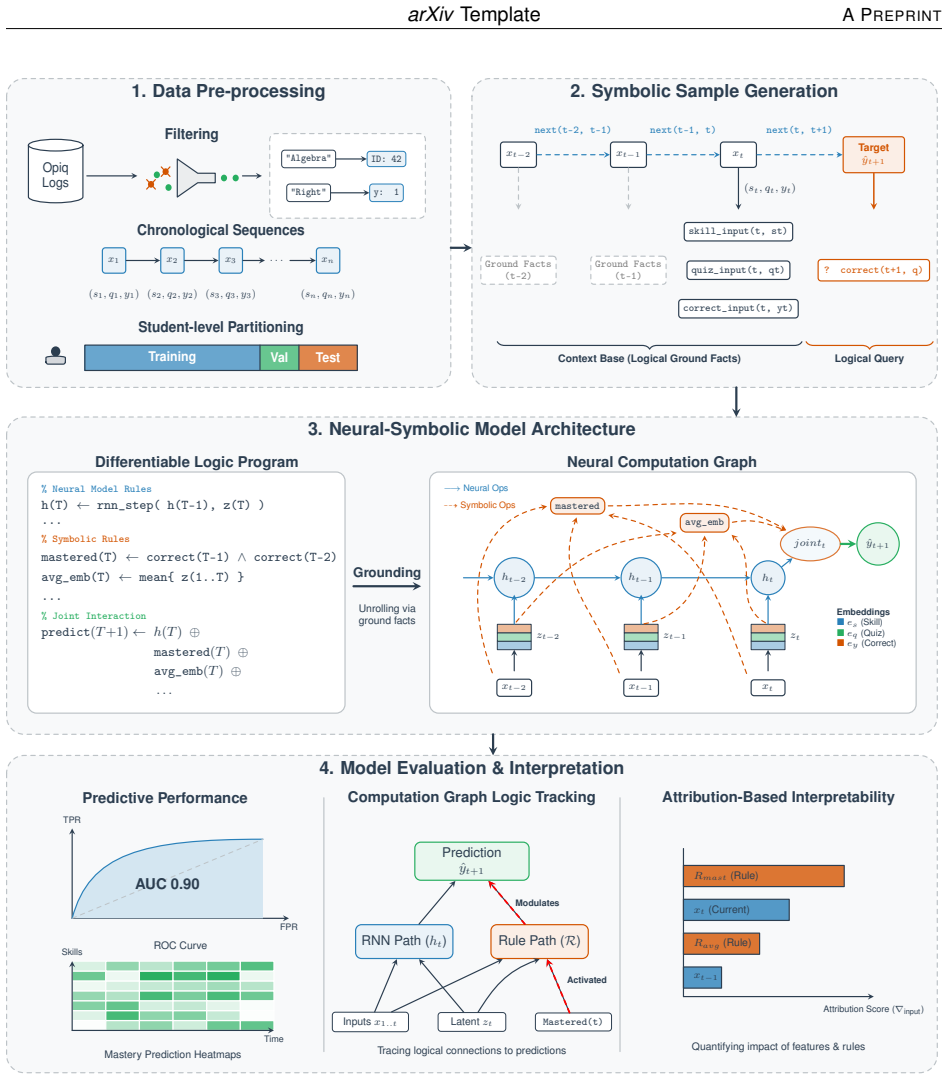
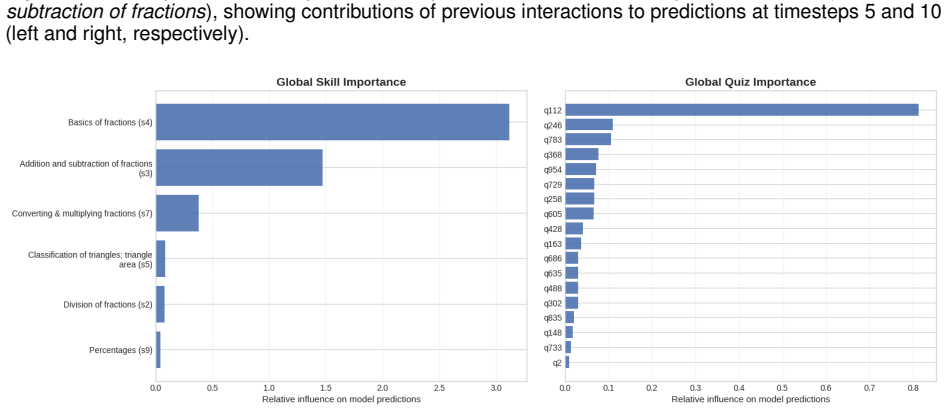
Responsible-DKT integrates symbolic educational knowledge such as mastery and non-mastery rules directly into sequential neural models for knowledge tracing. On a real-world dataset of students' math interactions, it outperforms both a neural-symbolic baseline and a standard PyTorch DKT model, achieving over 0.80 AUC with only 10% training data and up to 0.90 AUC, with improvements of up to 13%. It produces lower prediction errors in early and mid sequences and the lowest inconsistency rates, while its grounded computation graph provides intrinsic interpretability and allows empirical evaluation of pedagogical assumptions like the strong influence of repeated incorrect responses.
What carries the argument
Injection of symbolic mastery and non-mastery rules into the recurrent neural architecture to form a single grounded computation graph that mixes data-driven updates with explicit educational constraints for each prediction.
If this is right
- Higher AUC than both pure neural and prior hybrid baselines across all training-data sizes.
- Strong performance maintained even when only 10 percent of the data is available.
- Lower early- and mid-sequence prediction errors together with the lowest inconsistency rates over sequence lengths.
- Intrinsic interpretability through a grounded computation graph that supports local and global explanations.
- Direct empirical testing of pedagogical assumptions, such as the heavy influence of repeated non-mastery signals.
Where Pith is reading between the lines
- The same rule-injection pattern could be tried in non-math domains such as language or science tutoring to check whether gains transfer.
- The exposed computation graph may let educators inspect and adjust the model's internal logic before deployment.
- If the rules themselves can be learned from data rather than hand-specified, the approach might scale to new subjects without expert authoring.
- Similar hybrids might reduce opacity problems in other sequential modeling tasks that involve domain rules, such as medical event prediction.
Load-bearing premise
The chosen symbolic rules about mastery and non-mastery can be added to the neural model without introducing new biases or limiting what the network can still learn from the data.
What would settle it
A replication on a fresh dataset of student interactions that shows no AUC gain, no reduction in inconsistency rates, or loss of interpretability when the same rules are injected would falsify the central performance and reliability claims.
Figures




read the original abstract
The growing use of artificial intelligence (AI) in education, particularly large language models (LLMs), has increased interest in intelligent tutoring systems. However, LLMs often show limited adaptivity and struggle to model learners' evolving knowledge over time, highlighting the need for dedicated learner modelling approaches. Although deep knowledge tracing methods achieve strong predictive performance, their opacity and susceptibility to bias can limit alignment with pedagogical principles. To address this, we propose Responsible-DKT, a neural-symbolic deep knowledge tracing approach that integrates symbolic educational knowledge (e.g., mastery and non-mastery rules) into sequential neural models for responsible learner modelling. Experiments on a real-world dataset of students' math interactions show that Responsible-DKT outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT model across training settings. The model achieves over 0.80 AUC with only 10% of training data and up to 0.90 AUC, improving performance by up to 13%. It also demonstrates improved temporal reliability, producing lower early- and mid-sequence prediction errors and the lowest prediction inconsistency rates across sequence lengths, indicating that prediction updates remain directionally aligned with observed student responses over time. Furthermore, the neural-symbolic approach offers intrinsic interpretability via a grounded computation graph that exposes the logic behind each prediction, enabling both local and global explanations. It also allows empirical evaluation of pedagogical assumptions, revealing that repeated incorrect responses (non-mastery) strongly influence prediction updates. These results indicate that neural-symbolic approaches enhance both performance and interpretability, mitigate data limitations, and support more responsible, human-centered AI in education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Responsible-DKT, a neural-symbolic deep knowledge tracing model that injects symbolic educational knowledge (mastery and non-mastery rules) into sequential neural models for responsible learner modelling. It claims that this hybrid approach outperforms both a neural-symbolic baseline and a fully data-driven PyTorch DKT on a real-world math interactions dataset, achieving >0.80 AUC with only 10% training data and up to 0.90 AUC (up to 13% improvement), along with lower early/mid-sequence prediction errors, the lowest prediction inconsistency rates across sequence lengths, and intrinsic interpretability via a grounded computation graph that also allows empirical evaluation of pedagogical assumptions (e.g., non-mastery responses strongly influence updates).
Significance. If the results hold under rigorous validation, the work could meaningfully advance hybrid AI methods in education by demonstrating data-efficient, temporally reliable, and interpretable learner modelling that aligns better with pedagogical principles than pure deep learning approaches, while providing a concrete mechanism for evaluating symbolic assumptions.
major comments (2)
- [Experiments] Experiments: the central claim that symbolic rule injection is responsible for the reported AUC gains, temporal reliability improvements, and directional alignment of predictions rests on end-to-end system comparisons but provides no ablation that removes or randomizes the mastery/non-mastery rules while holding architecture, loss weighting, and optimization fixed. Without this, the improvements cannot be causally attributed to the neural-symbolic component rather than incidental differences between Responsible-DKT, the neural-symbolic baseline, and the PyTorch DKT.
- [Experiments] Experiments: the abstract and results sections supply no dataset size, exact baseline implementation details (e.g., hyperparameters, rule encoding for the neural-symbolic baseline), or statistical significance tests for the AUC and inconsistency-rate differences, preventing verification of the soundness of the performance and reliability claims.
minor comments (2)
- [Abstract] Abstract: the phrase 'improving performance by up to 13%' should explicitly state the reference baseline and confirm the metric (AUC is implied but not stated).
- The manuscript could clarify how the grounded computation graph is constructed from the injected rules to support the local/global explanation claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing Responsible-DKT. The comments highlight important aspects of experimental rigor that we will address to strengthen the causal claims and reproducibility of our results. We respond to each major comment below.
read point-by-point responses
-
Referee: Experiments: the central claim that symbolic rule injection is responsible for the reported AUC gains, temporal reliability improvements, and directional alignment of predictions rests on end-to-end system comparisons but provides no ablation that removes or randomizes the mastery/non-mastery rules while holding architecture, loss weighting, and optimization fixed. Without this, the improvements cannot be causally attributed to the neural-symbolic component rather than incidental differences between Responsible-DKT, the neural-symbolic baseline, and the PyTorch DKT.
Authors: We agree that the current comparisons, while informative, do not fully isolate the contribution of the symbolic rules. The neural-symbolic baseline and PyTorch DKT may differ in ways beyond rule injection. In the revised manuscript, we will add an ablation study that removes or randomizes the mastery and non-mastery rules while holding the neural architecture, loss weighting, and optimization procedure fixed. This will provide direct evidence for the causal role of the symbolic component in the observed gains. revision: yes
-
Referee: Experiments: the abstract and results sections supply no dataset size, exact baseline implementation details (e.g., hyperparameters, rule encoding for the neural-symbolic baseline), or statistical significance tests for the AUC and inconsistency-rate differences, preventing verification of the soundness of the performance and reliability claims.
Authors: We acknowledge that these details are necessary for full reproducibility and verification. Although the manuscript describes the real-world math interactions dataset, we will expand the experiments section to report the exact dataset size (number of students and interactions), all hyperparameters for Responsible-DKT and both baselines, the precise rule encoding method used in the neural-symbolic baseline, and statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) for the AUC and inconsistency-rate differences. These additions will be included in the revision. revision: yes
Circularity Check
No circularity: empirical results rest on external dataset comparisons
full rationale
The paper's claims derive from end-to-end experimental comparisons of Responsible-DKT against a neural-symbolic baseline and a PyTorch DKT model on real student math interaction data. Metrics (AUC, temporal error, inconsistency rates) are measured directly on held-out sequences rather than being algebraically forced by the model's own definitions or by self-citation. The symbolic mastery/non-mastery rules are an architectural choice whose contribution is assessed via overall system performance; no equation or theorem in the provided text reduces the reported gains to a tautology or to a prior result whose only support is the current paper. Self-citations, if present, are not load-bearing for the central empirical finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Symbolic educational knowledge such as mastery and non-mastery rules can be effectively encoded and integrated into neural sequential models without harming predictive power.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniquely forced by reciprocal cost axioms) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
symbolic rules R encode pedagogically motivated constraints... mastered(T)←correct(T-1)∧correct(T-2); not_mastered after three incorrect responses; correct(t,x)←mastered(x,t) ⊕ not_mastered(x,t) ⊕ avg_embed
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
grounded computation graph... PyNeuraLogic template... next(t,t+1) transitions
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Agentic Education: Using Claude Code to Teach Claude Code
cc-self-train is an adaptive project-based curriculum for mastering Claude Code featuring persona progression from Guide to Launcher, hook-based engagement adaptation, cross-domain unified feature sequencing, explicit...
Reference graph
Works this paper leans on
-
[1]
doi:10.1002/aaai.12046. Kenneth R Koedinger, Paulo F Carvalho, Ran Liu, and Elizabeth A McLaughlin. An astonishing regularity in student learning rate.Proceedings of the National Academy of Sciences, 120(13):e2221311120, 2023. doi:10.1073/pnas.2221311120. Ekaterina Krivich, Danial Hooshyar, Gustav Šír, Y eongwook Y ang, Mari Bauters, Raija Hämäläinen, and...
-
[2]
Guillaume Lample and François Charton
doi:10.48550/arXiv.1911.06473. Guillaume Lample and François Charton. Deep learning for symbolic mathematics.arXiv Preprint arXiv:1912.01412, 2019. Jinsook Lee, Y ann Hicke, Renzhe Yu, Christopher Brooks, and René F Kizilcec. The life cycle of large language models in education: A framework for understanding sources of bias.British Journal of Educational ...
-
[3]
Chun-Kit Y eung and Dit-Y an Y eung
doi:10.1007/978-3-030-67658-2_18. Chun-Kit Y eung and Dit-Y an Y eung. Addressing two problems in deep knowledge tracing via prediction- consistent regularization. InProceedings of the ACM Conference on Learning@Scale, pages 1–10, 2018. doi:10.1145/3231644.3231645. Yu Yin, Qi Liu, Zhenya Huang, Enhong Chen, Wei Tong, Shijin Wang, and Yiting Su. Quesnet: A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.