Recognition: unknown
Agentic Education: Using Claude Code to Teach Claude Code
Pith reviewed 2026-05-10 05:40 UTC · model grok-4.3
The pith
A modular curriculum adapts AI instructor personas and engagement heuristics to teach an agentic coding tool, producing self-efficacy gains across skills in a pilot.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
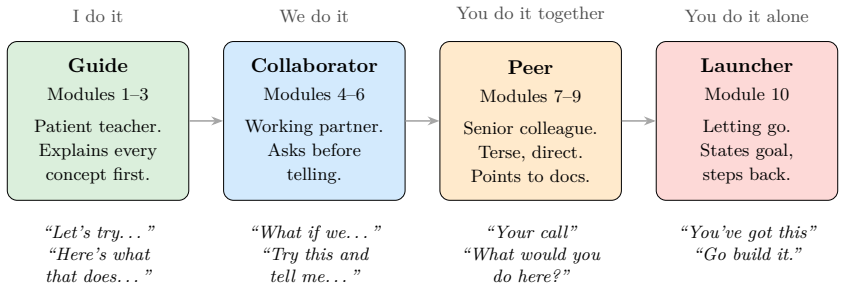
By combining a persona progression model (Guide to Collaborator to Peer to Launcher), hook-based adaptive scaffolding at two timescales, identical feature sequencing across domains, explicit pause primitives, and upstream change detection for auto-updates, the cc-self-train system enables learners to acquire practical mastery of Claude Code as measured by increased self-efficacy in a pilot evaluation.
What carries the argument
The persona progression model that operationalizes gradual release of responsibility by shifting the AI instructor from directive Guide to autonomous Launcher while hook-based heuristics detect engagement quality to adjust scaffolding.
If this is right
- Unified feature sequencing across domains supports transfer learning so mastery in one project type accelerates progress in others.
- Two-timescale adaptation (streak detection for immediate intervention and aggregate metrics for persona shifts) reduces information overload while maintaining structure.
- Auto-updating from upstream tool changes keeps the curriculum current without manual rewriting.
- The step-pacing mechanism with explicit pause primitives provides a concrete way to manage cognitive load when an AI acts as primary instructor.
Where Pith is reading between the lines
- The same adaptive-persona structure could be ported to teach other agentic AI systems whose interfaces evolve rapidly.
- If objective skill measures confirm the self-efficacy results, the curriculum format offers a scalable template for onboarding developers to new AI tools without relying on scattered documentation.
- Cross-domain consistency may allow curriculum designers to test pedagogical invariants once and apply them to many domains rather than rebuilding for each new tool.
Load-bearing premise
That gains in self-reported confidence after a short pilot with 27 participants reflect durable skill acquisition that will appear in other learners and other agentic tools.
What would settle it
A controlled study that tracks objective performance on standardized coding tasks (such as implementing a custom skill or using hooks correctly) before and after curriculum use, compared against a no-curriculum control group.
Figures



read the original abstract
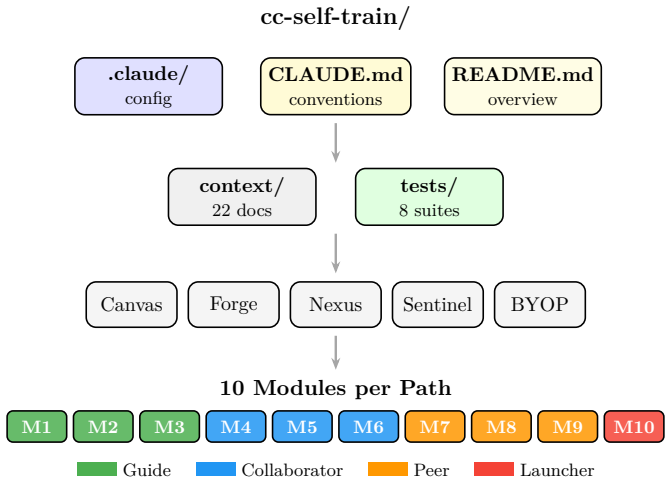
AI coding assistants have proliferated rapidly, yet structured pedagogical frameworks for learning these tools remain scarce. Developers face a gap between tool documentation and practical mastery, relying on fragmented resources such as blog posts, video tutorials, and trial-and-error. We present cc-self-train, a modular interactive curriculum for learning Claude Code, an agentic AI coding tool, through hands-on project construction. The system introduces five contributions: (1) a persona progression model that adapts instructor tone across four stages (Guide, Collaborator, Peer, Launcher), operationalizing Gradual Release of Responsibility for AI-mediated instruction; (2) an adaptive learning system that observes engagement quality through hook-based heuristics and adjusts scaffolding at two timescales, using streak detection for mid-module intervention and aggregate metrics for module-boundary persona changes; (3) a cross-domain unified curriculum in which five distinct project domains share identical feature sequencing, enabling transfer learning; (4) a step-pacing mechanism with explicit pause primitives to manage information overload in an AI-as-instructor context; and (5) an auto-updating curriculum design in which the onboarding agent detects upstream tool changes and updates teaching materials before instruction begins. A parametrized test suite enforces structural consistency as a proxy for pedagogical invariants across all 50 modules. A pilot evaluation with 27 participants shows statistically significant reported self-efficacy gains across all 10 assessed skill areas (p < 0.001), with the largest effects on advanced features such as hooks and custom skills. We discuss implications for the design of auto-updating educational systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces cc-self-train, a modular interactive curriculum for learning Claude Code (an agentic AI coding tool) via hands-on project construction across five domains. It details five contributions: (1) a persona progression model (Guide, Collaborator, Peer, Launcher) operationalizing Gradual Release of Responsibility; (2) an adaptive system using hook-based heuristics to observe engagement and adjust scaffolding at two timescales; (3) a unified cross-domain curriculum enabling transfer; (4) step-pacing with explicit pause primitives; and (5) an auto-updating mechanism that detects tool changes. A parametrized test suite enforces consistency across 50 modules. A pilot with 27 participants reports statistically significant self-efficacy gains (p < 0.001) across 10 skill areas, largest for advanced features such as hooks and custom skills.
Significance. If the central claims hold under stronger evaluation, the work could meaningfully advance pedagogical design for rapidly evolving AI coding assistants by providing concrete mechanisms for adaptive, self-maintaining instruction. The parametrized test suite for structural consistency across modules and the auto-updating feature are notable strengths that support reproducibility and practicality. The unified curriculum and persona model offer a structured approach to transfer learning and scaffolding that could generalize beyond this specific tool.
major comments (2)
- [Pilot Evaluation] Pilot Evaluation: The headline result of statistically significant self-efficacy gains (p < 0.001) across all 10 assessed skill areas rests on a within-subjects pre/post comparison of self-reports from n=27 participants. No control or comparison arm, objective performance metrics (e.g., task success rates on hook or custom-skill exercises), validated instrument details, recruitment method, or multiple-testing correction are described. This leaves the gains vulnerable to demand characteristics, expectancy effects, and repeated-testing artifacts, directly undermining attribution to the five listed contributions.
- [Adaptive Learning System] Adaptive Learning System: The hook-based heuristics for detecting engagement quality (used for mid-module streak interventions and module-boundary persona shifts) are presented as a core mechanism but without concrete definitions, example implementations, or any validation against actual engagement or learning outcomes. Because this heuristic drives the adaptive scaffolding claim, its operationalization must be specified to evaluate whether it functions as a reliable proxy.
minor comments (2)
- [Abstract] The abstract states that five distinct project domains share identical feature sequencing but does not name the domains; listing them would clarify the transfer-learning design.
- [Step-Pacing Mechanism] The description of the step-pacing mechanism with pause primitives would benefit from a short example of how pauses are triggered and what information is withheld during overload management.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have made revisions to improve clarity, transparency, and rigor where possible. The changes focus on better describing the pilot methods and limitations as well as operationalizing the adaptive heuristics.
read point-by-point responses
-
Referee: [Pilot Evaluation] The headline result of statistically significant self-efficacy gains (p < 0.001) across all 10 assessed skill areas rests on a within-subjects pre/post comparison of self-reports from n=27 participants. No control or comparison arm, objective performance metrics (e.g., task success rates on hook or custom-skill exercises), validated instrument details, recruitment method, or multiple-testing correction are described. This leaves the gains vulnerable to demand characteristics, expectancy effects, and repeated-testing artifacts, directly undermining attribution to the five listed contributions.
Authors: We agree that the pilot is exploratory and has important limitations. It was designed as a within-subjects pre/post feasibility study rather than a controlled trial. In the revised manuscript we have added: recruitment details (self-selected volunteers from AI developer communities via forum posts with IRB-approved consent), instrument description (10-item Likert self-efficacy questionnaire with items aligned to the assessed skills, adapted from prior computer self-efficacy scales), explicit discussion of multiple-comparison issues, and an expanded limitations section covering demand characteristics, repeated-testing effects, and the lack of objective metrics or control arm. We have also moderated causal language to present the results as preliminary evidence. We cannot add new data collection or a control condition within the scope of this revision. revision: partial
-
Referee: [Adaptive Learning System] The hook-based heuristics for detecting engagement quality (used for mid-module streak interventions and module-boundary persona shifts) are presented as a core mechanism but without concrete definitions, example implementations, or any validation against actual engagement or learning outcomes. Because this heuristic drives the adaptive scaffolding claim, its operationalization must be specified to evaluate whether it functions as a reliable proxy.
Authors: We appreciate the request for specificity. The revised manuscript now contains a new subsection with concrete operational definitions of the hook-based heuristics. Mid-module streak interventions trigger on observable log patterns: average response latency >90 seconds or response length <30 tokens across three consecutive steps. Module-boundary persona shifts use an aggregate engagement score combining completion rate, pause usage, and embedded self-report prompts. We include pseudocode, concrete threshold values, and two illustrative session traces. Exploratory analysis in the supplement shows modest positive correlations between these proxies and self-efficacy gains. We frame the heuristics explicitly as initial, observable proxies rather than validated measures. revision: yes
- Absence of a control arm and objective performance metrics (e.g., task success rates) in the pilot evaluation; these cannot be supplied without new data collection beyond the current revision.
Circularity Check
No circularity: empirical pilot without derivations or self-referential reductions
full rationale
The paper describes a curriculum design (persona progression, adaptive scaffolding, unified modules, step-pacing, auto-updating) and reports a within-subjects pilot of self-reported self-efficacy gains (p<0.001, n=27) across 10 skill areas. No equations, fitted parameters, predictions, or first-principles derivations appear in the abstract or described full text. The evaluation is presented as direct empirical observation rather than a quantity computed from prior inputs or self-citations. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The central claims therefore remain independent of the patterns that would produce circularity scores above 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Gradual Release of Responsibility model can be operationalized through AI persona progression for effective instruction
- ad hoc to paper Hook-based heuristics provide a reliable proxy for engagement quality in AI-mediated learning
invented entities (1)
-
cc-self-train curriculum system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
1956 , publisher =
Taxonomy of Educational Objectives: The Classification of Educational Goals , author =. 1956 , publisher =
1956
-
[2]
2013 , edition =
Better Learning Through Structured Teaching: A Framework for the Gradual Release of Responsibility , author =. 2013 , edition =
2013
-
[3]
Cognitive Science , volume =
Cognitive Load During Problem Solving: Effects on Learning , author =. Cognitive Science , volume =
-
[4]
1980 , publisher =
Mindstorms: Children, Computers, and Powerful Ideas , author =. 1980 , publisher =
1980
-
[5]
and Krathwohl, David R
Anderson, Lorin W. and Krathwohl, David R. , year =. A Taxonomy for Learning, Teaching, and Assessing: A Revision of
-
[6]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2022 , howpublished =
GitHub. 2022 , howpublished =
2022
-
[8]
2024 , howpublished =
Cursor: The. 2024 , howpublished =
2024
-
[9]
2025 , howpublished =
Claude Code: An agentic coding tool , author =. 2025 , howpublished =
2025
-
[10]
2025 , howpublished =
Codex: An autonomous coding agent , author =. 2025 , howpublished =
2025
-
[11]
Everything Claude Code: A Production-Ready Configuration System for
Affaan, Muhammad , year =. Everything Claude Code: A Production-Ready Configuration System for
-
[12]
2025 , howpublished =
2025
-
[13]
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and others , journal =
-
[14]
Chase, Harrison , year =
-
[15]
Frontiers of Computer Science , volume =
A Survey on Large Language Model based Autonomous Agents , author =. Frontiers of Computer Science , volume =
-
[16]
2025 , howpublished =
Anthropic Courses , author =. 2025 , howpublished =
2025
-
[17]
and Denny, Paul and Craig, Michelle and Grossman, Tovi , booktitle =
Kazemitabaar, Majeed and Ye, Runlong and Wang, Xiaoning and Henley, Austin Z. and Denny, Paul and Craig, Michelle and Grossman, Tovi , booktitle =. 2024 , doi =
2024
-
[18]
From Passive Tool to Socio-cognitive Teammate: A Conceptual Framework for Agentic
Yan, Lixiang , journal =. From Passive Tool to Socio-cognitive Teammate: A Conceptual Framework for Agentic
-
[19]
A Scoping Review of Large Language Model-Based Pedagogical Agents
A Scoping Review of Large Language Model-Based Pedagogical Agents , author =. arXiv preprint arXiv:2604.12253 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Your Brain on
Kosmyna, Nataliya and Hauptmann, Eugene and Yuan, Ye Tong and Situ, Jessica and Liao, Xian-Hao and Beresnitzky, Ashly Vivian and Braunstein, Iris and Maes, Pattie , journal =. Your Brain on
-
[21]
2025 , howpublished =
Superpowers: Agentic Skills Framework for Software Development , author =. 2025 , howpublished =
2025
-
[22]
and Denny, Paul and Finnie-Ansley, James and Luxton-Reilly, Andrew and Prather, James and Santos, Eddie Antonio , booktitle =
Becker, Brett A. and Denny, Paul and Finnie-Ansley, James and Luxton-Reilly, Andrew and Prather, James and Santos, Eddie Antonio , booktitle =. Programming Is Hard -- Or at Least It Used to Be: Educational Opportunities and Challenges of. 2023 , doi =
2023
-
[23]
and Weintrop, David and Grossman, Tovi , booktitle =
Kazemitabaar, Majeed and Chow, Justin and Ma, Carl Ka To and Ericson, Barbara J. and Weintrop, David and Grossman, Tovi , booktitle =. Studying the effect of. 2023 , doi =
2023
-
[24]
and Leinonen, Juho and MacNeil, Stephen and Randrianasolo, Arisoa and Becker, Brett A
Prather, James and Reeves, Brent N. and Leinonen, Juho and MacNeil, Stephen and Randrianasolo, Arisoa and Becker, Brett A. and Kimmel, Bailey and Wright, Jared and Briggs, Ben , booktitle =. The Widening Gap: The Benefits and Harms of Generative. 2024 , doi =
2024
-
[25]
Effective Personalized
Chung, Bobby and Zhang, Chenyue and Kung, Alvin and Bastani, Hamsa and Bastani, Osbert , journal =. Effective Personalized. 2025 , note =
2025
-
[26]
Neural-Symbolic Knowledge Tracing: Injecting Educational Knowledge into Deep Learning for Responsible Learner Modelling , author =. arXiv preprint arXiv:2604.08263 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Advances in Neural Information Processing Systems , volume =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[28]
Advances in Neural Information Processing Systems , volume =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[29]
, journal =
White, Jules and Fu, Quchen and Hays, Sam and Sandborn, Michael and Olea, Carlos and Gilbert, Henry and Elnashar, Ashraf and Spencer-Smith, Jesse and Schmidt, Douglas C. , journal =. A Prompt Pattern Catalog to Enhance Prompt Engineering with
-
[30]
Challapally, Aditya and Pease, Chris and Raskar, Ramesh and Chari, Pradyumna , institution =. The. 2025 , month = jul, type =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.