Floating or Suggesting Ideas? A Large-Scale Contrastive Analysis of Metaphorical and Literal Verb-Object Constructions
Pith reviewed 2026-05-10 16:45 UTC · model grok-4.3
The pith
Metaphorical and literal verb-object constructions show no single consistent pattern across linguistic features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The analysis of 297 verb-object pairs in approximately 2 million sentences reveals that literal contexts generally exhibit higher lexical frequency, cohesion, and structural regularity, whereas metaphorical contexts display greater affective load, imageability, lexical diversity, and constructional specificity. Within-pair examinations show substantial heterogeneity, with most pairs displaying non-uniform effects. These findings indicate that no single, consistent distributional pattern distinguishes metaphorical from literal usage; differences are largely construction-specific.
What carries the argument
Contrastive analysis of 2,293 cognitive and linguistic features extracted by five NLP tools across metaphorical and literal contexts of 297 verb-object pairs.
If this is right
- Metaphor research should prioritize construction-specific analyses over searches for universal distinguishing rules.
- Large-scale corpus work with multi-tool feature extraction can expose fine-grained, pair-dependent usage contrasts in language.
- Computational systems for metaphor detection or generation would gain accuracy by incorporating information tied to individual verb-object pairs.
- Within-pair comparisons alongside cross-pair trends offer a more precise way to map how literal and figurative language actually behave.
Where Pith is reading between the lines
- General-purpose metaphor identification tools that rely on broad distributional signals may underperform unless they also model specific verb-object combinations.
- The observed heterogeneity raises the possibility that similar construction-specific patterns appear in other languages or other near-synonymous expression types.
- Corpus-derived contrasts could be tested against psycholinguistic measures to check whether large-scale data align with human processing differences at the level of individual constructions.
Load-bearing premise
The 2,293 features extracted by the five NLP tools fully and without systematic bias capture all relevant affective, lexical, syntactic, and discourse properties that could distinguish metaphorical from literal uses.
What would settle it
Discovery of even one feature or small consistent set of features that reliably separates metaphorical from literal contexts across most of the 297 pairs would falsify the claim of no single pattern.
Figures


read the original abstract
Metaphor pervades everyday language, allowing speakers to express abstract concepts via concrete domains. While prior work has studied metaphors cognitively and psycholinguistically, large-scale comparisons with literal language remain limited, especially for near-synonymous expressions. We analyze 297 English verb-object pairs (e.g., float idea vs. suggest idea) in ~2M corpus sentences, examining their contextual usage. Using five NLP tools, we extract 2,293 cognitive and linguistic features capturing affective, lexical, syntactic, and discourse-level properties. We address: (i) whether features differ between metaphorical and literal contexts (cross-pair analysis), and (ii) whether individual VO pairs diverge internally (within-pair analysis). Cross-pair results show literal contexts have higher lexical frequency, cohesion, and structural regularity, while metaphorical contexts show greater affective load, imageability, lexical diversity, and constructional specificity. Within-pair analyses reveal substantial heterogeneity, with most pairs showing non-uniform effects. These results suggest no single, consistent distributional pattern that distinguishes metaphorical from literal usage. Instead, differences are largely construction-specific. Overall, large-scale data combined with diverse features provides a fine-grained understanding of metaphor-literal contrasts in VO usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale corpus study of 297 English verb-object pairs (e.g., 'float idea' vs. 'suggest idea') drawn from ~2M sentences. Five off-the-shelf NLP tools extract 2,293 features spanning affective, lexical, syntactic, and discourse properties. Cross-pair aggregate analyses report that literal contexts exhibit higher lexical frequency, cohesion, and structural regularity, while metaphorical contexts show elevated affective load, imageability, lexical diversity, and constructional specificity. Within-pair analyses find substantial heterogeneity, with most pairs exhibiting non-uniform feature effects. The authors conclude that no single, consistent distributional pattern distinguishes metaphorical from literal usage; differences are largely construction-specific.
Significance. If the heterogeneity result survives controls for sample-size imbalance, the work supplies a valuable large-scale empirical demonstration that metaphor-literal contrasts in VO constructions lack a uniform signature and are instead highly pair-dependent. The scale (~2M sentences) and feature breadth (2,293 dimensions from multiple tools) constitute clear strengths, offering a finer-grained picture than prior small-scale or single-feature studies and supplying testable predictions for cognitive linguistics and computational metaphor detection. The absence of a single overarching pattern challenges assumptions in the literature that distributional cues are broadly reliable across constructions.
major comments (1)
- Within-pair analyses (Results section): The central claim that 'most pairs showing non-uniform effects' and thus 'differences are largely construction-specific' rests on per-pair statistical tests. Because sentence counts per pair are almost certainly highly skewed (Zipfian) in a 2M-sentence corpus, low-N pairs will have low power to detect differences, producing more non-significant results and inflating the count of 'non-uniform' pairs. The manuscript does not report per-pair N values, conduct power analyses, apply frequency-weighted aggregates, or correct for multiple testing across 2,293 features. This statistical design issue is load-bearing for the heterogeneity conclusion and could be addressed by re-running the within-pair tests with explicit N reporting, effect-size confidence intervals, or subsampling to equalize power.
Simulated Author's Rebuttal
We thank the referee for their careful and constructive review. The concern regarding statistical power and reporting in the within-pair analyses is well-taken, and we address it directly below with plans for revision.
read point-by-point responses
-
Referee: Within-pair analyses (Results section): The central claim that 'most pairs showing non-uniform effects' and thus 'differences are largely construction-specific' rests on per-pair statistical tests. Because sentence counts per pair are almost certainly highly skewed (Zipfian) in a 2M-sentence corpus, low-N pairs will have low power to detect differences, producing more non-significant results and inflating the count of 'non-uniform' pairs. The manuscript does not report per-pair N values, conduct power analyses, apply frequency-weighted aggregates, or correct for multiple testing across 2,293 features. This statistical design issue is load-bearing for the heterogeneity conclusion and could be addressed by re-running the within-pair tests with explicit N reporting, effect-size confidence intervals, or subsampling to equalize power.
Authors: We agree that sentence counts per pair are likely to be highly skewed in a corpus of this size, which can reduce power for low-N pairs and potentially inflate the proportion of pairs classified as non-uniform. The original manuscript did not report per-pair N distributions, conduct power analyses, use frequency-weighted aggregates, or apply multiple-testing corrections across the 2,293 features. In revision we will add: (i) a summary of the per-pair sentence counts (including min, max, median, and a histogram), (ii) effect sizes with confidence intervals for all within-pair comparisons, (iii) a discussion of how low-N pairs affect the heterogeneity result, and (iv) a robustness check via subsampling from high-N pairs to equalize power. For multiple testing we will clarify that the analysis was exploratory and focused on directional consistency rather than isolated p-values; we will also report FDR-adjusted results for the main within-pair tests. These additions will make the heterogeneity claim more robust and transparent. revision: yes
Circularity Check
No circularity: purely empirical corpus analysis
full rationale
The paper conducts a large-scale observational study on ~2M corpus sentences for 297 pre-identified VO pairs. It applies five external off-the-shelf NLP tools to extract 2,293 features and performs statistical comparisons (cross-pair and within-pair). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The central claim of construction-specific heterogeneity follows directly from the data distributions rather than reducing to any input by construction. Potential statistical-power artifacts from uneven sentence counts per pair are a methodological concern but do not constitute circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 297 selected verb-object pairs are near-synonymous and representative for comparing metaphorical versus literal usage.
- domain assumption The five NLP tools produce reliable measurements of the intended cognitive and linguistic properties.
Reference graph
Works this paper leans on
-
[1]
Introduction Metaphor is a "necessary" language feature of everyday thought and communication that allows speakerstoconceptualizeabstractideasintermsof more concrete domains (Ortony, 1975; Lakoff and Johnson, 1980; van den Broek, 1981; Schäffner, 2004, i.a.). While metaphor has been extensively studiedincognitivelinguisticsandpsycholinguistics (Gibbs, 198...
work page internal anchor Pith review Pith/arXiv arXiv 1975
-
[2]
Datasets and Linguistic Features VOPairsWe downloaded theVOs from Piccirilli et al. (2024). They collected a set of 47VOs from previous work (Mohammad et al., 2016; Shutova, 2010; Piccirilli and Schulte im Walde, 2021; Stowe et al., 2022), which they semi-automatically ex- tended by collecting the most frequently observed shared direct objects of the corr...
work page 2024
-
[3]
Comparison of Metaphorical and Literal Verb-Objects: Approach For comparing metaphorical vs. literalVOs, this work addresses two research questions: RQ1Arethereconsistentdifferencesincognitive and linguistic feature patternsbetween literal and metaphorical language (=cross-pair)? RQ2Are therespecificVOpairsshowing a par- ticularly strong contrast in cogni...
-
[4]
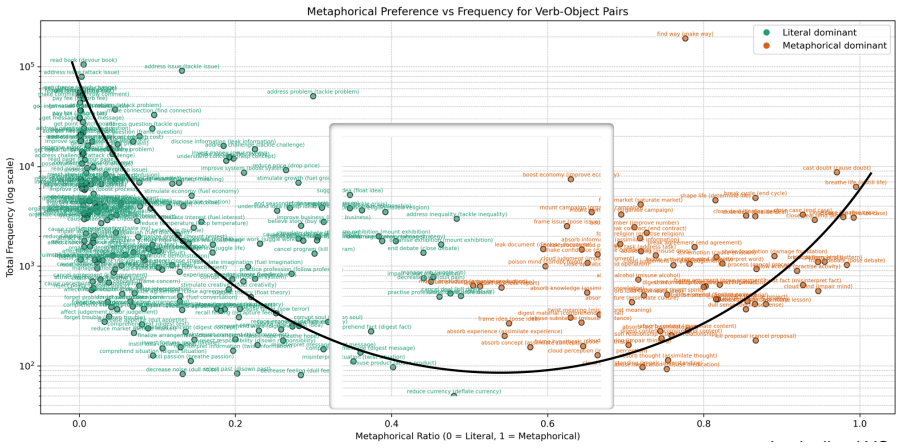
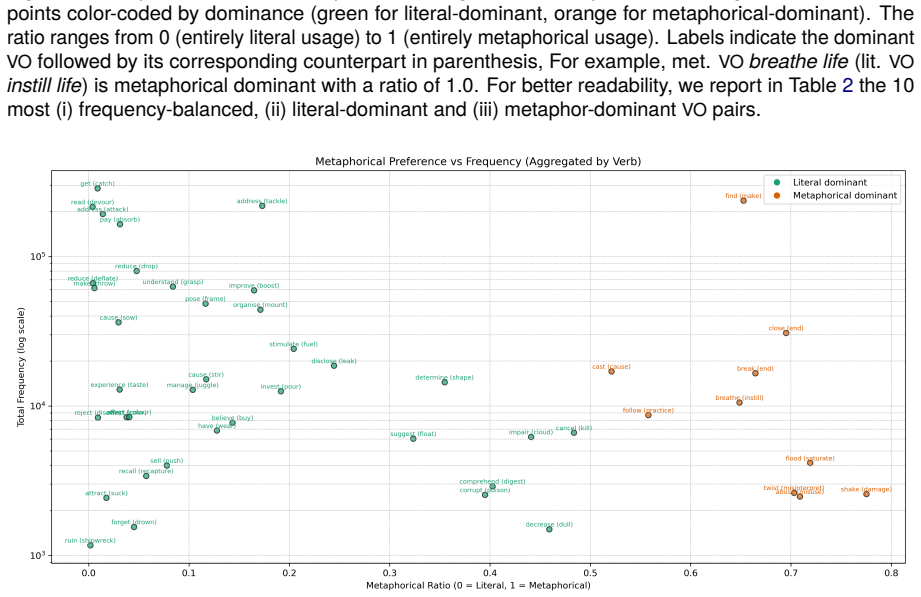
Analyses and Discussion Thissectionprovidesouranalysesanddiscussions regarding our two research questionsThese two main studies in Sections 4.2 and 4.3 are preceded by a frequency analysis (Section 4.1). 4.1. Metaphorical vs. Literal Preferences FrequencyTable 1 presents an overview of the distribution of literal and metaphorical sentences across our 297V...
work page 1980
-
[5]
with a very high frequency. This finding high- lights how crucial it is to consider the verb and its object as a unit, as verbs behave very differently in terms of their frequency and metaphoricity when considered with or without their objects. 4.2. Cross-Pair Analysis: Feature-based Comparison of Metaphorical and Literal VOs In this section, we address o...
work page 1980
-
[6]
Conclusion This study provides a large-scale, feature-based comparison of metaphorical and literal verb–object constructions in natural English sentences. Lever- aging nearly two million corpus instances and over 2,200 linguistic features derived from five comple- mentaryNLPtools, we investigated both cross-pair and within-pair patterns of divergence. At ...
-
[7]
Limitations Several limitations should be acknowledged. First, our analysis is restricted to the English language, and the patterns observed in this work may not generalize to other languages with different mor- phological, syntactic, or metaphorical conventions, especially given the fact that theNLPtools we used are built on and for the English language....
-
[8]
Prisca Piccirilli is also supported by the Studiens- tiftung des deutschen Volkes
Acknowledgments ThisresearchwassupportedbytheDFGResearch Grants SCHU 2580/4-1 (MUDCAT: Multimodal Di- mensions and Computational Applications of Ab- stractness) and SCHU 2580/7-1 and FR 2829/8-1 (MeTRapher: Learning to Translate Metaphors). Prisca Piccirilli is also supported by the Studiens- tiftung des deutschen Volkes. We are grateful to Annerose Eiche...
-
[9]
Bibliographical References Dawn G. Blasko. 1999. "Only the Tip of the Ice- berg": Who Understands what about Metaphor? Journal of Pragmatics, 31:1675–1683. Lera Boroditsky. 2000. Metaphoric Structuring: Un- derstanding Time Through Spatial Metaphors. Cognition, 75(1):1–28. Brian Bowdle and Dedre Gentner. 2005. The Career of Metaphor.Psychological Review, ...
work page 1999
-
[10]
GeorgeLakoffandMarkJohnson.1980.Metaphors We Live By
Assessing the Validity of Lexical Diversity Using Direct Judgements.Language Assess- ment Quarterly, 18(2):154–170. GeorgeLakoffandMarkJohnson.1980.Metaphors We Live By. University of Chicago Press, Chicago. Saif Mohammad, Ekaterina Shutova, andPeter Tur- ney. 2016. Metaphor as a Medium for Emotion: An Empirical Study. InProceedings of the Fifth Joint Con...
work page 1980
-
[11]
IMPLI: Investigating NLI Models’ Perfor- mance on Figurative Language. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics, pages 5375–5388, Dublin, Ireland. Association for Computational Linguistics. Mark Turner. 1996.The Literary Mind: The Origins of Thought and Language. Oxford University Press, Oxford. Raymondvand...
work page 1996
-
[12]
TheSyntacticFlexibilityofGermanandEn- glish Idioms: Evidence from Acceptability Rating Experiments.Journal of Linguistics, 60:1–38. A. Supplementary Materials A.1. Met vs. Lit Verb-Object Pairs Table 3: Metaphorical vs. Literal Verb–Object Pairs with Corpus Frequencies (N=297) MetaphoricalVOLiteralVOMet Count Lit Count absorb knowledge assimilate knowledg...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.