Recognition: 2 theorem links
· Lean TheoremGroundingAnomaly: Spatially-Grounded Diffusion for Few-Shot Anomaly Synthesis
Pith reviewed 2026-05-10 18:23 UTC · model grok-4.3
The pith
A new diffusion framework generates high-quality anomalies from few examples by conditioning on per-pixel semantic maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GroundingAnomaly is a few-shot anomaly image generation framework that employs a Spatial Conditioning Module leveraging per-pixel semantic maps to enable precise spatial control over synthesized anomalies and a Gated Self-Attention Module to inject conditioning tokens into a frozen U-Net, thereby preserving pretrained priors while ensuring stable adaptation and producing high-quality anomalies that yield state-of-the-art performance on downstream inspection tasks.
What carries the argument
The Spatial Conditioning Module that uses per-pixel semantic maps for location-specific anomaly placement, combined with the Gated Self-Attention Module that injects conditioning tokens into a frozen diffusion U-Net.
If this is right
- The generated anomalies integrate naturally into normal images and come with accurate masks.
- Few-shot adaptation succeeds while the underlying U-Net priors remain intact.
- State-of-the-art results appear across anomaly detection, segmentation, and instance-level detection on MVTec AD and VisA.
- The approach enlarges training sets for industrial inspection without requiring large numbers of real anomalies.
Where Pith is reading between the lines
- The same spatial-grounding pattern could be applied to other data-scarce image-editing tasks such as defect repair or object insertion.
- If the gated adaptation proves robust across domains, it offers a general recipe for conditioning large pretrained diffusion models without full fine-tuning.
- Accurate synthetic masks produced alongside the images may reduce the annotation burden for training segmentation models in manufacturing.
Load-bearing premise
The Spatial Conditioning Module and Gated Self-Attention Module together deliver precise spatial control and stable few-shot adaptation without introducing artifacts or mode collapse that would harm downstream task performance.
What would settle it
Downstream anomaly detectors trained on GroundingAnomaly outputs perform no better than those trained on outputs from prior synthesis methods when tested on the MVTec AD dataset.
Figures




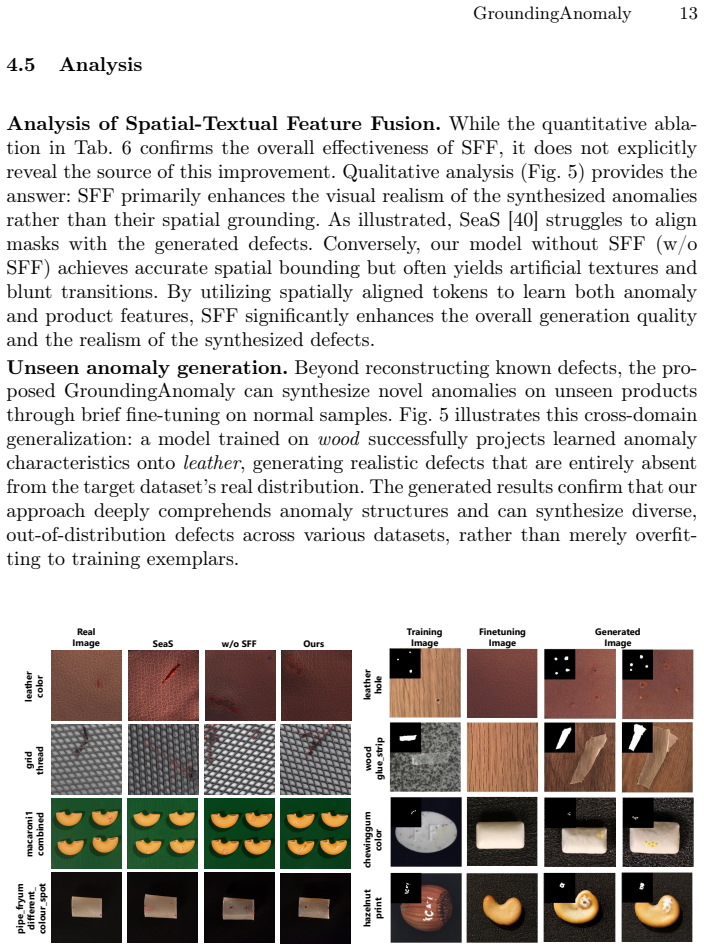






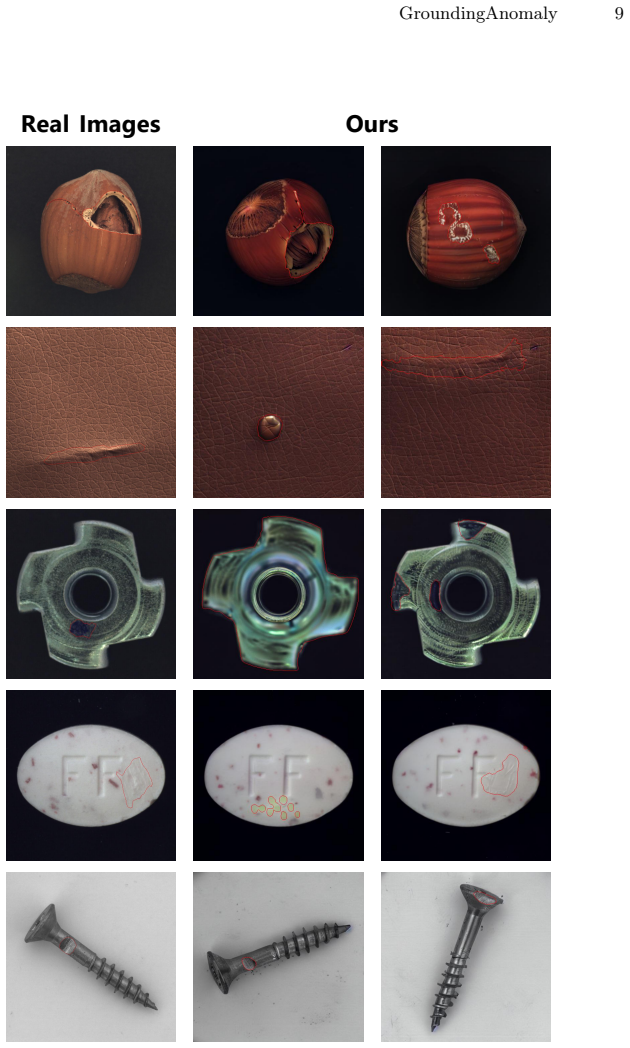



read the original abstract
The performance of visual anomaly inspection in industrial quality control is often constrained by the scarcity of real anomalous samples. Consequently, anomaly synthesis techniques have been developed to enlarge training sets and enhance downstream inspection. However, existing methods either suffer from poor integration caused by inpainting or fail to provide accurate masks. To address these limitations, we propose GroundingAnomaly, a novel few-shot anomaly image generation framework. Our framework introduces a Spatial Conditioning Module that leverages per-pixel semantic maps to enable precise spatial control over the synthesized anomalies. Furthermore, a Gated Self-Attention Module is designed to inject conditioning tokens into a frozen U-Net via gated attention layers. This carefully preserves pretrained priors while ensuring stable few-shot adaptation. Extensive evaluations on the MVTec AD and VisA datasets demonstrate that GroundingAnomaly generates high-quality anomalies and achieves state-of-the-art performance across multiple downstream tasks, including anomaly detection, segmentation, and instance-level detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GroundingAnomaly, a few-shot anomaly synthesis framework based on diffusion models. It introduces a Spatial Conditioning Module that uses per-pixel semantic maps to achieve precise spatial control over generated anomalies, along with a Gated Self-Attention Module that injects conditioning tokens into a frozen U-Net to enable stable adaptation while preserving pretrained priors. Extensive experiments on MVTec AD and VisA datasets are reported to show high-quality anomaly generation and state-of-the-art results on downstream tasks including anomaly detection, segmentation, and instance-level detection.
Significance. If the results hold, this approach could meaningfully advance few-shot anomaly synthesis for industrial inspection by addressing limitations of inpainting-based methods and providing accurate masks through spatial grounding. The design choice of freezing the U-Net and using gated attention for adaptation is a strength, as it supports stable few-shot learning without mode collapse or loss of generative quality, potentially benefiting other conditional diffusion applications.
minor comments (3)
- §3.1: The description of how per-pixel semantic maps are derived from the few-shot normal and anomalous examples should be expanded with a concrete example or pseudocode to clarify the input preparation pipeline.
- Figure 3: The visualization of synthesized anomalies would be clearer if the corresponding ground-truth masks were shown side-by-side for direct comparison of spatial accuracy.
- §4.1: The training protocol mentions 'few-shot' settings but does not specify the exact number of shots used in the main experiments; this detail should be stated explicitly in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the thorough and positive review of our manuscript on GroundingAnomaly. We are encouraged by the recognition of our framework's contributions to few-shot anomaly synthesis via spatial grounding and gated adaptation in diffusion models, as well as the potential impact on industrial inspection tasks. The recommendation for minor revision is noted.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper describes an architectural framework (Spatial Conditioning Module + Gated Self-Attention Module) inserted into a frozen U-Net for few-shot anomaly synthesis. No equations, predictions, or first-principles derivations are presented that reduce to fitted parameters or self-definitions by construction. Performance claims rest on external benchmarks (MVTec AD, VisA) rather than internal fits renamed as predictions. No self-citation chains, uniqueness theorems, or ansatz smuggling are load-bearing in the provided abstract and method summary. The derivation is self-contained as a set of engineering choices evaluated downstream, consistent with a score of 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our framework introduces a Spatial Conditioning Module that leverages per-pixel semantic maps... Gated Self-Attention Module... frozen U-Net via gated attention layers.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Extensive evaluations on the MVTec AD and VisA datasets demonstrate... state-of-the-art performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mvtec AD - A comprehensive real-world dataset for unsupervised anomaly detection
Bergmann, P., Fauser, M., Sattlegger, D., Steger, C.: Mvtec ad — a comprehen- sive real-world dataset for unsupervised anomaly detection. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9584–9592 (2019).https://doi.org/10.1109/CVPR.2019.00982
-
[2]
arXiv preprint arXiv:2401.16402 (2024)
Cao, Y., Xu, X., Zhang, J., Cheng, Y., Huang, X., Pang, G., Shen, W.: A survey on visual anomaly detection: Challenge, approach, and prospect. arXiv preprint arXiv:2401.16402 (2024)
-
[3]
In: European conference on computer vision
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End- to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
2020
-
[4]
In: European Conference on Computer Vision
Chen, Q., Luo, H., Lv, C., Zhang, Z.: A unified anomaly synthesis strategy with gradient ascent for industrial anomaly detection and localization. In: European Conference on Computer Vision. pp. 37–54. Springer (2024)
2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, H., Li, X.: Anomaly detection via reverse distillation from one-class embed- ding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9737–9746 (2022)
2022
-
[6]
In: AAAI (2023)
Duan, Y., Hong, Y., Niu, L., Zhang, L.: Few-shot defect image generation via defect-aware feature manipulation. In: AAAI (2023)
2023
-
[7]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. arXiv preprint arXiv:2208.01618 (2022)
work page internal anchor Pith review arXiv 2022
-
[8]
Advances in neural in- formation processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural in- formation processing systems27(2014)
2014
-
[9]
Gui, G., Gao, B.B., Liu, J., Wang, C., Wu, Y.: Few-shot anomaly-driven generation foranomalyclassificationandsegmentation.In:EuropeanConferenceonComputer Vision. pp. 210–226. Springer (2024)
2024
-
[10]
arXiv preprint arXiv:2510.17611 (2025)
Guo,J.,Lu,S.,Fan,L.,Li,Z.,Di,D.,Song,Y.,Zhang,W.,Zhu,W.,Yan,H.,Chen, F., et al.: One dinomaly2 detect them all: A unified framework for full-spectrum unsupervised anomaly detection. arXiv preprint arXiv:2510.17611 (2025)
-
[11]
Advances in Neural Information Processing Systems37, 71162– 71187 (2024)
He, H., Bai, Y., Zhang, J., He, Q., Chen, H., Gan, Z., Wang, C., Li, X., Tian, G., Xie, L.: Mambaad: Exploring state space models for multi-class unsupervised anomaly detection. Advances in Neural Information Processing Systems37, 71162– 71187 (2024)
2024
-
[12]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[13]
Heckler-Kram, L., Neudeck, J.H., Scheler, U., König, R., Steger, C.: The mvtec ad 2 dataset: Advanced scenarios for unsupervised anomaly detection. arXiv preprint arXiv:2503.21622 (2025)
-
[14]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[15]
In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf9
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: International Con- ference on Learning Representations (2022),https://openreview.net/forum?id= nZeVKeeFYf9
2022
-
[16]
Liu et al
Hu, T., Zhang, J., Yi, R., Du, Y., Chen, X., Liu, L., Wang, Y., Wang, C.: Anomaly- diffusion:Few-shotanomalyimagegenerationwithdiffusionmodel.In:Proceedings of the AAAI Conference on Artificial Intelligence (2024) 16 Y. Liu et al
2024
-
[17]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jeong, J., Zou, Y., Kim, T., Zhang, D., Ravichandran, A., Dabeer, O.: Winclip: Zero-/few-shot anomaly classification and segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19606–19616 (June 2023)
2023
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jin,Y.,Peng,J.,He,Q.,Hu,T.,Wu,J.,Chen,H.,Wang,H.,Zhu,W.,Chi,M.,Liu, J., et al.: Dual-interrelated diffusion model for few-shot anomaly image generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 30420–30429 (2025)
2025
-
[19]
https://github.com/ultralytics/yolov5(Oct 2020).https://doi.org/10
Jocher, G.: ultralytics/yolov5: v3.1 - bug fixes and performance improvements. https://github.com/ultralytics/yolov5(Oct 2020).https://doi.org/10. 5281/zenodo.4154370,https://doi.org/10.5281/zenodo.4154370
-
[20]
In: Proc
Karras, T., Aittala, M., Hellsten, J., Laine, S., Lehtinen, J., Aila, T.: Training generative adversarial networks with limited data. In: Proc. NeurIPS (2020)
2020
-
[21]
Auto-Encoding Variational Bayes
Kingma, D.P., Welling, M.: Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, C.L., Sohn, K., Yoon, J., Pfister, T.: Cutpaste: Self-supervised learning for anomaly detection and localization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9664–9674 (2021)
2021
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li,Y.,Liu,H.,Wu,Q.,Mu,F.,Yang,J.,Gao,J.,Li,C.,Lee,Y.J.:Gligen:Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22511–22521 (2023)
2023
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[25]
In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Lu, R., Wu, Y., Tian, L., Wang, D., Chen, B., Liu, X., Hu, R.: Hierarchical vector quantized transformer for multi-class unsupervised anomaly detection. In: Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems. vol. 36, pp. 8487–8500. Curran Associates, Inc. (2023),https://proceedin...
2023
-
[26]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference (CVPR)
Luo, W., Cao, Y., Yao, H., Zhang, X., Lou, J., Cheng, Y., Shen, W., Yu, W.: Exploring intrinsic normal prototypes within a single image for universal anomaly detection. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference (CVPR). pp. 9974–9983 (June 2025)
2025
-
[27]
Advances in neural information processing systems28(2015)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object de- tection with region proposal networks. Advances in neural information processing systems28(2015)
2015
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[29]
In: International Conference on Medical image computing and computer-assisted intervention
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi- cal image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. pp. 234–241. Springer (2015)
2015
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., Gehler, P.: Towards total recall in industrial anomaly detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14318– 14328 (June 2022)
2022
-
[31]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Roth, K., Pemula, L., Zepeda, J., Schölkopf, B., Brox, T., Gehler, P.: Towards total recall in industrial anomaly detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14318–14328 (2022) GroundingAnomaly 17
2022
-
[32]
Denoising Diffusion Implicit Models
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[33]
In: Proceedings of the European conference on computer vision (ECCV)
Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J.: Unified perceptual parsing for scene understanding. In: Proceedings of the European conference on computer vision (ECCV). pp. 418–434 (2018)
2018
-
[34]
Advances in neural information processing systems34, 12077–12090 (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in neural information processing systems34, 12077–12090 (2021)
2021
-
[35]
In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A
You, Z., Cui, L., Shen, Y., Yang, K., Lu, X., Zheng, Y., Le, X.: A uni- fied model for multi-class anomaly detection. In: Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A. (eds.) Advances in Neural In- formation Processing Systems. vol. 35, pp. 4571–4584. Curran Associates, Inc. (2022),https : / / proceedings . neurips . cc / paper _ fil...
2022
-
[36]
International journal of computer vision129(11), 3051–3068 (2021)
Yu, C., Gao, C., Wang, J., Yu, G., Shen, C., Sang, N.: Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. International journal of computer vision129(11), 3051–3068 (2021)
2021
-
[37]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Zavrtanik, V., Kristan, M., Skočaj, D.: Draem - a discriminatively trained re- construction embedding for surface anomaly detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 8330–8339 (October 2021)
2021
-
[38]
Zhang, J., Chen, X., Wang, Y., Wang, C., Liu, Y., Li, X., Yang, M.H., Tao, D.: Exploring plain vit reconstruction for multi-class unsupervised anomaly detection. arXiv preprint arXiv:2312.07495 (2023)
-
[39]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023)
2023
-
[40]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Zhewei,D.,Shilei,Z.,Haotian,L.,Xurui,L.,Feng,X.,Yu,Z.:Seas:Few-shotindus- trial anomaly image generation with separation and sharing fine-tuning. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[41]
In: The Twelfth International Conference on Learning Representations (2023)
Zhou, Q., Pang, G., Tian, Y., He, S., Chen, J.: Anomalyclip: Object-agnostic prompt learning for zero-shot anomaly detection. In: The Twelfth International Conference on Learning Representations (2023)
2023
-
[42]
In: European conference on computer vision
Zou, Y., Jeong, J., Pemula, L., Zhang, D., Dabeer, O.: Spot-the-difference self- supervised pre-training for anomaly detection and segmentation. In: European conference on computer vision. pp. 392–408. Springer (2022) GroundingAnomaly 1 A Appendix This supplementary material consists of: –More Implementation Details (Sec. A.1). –More Ablation Studies & An...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.